KeepAlive既熟悉又陌生,踩過坑的同學都知道痛。一線運維工程師踩坑之後對於KeepAlive的總結,你不應該錯過!
最近工作中遇到一個問題,想把它記錄下來,場景是這樣的:
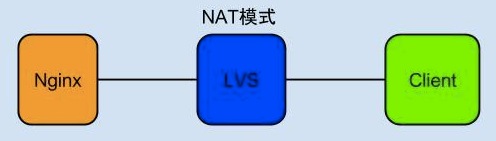
從上圖可以看出,使用者通過Client訪問的是LVS的VIP, VIP後端掛載的RealServer是Nginx伺服器。 Client可以是瀏覽器也可以是一個客戶端程式。一般情況下,這種架構不會出現問題,但是如果Client端把請求傳送給Nginx,Nginx的後端需要一段時間才能返回結果,超過1分30秒就會有問題,使用LVS作為負載均衡裝置看到的現象就是1分30秒之後, Client和Nginx連結被斷開,沒有資料返回。
原因是LVS預設保持TCP的Session為90s,超過90s沒有TCP報文在連結上傳輸,LVS就會給兩端傳送RESET報文斷開連結。LVS這麼做的原因相信大家都知道一二,我所知道的原因主要有兩點:
1. 節省負載均衡裝置資源,每一個TCP/UDP的連結都會在負載均衡裝置上建立一個Session的結構, 連結如果一直不斷開,這種Session結構資訊最終會消耗掉所有的資源,所以必須釋放掉。
2.另外釋放掉能保護後端的資源,如果攻擊者通過空連結,連結到Nginx上,如果Nginx沒有做合適 的保護,Nginx會因為連結數過多而無法提供服務。
這種問題不只是在LVS上有,之前在商用負載均衡裝置F5上遇到過同樣的問題,F5的session斷開方式和LVS有點區別,F5不會主動傳送RESET給連結的兩端,session消失之後,當連結中一方再次傳送報文時會接收到F5的RESET, 之後的現象是再次傳送報文的一端TCP連結狀態已經斷開,而另外一端卻還是ESTABLISH狀態。
知道是負載均衡裝置原因之後,第一反應就是通過開啟KeepAlive來解決。到此這個問題應該是結束了,但是我發現過一段時間總又有人提起KeepAlive的問題,甚至發現由於KeepAlive的理解不正確浪費了很多資源,原本能使用LVS的應用放在了公網下沉區,或者換成了商用F5裝置(F5裝置的Session斷開時間要長一點,預設應該是5分鐘)。
所以我決定把我知道的KeepAlive知識點寫篇部落格分享出來。
為什麼要有KeepAlive?
在談KeepAlive之前,我們先來了解下簡單TCP知識(知識很簡單,高手直接忽略)。首先要明確的是在TCP層是沒有“請求”一說的,經常聽到在TCP層傳送一個請求,這種說法是錯誤的。
TCP是一種通訊的方式,“請求”一詞是事務上的概念,HTTP協議是一種事務協議,如果說傳送一個HTTP請求,這種說法就沒有問題。也經常聽到面試官反饋有些面試運維的同學,基本的TCP三次握手的概念不清楚,面試官問TCP是如何建立連結,面試者上來就說,假如我是客戶端我傳送一個請求給服務端,服務端傳送一個請求給我。。。
這種一聽就知道對TCP基本概念不清楚。下面是我通過wireshark抓取的一個TCP建立握手的過程。(命令列基本上用TCPdump,後面我們還會用這張圖說明問題):

現在我看只要看前3行,這就是TCP三次握手的完整建立過程,第一個報文SYN從發起方發出,第二個報文SYN,ACK是從被連線方發出,第三個報文ACK確認對方的SYN,ACK已經收到,如下圖:
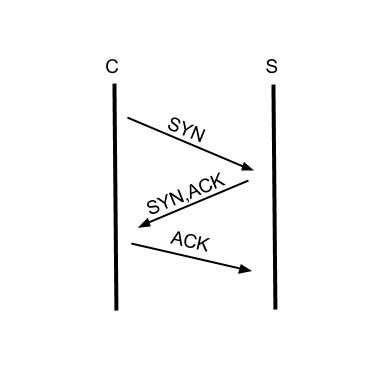
但是資料實際上並沒有傳輸,請求是有資料的,第四個報文才是資料傳輸開始的過程,細心的讀者應該能夠發現wireshark把第四個報文解析成HTTP協議,HTTP協議的GET方法和URI也解析出來,所以說TCP層是沒有請求的概念,HTTP協議是事務性協議才有請求的概念,TCP報文承載HTTP協議的請求(Request)和響應(Response)。
現在才是開始說明為什麼要有KeepAlive。連結建立之後,如果應用程式或者上層協議一直不傳送資料,或者隔很長時間才傳送一次資料,當連結很久沒有資料包文傳輸時如何去確定對方還線上,到底是掉線了還是確實沒有資料傳輸,連結還需不需要保持,這種情況在TCP協議設計中是需要考慮到的。
TCP協議通過一種巧妙的方式去解決這個問題,當超過一段時間之後,TCP自動傳送一個資料為空的報文給對方,如果對方迴應了這個報文,說明對方還線上,連結可以繼續保持,如果對方沒有報文返回,並且重試了多次之後則認為連結丟失,沒有必要保持連結。
如何開啟KeepAlive?
KeepAlive並不是預設開啟的,在Linux系統上沒有一個全域性的選項去開啟TCP的KeepAlive。需要開啟KeepAlive的應用必須在TCP的socket中單獨開啟。Linux Kernel有三個選項影響到KeepAlive的行為:
1.net.ipv4.tcpkeepaliveintvl = 75
2.net.ipv4.tcpkeepaliveprobes = 9
3.net.ipv4.tcpkeepalivetime = 7200
tcpkeepalivetime的單位是秒,表示TCP連結在多少秒之後沒有資料包文傳輸啟動探測報文; tcpkeepaliveintvl單位是也秒,表示前一個探測報文和後一個探測報文之間的時間間隔,tcpkeepaliveprobes表示探測的次數。
TCP socket也有三個選項和核心對應,通過setsockopt系統呼叫針對單獨的socket進行設定:
TCPKEEPCNT: 覆蓋 tcpkeepaliveprobes
TCPKEEPIDLE: 覆蓋 tcpkeepalivetime
TCPKEEPINTVL: 覆蓋 tcpkeepalive_intvl
舉個例子,以我的系統預設設定為例,kernel預設設定的tcpkeepalivetime是7200s, 如果我在應用程式中針對socket開啟了KeepAlive,然後設定的TCP_KEEPIDLE為60,那麼TCP協議棧在發現TCP連結空閒了60s沒有資料傳輸的時候就會傳送第一個探測報文。
TCP KeepAlive和HTTP的Keep-Alive是一樣的嗎?
估計很多人乍看下這個問題才發現其實經常說的KeepAlive不是這麼回事,實際上在沒有特指是TCP還是HTTP層的KeepAlive,不能混為一談。TCP的KeepAlive和HTTP的Keep-Alive是完全不同的概念。
TCP層的KeepAlive上面已經解釋過了。 HTTP層的Keep-Alive是什麼概念呢? 在講述TCP連結建立的時候,我畫了一張三次握手的示意圖,TCP在建立連結之後, HTTP協議使用TCP傳輸HTTP協議的請求(Request)和響應(Response)資料,一次完整的HTTP事務如下圖:
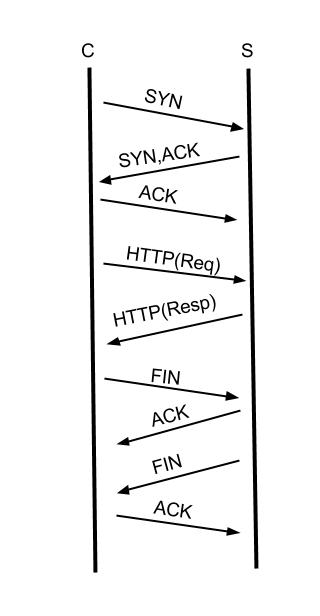
各位看官請注意,這張圖我簡化了HTTP(Req)和HTTP(Resp),實際上的請求和響應需要多個TCP報文。
從圖中可以發現一個完整的HTTP事務,有連結的建立,請求的傳送,響應接收,斷開連結這四個過程,早期通過HTTP協議傳輸的資料以文字為主,一個請求可能就把所有要返回的資料取到,但是,現在要展現一張完整的頁面需要很多個請求才能完成,如圖片,JS,CSS等,如果每一個HTTP請求都需要新建並斷開一個TCP,這個開銷是完全沒有必要的。
開啟HTTP Keep-Alive之後,能複用已有的TCP連結,當前一個請求已經響應完畢,伺服器端沒有立即關閉TCP連結,而是等待一段時間接收瀏覽器端可能傳送過來的第二個請求,通常瀏覽器在第一個請求返回之後會立即傳送第二個請求,如果某一時刻只能有一個連結,同一個TCP連結處理的請求越多,開啟KeepAlive能節省的TCP建立和關閉的消耗就越多。
當然通常會啟用多個連結去從伺服器器上請求資源,但是開啟了Keep-Alive之後,仍然能加快資源的載入速度。HTTP/1.1之後預設開啟Keep-Alive, 在HTTP的頭域中增加Connection選項。當設定為Connection:keep-alive表示開啟,設定為Connection:close表示關閉。實際上HTTP的KeepAlive寫法是Keep-Alive,跟TCP的KeepAlive寫法上也有不同。所以TCP KeepAlive和HTTP的Keep-Alive不是同一回事情。
Nginx的TCP KeepAlive如何設定?
開篇提到我最近遇到的問題,Client傳送一個請求到Nginx服務端,服務端需要經過一段時間的計算才會返回, 時間超過了LVS Session保持的90s,在服務端使用Tcpdump抓包,本地通過wireshark分析顯示的結果如第二副圖所示,第5條報文和最後一條報文之間的時間戳大概差了90s。
在確定是LVS的Session保持時間到期的問題之後,我開始在尋找Nginx的TCP KeepAlive如何設定,最先找到的選項是keepalivetimeout,從同事那裡得知keepalivetimeout的用法是當keepalivetimeout的值為0時表示關閉keepalive,當keepalivetimeout的值為一個正整數值時表示連結保持多少秒,於是把keepalivetimeout設定成75s,但是實際的測試結果表明並不生效。
顯然keepalivetimeout不能解決TCP層面的KeepAlive問題,實際上Nginx涉及到keepalive的選項還不少,Nginx通常的使用方式如下:
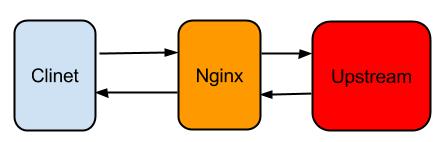
從TCP層面Nginx不僅要和Client關心KeepAlive,而且還要和Upstream關心KeepAlive, 同時從HTTP協議層面,Nginx需要和Client關心Keep-Alive,如果Upstream使用的HTTP協議,還要關心和Upstream的Keep-Alive,總而言之,還比較複雜。
所以搞清楚TCP層的KeepAlive和HTTP的Keep-Alive之後,就不會對於Nginx的KeepAlive設定錯。我當時解決這個問題時候不確定Nginx有配置TCP keepAlive的選項,於是我開啟Ngnix的原始碼,在原始碼裡面搜尋TCP_KEEPIDLE,相關的程式碼如下:
從程式碼的上下文我發現TCP KeepAlive可以配置,所以我接著查詢通過哪個選項配置,最後發現listen指令的so_keepalive選項能對TCP socket進行KeepAlive的配置。

以上三個引數只能使用一個,不能同時使用, 比如sokeepalive=on, sokeepalive=off或者sokeepalive=30s::(表示等待30s沒有資料包文傳送探測報文)。通過設定listen 80,sokeepalive=60s::之後成功解決Nginx在LVS保持長連結的問題,避免了使用其他高成本的方案。在商用負載裝置上如果遇到類似的問題同樣也可以通過這種方式解決。