異常點/離群點檢測演算法——LOF
區域性異常因子演算法-Local Outlier Factor(LOF)
在資料探勘方面,經常需要在做特徵工程和模型訓練之前對資料進行清洗,剔除無效資料和異常資料。異常檢測也是資料探勘的一個方向,用於反作弊、偽基站、金融詐騙等領域。
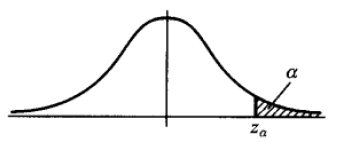
異常檢測方法,針對不同的資料形式,有不同的實現方法。常用的有基於分佈的方法,在上、下α分位點之外的值認為是異常值(例如圖1),對於屬性值常用此類方法。基於距離的方法,適用於二維或高維座標體系內異常點的判別,例如二維平面座標或經緯度空間座標下異常點識別,可用此類方法。
這次要介紹一下一種基於距離的異常檢測演算法,區域性異常因子LOF演算法(Local Outlier Factor)。
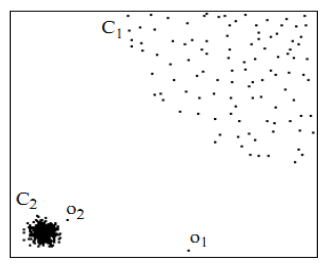
用視覺直觀的感受一下,如圖2,對於C1集合的點,整體間距,密度,分散情況較為均勻一致,可以認為是同一簇;對於C2集合的點,同樣可認為是一簇。o1、o2點相對孤立,可以認為是異常點或離散點。現在的問題是,如何實現演算法的通用性,可以滿足C1和C2這種密度分散情況迥異的集合的異常點識別。LOF可以實現我們的目標。
下面介紹LOF演算法的相關定義:
1)
d(p, o)
:兩點p和o之間的距離; 2) k-distance:第k距離
對於點p的第k距離
d_{k}(p)
定義如下: d_{k}(p) = d(p, o)
,並且滿足: a) 在集合中至少有不包括p在內的
k
個點o^,\in C\{x \neq p\}
, 滿足d(p, o^,) \le d(p, o)
; b) 在集合中最多有不包括p在內的
k-1
個點o^,\in C\{x \neq p\}
,滿足d(p, o^,) \lt d(p, o)
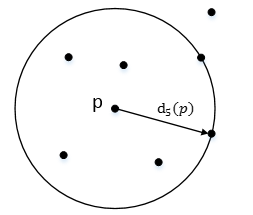
; p的第k距離,也就是距離p第k遠的點的距離,不包括p,如圖3。
3) k-distance neighborhood of p:第k距離鄰域
點p的第k距離鄰域
N_k(p)
,就是p的第k距離即以內的所有點,包括第k距離。 因此p的第k鄰域點的個數
|N_k(p)| \ge k
。 4) reach-distance:可達距離
點o到點p的第k可達距離定義為:
reach-distance_k(p, o) = max\{k-distance(o), d(p, o)\}
也就是,點o到點p的第k可達距離,至少是o的第k距離,或者為o、p間的真實距離。
這也意味著,離點o最近的k個點,o到它們的可達距離被認為相等,且都等於
d_{k}(o)
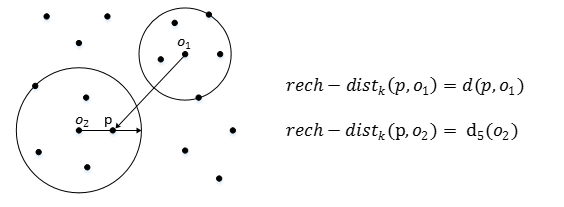
。 如圖4,
o_1
到p的第5可達距離為d(p,o_1)
,o_2
到p的第5可達距離為d_5(o_2)
。 
5) local reachability density:區域性可達密度
點p的區域性可達密度表示為:
lrd_k(p) = 1 / (\frac{\sum_{o \in N_{k}(p)} reach-dist_k(p,o)}{|N_{k}(p)|})
表示點p的第k鄰域內點到p的平均可達距離的倒數。
注意,是p的鄰域點
N_k(p)
到p的可達距離,不是p到N_k(p)
的可達距離,一定要弄清楚關係。並且,如果有重複點,那麼分母的可達距離之和有可能為0,則會導致lrd變為無限大,下面還會繼續提到這一點。 這個值的含義可以這樣理解,首先這代表一個密度,密度越高,我們認為越可能屬於同一簇,密度越低,越可能是離群點。如果p和周圍鄰域點是同一簇,那麼可達距離越可能為較小的
d_{k}(o)
,導致可達距離之和較小,密度值較高;如果p和周圍鄰居點較遠,那麼可達距離可能都會取較大值d(p, o)
,導致密度較小,越可能是離群點。 6) local outlier factor:區域性離群因子
點p的區域性離群因子表示為:
LOF_k(p)=\frac{\sum_{o \in N_{k}(p)} \frac{lrd_k(o)}{lrd_k(p)}}{|N_k(p)|} = \frac{\sum_{o \in N_k(p)} lrd_k(o)}{|N_k(p)|} / lrd_k(p)
表示點p的鄰域點
N_k(p)
的區域性可達密度與點p的區域性可達密度之比的平均數。 如果這個比值越接近1,說明p的其鄰域點密度差不多,p可能和鄰域同屬一簇;如果這個比值越小於1,說明p的密度高於其鄰域點密度,p為密集點;如果這個比值越大於1,說明p的密度小於其鄰域點密度,p越可能是異常點。
現在概念定義已經介紹完了,現在再回過頭來看一下lof的思想,主要是通過比較每個點p和其鄰域點的密度來判斷該點是否為異常點,如果點p的密度越低,越可能被認定是異常點。至於密度,是通過點之間的距離來計算的,點之間距離越遠,密度越低,距離越近,密度越高,完全符合我們的理解。而且,因為lof對密度的是通過點的第k鄰域來計算,而不是全域性計算,因此得名為“區域性”異常因子,這樣,對於圖1的兩種資料集C1和C2,lof完全可以正確處理,而不會因為資料密度分散情況不同而錯誤的將正常點判定為異常點。
演算法思想已經講完了,現在進入乾貨環節,亮程式碼。
給一個python實現的lof演算法:
https://github.com/damjankuznar/pylof
再給一下我fork之後的程式碼:
https://github.com/wangyibo360/pylof
有區別:
上面提到了,對於重複點區域性可達密度可能會變為無限大的問題,我改的程式碼對這個問題做了處理,如果有重複點方面的場景,可以用我的程式碼,原始碼這塊有bug沒有fix,而且好像程式碼主人無蹤影了,提的pull也沒人管。。。
相關文章
- Python機器學習筆記:異常點檢測演算法——LOF(Local Outiler Factor)Python機器學習筆記演算法
- 異常點檢測演算法小結演算法
- 吳恩達機器學習筆記 —— 16 異常點檢測吳恩達機器學習筆記
- 異常檢測
- 機器學習-異常檢測演算法(二):LocalOutlierFactor機器學習演算法
- 序列異常檢測
- [譯] 時間序列異常檢測演算法演算法
- Fast角點檢測演算法AST演算法
- 白話異常檢測演算法Isolation Forest演算法REST
- 蟻群演算法的特點演算法
- 華為AGC提包檢測報告:檢測異常GC
- openCV - 角點檢測快速演算法 FASTOpenCV演算法AST
- 目標檢測演算法盤點(最全)演算法
- 【機器學習】李宏毅——Anomaly Detection(異常檢測)機器學習
- 異常聲音檢測總結
- OpenCV計算機視覺學習(13)——影像特徵點檢測(Harris角點檢測,sift演算法)OpenCV計算機視覺特徵演算法
- Java常見知識點彙總(⑨)——異常Java
- 【OpenCV】角點檢測:Harris角點及Shi-Tomasi角點檢測OpenCV
- Harris角點檢測
- java異常知識點彙總Java
- 準實時異常檢測系統
- C++檢測異常assert()函式C++函式
- AI賦能一鍵自動檢測:頁面異常、控制元件異常、文字異常AI控制元件
- 影像區域性特徵點檢測演算法綜述特徵演算法
- opencv關鍵點檢測OpenCV
- K8S節點異常怎麼辦?TKE"節點健康檢查和自愈"來幫忙K8S
- oracle ckpt檢查點型別(增量及常規完全檢查點)checkpointOracle型別
- 異常處理及其相關知識點
- 2.Harris角點檢測
- 區域性異常因子(Local Outlier Factor, LOF)演算法詳解及實驗演算法
- [譯] 時間順序的價格異常檢測
- 表空間檢測異常的問題診斷
- 異常檢測(Anomaly Detection)方法與Python實現Python
- iOS 人臉關鍵點檢測iOS
- OpenCV探索之路(十五):角點檢測OpenCV
- PFLD:簡單、快速、超高精度人臉特徵點檢測演算法特徵演算法
- PFLD:簡單高效的實用人臉關鍵點檢測演算法演算法
- 軟體為什麼要做異常測試?測試員必知的22個測試點總結!