Java中將記憶體的控制交給JVM來實現,方便了JAVA程式猿,當然犧牲了一部分效率,不過總體來看是值得的。那麼JVM中是如何設計GC的呢,本文從幾個問題入手,然後分析了一下設計思路,如果有理解錯誤的地方,請批評指正!主要參考了《深入理解JAVA虛擬機器》這本書,圖是盜來的,圖的內容和書上一樣。
在JVM的記憶體模型中,堆記憶體是JAVA記憶體區域中最大的一部分,GC主要就是發生在堆中,用來回收那些無用的物件。這樣直接就引申出了第一個問題:什麼樣的物件需要被回收?判斷條件是什麼?如何判斷?
先談談什麼物件需要被回收,OK,我們自己想一想,肯定是沒用的物件需要被回收,對吧?那麼如何判斷哪些物件還有用,哪些沒用了呢?一個物件被建立,如果被引用了,那這個物件肯定是有用的對吧,如果引用全失效了,那就是沒用的物件了,需要被回收。基於這個思想,引用計數法誕生了。
- 引用計數演算法:這個非常容易理解,給每個物件新增一個引用計數器,物件每被引用一次,引用計數器就+1,引用失效時就-1。那麼判斷一個物件是否有用的條件就變成了對這個計數器值得判斷了,如果為0,那麼被回收,如果為>0,那麼保留。但是這種方式會產生一個問題,就是物件之間的迴圈引用無法被識別,即使這兩個物件不能被訪問,但是它們之間互相引用著對方,故而計數器肯定>0,那麼就不能被回收。JVM中並沒有使用引用計數演算法,而是使用了根搜尋演算法。
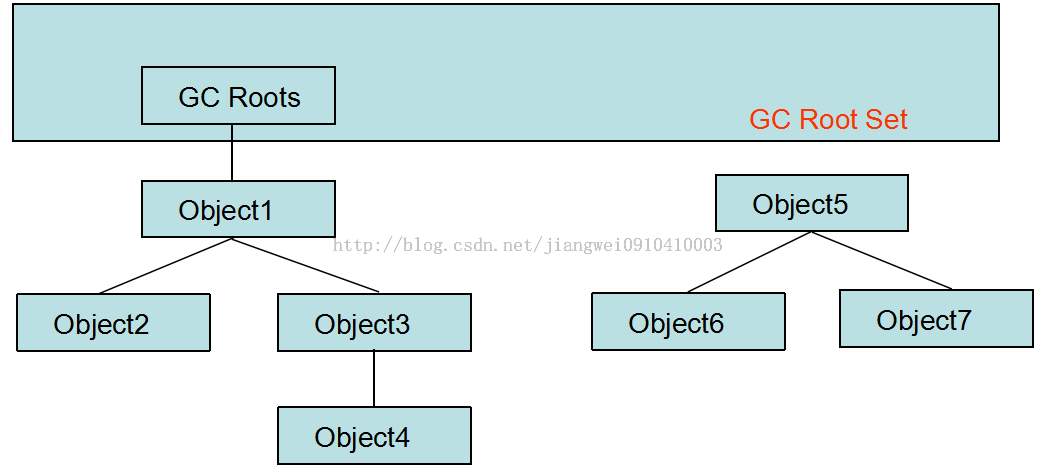
- 根搜尋演算法:這個演算法也不難理解,通過條件,選擇一系列的物件成為“GC Roots"物件,然後將”GC Roots"物件作為起始點開始向下搜尋,搜尋所有走過的路徑成為“引用鏈”。在這個引用鏈上的物件就保留,而如果一個或多個互相引用的物件不在這個引用鏈上,或者說物件到“GC Roots"不可達,那麼這些就是無用的物件,都需要被回收。
注:Java語言中,可作為GC Roots的物件包括下面幾種:
1) 虛擬機器棧(棧幀中的本地變數表)中引用的物件
2) 方法區中類靜態屬性引用的物件
3) 方法區中常量引用的物件
4) 本地方法棧中JNI(即一般說的Native方法)引用的物件
既然根搜尋演算法需要考慮到物件之間的引用,那麼就要說一下JAVA中物件的引用型別了:
從JDK1.2之後,Java對引用的概念進行了擴充,將引用分為強引用,軟引用,弱引用,虛引用,這四種引用的強度依次減弱
1) 強引用就是指在程式程式碼之中普遍存在的,類似 “Object obj = new Object()” 這類的引用,只要強引用還存在,垃圾回收器永遠不會回收被引用的物件。我們也正是利用這個原理來重現了OOM異常。
2) 軟引用(SoftReference類)是用來描述一些還有用但並非需要的物件,對於軟引用關聯著的物件,在系統將要發生記憶體異常之前,將會把這些物件列進回收範圍之中進行第二次回收,如果這次回收還沒有足夠的記憶體,才會丟擲記憶體異常
3) 弱引用(WeakReference類)也是用來描述非必需物件的,被弱引用關聯的物件只能生存到下一次GC發生之前,當垃圾收集器工作時,無論當前記憶體釋放足夠,都會回收掉只被弱引用關聯的物件
4) 虛引用(PhantomReference類)也稱為幽靈引用或者幻影引用,它是最弱的一種引用關係,一個物件是否有虛引用的存在,完全不會對其生存時間構成影響,也無法通過虛引用來取得一個物件例項,對一個物件設定虛引用關聯的唯一目的就是能在這個物件被收集器回收時收到一個系統通知
那麼上述內容看完之後想必都知道了什麼樣的物件會被GC了吧,那麼JVM又是通過什麼方式來回收這些記憶體的呢?下面就需要了解一下垃圾的回收演算法了。
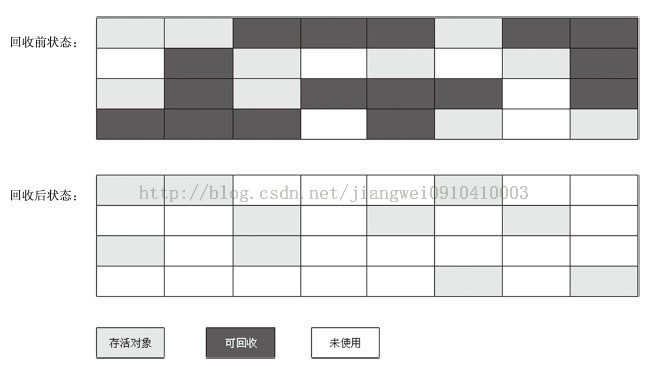
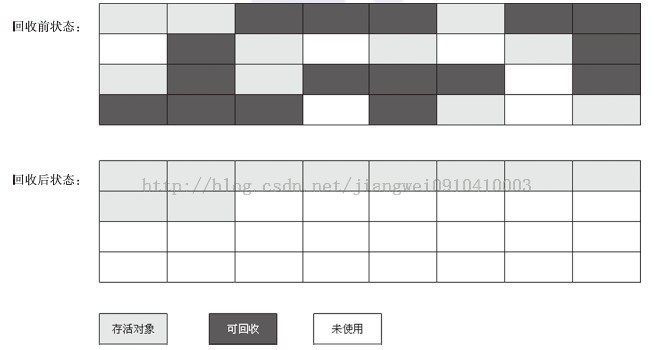
想到這裡,就需要分析一下了。一個個的標記然後清除,效率高嗎?當然不。看看下圖的標記-清除演算法的示意圖,可以發現,標記-清除之後會產生大量的記憶體碎片,如果碎片太多,當程式執行沒有足夠連續的記憶體空間來存放大物件的時候,就會不得不提前觸發一次GC。概括來說就是有兩個缺點:效率不高;記憶體碎片可能導致提前發生GC。
學習演算法的童鞋應該都很清楚,效率是很重要的,有時候需要使用空間來換時間提高效率,那麼就需要了解一下第二種回收演算法了——複製演算法。
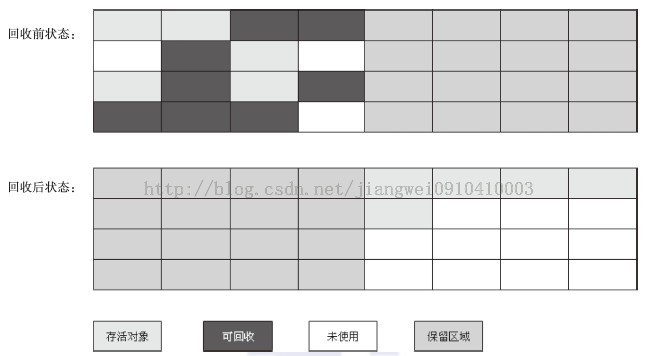
複製演算法呢?它的思想就是空間換時間,將記憶體容量劃分成相等的兩塊,當這一塊的記憶體用完了,就將還存活的記憶體複製到另一塊上,然後再把使用過的記憶體空間一次性清理乾淨。這樣每次都是對其中的一塊的記憶體進行回收,也就不需要考慮記憶體碎片等複雜情況了,只需要移動堆頂指標,然後按照順序分配即可,實現簡單,執行高效。但是缺點也很明顯:記憶體變成一半了.......下圖就是複製演算法的示意圖:
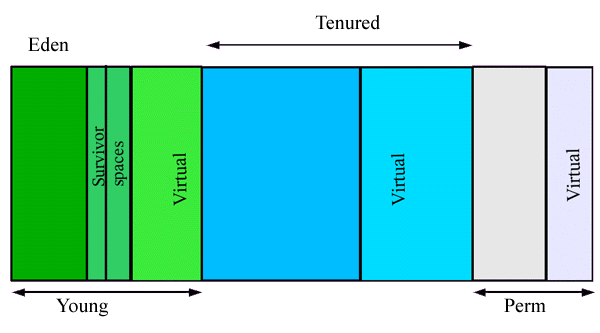
我們知道,在JVM中堆記憶體的新生代(new )中的物件存活率較低,採用複製演算法每次需要複製的物件也不是很多,效率較高,空間換時間值得的。現在的商業虛擬機器都是採用複製演算法來回收新生代,IBM的專門研究表明:新生代中物件98%是朝生夕死,所以並不需要按照1:1的比例來劃分空間來實現複製演算法,而是將記憶體分為一塊較大的Eden空間和兩塊較小的Survivor空間,每次使用Eden空間和其中一個Survivor空間。當發生GC的時候,將Eden空間和Survivor空間中還存活的物件拷貝到另一個沒使用的Survivor空間中,然後再清理掉Eden和剛剛使用的Survivor空間。Hotspot虛擬機器預設Eden和Survivor的大小比例是8:1,也就是新生代每次可以使用的記憶體空間是整個新生代的90%,只有10%的空間會被浪費。
OK,通過上述的分析,我們知道了在JVM中對於新生帶的垃圾回收使用的複製演算法(此時發生的GC成為young gc),效率高,我們也就只犧牲了10%的記憶體空間,挺不錯的。請注意這裡提到的young gc,後面會提到full gc。但是雖然IBM研究表明一般情況下有98%的物件是朝生夕死,需要回收的,但是不能保證每次回收的時候物件的存活率都低於10%啊,是不是?一旦超過了10%,那麼空閒的survivor空間就不夠用了,此時就必須依賴老年代的空間來進行分配擔保(就相當於A找B借錢,C替A做擔保,保證如果A換不起就自己來還,C就是擔保人,對映到記憶體中老年代所佔記憶體就是擔保人)。如果空閒的Survivor空間無法存放上次GC之後的存活物件,那麼這些物件就會通過分配擔保機制進入老年代。
老年代呢,裡面儲存的都是生存週期較長的物件(老年代裡面的物件都是經過了新生代,然後多次存活下來的物件),而複製演算法在應對這種存活率極高的記憶體區域的物件回收時,需要執行較多的複製操作,效率將會變低。關鍵的還是如果不想浪費50%的空間,那麼就需要分配擔保機制(參考新生代的設計),但是並沒有額外的空間來擔保了。所以對於老年代的特性,有人提出了一種“標記-整理演算法”,看到這裡肯定就想到了前面提到的“標記-清除演算法“了,OK,這兩個演算法標記的過程都是一樣的,就在於”標記-整理演算法”不是直接對可回收物件進行清理,而是讓所有存活的物件都向一端移動,然後直接清理掉端邊界以外的記憶體,示意圖如下圖所示。
很明顯,這種”標記-整理演算法“的效率不高,所以如果老年代發生GC,那麼效率也就不高了,並且一旦老年代發生GC,那麼發生的必然是Full GC ,Full GC 會同時對老年代和新生代進行GC操作,順便也會回收一下perm gen中的記憶體,所以相比較young gc來說很慢,我們在JVM調優的時候需要避免JVM頻繁發生full gc。full gc的速度比young gc要慢10倍。
通過上述的分析呢,就知道了對於堆中的新生代和老年代會採用不同的垃圾回收演算法來回收“死亡”的物件,這種分代回收物件的方法稱為“分代收集演算法”。這個分代收集演算法根據各個年代的特點採用適當的收集演算法。在新生代中,每次GC的時候都發現大批的物件死去,只有少量存活,自然選用複製演算法;而對於老年代這種存活率高、沒有額外擔保空間的,就必須使用“標記-清除演算法”或者“標記-整理演算法“了。
GC設計的理論基礎就是這些了,其實原理還是比較容易理解的。GC的具體實現就是垃圾收集器,目前尚沒有一個垃圾收集器是完美的,需要配合使用。下面插上一副堆記憶體劃分圖。
注:本文寫的比較片面,如果想更深入瞭解,推薦這篇博文:http://jbutton.iteye.com/blog/1569746