Python爬蟲開發(二):整站爬蟲與Web挖掘
*原創作者:VillanCh
0×00 介紹
0×01 協議
0×02 原則
0×03 確立目標與分析過程
0×04 動手
0×05 sitemap爬蟲
0×06 web元素處理
0×07 總結與預告
0×00 介紹
在網際網路這個複雜的環境中,搜尋引擎本身的爬蟲,出於個人目的的爬蟲,商業爬蟲肆意橫行,肆意掠奪網上的或者公共或者私人的資源。顯然資料的收集並不是為所欲為,有一些協議或者原則還是需要每一個人注意。本文主要介紹關於爬蟲的一些理論和約定協議,然後相對完整完成一個爬蟲的基本功能。
0×01 協議
一般情況下網站的根目錄下存在著一個robots.txt的檔案,用於告訴爬蟲那些資料夾或者哪些檔案是網站的擁有者或者管理員不希望被搜尋引擎和爬蟲瀏覽的,或者是不希望被非人類的東西檢視的。但是不僅僅如此,在這個檔案中,有時候還會指明sitemap的位置,爬蟲可以直接尋找sitemap而不用費力去爬取網站,製作自己的sitemap。那麼最好我們看個具體的例子吧,這樣更有助於理解robots協議:
-----------------------以下時freebuf的robots.txt-------------
User-agent: *
Disallow: /*?*
Disallow: /trackback
Disallow: /wp-*/
Disallow: */comment-page-*
Disallow: /*?replytocom=*
Disallow: */trackback
Disallow: /?random
Disallow: */feed
Disallow: /*.css$
Disallow: /*.js$
Sitemap: http://www.freebuf.com/sitemap.txt
大家可以看到,這裡指明瞭適用的User-agent頭,指明瞭Disallow的目錄,也指明瞭sitemap,然後我們在看一下sitemap中是什麼:
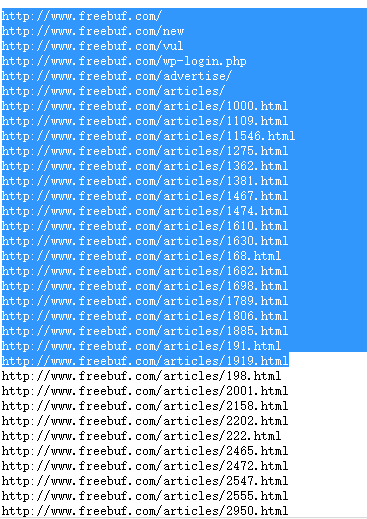
我們大致可以發現這些都是整個網站允許公開的內容,如果這個爬蟲作者是對freebuf的文章感興趣的話,大可不必從頭到尾設計爬蟲演算法拿下整個網站的sitemap,這樣直接瀏覽sitemap節省了大量的時間。
0×02 原則
如果協議不存在的話,我們仍然不能為所欲為,上網隨意搜尋一下源於爬蟲協議的官司,國內外都有。爬蟲的協議規則建立在如下的基礎上:
1. 搜尋技術應該服務於人類,尊重資訊提供者的意願,並維護其隱私權;
2. 網站也有義務保護其使用者的個人資訊和隱私不被侵犯。
簡單來說,就是構建的爬蟲以資訊收集為目的是沒錯的,但是不能侵犯別人的隱私,比如你掃描並且進入了網站的robots中的disallow欄位,你就可能涉及侵犯別人隱私的問題。當然作為一般人來講,我們使用爬蟲技術無非是學習,或者是蒐集想要的資訊,並沒有想那麼多的侵權,或者是商業的問題。
0×03 確立目標與分析過程
這裡我提供一個爬蟲誕生要經歷的一般過程:
1. 確立需求在,sitemap中挑選出需要挖掘的頁面;
2. 依次分析挑選出的頁面;
3. 儲存分析結果。
但是有時候問題就是,我們的目標網站沒有提供sitemap,那麼這就得麻煩我們自己去獲取自己定製的sitemap。
目標:製作一個網站的sitemap:
分析:我們要完成這個過程,但是不存在現成sitemap,筆者建議大家把這個網站想象成一個圖的結構,網站的url之間縱橫交錯,我們可以通過主頁面進行深度優先或者廣度優先搜尋從而遍歷整個網站拿到sitemap。顯然我們發現,我們首先要做的第一步就是完整的獲取整個頁面的url。
但是我們首先得想清楚一個問題:我們獲取到的url是應該是要限制域名的,如果爬蟲從目標網站跳走了,也就意味著將無限陷入整個網路進行挖掘。這麼龐大的資料量,我想不是一般人的電腦硬碟可以承受的吧!
那麼我們的第一步就是編寫程式碼去獲取整個頁面的url。其實這個例子在上一篇文章中已經講到過。
0×04 動手
我們的第一個小目標就是獲取當前頁面所有的url:
首先必須說明的是,這個指令碼並不具有普遍性(只針對freebuf.com),並且效率低下,可以優化的地方很多:只是為了方便,簡單實現了功能,有興趣的朋友可以任意重構達到高效優雅的目的
import urllib
from bs4 import BeautifulSoup
import re
def get_all_url(url):
urls = []
web = urllib.urlopen(url)
soup =BeautifulSoup(web.read())
#通過正則過濾合理的url(針對與freebuf.com來講)
tags_a =soup.findAll(name='a',attrs={'href':re.compile("^https?://")})
try :
for tag_a in tags_a:
urls.append(tag_a['href'])
#return urls
except:
pass
return urls
#得到所有freebuf.com下的url
def get_local_urls(url):
local_urls = []
urls = get_all_url(url)
for _url in urls:
ret = _url
if 'freebuf.com' in ret.replace('//','').split('/')[0]:
local_urls.append(_url)
return local_urls
#得到所有的不是freebuf.com域名的url
def get_remote_urls(url):
remote_urls = []
urls = get_all_url(url)
for _url in urls:
ret = _url
if "freebuf.com" not in ret.replace('//','').split('/')[0]:
remote_urls.append(_url)
return remote_urls
def __main__():
url = 'http://freebuf.com/'
rurls = get_remote_urls(url)
print "--------------------remote urls-----------------------"
for ret in rurls:
print ret
print "---------------------localurls-----------------------"
lurls = get_local_urls(url)
for ret in lurls:
print ret
if __name__ == '__main__':
__main__()
這樣我們就得到了該頁面的url,本域名和其他域名下:
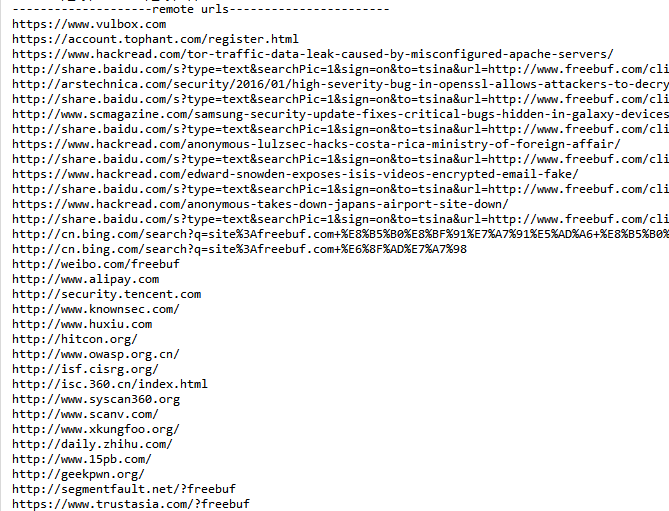
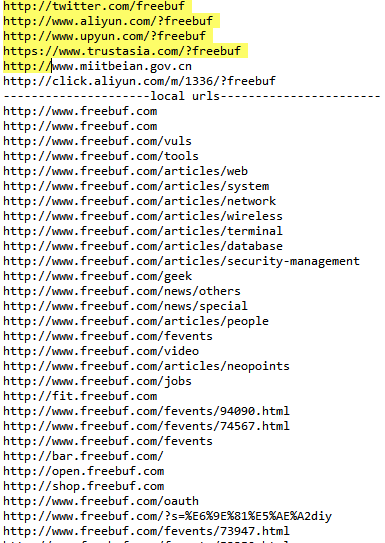
當然圖中所示的結果為部分截圖,至少證明了我們上面的程式碼比較好的解決的url獲取的問題,由於這裡我們的判斷規則簡單,還有很多情況沒有考慮到,所以建議大家如果有時間,可以把上面程式碼重構成更佳普適,更加完整的指令碼,再投入真正的實際使用。
0×05 sitemap爬蟲
所謂的sitemap,我們在上面的例子中又講到sitemap記錄了整個網站的網站擁有者允許你爬取內容的連結。但是很多情況下,sitemap沒有寫出,那麼問題就來了,我們面對一個陌生的網站如何進行爬取(在不存在sitemap的情況下).
當然我們首先要獲取sitemap,沒有現成的我們就自己動手獲取整個網站的sitemap。
再開始之前我們需要整理一下思路:我們可以把整站當成一個錯綜複雜的圖結構,有一些演算法基礎的讀者都會知道圖的簡單遍歷方法:dfs和bfs(深度優先和廣度優先)。如果這裡讀者有問題的話建議先去學習一下這兩種演算法。大體的演算法結構我們清楚了,但是在實現中我們顯然需要特殊處理url,需要可以區分當前目標站點域名下的網站和其他域名的網站,除此之外,在href的值中經常會出現相對url,這裡也要特別處理。
import urllib
from bs4 import BeautifulSoup
import urlparse
import time
import urllib2
url = "http://xxxx.xx/"
domain = "xxxx.xx"
deep = 0
tmp = ""
sites = set()
visited = set()
#local = set()
def get_local_pages(url,domain):
global deep
global sites
global tmp
repeat_time = 0
pages = set()
#防止url讀取卡住
while True:
try:
print "Ready to Open the web!"
time.sleep(1)
print "Opening the web", url
web = urllib2.urlopen(url=url,timeout=3)
print "Success to Open the web"
break
except:
print "Open Url Failed !!! Repeat"
time.sleep(1)
repeat_time = repeat_time+1
if repeat_time == 5:
return
print "Readint the web ..."
soup = BeautifulSoup(web.read())
print "..."
tags = soup.findAll(name='a')
for tag in tags:
#避免引數傳遞異常
try:
ret = tag['href']
except:
print "Maybe not the attr : href"
continue
o = urlparse.urlparse(ret)
"""
#Debug I/O
for _ret in o:
if _ret == "":
pass
else:
print _ret
"""
#處理相對路徑url
if o[0] is "" and o[1] is "":
print "Fix Page: " +ret
url_obj = urlparse.urlparse(web.geturl())
ret = url_obj[0] + "://" + url_obj[1] + url_obj[2] + ret
#保持url的乾淨
ret = ret[:8] + ret[8:].replace('//','/')
o = urlparse.urlparse(ret)
#這裡不是太完善,但是可以應付一般情況
if '../' in o[2]:
paths = o[2].split('/')
for i inrange(len(paths)):
if paths[i] == '..':
paths[i] = ''
if paths[i-1]:
paths[i-1] = ''
tmp_path = ''
for path in paths:
if path == '':
continue
tmp_path = ret_path + '/' +path
ret =ret.replace(o[2],ret_path)
print "FixedPage: " + ret
#協議處理
if 'http' not in o[0]:
print "Bad Page:" + ret.encode('ascii')
continue
#url合理性檢驗
if o[0] is "" and o[1] is not "":
print "Bad Page: " +ret
continue
#域名檢驗
if domain not in o[1]:
print "Bad Page: " +ret
continue
#整理,輸出
newpage = ret
if newpage not in sites:
print "Add New Page: " + newpage
pages.add(newpage)
return pages
#dfs演算法遍歷全站
def dfs(pages):
#無法獲取新的url說明便利完成,即可結束dfs
if pages is set():
return
global url
global domain
global sites
global visited
sites = set.union(sites,pages)
for page in pages:
if page not in visited:
print "Visiting",page
visited.add(page)
url = page
pages = get_local_pages(url, domain)
dfs(pages)
print "sucess"
pages = get_local_pages(url, domain)
dfs(pages)
for i in sites:
print i
在這個指令碼中,我們採用了dfs(深度優先演算法),關於演算法的問題我們不做深入討論,實際上在完成過程中我們關鍵要完成的是對href的處理,在指令碼程式碼中我們也可以看到,url的處理佔了大部分程式碼,但是必須說明的是:很遺憾我們並沒有把所有的情況都解決清楚,但是經過測試,上面的程式碼可以應付很多種情況。所以大家如果有需要可以隨意修改使用。
測試:用上面的指令碼在網路狀況一般的情況下,對我的個人部落格(大概100個頁面)進行掃描,大概用時2分半,這是單機爬蟲。
0×06 Web元素處理
在接下來的這個例子中,我們不再關注url的處理,我們暫且把目光對準web單個頁面的資訊處理。按照爬蟲編寫的一般流程,在本例子中,爭取每一步都是完整的可操作的。
確立目標:獲取freebuf的文章並且生成docx文件。
過程:偵察目標網頁的結構,針對特定結構設計方案
指令碼實現:bs4模組和docx模組的使用
預備知識:
1.Bs4的基本api的使用,關於beautifulSoup的基本使用方法,我這裡需要介紹在下面的指令碼中我使用到的方法:
Soup = BeautifulSoup(data)#構建一個解析器
Tags = Soup.findAll(name,attr)
我們重點要講findAll方法的兩個引數:name和attr
Name: 指的是標籤名,傳入一個標籤名的名稱就可以返回所有固定名稱的標籤名
Attr: 是一個字典儲存需要查詢的標籤引數,返回對應的標籤
Tag.children 表示獲取tag標籤的所有子標籤
Tag.string 表示獲取tag標籤內的所有字串,不用一層一層索引下去尋找字串
Tag.attrs[key] 表示獲取tag標籤內引數的鍵值對鍵為key的值
Tag.img 表示獲取tag標籤的標籤名為img的自標籤(一個)
在本例子的使用中,筆者通過標籤名+id+class來定位標籤,雖然這樣的方法不是絕對的正確,但是一般情況下,準確率還是比較高的。
2.docx的使用:在使用這個模組的時候,要記清楚如果:
pip install python-docx
easy_install python-docx
兩種方式安裝都不能正常使用的話,就需要下載tar包自己手動安裝
Docx模組是一個可以直接操作生成docx文件的python模組,使用方法極盡簡單:
Demo = Document() #在記憶體中建立一個doc文件
Demo.add_paragraph(data) #在doc文件中新增一個段落
Demo.add_picture(“pic.png”) #doc文件中新增一個圖片
Demo.save(‘demo.docx’) #儲存docx文件
當然這個模組還可以操作段落的字型啊格式啊各種強大的功能,大家可以從官方網站找到對應的文件。鑑於我們以學習為目的,我就不作深入的排版介紹了
開始:
觀察html結構:
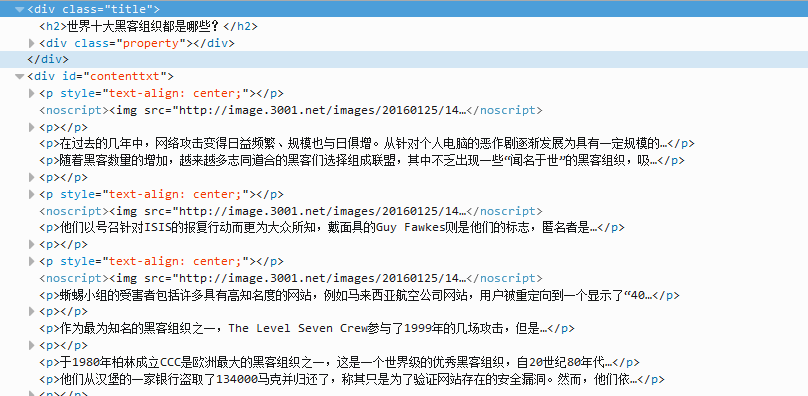
我們大致觀察一下結構,定位到文章的具體內容需要找到標籤,然後再遍歷標籤的子標籤即可遍歷到所有的段落,配圖資料
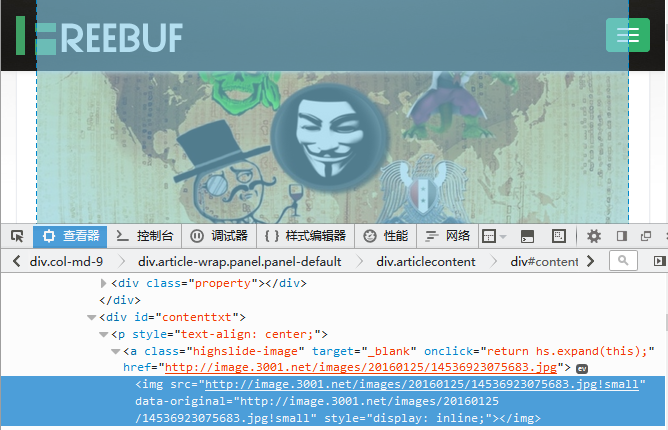
這樣定位到圖片,那麼我們怎麼樣來尋找
程式碼
from docx import Document
from bs4 import BeautifulSoup
import urllib
url ="http://freebuf.com/news/94263.html"
data = urllib.urlopen(url)
document = Document()
soup = BeautifulSoup(data)
article = soup.find(name ="div",attrs={'id':'contenttxt'}).children
for e in article:
try:
if e.img:
pic_name = ''
print e.img.attrs['src']
if 'gif' in e.img.attrs['src']:
pic_name = 'temp.gif'
elif 'png' in e.img.attrs['src']:
pic_name = 'temp.png'
elif 'jpg' in e.img.attrs['src']:
pic_name = 'temp.jpg'
else:
pic_name = 'temp.jpeg'
urllib.urlretrieve(e.img.attrs['src'], filename=pic_name)
document.add_picture(pic_name)
except:
pass
if e.string:
print e.string.encode('gbk','ignore')
document.add_paragraph(e.string)
document.save("freebuf_article.docx")
print "success create a document"
當然上面的程式碼,讀者看起來是非常粗糙的,其實沒關係,我們的目的達到了,在使用中學習,這也是python的精神。可能大家不熟悉beautifulsoup的使用,這裡需要大家自行去讀一下beautifulsoup官方的doc,筆者不知道有沒有中文版,但是讀英文也不是那麼麻煩,基本寫的還是非常簡明易懂。
那麼我們可以看一下輸出的結構吧!
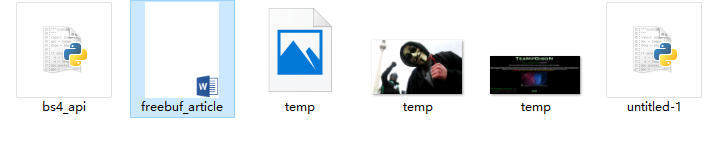
這是資料夾目錄下的檔案,開啟生成的docx文件以後:

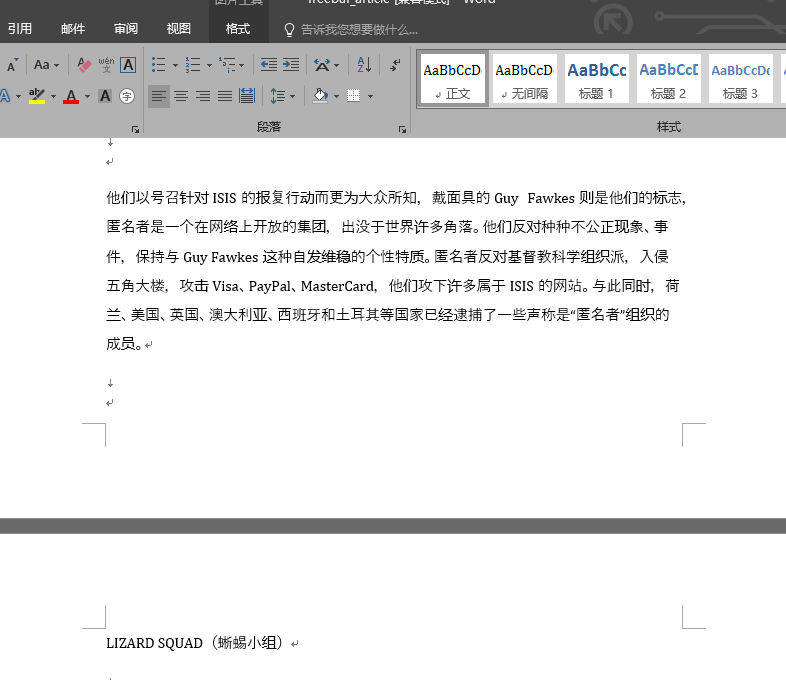
這裡我們發現排版仍然是有缺陷,但是所有的內容,圖片都按照原來的順序成功儲存在了.docx檔案中。
0×07 總結與預告
在本文中我們快速學習了簡單單機爬蟲的製作,並且動手對網頁的資訊進行了一定的處理分類。但是這並不是結束,而僅僅是一個開始。還有很多的知識等待我們去探究:比如模擬登陸,抓取登陸以後的web網頁等,其實這些並不困難。
在接下來的文章中我們會陸續講到:
1. 資料儲存
2. 多執行緒
3. 動態網頁抓取(js載入)
*原創作者:VillanCh,本文屬FreeBuf原創獎勵計劃文章,未經作者本人及FreeBuf許可,切勿私自轉載
相關文章
- 【Python學習】爬蟲爬蟲爬蟲爬蟲~Python爬蟲
- Python爬蟲開發與專案實戰——基礎爬蟲分析Python爬蟲
- Python爬蟲開發與專案實戰 3: 初識爬蟲Python爬蟲
- 不踩坑的Python爬蟲:Python爬蟲開發與專案實戰,從爬蟲入門 PythonPython爬蟲
- Java爬蟲與Python爬蟲的區別?Java爬蟲Python
- 通用爬蟲與聚焦爬蟲爬蟲
- 【python爬蟲】python爬蟲demoPython爬蟲
- python爬蟲---網頁爬蟲,圖片爬蟲,文章爬蟲,Python爬蟲爬取新聞網站新聞Python爬蟲網頁網站
- 一個很垃圾的整站爬取--Java爬蟲Java爬蟲
- Python爬蟲與Java爬蟲有何區別?Python爬蟲Java
- 《Python3網路爬蟲開發實戰》教程||爬蟲教程Python爬蟲
- 爬蟲開發技巧爬蟲
- 爬蟲技術(二)-客戶端爬蟲爬蟲客戶端
- python簡單爬蟲(二)Python爬蟲
- python爬蟲實操專案_Python爬蟲開發與專案實戰 1.6 小結Python爬蟲
- [Python3網路爬蟲開發實戰] 分散式爬蟲原理Python爬蟲分散式
- python就是爬蟲嗎-python就是爬蟲嗎Python爬蟲
- python3網路爬蟲開發實戰_Python 3開發網路爬蟲(一)Python爬蟲
- python爬蟲實戰教程-Python爬蟲開發實戰教程(微課版)Python爬蟲
- 新手爬蟲,教你爬掘金(二)爬蟲
- 爬蟲與反爬蟲技術簡介爬蟲
- 爬蟲:多程式爬蟲爬蟲
- python爬蟲Python爬蟲
- python 爬蟲Python爬蟲
- Python爬蟲開發與專案實戰 2:Web前端基礎Python爬蟲Web前端
- Python爬蟲教程-01-爬蟲介紹Python爬蟲
- Python爬蟲開發與專案實戰pdfPython爬蟲
- Python爬蟲開發與專案實踐(3)Python爬蟲
- Python爬蟲開發與專案實戰(2)Python爬蟲
- Python爬蟲開發與專案實戰(1)Python爬蟲
- IPIDEA乾貨|Java爬蟲與Python爬蟲的區別IdeaJava爬蟲Python
- python爬蟲開發微課版pdf_Python爬蟲開發實戰教程(微課版)Python爬蟲
- python3網路爬蟲開發實戰_Python3 爬蟲實戰Python爬蟲
- python爬蟲之js逆向(二)Python爬蟲JS
- Python爬蟲知識點二Python爬蟲
- 我的爬蟲入門書 —— 《Python3網路爬蟲開發實戰(第二版)》爬蟲Python
- websocket與爬蟲Web爬蟲
- C#爬蟲與反爬蟲--字型加密篇C#爬蟲加密