(EM演算法)The EM Algorithm
之前介紹了EM演算法在混合高斯模型中的應用,現在讓我們來看看問什麼EM演算法可以用於這類問題。
首先介紹一下Jensen 不等式
Jensen 不等式
我們知道,如果設
顯然我們的樣本
begin-補充-hessian矩陣
對於一個實值多元函式
其中 D_i表示對第
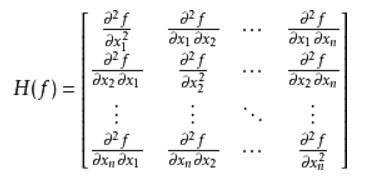
可見如果hessian矩陣存在那麼它必然是對稱的因為求偏導數時的求導順序並不影響最終結果:
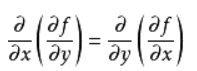
利用hessian進行多元函式極值的判定:
如果實值多元函式
如果H(M)是正定矩陣,則臨界點M處是一個區域性的極小值。
如果H(M)是負定矩陣,則臨界點M處是一個區域性的極大值。
如果H(M)是不定矩陣,則臨界點M處不是極值。
end-補充-hessian矩陣
如果
下面給出jensen不等式定理:
如果 f 是凸函式, X 是隨機變數,那麼
特別地,如果
為了便於理解我們們先看下面:
凸函式的概念:
【定義】如果函式
注意哦開口向下的是凸,開口向上的是凹。
如果不等式中等號只有 時才成立,我們分別稱它們為嚴格的凹凸函式.
推廣下就是:
對於任意的凹函式
對於任意的凸函式
如果上面凹凸是嚴格的,那麼不等式的等號只有
其實上面的結論就是我們的jensen不等式,相信大家都見過。
可將jensen用圖形表示如下:
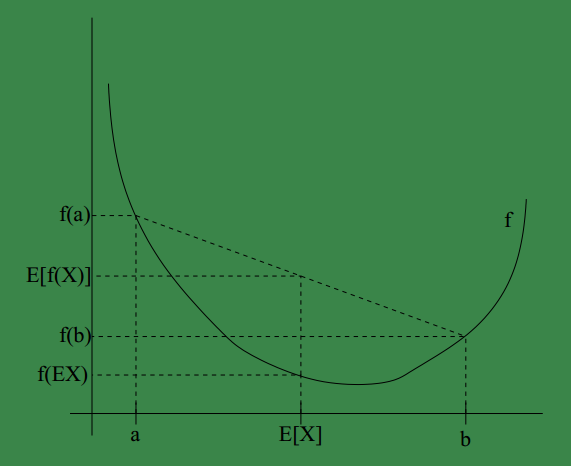
其中
另外,
Jensen 不等式應用於凹函式時,不等號方向反向,也就是
EM演算法
假如我們有訓練樣本集{
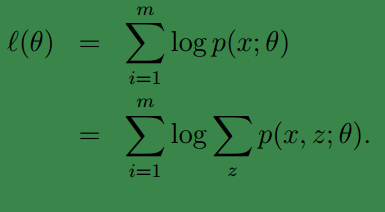
但是在上一篇中我們提到由於
EM 是一種解決存在隱含變數優化問題的有效方法。其思想是:不斷地建立
對於每一個樣例
這樣我們可以得到:
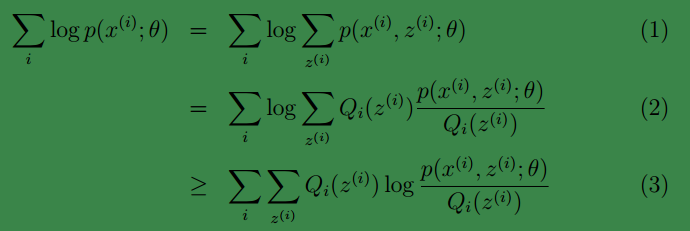
注:
1、(1)到(2)比較直接,就是分子分母同乘以一個相等的函式。
2、(2)到(3)利用了 Jensen不等式;首先log函式是凹函式。其次根據lazy Statistician規則,可知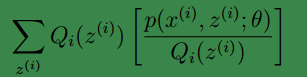
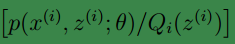
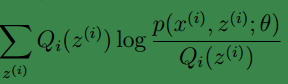
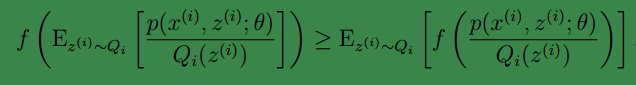
begin-補充-Lazy Statistician規則
設
(1)
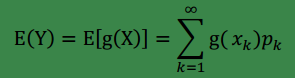
(2)
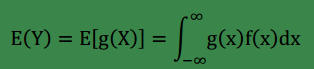
end-補充
因此,對於任何一種分佈
(我們知道,在EM演算法中的E步中,我們的
其中
進而可得:
再利用條件概率公式可得:
上面的推導有點亂,現在把他們壓縮下就是:
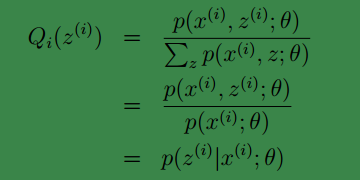
現在我們知道
這一步就是
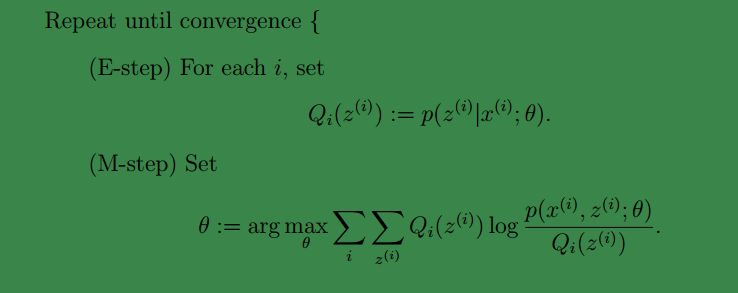
下面讓我們來證明EM演算法的收斂性:
假定θ(t)和θ(t+1)是 EM 第 t 次和 t+1 次迭代後的結果。 如果我們證明了ℓ(θ(t)) ≤ ℓ(θ(t+1)),也就是說極大似然估計單調增加,那麼最終我們會到達最大似然估計的最大值。 下面來證明,選定
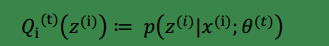
進而等號滿足:
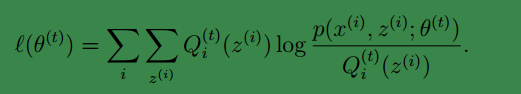
然後我們通過最大化上面等式的式右面獲得了新的引數
此時必然有:
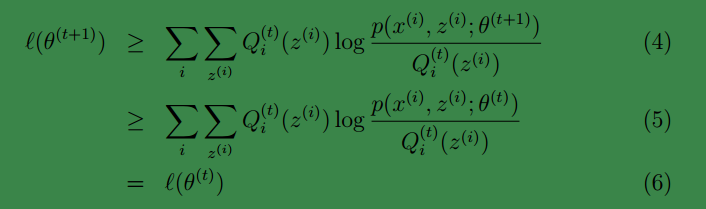
上面第一行是由式(3)得到,即基於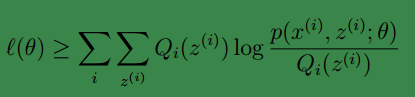
第( 5)步利用了 M 步的定義。第( 5)步利用了 M 步的定義, M 步就是將θ(t)調整到θ(t+1),即
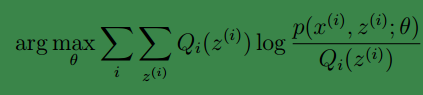
這樣就證明了ℓ(θ)會單調增加。因此EM演算法是收斂的。
如果我們定義:
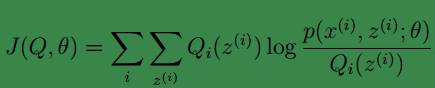
從前面的推導中我們知道ℓ(θ) ≥ J(Q, θ), EM 可以看作是 J 的座標上升法, E 步固定θ,優化Q, M 步固定Q優化θ。
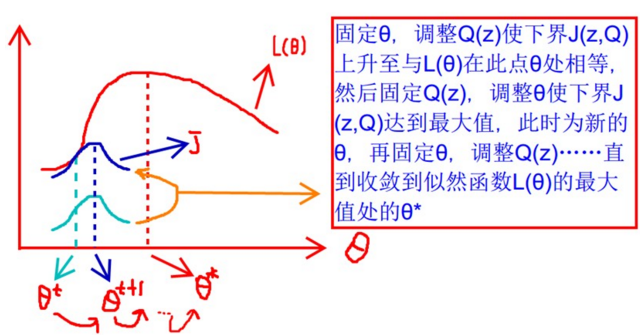
下面從別人那偷了張圖,很好的說明了EM演算法的優化過程:
相關文章
- 04EM演算法-EM演算法收斂證明演算法
- EM演算法1演算法
- 03EM演算法-EM演算法流程和直觀案例演算法
- 09_EM演算法演算法
- 白話EM演算法演算法
- EM
- EM演算法原理總結演算法
- EM演算法學習(三)演算法
- 機器學習經典演算法之EM機器學習演算法
- EM演算法學習筆記演算法筆記
- 演算法進階(8): EM演算法演算法
- 【EM】重新建立EM Database ControlDatabase
- python機器學習筆記:EM演算法Python機器學習筆記演算法
- 如何感性地理解EM演算法?演算法
- ORACLE EM recreateOracle
- windows drop emWindows
- 重建oracle EMOracle
- em 和 remREM
- 機器學習十大演算法之EM演算法機器學習演算法
- 05EM演算法-高斯混合模型-GMM演算法模型
- 期望最大化演算法(EM)簡介演算法
- rem與em的區別||結合使用rem與emREM
- oracle EM 優化Oracle優化
- em,rem和vhREM
- oracle 重建EM databaseOracleDatabase
- oracle em 修改埠Oracle
- 統計學習方法筆記-EM演算法筆記演算法
- 高斯混合模型(GMM)及其EM演算法的理解模型演算法
- 【機器學習】--EM演算法從初識到應用機器學習演算法
- 從最大似然到EM演算法淺解演算法
- Oracle 19C EMOracle
- px em rem 探討REM
- CSS中強大的EMCSS
- oracle EM配置命令解析Oracle
- oracle重新配置emOracle
- EM 失效的處理
- EM和動態ip
- Oracle中EM的配置Oracle