Python爬蟲開發(一):零基礎入門
*原創作者:VillanCh
0×00 介紹
0×01 要求
0×02 你能學到什麼?
0×03 知識補充
0×04 最簡單的開始
0×05 更優雅的解決方案
0×06 url合法性判斷
0×07 總結與預告
0×00 介紹
爬蟲技術是資料探勘,測試技術的重要的組成部分,是搜尋引擎技術的核心。
但是作為一項普通的技術,普通人同樣可以用爬蟲技術做很多很多的事情,比如:你想了解一下FreeBuf所有關於爬蟲技術的文章,你就可以編寫爬蟲去對FreeBuf的文章進行搜尋,解析。比如你想獲得淘寶某類商品的價格,你可以編寫爬蟲自動搜尋某類商品,然後獲取資訊,得到自己想要的結果,每天定時爬一下自己就可以決定在什麼時候低價的時候買下心儀的商品了。或者說自己想收集某類資訊集合成自己的資料庫,但是手動複製貼上特別的麻煩,這時候爬蟲技術就可以幫上大忙了對不對?
0×01 要求
那麼本系列文章旨在普及爬蟲技術,當然不是那種直接拿來爬蟲框架來說明的。在本系列文章中,筆者盡力從簡到難,簡明地介紹爬蟲的各種要素,怎麼樣快速編寫對自己有用的程式碼。但是對讀者有一定小小的要求:看得懂python程式碼,然後自己能動手實踐一些,除此之外,還要對html元素有一定的瞭解。
0×02 你能學到什麼?
當然爬蟲的文章在網上很容易找到,但是精緻,系統地講解的文章還是比較少,筆者在本文和今後的文章將介紹關於爬蟲的各種各樣的知識:
大致上,本文的寫作順序是單機爬蟲到分散式爬蟲,功能實現到整體設計,從微觀到巨集觀。
1. 簡單模組編寫簡單爬蟲
2. 相對優雅的爬蟲
3. 爬蟲基本理論以及一般方法
4. 簡單Web資料探勘
5. 動態web爬蟲(可以處理js的爬蟲)
6. 爬蟲的資料儲存
7. 多執行緒與分散式爬蟲設計
如果有讀者想找一些爬蟲的入門書籍來看,我推薦《web scraping with python》,這本書是英文版目前沒有中文譯本,但是網上有愛好者在翻譯,有興趣的讀者可以瞭解一下。
0×03 知識補充
在這裡的知識補充我其實是要簡單介紹目前主流的幾種爬蟲編寫用的模組:
Htmllib(sgmllib),這個模組是非常古老的一個模組,偏底層,實際就是簡單解析html文件而已,不支援搜尋標籤,容錯性也比較差,這裡指的提醒的是,如果傳入的html文件沒有正確結束的話,這個模組是不會解析的,直到正確的資料傳入或者說強行關閉。
BeautifulSoup,這個模組解析html非常專業,具有很好的容錯性,可以搜尋任意標籤,自帶編碼處理方案。
Selenium,自動化web測試方案解決者,類似BeautifulSoup,但是不一樣的是,selenium自帶了js直譯器,也就是說selenium配合瀏覽器可以用來做動態網頁的爬取,分析,挖掘。
Scrapy框架:一個專業的爬蟲框架(單機),有相對完整的解決方案。
API爬蟲:這裡大概都是需要付費的爬蟲API,比如google,twitter的解決方案,就不在介紹。
筆者在文章中只會出現前三種方式來做爬蟲編寫。
0×04 最簡單的開始
最開始的一個例子,我將會先介紹最簡單的模組,編寫最簡單的單頁爬蟲:
Urllib這個模組我們這裡用來獲取一個頁面的html文件,具體的使用是,
Web = urllib.urlopen(url)
Data = Web.read()
要注意的是,這是py2的寫法,py3是不一樣的。
Smgllib這個庫是htmllib的底層,但是也可以提供一個對html文字的解析方案,具體的使用方法是:
1. 自定義一個類,繼承sgmllib的SGMLParser;
2. 複寫SGMLParser的方法,新增自己自定義的標籤處理函式
3. 通過自定義的類的物件的.feed(data)把要解析的資料傳入解析器,然後自定義的方法自動生效。
import urllib
import sgmllib
class handle_html(sgmllib.SGMLParser):
#unknown_starttag這個方法在任意的標籤開始被解析時呼叫
#tag為標籤名
#attrs表示標籤的參賽
def unknown_starttag(self, tag, attrs):
print "-------"+tag+" start--------"
print attrs
#unknown_endtag這個方法在任意標籤結束被解析時被呼叫
def unknown_endtag(self, tag):
print "-------"+tag+" end----------"
web =urllib.urlopen("http://freebuf.com/")
web_handler = handle_html()
#資料傳入解析器
web_handler.feed(web.read())
短短十幾行程式碼,最簡單的單頁面爬蟲就完成了,以下是輸出的效果。我們可以看到標籤開始和結束都被標記了。然後同時列印出了每一個引數。
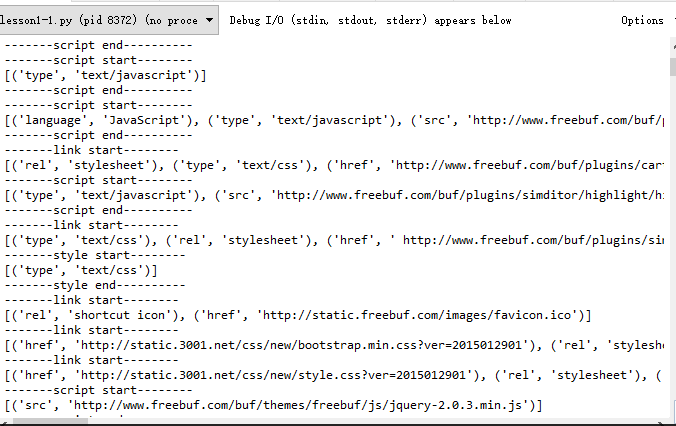
接下來我們可以使用這種底層的解析方式來做個基礎的小例子:
下面這個小例子在標籤開始的時候檢查標籤中的attrs屬性,解析出所有的引數的href屬性,知道的讀者都知道這基本是被一個爬蟲的必經之路。
import urllib
import sgmllib
class handle_html(sgmllib.SGMLParser):
defunknown_starttag(self, tag, attrs):
#這裡利用try與except來避免報錯。
#但是並不推薦這樣做,
#對於這種小指令碼雖然無傷大雅,但是在實際的專案處理中,
#這種做法存在很大的隱患
try:
for attr in attrs:
if attr[0] == "href":
printattr[0]+":"+attr[1].encode('utf-8')
except:
pass
web =urllib.urlopen("http://freebuf.com/")
web_handler = handle_html()
web_handler.feed(web.read())
解析結果為:
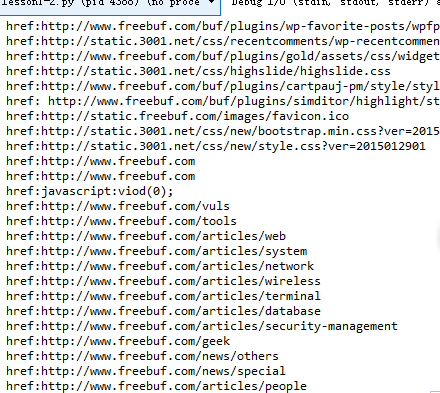
我們發現在解析出的href種,存在一些不和諧的因素,比如JavaScript的出現,比如其他域名的出現,或者有些讀者說的,url有重複。實際上,這是對於我們的FreeBuf站來說,但是對於網際網路上的各種複雜環境來說,上面的考慮是完全不夠的。關於這一點我們稍後再做討論。
但是筆者並不計劃就用這個方法來把我們的問題處理完全。因為我們有更優雅的解決方案。
0×05 更優雅的解決方案
當然我說的時BeautifulSoup,為什麼選用這個模組呢?筆者私認為這個模組解析html非常專業,這裡簡稱bs4,讀過bs4的讀者都很清楚。實際上beautifulsoup並不只是簡單的解析html文件,實際上裡面大有玄機:五種解析器自動選擇或者手動指定,每個解析器的偏重方向都不一樣,有的偏重速度,有的偏重正確率。自動識別html文件的編碼,並且給出非常完美的解決方案,支援css篩選,各種引數的方便使用。
BeautifulSoup的一般使用步驟:
1. 匯入beatifulsoup庫 :from bs4 import BeautifulSoup
2. 傳入資料,建立物件: soup = BeautifulSoup(data),
3. 操作soup,完成需求解析。
下面我們來看具體的程式碼例項:
from bs4 import BeautifulSoup
import urllib
import re
web =urllib.urlopen("http://freebuf.com/")
soup = BeautifulSoup(web.read())
tags_a =soup.findAll(name="a",attrs={'href':re.compile("^https?://")})
for tag_a in tags_a:
printtag_a["href"]
這一段與sgmllib的第二短程式碼相同功能,但寫起來就更加的優雅。然後還引入了正規表示式,稍微過濾下連結的表示式,過濾掉了JavaScript字樣,顯然看起來簡煉多了:
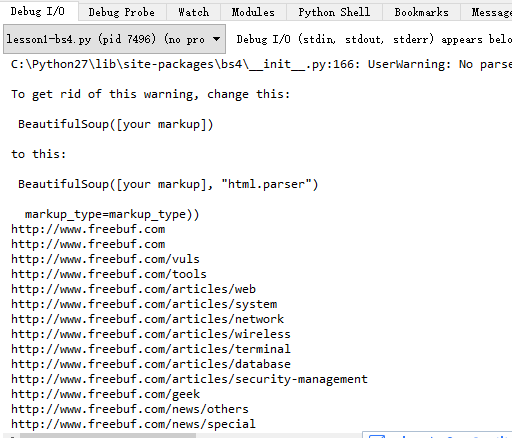
簡單解釋一下上面的warning:
UserWarning: No parser was explicitlyspecified, so I’m using the best available HTML parser for this system(“html.parser”). This usually isn’t a problem, but if you run thiscode on another system, or in a different virtual environment, it may use adifferent parser and behave differently.
To get rid of this warning, change this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup],”html.parser”)
上面的內容是說:沒有特別指明解析器,bs4使用了它認為最好的解析器html.parser,這一般不會出問題,但是如果你在不同的環境下執行,可能解析器是不一樣的。要移除這個warning可以修改你的beautifulsoup選項改成BeautifulSoup(data, “html.parser”)
這個warning表明了bs4的自動選擇解析器來解析的特性。
0×06 url和合法性判斷
url與uri其實是一個東西,如果但是我們更多的不提uri,那麼我們來說一下關於url的處理:如果說像我們一開始那樣做的話,我們手動,或者通過正則去分析每一個url,我們要考慮url的各種結構,比如下面這些例子:
path?ss=1#arch
http://freebuf.com/geek
?ss=1
path/me
javascript:void(0)
/freebuf.com/s/s/s/
sssfadea://ssss.ss
path?ss=1&s=1
ftp://freeme.com/ss/s/s
path?ss=1
#arch
//freebuf.com/s/s/s/
https://freebuf.com:443/geek?id=1#sid
//freebuf.com/s/s/s
我們大概就是要處理這麼多的不同形式的url,這些都是在網頁上非常有可能出現的url,那麼,那麼我們怎麼判斷這些的合法性呢?
先以//分開,左邊時協議+‘:’,右邊到第一個’/’是域名,域名後面時路徑,?後面時引數,#後面是錨點。
這麼分析來的話寫程式碼判斷應該不是一個特別困難的事情,但是我們並沒有必要每次都去寫程式碼解決這個問題啊,畢竟我們在使用python,這些事情並不需要自己來做,
其實我個人覺得這個要得益於python強大的模組:urlparser,這個模組就是把我們上面的url分析思路做了實現,用法也是pythonic:
import urlparse
url = set()
url.add('javascript:void(0)')
url.add('http://freebuf.com/geek')
url.add('https://freebuf.com:443/geek?id=1#sid')
url.add('ftp://freeme.com/ss/s/s')
url.add('sssfadea://ssss.ss')
url.add('//freebuf.com/s/s/s')
url.add('/freebuf.com/s/s/s/')
url.add('//freebuf.com/s/s/s/')
url.add('path/me')
url.add('path?ss=1')
url.add('path?ss=1&s=1')
url.add('path?ss=1#arch')
url.add('?ss=1')
url.add('#arch')
for item in url:
print item
o= urlparse.urlparse(item)
print o
print
然後執行程式碼,我們可以看一下具體的解析結果:
import urlparse
url = set()
url.add('javascript:void(0)')
url.add('http://freebuf.com/geek')
url.add('https://freebuf.com:443/geek?id=1#sid')
url.add('ftp://freeme.com/ss/s/s')
url.add('sssfadea://ssss.ss')
url.add('//freebuf.com/s/s/s')
url.add('/freebuf.com/s/s/s/')
url.add('//freebuf.com/s/s/s/')
url.add('path/me')
url.add('path?ss=1')
url.add('path?ss=1&s=1')
url.add('path?ss=1#arch')
url.add('?ss=1')
url.add('#arch')
for item in url:
print item
o= urlparse.urlparse(item)
print o
printpath?ss=1#arch
ParseResult(scheme='', netloc='',path='path', params='', query='ss=1', fragment='arch')
http://freebuf.com/geek
ParseResult(scheme='http',netloc='freebuf.com', path='/geek', params='', query='', fragment='')
?ss=1
ParseResult(scheme='', netloc='', path='',params='', query='ss=1', fragment='')
path/me
ParseResult(scheme='', netloc='',path='path/me', params='', query='', fragment='')
javascript:void(0)
ParseResult(scheme='javascript', netloc='',path='void(0)', params='', query='', fragment='')
/freebuf.com/s/s/s/
ParseResult(scheme='', netloc='', path='/freebuf.com/s/s/s/',params='', query='', fragment='')
sssfadea://ssss.ss
ParseResult(scheme='sssfadea',netloc='ssss.ss', path='', params='', query='', fragment='')
path?ss=1&s=1
ParseResult(scheme='', netloc='',path='path', params='', query='ss=1&s=1', fragment='')
ftp://freeme.com/ss/s/s
ParseResult(scheme='ftp',netloc='freeme.com', path='/ss/s/s', params='', query='', fragment='')
path?ss=1
ParseResult(scheme='', netloc='',path='path', params='', query='ss=1', fragment='')
#arch
ParseResult(scheme='', netloc='', path='',params='', query='', fragment='arch')
//freebuf.com/s/s/s/
ParseResult(scheme='',netloc='freebuf.com', path='/s/s/s/', params='', query='', fragment='')
https://freebuf.com:443/geek?id=1#sid
ParseResult(scheme='https',netloc='freebuf.com:443', path='/geek', params='', query='id=1',fragment='sid')
//freebuf.com/s/s/s
ParseResult(scheme='',netloc='freebuf.com', path='/s/s/s', params='', query='', fragment='')
在urlparser返回的物件中我們可以直接以索引的方式拿到每一個引數的值。那麼我們這裡就有索引表了:
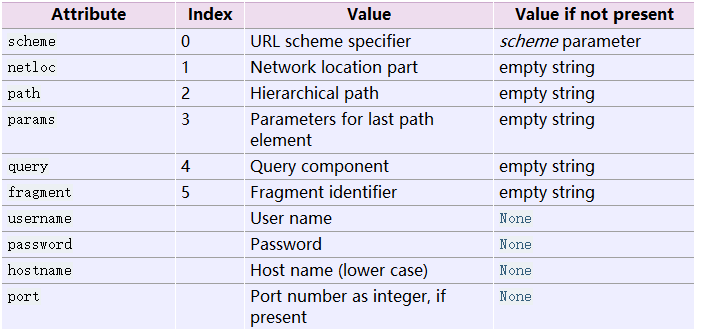
這張表的用法,
o = urlparse.urlparse(url)
o[0]表示scheme
o[1]表示netloc
……
以此類推。
我們發現:
如果scheme和netloc都同時為空的話,該url可能是當前url+path
如果scheme不為空但是netloc為空的話,該url不合法
如果scheme為空但是netloc不為空的話,不一定不合法,要具體分析,一般情況下是http
如果只存在fragment或者query的話,該url為當前的url+query[+fragment]
……
那麼根據上面的規則,我們基本可以把無關的url或者不是url排除掉,或者恢復完整的url
0×07 總結與預告
本章中我們一起探究了一個簡單爬蟲的實現,然後稍微討論了一下如何處理頁面的url。相信讀者讀完本文的時候已經有了一定的對爬蟲的基礎認識,但是要知道,只瞭解到這種程度還不能說了解爬蟲,這只是冰山一角。
在下一節中,我們將學到下面的知識:
1、爬蟲道德與爬蟲的理論知識
2、sitemap爬蟲
3、簡單web資料處理
相關文章
- Python爬蟲五大零基礎入門教程Python爬蟲
- 爬蟲入門基礎-Python爬蟲Python
- 零基礎自學用Python 3開發網路爬蟲(一)Python爬蟲
- Python爬蟲入門(2):爬蟲基礎瞭解Python爬蟲
- 爬蟲開發知識入門基礎(1)爬蟲
- 零基礎自學用Python 3開發網路爬蟲(四): 登入Python爬蟲
- 零基礎入門學習Python爬蟲必備的知識點!Python爬蟲
- Python爬蟲入門Python爬蟲
- 不踩坑的Python爬蟲:Python爬蟲開發與專案實戰,從爬蟲入門 PythonPython爬蟲
- Python3爬蟲入門(一)Python爬蟲
- 爬蟲(1) - 爬蟲基礎入門理論篇爬蟲
- 如何入門 Python 爬蟲?Python爬蟲
- python-爬蟲入門Python爬蟲
- 【爬蟲】python爬蟲從入門到放棄爬蟲Python
- Python超簡單超基礎的免費小說爬蟲!爬蟲入門從這開始!Python爬蟲
- 什麼是Python爬蟲?python爬蟲入門難嗎?Python爬蟲
- Python爬蟲開發與專案實戰——基礎爬蟲分析Python爬蟲
- python3 爬蟲入門Python爬蟲
- Python爬蟲入門指導Python爬蟲
- Python爬蟲入門專案Python爬蟲
- Python 爬蟲零基礎教程(1):爬單個圖片Python爬蟲
- Python爬蟲超詳細講解(零基礎入門,老年人都看的懂)Python爬蟲
- 爬蟲入門爬蟲
- Python爬蟲入門,8個常用爬蟲技巧盤點Python爬蟲
- Python零基礎,如何快速學爬蟲技術Python爬蟲
- Python網路爬蟲實戰(一)快速入門Python爬蟲
- Python零基礎爬蟲教學(實戰案例手把手Python爬蟲教學)Python爬蟲
- 為什麼零基礎會入不了Python爬蟲的門?8個常用技巧助你一臂之力Python爬蟲
- python爬蟲 之 BeautifulSoup庫入門Python爬蟲
- Python爬蟲入門(1):綜述Python爬蟲
- 我的爬蟲入門書 —— 《Python3網路爬蟲開發實戰(第二版)》爬蟲Python
- 為什麼學習python及爬蟲,Python爬蟲[入門篇]?Python爬蟲
- python3網路爬蟲開發實戰_Python 3開發網路爬蟲(一)Python爬蟲
- Python3網路爬蟲快速入門實戰解析(一小時入門 Python 3 網路爬蟲)Python爬蟲
- 十四個爬蟲專案爬蟲超詳細講解(零基礎入門,老年人都看的懂)爬蟲
- Python零基礎入門看完這一篇就夠了:零基礎入門筆記Python筆記
- PYTHON系列-從零開始的爬蟲入門指南Python爬蟲
- Python爬蟲入門【5】:27270圖片爬取Python爬蟲