【機器學習PAI實踐一】搭建心臟病預測案例
產品地址:https://data.aliyun.com/product/learn?spm=a21gt.99266.416540.102.OwEfx2
一、背景
心臟病是人類健康的頭號殺手。全世界1/3的人口死亡是因心臟病引起的,而我國,每年有幾十萬人死於心臟病。 所以,如果可以通過提取人體相關的體側指標,通過資料探勘的方式來分析不同特徵對於心臟病的影響,對於預測和預防心臟病將起到至關重要的作用。本文將會通過真實的資料,通過阿里雲機器學習平臺搭建心臟病預測案例。
二、資料集介紹
資料來源: UCI開源資料集heart_disease
針對美國某區域的心臟病檢查患者的體測資料,共303條資料。具體欄位如下表:
| 欄位名 | 含義 | 型別 | 描述 |
|---|---|---|---|
| age | 年齡 | string | 物件的年齡,數字表示 |
| sex | 性別 | string | 物件的性別,female和male |
| cp | 胸部疼痛型別 | string | 痛感由重到無typical、atypical、non-anginal、asymptomatic |
| trestbps | 血壓 | string | 血壓數值 |
| chol | 膽固醇 | string | 膽固醇數值 |
| fbs | 空腹血糖 | string | 血糖含量大於120mg/dl為true,否則為false |
| restecg | 心電圖結果 | string | 是否有T波,由輕到重為norm、hyp |
| thalach | 最大心跳數 | string | 最大心跳數 |
| exang | 運動時是否心絞痛 | string | 是否有心絞痛,true為是,false為否 |
| oldpeak | 運動相對於休息的ST depression | string | st段壓數值 |
| slop | 心電圖ST segment的傾斜度 | string | ST segment的slope,程度分為down、flat、up |
| ca | 透視檢檢視到的血管數 | string | 透視檢檢視到的血管數 |
| thal | 缺陷種類 | string | 併發種類,由輕到重norm、fix、rev |
| status | 是否患病 | string | 是否患病,buff是健康、sick是患病 |
三、資料探索流程
資料探勘流程如下:
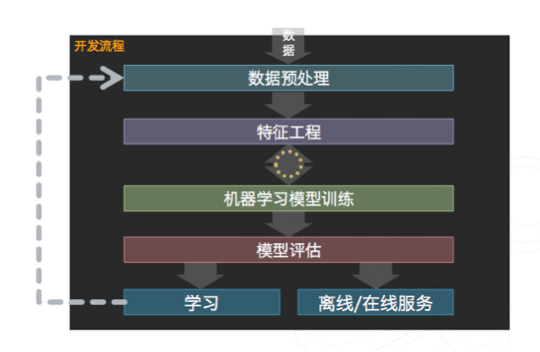
整體實驗流程:
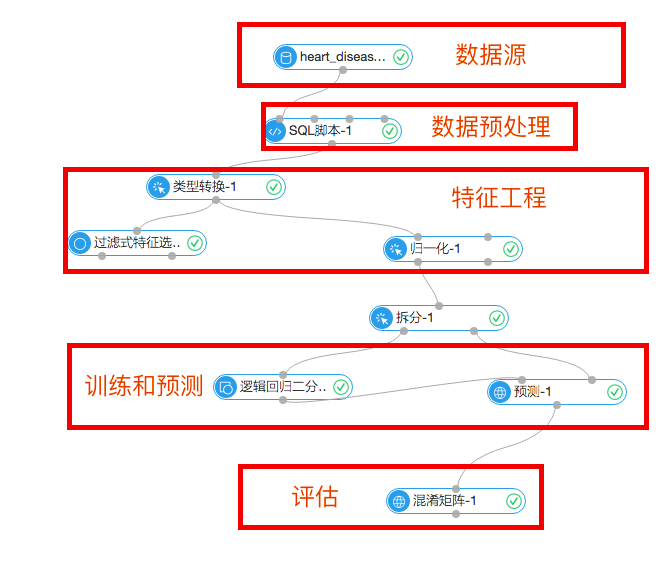
1.資料預處理
資料預處理也叫作資料清洗,主要在資料進入演算法流程前對資料進行去噪、填充缺失值、型別變換等操作。本次實驗的輸入資料包括14個特徵和1個目標佇列。需要解決的場景是根據使用者的體檢指標預測是否會患有心臟病,每個樣本只有患病或不患病兩種,是分類問題。因為本次分類實驗選用的是線性模型邏輯迴歸,要求輸入的特徵都是double型的資料。
輸入資料展示:
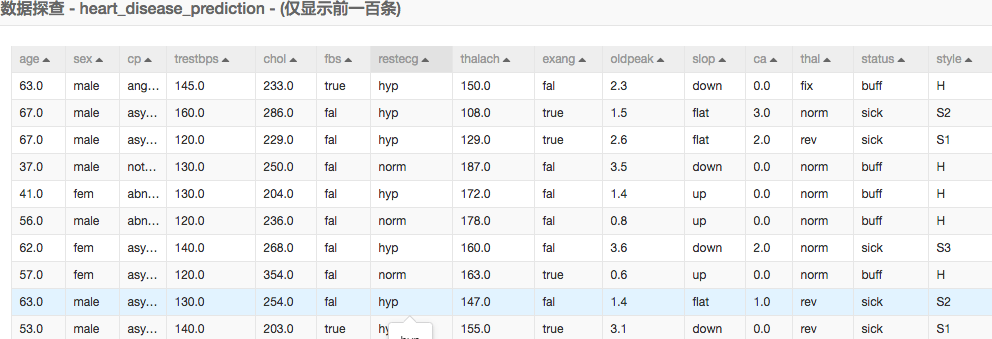
我們看到有很多資料是文字描述的,在資料預處理的過程中我們需要根據每個欄位的含義將字元型轉為數值。
1)二值類的資料
二值類的比較容易轉換,如sex欄位有兩種表現形式female和male,我們可以將female表示成0,把male表示成1。
2)多值類的資料
比如cp欄位,表示胸部的疼痛感,我們可以通過疼痛的由輕到重對映成0~3的數值。
資料的預處理通過sql指令碼來實現,具體請參考SQL指令碼-1元件,
select age,
(case sex when 'male' then 1 else 0 end) as sex,
(case cp when 'angina' then 0 when 'notang' then 1 else 2 end) as cp,
trestbps,
chol,
(case fbs when 'true' then 1 else 0 end) as fbs,
(case restecg when 'norm' then 0 when 'abn' then 1 else 2 end) as restecg,
thalach,
(case exang when 'true' then 1 else 0 end) as exang,
oldpeak,
(case slop when 'up' then 0 when 'flat' then 1 else 2 end) as slop,
ca,
(case thal when 'norm' then 0 when 'fix' then 1 else 2 end) as thal,
(case status when 'sick' then 1 else 0 end) as ifHealth
from ${t1};
2.特徵工程
特徵工程主要是包括特徵的衍生、尺度變化等。本例中有兩個元件負責特徵工程的部分。
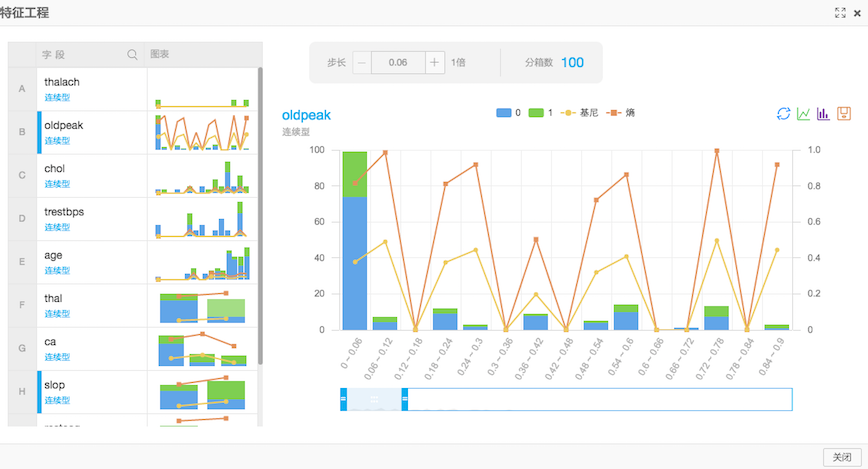
1)過濾式特徵選擇
主要是通過這個元件判斷每個特徵對於結果的影響,通過資訊熵和基尼係數來表示,可以通過檢視評估報告來顯示最終的結果。
2)歸一化
因為本次實驗選擇的是通過邏輯迴歸二分類來進行模型訓練,需要每個特徵去除量綱的影響。歸一化的作用是將每個特徵的數值範圍變為0到1之間。歸一化的公式為result=(val-min)/(max-min)。
歸一化結果:
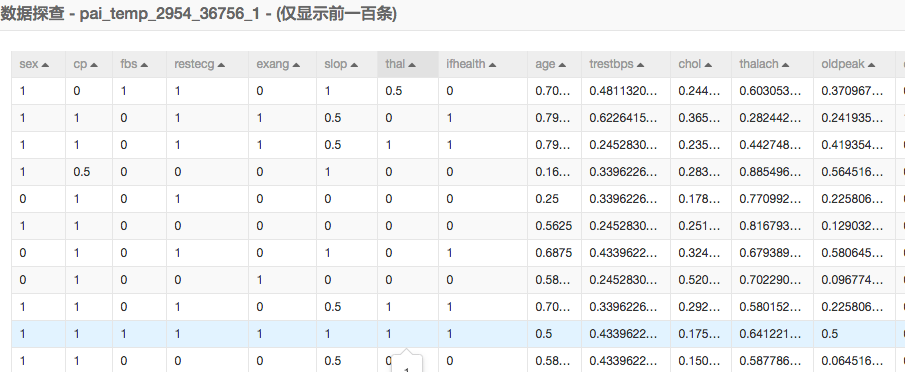
3.模型訓練和預測
本次實驗是監督學習,因為我們已經知道每個樣本是否患有心臟病,所謂監督學習就是已知結果來訓練模型。解決的問題是預測一組使用者是否患有心臟病。
1)拆分
首先通過拆分元件將資料分為兩部分,本次實驗按照訓練集和預測集7:3的比例拆分。訓練集資料流入邏輯迴歸二分類元件用來訓練模型,預測集資料進入預測元件。
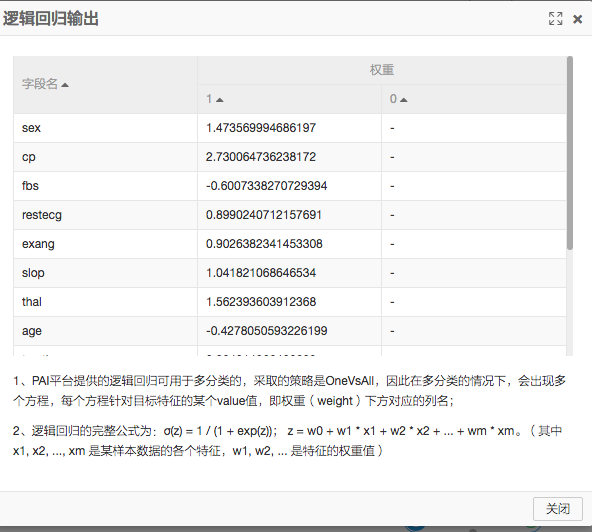
2)邏輯迴歸二分類
邏輯迴歸是一個線性模型,在這裡通過計算結果的閾值實現分類。具體的演算法詳情推薦大家在網上或者書籍中自行了解。邏輯迴歸訓練好的模型可以在模型頁籤中檢視。
3)預測
預測元件的兩個輸入分別是模型和預測集。預測結果展示的是預測資料、真實資料、每組資料不同結果的概率。
4.評估
通過混淆矩陣元件可以評估模型的準確率等引數,
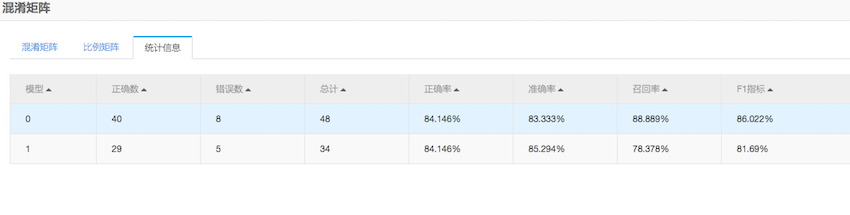
通過此元件可以方便的通過預測的準確性來評估模型。
四.總結
通過以上資料探索的流程我們可以得到以下的結論。
1)特徵權重
我們可以通過過濾式特徵選擇得到每個特徵對於結果的權重。
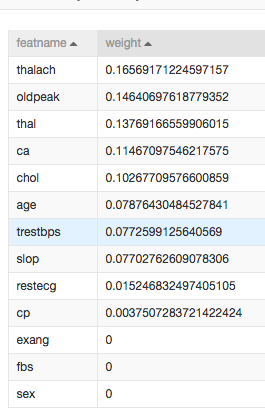
-可以看出thalach(心跳數)對於是否發生心臟病影響最大。
-性別對於心臟病沒有影響
2)模型效果
通過上文提供的14個特徵,可以達到百分之八十多的心臟病預測準確率。模型可以用來做預測,輔助醫生預防和治療心臟病。
五、其它
免費體驗:阿里雲數加機器學習平臺
相關文章
- 機器學習專案---預測心臟病(一)機器學習
- 機器學習專案---預測心臟病(二)機器學習
- 【機器學習PAI實踐九】如何通過機器學習實現雲端實時心臟狀況監測機器學習AI
- 【機器學習PAI實踐六】金融貸款發放預測機器學習AI
- 心臟病不再擔心,人工智慧3D列印心臟人工智慧3D
- 人工智慧可以預測心臟病發作時間 挽救更多生命人工智慧
- 準確率超90%!AI預測心臟病發作及死亡率遠勝人類AI
- 【機器學習PAI實踐三】霧霾成因分析機器學習AI
- 【機器學習PAI實踐五】機器學習眼中的《人民的名義》機器學習AI
- 【機器學習PAI實踐四】如何實現金融風控機器學習AI
- 【機器學習PAI實踐二】人口普查統計機器學習AI
- 【機器學習PAI實踐十一】機器學習PAI為你自動寫歌詞,媽媽再也不用擔心我的freestyle了(提供資料、程式碼機器學習AI
- 美國心臟協會:2022年美國心臟病和卒中統計資料包告(487頁)
- 視網膜眼底影象預測心臟病風險:Nature綜述深度學習在生物醫療中的新應用深度學習
- 視網膜眼底影像預測心臟病風險:Nature綜述深度學習在生物醫療中的新應用深度學習
- 扎心實戰案例:麻(shi)雀(zhan)雖小,五臟俱全
- 機器學習PAI全新功效——實時新聞熱點OnlineLearning實踐機器學習AI
- 【機器學習PAI實踐八】用機器學習演算法評估學生考試成績機器學習AI演算法
- 人工智慧訓練使用視網膜掃描發現心臟病風險人工智慧
- AI診斷心臟病比人類更準?但這只是識圖,不是診斷AI
- 美國心臟病協會:《Pokemon Go》促進玩家每日步數增加2000Go
- 【機器學習PAI實踐十二】機器學習實現雙十一購物清單的自動商品標籤歸類機器學習AI
- Nature論文解讀 | 基於深度學習和心臟影像預測生存概率深度學習
- 【機器學習PAI實踐七】文字分析演算法實現新聞自動分類機器學習AI演算法
- 機器學習PAI快速入門與業務實戰機器學習AI
- 機器學習PAI快速入門機器學習AI
- 【機器學習PAI實踐十】深度學習Caffe框架實現影象分類的模型訓練機器學習AI深度學習框架模型
- 【機器學習PAI實踐十二】機器學習演算法基於信用卡消費記錄做信用評分機器學習AI演算法
- 【機器學習PAI實踐十二】機器學習實現男女聲音識別分類(含語音特徵提取資料和程式碼)機器學習AI特徵
- 機器學習模型在雲音樂指標異動預測的應用實踐機器學習模型指標
- 【機器學習PAI實戰】—— 玩轉人工智慧之綜述機器學習AI人工智慧
- 快速玩轉 Mixtral 8x7B MOE大模型!阿里雲機器學習 PAI 推出實踐大模型阿里機器學習AI
- DispatcherServlet ——Spring MVC 的大心臟ServletSpringMVC
- 機器學習(一):5分鐘理解機器學習並上手實踐機器學習
- 機器學習股票價格預測初級實戰機器學習
- 美國心臟協會雜誌:研究揭示大麻與心臟健康之間令人擔憂的聯絡
- 【機器學習PAI實戰】—— 玩轉人工智慧之美食推薦機器學習AI人工智慧
- 機器學習實踐指南機器學習