Apriori演算法
一、Apriori演算法簡介: Apriori演算法是一種挖掘關聯規則的頻繁項集演算法,其核心思想是通過候選集生成和情節的向下封閉檢測兩個階段來挖掘頻繁項集。 Apriori(先驗的,推測的)演算法應用廣泛,可用於消費市場價格分析,猜測顧客的消費習慣;網路安全領域中的入侵檢測技術;可用在用於高校管理中,根據挖掘規則可以有效地輔助學校管理部門有針對性的開展貧困助學工作;也可用在行動通訊領域中,指導運營商的業務運營和輔助業務提供商的決策制定。
二、挖掘步驟:
1.依據支援度找出所有頻繁項集(頻度)
2.依據置信度產生關聯規則(強度)
三、基本概念
對於A->B
①支援度:P(A ∩ B),既有A又有B的概率
②置信度:
P(B|A),在A發生的事件中同時發生B的概率 p(AB)/P(A) 例如購物籃分析:牛奶 ⇒ 麵包
例子:[支援度:3%,置信度:40%]
支援度3%:意味著3%顧客同時購買牛奶和麵包
置信度40%:意味著購買牛奶的顧客40%也購買麵包
③如果事件A中包含k個元素,那麼稱這個事件A為k項集事件A滿足最小支援度閾值的事件稱為頻繁k項集。
④同時滿足最小支援度閾值和最小置信度閾值的規則稱為強規則
四、實現步驟
Apriori演算法是一種最有影響的挖掘布林關聯規則頻繁項集的演算法Apriori使用一種稱作逐層搜尋的迭代方法,“K-1項集”用於搜尋“K項集”。
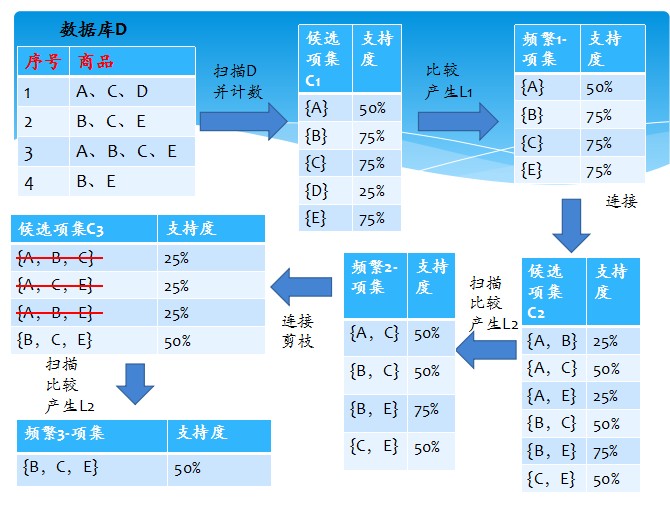
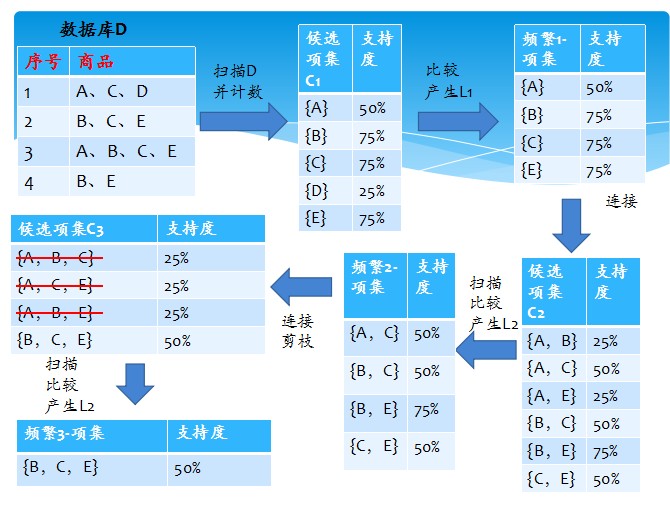
首先,找出頻繁“1項集”的集合,該集合記作L1。L1用於找頻繁“2項集”的集合L2,而L2用於找L3。如此下去,直到不能找到“K項集”。找每個Lk都需要一次資料庫掃描。
核心思想是:連線步和剪枝步。連線步是自連線,原則是保證前k-2項相同,並按照字典順序連線。剪枝步,是使任一頻繁項集的所有非空子集也必須是頻繁的。反之,如果某
個候選的非空子集不是頻繁的,那麼該候選肯定不是頻繁的,從而可以將其從CK中刪除。
簡單的講,1、發現頻繁項集,過程為(1)掃描(2)計數(3)比較(4)產生頻繁項集(5)連線、剪枝,產生候選項集 重複步驟(1)~(5)直到不能發現更大的頻集
2、產生關聯規則,過程為:根據前面提到的置信度的定義,關聯規則的產生如下:
(1)對於每個頻繁項集L,產生L的所有非空子集;
(2)對於L的每個非空子集S,如果
P(L)/P(S)≧min_conf
則輸出規則“SàL-S”
注:L-S表示在項集L中除去S子集的項集
一、Apriori演算法虛擬碼實現:
- 虛擬碼描述:
- // 找出頻繁 1 項集
- L1 =find_frequent_1-itemsets(D);
- For(k=2;Lk-1 !=null;k++){
- // 產生候選,並剪枝
- Ck =apriori_gen(Lk-1 );
- // 掃描 D 進行候選計數
- For each 事務t in D{
- Ct =subset(Ck,t); // 得到 t 的子集
- For each 候選 c 屬於 Ct
- c.count++;
- }
- //返回候選項集中不小於最小支援度的項集
- Lk ={c 屬於 Ck | c.count>=min_sup}
- }
- Return L= 所有的頻繁集;
- 第一步:連線(join)
- Procedure apriori_gen (Lk-1 :frequent(k-1)-itemsets)
- For each 項集 l1 屬於 Lk-1
- For each 項集 l2 屬於 Lk-1
- If( (l1 [1]=l2 [1])&&( l1 [2]=l2 [2])&& ……&& (l1 [k-2]=l2 [k-2])&&(l1 [k-1]<l2 [k-1]) )
- then{
- c = l1 連線 l2 // 連線步:產生候選
- //若k-1項集中已經存在子集c則進行剪枝
- if has_infrequent_subset(c, Lk-1 ) then
- delete c; // 剪枝步:刪除非頻繁候選
- else add c to Ck;
- }
- Return Ck;
- 第二步:剪枝(prune)
- Procedure has_infrequent_sub (c:candidate k-itemset; Lk-1 :frequent(k-1)-itemsets)
- For each (k-1)-subset s of c
- If s 不屬於 Lk-1 then
- Return true;
- Return false;
三、總結:
①Apriori演算法的缺點:(1)由頻繁k-1項集進行自連線生成的候選頻繁k項集數量巨大。(2)在驗證候選頻繁k項集的時候需要對整個資料庫進行掃描,非常耗時。
②網上提到的頻集演算法的幾種優化方法:1. 基於劃分的方法。2. 基於hash的方法。3. 基於取樣的方法。4. 減少交易的個數。
我重點看了“基於劃分的方法”改進演算法,現在簡單介紹一下實現思想:
基於劃分(partition)的演算法,這個演算法先把資料庫從邏輯上分成幾個互不相交的塊,每次單獨考慮一個分塊並 對它生成所有的頻集,然後把產生的頻集合並,用來生成所有可能的頻集,最後計算這些項集的支援度。
其中,partition演算法要注意的是分片的大小選取,要保證每個分片可以被放入到記憶體。當每個分片產生頻集後,再合併產生產生全域性的候選k-項集。若在多個處理器分片,可以通過處理器之間共享一個雜湊樹來產生頻集。
相關文章
- Apriori演算法原理總結演算法
- Apriori演算法 java程式碼演算法Java
- Apriori演算法的介紹演算法
- 關聯分析(二)--Apriori演算法演算法
- 關聯規則方法之apriori演算法演算法
- 使用apriori演算法進行關聯分析演算法
- 關聯規則挖掘(二)-- Apriori 演算法演算法
- 關聯規則挖掘之apriori演算法演算法
- 模式識別中的Apriori演算法和FPGrowth演算法模式演算法
- 關聯分析Apriori演算法和FP-growth演算法初探演算法
- Apriori 演算法-如何進行關聯規則挖掘演算法
- 關聯規則挖掘:Apriori演算法的深度探討演算法
- 資料探勘十大演算法之Apriori詳解演算法
- 關聯規則apriori演算法的python實現演算法Python
- 關聯規則分析 Apriori 演算法 簡介與入門演算法
- 菜市場價格分析 python pandas Apriori演算法 資料預處理Python演算法
- 第十四篇:Apriori 關聯分析演算法原理分析與程式碼實現演算法
- 機器學習系列文章:Apriori關聯規則分析演算法原理分析與程式碼實現機器學習演算法
- 市場購物籃分析(規則歸納/C5.0)+apriori
- 基於Apriori關聯規則的電影推薦系統(附python程式碼)Python
- 【Python資料探勘課程】八.關聯規則挖掘及Apriori實現購物推薦Python
- 【演算法】KMP演算法演算法KMP
- 演算法-回溯演算法演算法
- 【JAVA演算法】圖論演算法 -- Dijkstra演算法Java演算法圖論
- 演算法(2)KMP演算法演算法KMP
- 【演算法】遞迴演算法演算法遞迴
- 演算法題:洗牌演算法演算法
- [演算法之回溯演算法]演算法
- Manacher演算法、KMP演算法演算法KMP
- 【演算法】KMP演算法解析演算法KMP
- 介面限流演算法:漏桶演算法&令牌桶演算法演算法
- 前端演算法:快速排序演算法前端演算法排序
- 演算法初探--遞迴演算法演算法遞迴
- BP演算法和LMBP演算法演算法
- 隨機演算法 概率演算法隨機演算法
- STL::演算法::常見演算法演算法
- 常用演算法 插值演算法演算法
- 前向分步演算法 && AdaBoost演算法 && 提升樹(GBDT)演算法 && XGBoost演算法演算法