用Scrapy抓取豆瓣小組資料(三)
接著上篇部落格《用Scrapy抓取豆瓣小組資料(三)》,http://my.oschina.net/chengye/blog/124162
處理抓取的資料
我抓取了豆瓣一千多個小組的首頁,獲取的內容包括名稱,成員數目,小組連結以及相關友情小組和推薦小組。Scrapy匯出的資料格式可以是json/xml/csv等,我這邊用了json格式,每個小組資料的格式如下:
01 |
{ |
02 |
"groupName": "\u5e2e\u52a9\u5927\u5c71\u91cc\u7684\u5b69\u5b50", |
03 |
"groupURL": "http://www.douban.com/group/16533/", |
04 |
"RelativeGroups":
[ |
05 |
"http://www.douban.com/group/henisiben/", |
06 |
"http://www.douban.com/group/HOWPROJECT/", |
07 |
"http://www.douban.com/group/225202/", |
08 |
"http://www.douban.com/group/334177/", |
09 |
"http://www.douban.com/group/gesanghua/", |
10 |
"http://www.douban.com/group/J/", |
11 |
"http://www.douban.com/group/17551/", |
12 |
"http://www.douban.com/group/wutaishan/", |
13 |
"http://www.douban.com/group/72790/", |
14 |
"http://www.douban.com/group/ChindiaIndia/", |
15 |
"http://www.douban.com/group/74982/", |
16 |
"http://www.douban.com/group/119384/" |
17 |
], |
18 |
"totalNumber": "5833" |
19 |
} |
由於是要進行網路分析,假設每個小組就是一個節點(vertex),如果任意兩個小組是相關小組(通過RelativeGroups來判斷),則兩個節點相連線(edge)。所以處理指令碼要做的事情,第一生成節點的列表,第二生成節點間的連線。要注意的是對抓取的的重複資料進行清理,並且保證每個連線兩端的節點都是有效的。
偷懶用javascript處理了下,然後列印出一個gml格式的檔案,用於下一步分析。 GML格式的非常簡單,就是一個node列表加上edge列表。定義node時其實只有id是必填項,其他屬性都可以自定義的。
01 |
graph |
02 |
[ |
03 |
comment "Douban
group graph" |
04 |
directed 0 |
05 |
|
06 |
node |
07 |
[ |
08 |
id 1 |
09 |
label "幫助大山裡的孩子" |
10 |
size 5833 |
11 |
url "http://www.douban.com/group/16533/" |
12 |
] |
13 |
node |
14 |
[ |
15 |
id 2 |
16 |
label "加入這個組你就會變聰明" |
17 |
size 3689 |
18 |
url "http://www.douban.com/group/congming/" |
19 |
] |
20 |
..... |
21 |
edge |
22 |
[ |
23 |
source 1 |
24 |
target 2 |
25 |
] |
26 |
] |
在Gephi中視覺化處理網路
Gephi是一款很流行復雜網路視覺化軟體,我就用它開啟前面生成的GML檔案,然後可以對節點進行配色,分類以及佈局。具體就不講了,最後得到的網路圖是這個模樣的。
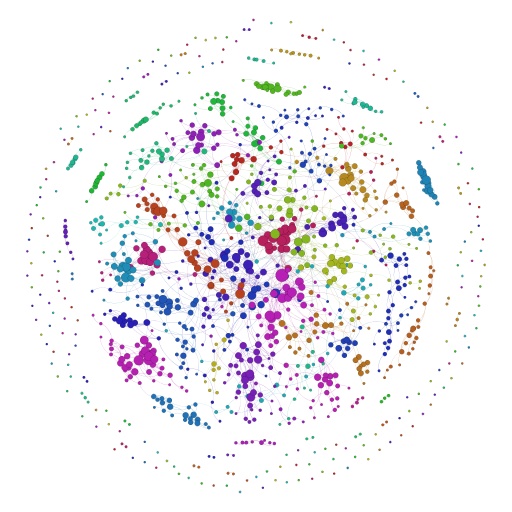
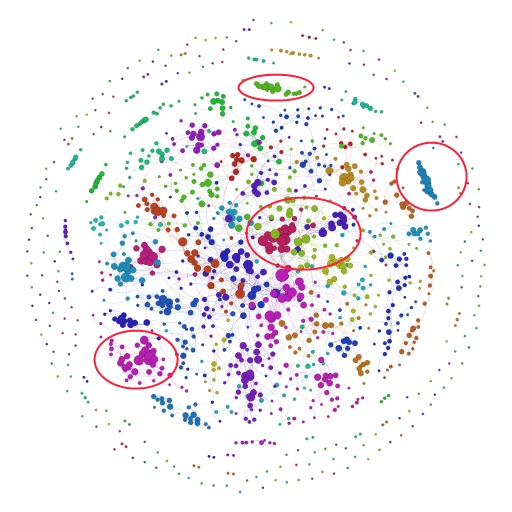
節點越大說明小組的連線個數越多,顏色代表著不同的小組型別(用Gephi的自帶演算法分類的)。下面這張圖這種我劃出了4個不同的區域,代表著不同型別的小組,有人能猜到分別是什麼型別的小組嗎?可以告訴你是哪四種:蕾絲小組,Gay小組,手工小組,美容小組。
Have Fun~
相關文章
- 用Scrapy抓取豆瓣小組資料(一)
- 用Scrapy抓取豆瓣小組資料(二)
- 使用Scrapy抓取資料
- scrapy爬取豆瓣電影資料
- scrapy 爬電影 抓取資料
- 用scrapy進行網頁抓取網頁
- scrapy實戰之定向抓取某網店商品資料
- 爬蟲教程——用Scrapy爬取豆瓣TOP250爬蟲
- 英語資料抓取組的章程
- 批量抓取豆瓣電影圖片
- 【仿豆瓣小組】極簡社群開源產品
- Scrapy框架抓取安居客房源資訊框架
- scrapy抓取ajax請求的網頁網頁
- 關於成立英語資料抓取組的倡議
- scrapy入門:豆瓣電影top250爬取
- Python爬蟲入門教程 33-100 《海王》評論資料抓取 scrapyPython爬蟲
- scrapy爬蟲成長日記之將抓取內容寫入mysql資料庫爬蟲MySql資料庫
- 使用Chrome快速實現資料的抓取(三)——JQueryChromejQuery
- python爬蟲實踐: 豆瓣小組命令列客戶端Python爬蟲命令列客戶端
- python爬蟲知識點三--解析豆瓣top250資料Python爬蟲
- 豆瓣top250資料爬取
- Node.js爬取豆瓣資料Node.js
- 用代理IP抓取大資料有什麼好處?大資料
- 用rvest包來抓取Google學術搜尋資料Go
- 跨DB主機抓取資料建議用MATERIALIZED VIEWZedView
- 儲存資料到MySql資料庫——我用scrapy寫爬蟲(二)MySql資料庫爬蟲
- windows安裝Anaconda3,Anaconda3安裝scrapy抓取鏈家資料入門例子Windows
- 資料分析的三大組成部分
- 如何使用代理IP進行資料抓取,PHP爬蟲抓取亞馬遜商品資料PHP爬蟲亞馬遜
- 爬取網頁後的抓取資料_3種抓取網頁資料方法網頁
- Scrapy爬蟲:實習僧網最新招聘資訊抓取爬蟲
- Python爬蟲筆記(4):利用scrapy爬取豆瓣電影250Python爬蟲筆記
- 不會程式設計?來用Excel抓取網路資料程式設計Excel
- Scrapy框架-通過scrapy_splash解析動態渲染的資料框架
- 業務資料抓取的影響
- python簡書資料抓取Python
- 爬蟲原理與資料抓取爬蟲
- 資料包抓取工具:Debookee for macMac