十圖詳解TensorFlow資料讀取機制(附程式碼)
在學習TensorFlow的過程中,有很多小夥伴反映讀取資料這一塊很難理解。確實這一塊官方的教程比較簡略,網上也找不到什麼合適的學習材料。今天這篇文章就以圖片的形式,用最簡單的語言,為大家詳細解釋一下TensorFlow的資料讀取機制,文章的最後還會給出實戰程式碼以供參考。
TensorFlow讀取機制圖解
首先需要思考的一個問題是,什麼是資料讀取?以影象資料為例,讀取資料的過程可以用下圖來表示:
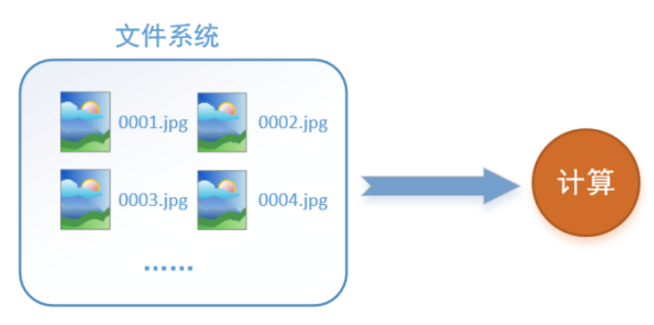
假設我們的硬碟中有一個圖片資料集0001.jpg,0002.jpg,0003.jpg……我們只需要把它們讀取到記憶體中,然後提供給GPU或是CPU進行計算就可以了。這聽起來很容易,但事實遠沒有那麼簡單。事實上,我們必須要把資料先讀入後才能進行計算,假設讀入用時0.1s,計算用時0.9s,那麼就意味著每過1s,GPU都會有0.1s無事可做,這就大大降低了運算的效率。
如何解決這個問題?方法就是將讀入資料和計算分別放在兩個執行緒中,將資料讀入記憶體的一個佇列,如下圖所示:
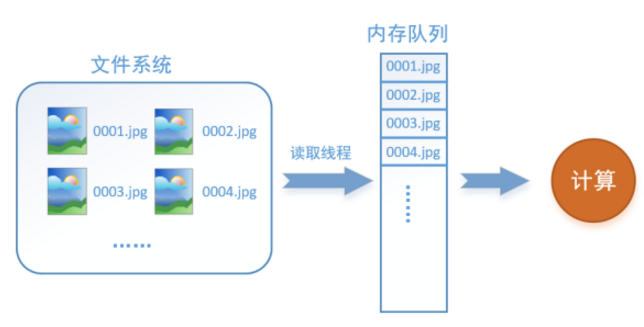
讀取執行緒源源不斷地將檔案系統中的圖片讀入到一個記憶體的佇列中,而負責計算的是另一個執行緒,計算需要資料時,直接從記憶體佇列中取就可以了。這樣就可以解決GPU因為IO而空閒的問題!
而在TensorFlow中,為了方便管理,在記憶體佇列前又新增了一層所謂的“檔名佇列”。
為什麼要新增這一層檔名佇列?我們首先得了解機器學習中的一個概念:epoch。對於一個資料集來講,執行一個epoch就是將這個資料集中的圖片全部計算一遍。如一個資料集中有三張圖片A.jpg、B.jpg、C.jpg,那麼跑一個epoch就是指對A、B、C三張圖片都計算了一遍。兩個epoch就是指先對A、B、C各計算一遍,然後再全部計算一遍,也就是說每張圖片都計算了兩遍。
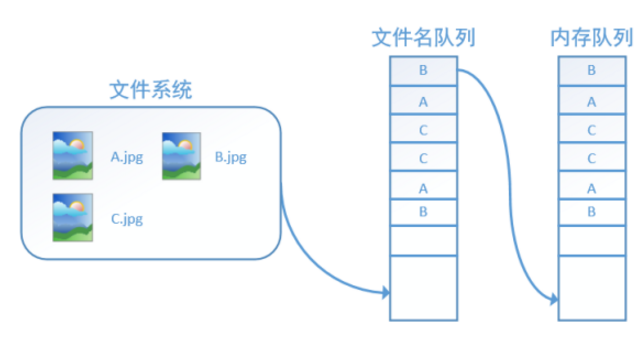
TensorFlow使用檔名佇列+記憶體佇列雙佇列的形式讀入檔案,可以很好地管理epoch。下面我們用圖片的形式來說明這個機制的執行方式。如下圖,還是以資料集A.jpg, B.jpg, C.jpg為例,假定我們要跑一個epoch,那麼我們就在檔名佇列中把A、B、C各放入一次,並在之後標註佇列結束。
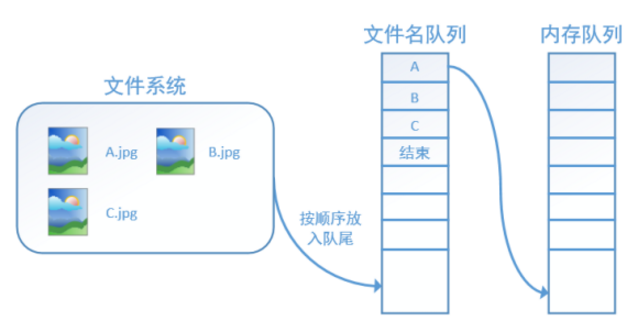
程式執行後,記憶體佇列首先讀入A(此時A從檔名佇列中出隊):
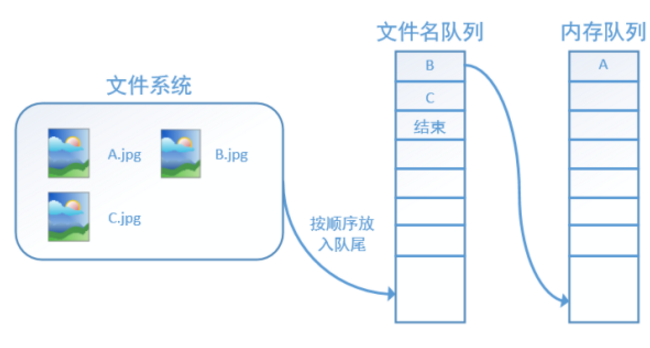
再依次讀入B和C:
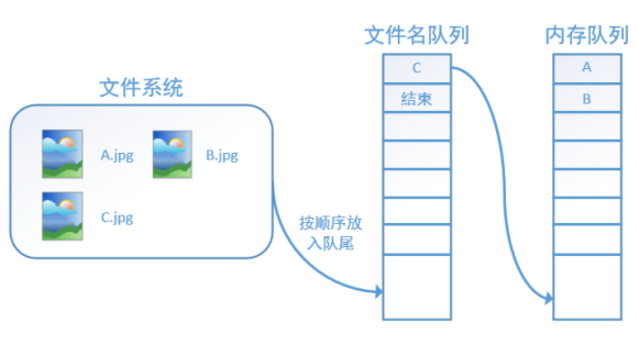
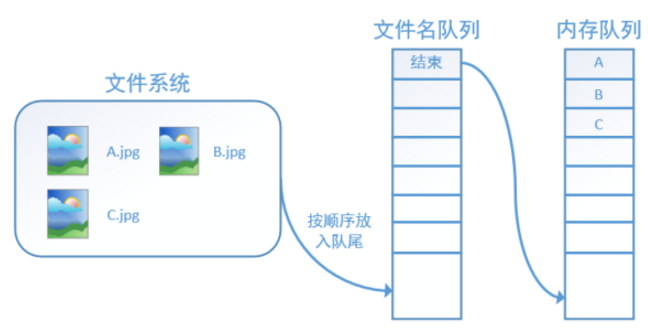
此時,如果再嘗試讀入,系統由於檢測到了“結束”,就會自動丟擲一個異常(OutOfRange)。外部捕捉到這個異常後就可以結束程式了。這就是TensorFlow中讀取資料的基本機制。如果我們要跑2個epoch而不是1個epoch,那隻要在檔名佇列中將A、B、C依次放入兩次再標記結束就可以了。
TensorFlow讀取資料機制的對應函式
如何在TensorFlow中建立上述的兩個佇列呢?
對於檔名佇列,我們使用tf.train.string_input_producer函式。這個函式需要傳入一個檔名list,系統會自動將它轉為一個檔名佇列。
此外tf.train.string_input_producer還有兩個重要的引數,一個是num_epochs,它就是我們上文中提到的epoch數。另外一個就是shuffle,shuffle是指在一個epoch內檔案的順序是否被打亂。若設定shuffle=False,如下圖,每個epoch內,資料還是按照A、B、C的順序進入檔名佇列,這個順序不會改變:
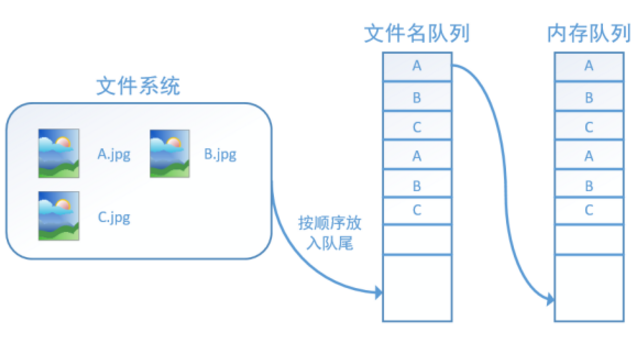
如果設定shuffle=True,那麼在一個epoch內,資料的前後順序就會被打亂,如下圖所示:
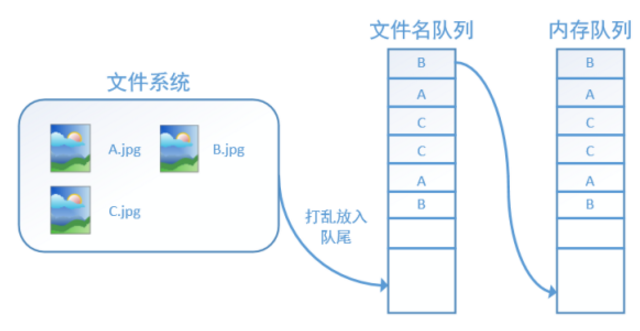
在TensorFlow中,記憶體佇列不需要我們自己建立,我們只需要使用reader物件從檔名佇列中讀取資料就可以了,具體實現可以參考下面的實戰程式碼。
除了tf.train.string_input_producer外,我們還要額外介紹一個函式:tf.train.start_queue_runners。初學者會經常在程式碼中看到這個函式,但往往很難理解它的用處,在這裡,有了上面的鋪墊後,我們就可以解釋這個函式的作用了。
在我們使用tf.train.string_input_producer建立檔名佇列後,整個系統其實還是處於“停滯狀態”的,也就是說,我們檔名並沒有真正被加入到佇列中(如下圖所示)。此時如果我們開始計算,因為記憶體佇列中什麼也沒有,計算單元就會一直等待,導致整個系統被阻塞。
而使用tf.train.start_queue_runners之後,才會啟動填充佇列的執行緒,這時系統就不再“停滯”。此後計算單元就可以拿到資料並進行計算,整個程式也就跑起來了,這就是函式tf.train.start_queue_runners的用處。
實戰程式碼
我們用一個具體的例子感受TensorFlow中的資料讀取。如圖,假設我們在當前資料夾中已經有A.jpg、B.jpg、C.jpg三張圖片,我們希望讀取這三張圖片5個epoch並且把讀取的結果重新存到read資料夾中。

對應的程式碼如下:
# 匯入TensorFlow
import TensorFlow as tf
# 新建一個Session
with tf.Session() as sess:
# 我們要讀三幅圖片A.jpg, B.jpg, C.jpg
filename = ['A.jpg', 'B.jpg', 'C.jpg']
# string_input_producer會產生一個檔名佇列
filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)
# reader從檔名佇列中讀資料。對應的方法是reader.read
reader = tf.WholeFileReader()
key, value = reader.read(filename_queue)
# tf.train.string_input_producer定義了一個epoch變數,要對它進行初始化
tf.local_variables_initializer().run()
# 使用start_queue_runners之後,才會開始填充佇列
threads = tf.train.start_queue_runners(sess=sess)
i = 0
while True:
i += 1
# 獲取圖片資料並儲存
image_data = sess.run(value)
with open('read/test_%d.jpg' % i, 'wb') as f:
f.write(image_data)我們這裡使用filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)建立了一個會跑5個epoch的檔名佇列。並使用reader讀取,reader每次讀取一張圖片並儲存。
執行程式碼後,我們得到就可以看到read資料夾中的圖片,正好是按順序的5個epoch:

如果我們設定filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)中的shuffle=True,那麼在每個epoch內影象就會被打亂,如圖所示:

我們這裡只是用三張圖片舉例,實際應用中一個資料集肯定不止3張圖片,不過涉及到的原理都是共通的。
總結
這篇文章主要用圖解的方式詳細介紹了TensorFlow讀取資料的機制,最後還給出了對應的實戰程式碼,希望能夠給大家學習TensorFlow帶來一些實質性的幫助。
相關文章
- 10 張圖詳解 TensorFlow 資料讀取機制(附程式碼)
- 十圖詳解TensorFlow資料讀取機制tf.train.string_input_producer和tf.train.start_queue_runnersAI
- 解讀MySQL 8.0資料字典快取管理機制MySql快取
- TensorFlow讀取CSV資料
- TensorFlow分散式計算機制解讀:以資料並行為重分散式計算機並行
- TensorFlow讀取CSV資料(批次)
- Oracle SCN機制詳細解讀Oracle
- 程式設計師筆記| 詳解Eureka 快取機制程式設計師筆記快取
- 分頁機制圖文詳解
- 瀏覽器快取機制詳解瀏覽器快取
- Hibernate 所有快取機制詳解快取
- Android事件機制詳細解讀Android事件
- ajax讀取資料庫資料程式碼例項資料庫
- 雲端TensorFlow讀取資料IO的高效方式
- Nginx 快取機制詳解!非常詳細實用Nginx快取
- Logstash讀取Kafka資料寫入HDFS詳解Kafka
- iOS Cell非同步圖片載入優化,快取機制詳解iOS非同步優化快取
- TensorFlow讀寫資料
- 圖解Dubbo,6 種擴充套件機制詳解圖解套件
- TensorFlow高效讀取資料的方法——TFRecord的學習
- 圖解 HTTP 的快取機制 | 實用 HTTP圖解HTTP快取
- Session機制詳解Session
- AsyncTask機制詳解
- 瀏覽器 HTTP 協議快取機制詳解瀏覽器HTTP協議快取
- Hadoop框架:HDFS讀寫機制與API詳解Hadoop框架API
- Java SPI機制總結系列之萬字最詳細圖解Java SPI機制原始碼分析Java圖解原始碼
- TensorFlow引入了動態圖機制Eager Execution
- UCI資料集詳解及其資料處理(附148個資料集及處理程式碼)
- JVM類載入機制及雙親委派機制原始碼解讀JVM原始碼
- 關於tensorflow 的資料讀取執行緒管理QueueRunner執行緒
- 動態引入js檔案使用隨機數防止讀取快取資料程式碼例項JS隨機快取
- 瀏覽器快取機制(詳)瀏覽器快取
- Android Handler訊息機制原始碼解讀Android原始碼
- 如何用ABAP程式碼讀取CDS view association的資料View
- 【Tensorflow_DL_Note9】Tensorflow原始碼解讀1原始碼
- 【Tensorflow_DL_Note13】TensorFlow中資料的讀取方式(1)
- 聊聊資料庫和快取同步機制資料庫快取
- Kafka 架構和原理機制 (圖文全面詳解)Kafka架構