PageRank演算法和HITS演算法
連結分析
在連結分析中有2個經典的演算法,1個是PageRank演算法,還有1個是HITS演算法,說白了,都是做連結分析的。具體是怎麼做呢,繼續往下看。
PageRank演算法
要說到PageRank演算法的作用,得先從搜尋引擎開始講起,PageRank演算法的由來正式與此相關。
搜尋引擎
最早時期的搜尋引擎的結構,無外乎2個核心步驟,step1:建立龐大的資料庫,step2:建立索引庫,用於指向具體的資料。然後就是使用者的查詢操作了,那怎麼查呢,一個很讓人會聯想到的方法就是通過關鍵字匹配的方法,例如我想輸入張三這個關鍵詞,那我就會在資源中查包含有張三這個詞語的文章,按照關鍵詞匹配方法,只要一篇文章中張三出現的次數越多,就越是要查詢的目標。(但是更公正的方法應是次數/文章總次數,一個比值的形式顯然更公平)。仔細這麼想也沒錯。好繼續往下。
Term Spam攻擊
既然我已經知道了搜尋的核心原理,如果我想要讓我的網頁能夠出現在搜尋的結果更靠前的位置,只要在頁面中加入更多對應的關鍵詞不就OK了,比如在html的div中寫入10000個張三,讓後使其隱藏此標籤,使得前端頁面不受影響,那我的目的豈不是達到了,這就是Term Spam攻擊。
PageRank演算法原理
既然關鍵詞匹配演算法容易遭到攻擊,那有什麼好的辦法呢,這是候就出現了著名的PageRank演算法,作為新的網頁排名/重要性演算法,最早是由Google的創始人所寫的演算法,PageRank演算法徹底摒棄了什麼關鍵詞不關鍵詞的,每個網頁都有自己的PageRank值,意味一個網頁的重要程度,PR值越高,最後呈現的位置更靠前。那怎麼衡量每個網頁的重要程度呢,答案是別的頁面對他的連結。一句話,越多的網頁在其內容上存在指向你的連結,說明你的網頁越有名。具體PR值的計算全是通過別的網頁的PR值做計算的,簡單計算過程如下:
假設一個由只有4個頁面組成的集合:A,B,C和D。如果所有頁面都鏈向A,那麼A的PR(PageRank)值將是B,C及D的和。

繼續假設B也有連結到C,並且D也有連結到包括A的3個頁面。一個頁面不能投票2次。所以B給每個頁面半票。以同樣的邏輯,D投出的票只有三分之一算到了A的PageRank上。

換句話說,根據鏈出總數平分一個頁面的PR值。

所示的例子來說明PageRank的具體計算過程。


q稱為阻尼係數。
PageRank的計算過程
PageRank的計算過程實際並不複雜,他的計算數學表示式如下:

就是1-q變成了1-q/n了,演算法的過程其實是利用了冪法的原理,等最後計算達到收斂了,也就結束了。
按照上面的計算公式假設矩陣A = q × P + ( 1 一 q) * /N,e為全為1的單位向量,P是一個連結概率矩陣,將連結的關係通過概率矩陣表現,A[i][j]表示網頁i存在到網頁j的連結,轉化如下:
/N,e為全為1的單位向量,P是一個連結概率矩陣,將連結的關係通過概率矩陣表現,A[i][j]表示網頁i存在到網頁j的連結,轉化如下:




圖4 P’ 的轉置矩 陣
這裡為什麼要把矩陣做轉置操作呢,原本a[i][j]代表i到j連結,現在就變為了j到i的連結的概率了,好,關鍵記住這點就夠了。最後A就計算出來了,你可以把他理解為網頁連結概率矩陣,最後只需要乘上對應的網頁PR值就可以了。
此時初始化向量R[1, 1, 1];代表最初的網頁的PR值,與此A概率矩陣相乘,第一個PR值R[0]'=A[0][0]*R[0] + A[0][1]*R[1] + A[0][2]*R[2],又因為A[i][j]此時的意思正是j到i網頁的連結概率,這樣的表示式恰恰就是上文我們所說的核心原理。然後將計算新得的R向量值域概率矩陣迭代計算直到收斂。
PageRank小結
PageRank的計算過程巧妙的被轉移到了矩陣的計算中了,使得過程非常的精簡。
Link Spam攻擊
魔高一尺道高一丈,我也已經知道了PageRank演算法的原理無非就是靠連結數升排名嘛,那我想讓我自己的網頁排名靠前,只要搞出很多網頁,把連結指向我,不就行了,學術上這叫Link Spam攻擊。但是這裡有個問題,PR值是相對的,自己的網頁PR值的高低還是要取決於指向者的PR值,這些指向者 的PR值如果不高,目標頁也不會高到哪去,所以這時候,如果你想自己造成一堆的殭屍網頁,統統指向我的目標網頁,PR也不見的會高,所以我們看到的更常見的手段是在入口網站上放連結,各大論壇或者類似於新浪,網頁新聞中心的評論中方連結,另類的實現連結指向了。目前針對這種作弊手法的直接的比較好的解決辦法是沒有,但是更多采用的是TrustRank,意味信任排名檢測,首先挑出一堆信任網頁做參照,然後計算你的網頁的PR值,如果你網頁本身很一般,但是PR值特別高,那麼很有可能你的網頁就是有問題的。
HITS
HITS演算法同樣作為一個連結分析演算法,與PageRank演算法在某些方面還是比較像的,將這2種演算法放在一起做比較,再好不過的了,一個明顯的不同點是HITS處理的網頁量是小規模的集合,而且他是與查詢相關的,首先輸入一個查詢q,假設檢索系統返回n個頁面,HITS演算法取其中的200個(假設值),作為分析的樣本資料,返回裡面更有價值的頁面。
HITS演算法原理
HITS衡量1個頁面用A[i]和H[i]值表示,A代表Authority權威值,H代表Hub樞紐值。
大意可理解為我指出的網頁的權威值越高,我的Hub值越大。指向我的網頁的Hub值越大,我的權威值越高。二者的變數相互權衡。下面一張圖直接明瞭:
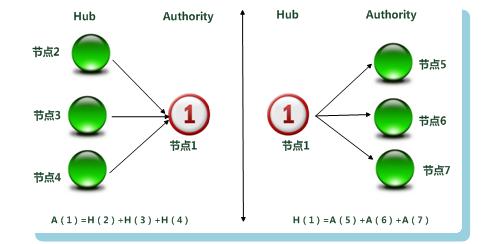
圖3 Hub與Authority權值計算
如果理解了PageRank演算法的原理,理解HITS應該很容易,最後結果的輸出是根據頁面的Authority權威值從高到低。
HITS演算法描述

具體可以對照後面我寫的程式。
HITS小結
從連結反作弊的角度來思考,HITS更容易遭受到Link Spam的攻擊,因為你想啊,網頁數量少啊,出錯的機率就顯得會大了。
相關文章
- PageRank演算法初探演算法
- 排名演算法(一)--PageRank演算法
- Machine Learning:PageRank演算法Mac演算法
- 谷歌PageRank演算法詳解谷歌演算法
- pangrank演算法--PageRank演算法並行實現演算法並行
- 張洋:淺析PageRank演算法演算法
- PageRank 演算法-Google 如何給網頁排名演算法Go網頁
- PageRank演算法概述與Python實現演算法Python
- 【大創_社群劃分】——PageRank演算法MapReduce實現演算法
- 機器學習之PageRank演算法應用與C#實現(1):演算法介紹機器學習演算法C#
- 【大創_社群劃分】——PageRank演算法的解析與Python實現演算法Python
- 基於圖的推薦演算法之Personal PageRank程式碼實戰演算法
- 程式設計師必須知道機器學習與資料探勘十大經典演算法:PageRank演算法篇程式設計師機器學習演算法
- BP演算法和LMBP演算法演算法
- 字串匹配-BF演算法和KMP演算法字串匹配演算法KMP
- KMP演算法和bfprt演算法總結KMP演算法
- 演算法和大便演算法
- 機器學習和演算法機器學習演算法
- 演算法---貪心演算法和動態規劃演算法動態規劃
- 最小生成樹——Prim演算法和Kruscal演算法演算法
- 最短路徑——Dijkstra演算法和Floyd演算法演算法
- 最短路徑—Dijkstra演算法和Floyd演算法演算法
- 最小生成樹:Kruskal演算法和Prim演算法演算法
- 最小生成樹-Prim演算法和Kruskal演算法演算法
- 《演算法帝國》:被演算法和演算法交易改變的未來(上)演算法
- 最小生成樹---普里姆演算法(Prim演算法)和克魯斯卡爾演算法(Kruskal演算法)演算法
- 字串查詢演算法總結(暴力匹配、KMP 演算法、Boyer-Moore 演算法和 Sunday 演算法)字串演算法KMP
- 機器學習之PageRank演算法應用與C#實現(2):球隊排名應用與C#程式碼機器學習演算法C#
- 演算法面試(七) 廣度和深度優先演算法演算法面試
- 模式識別中的Apriori演算法和FPGrowth演算法模式演算法
- js資料結構和演算法(9)-排序演算法JS資料結構演算法排序
- 總結下js排序演算法和亂序演算法JS排序演算法
- 粒子群演算法和遺傳演算法的比較演算法
- 資料結構和演算法——棧的面試演算法資料結構演算法面試
- 最小生成樹之Prim演算法和Kruskal演算法演算法
- 演算法設計與分析中的幾個核心演算法策略:動態規劃、貪心演算法、回溯演算法和分治演算法演算法動態規劃
- 常用HITS說明文件
- 聊聊演算法——BFS和DFS演算法