新聞個性化推薦系統(python)-(附原始碼 資料集)
1.背景
最近參加了一個評測,是關於新聞個性化推薦。說白了就是給你一個人的瀏覽記錄,預測他下一次的瀏覽記錄。花了一週時間寫了一個整合系統,可以一鍵推薦新聞,但是準確率比較不理想,所以發到這裡希望大家給與一些建議。用到的分詞部分的程式碼借用的jieba分詞。資料集和程式碼在下面會給出。
2.資料集

一共五個欄位,以tab隔開。分別是user編號,news編號,時間編號,新聞標題,對應當前月份的日(3就是3號)
3.程式碼部分
先來看下演示圖

(1)演算法說明
舉個例子簡單說明下演算法,其實也比較簡單,不妥的地方希望大家指正。我們有如下一條資料
5738936 100649879 1394550848 MH370航班假護照乘客身份查明(更新) 115738936這名使用者在11號看了“MH370航班假護照乘客...”這條新聞。我們通過jieba找出11號的熱點詞如下。
失聯 311 三週年 馬方 偷渡客 隱形 護照 吉隆坡 航班 護照者 我們發現“航班”、“護照”這兩個keywords出現在新聞裡。於是我們就推薦5738936這名使用者,11號出現“航班”、“護照”的其它新聞。同時我們對推薦集做了處理,比如說5738936瀏覽過的新聞不會出現,熱度非常低的新聞不會出現等。
(2)使用方法
整個系統採用一鍵式啟動,使用起來非常方便。首先建立一個test資料夾,然後在test裡新建三個資料夾,注意命名要和圖中的統一,因為新聞是有時效的,每一天要去分開來計算,要儲存每一天的內容做成文件。test文件如下圖,就可以自動生成。(下面的github連結提供了完整的test文件結構)
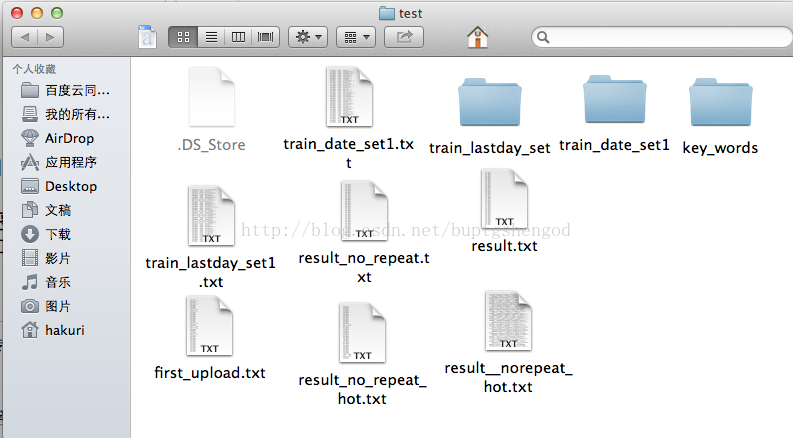
使用的時候,要先在Global_param.py中設定好test資料夾的路徑引數。一切設定完畢,只要找到wordSplite_test包下面的main()函式,執行程式即可。
Global_param中設定引數說明:
number_jieba:控制提取關鍵詞的數量
number_day:從第一天開始,要預測的天數
hot_rate:預測集預測的新聞熱度,數值越大熱度越高
(3)程式碼流程
首先我們從main()看起。
import Get_day_data
import Get_keywords
import Get_keynews
import Delete_Repeat
import Get_hot_result
import Global_param
def main():
for i in range(1,Global_param.number_day):
Get_day_data.TransforData(i)
Get_day_data.TransforDataset(i)
Get_keywords.Get_keywords(i)
Get_keynews.Get_keynews(i)
Delete_Repeat.Delete_Repeat()
Get_hot_result.get_hot_result(Global_param.hot_rate)
main() 1.首先Get_day_data.TransforData(i)函式,找到最後一次瀏覽的是第i天的新聞的使用者行為,存放在test/train_lastday_set目錄下。
2.Get_day_data.TransforDataset(i)函式,區分每一天的新聞,存放在test/train_date_set1目錄下
3.Get_keywords.Get_keywords(i)函式,呼叫jieba庫,挑出每一天最火的keywords,存放在test/key_words下
4.Get_keynews.Get_keynews(i)函式,通過每一個使用者最後一次瀏覽的新聞,比對看有沒有出現當天的熱門keywords。如果出現,就推薦當天包含這個keywords的其它新聞。迴圈Global_param.number_day天,生成test/result.txt檔案
5. Delete_Repeat.Delete_Repeat()函式,去除result中的重複項,生成test/result_no_repeat.txt
6.Get_hot_result.get_hot_result(Global_param.hot_rate)函式,因為上面生成的result_no_repeat函式可能出現,每個使用者推薦過多的情況,影響準確率。所以用這個函式控制數量,每個使用者只推薦新聞熱度相對高的候選項。最終結果集
test/result_no_repeat_hot.txt
注意:test下的result.txt檔案每執行一次程式要手動清空,其它檔案都是自動生成不用處理。
專案地址:https://github.com/X-Brain/News-Recommend-System(src資料夾下是程式碼,test下是資料、和文件結構)
希望大家有什麼建議,可以在部落格留言,或者在github上發issue,希望有更多的人蔘與貢獻。
/********************************
* 本文來自部落格 “李博Garvin“
* 轉載請標明出處:http://blog.csdn.net/buptgshengod
******************************************/
相關文章
- 個性化推薦系統來了
- 一文看懂虛假新聞檢測(附資料集 & 論文推薦)
- 個性化推薦系統實踐應用
- 智慧推薦系統:個性化推薦引領消費新潮流
- 搜狐:新聞推薦系統的CTR預估模型模型
- 【推薦系統篇】--推薦系統之測試資料
- 五個有關推薦系統的資料
- 零基礎入門新聞推薦系統(多路召回)
- 推薦系統實踐 0x05 推薦資料集MovieLens及評測
- 推薦:門戶portal系統的兩個開發原始碼原始碼
- 基於springboot的圖書個性化推薦系統Spring Boot
- 大資料驅動下的電商個性化推薦(PPT)大資料
- python 推薦系統Python
- 乾貨|個性化推薦系統五大研究熱點之可解釋推薦(五)
- 淺談個性化推薦系統中的非取樣學習
- 百億資料個性化推薦:彈幕工程架構演進架構
- 1億行為資料,知乎、清華開放國內最大個性化推薦實際互動資料集
- 天池新聞推薦入門賽之【資料分析】Task02
- 騰訊:僅24%使用者認為個性化推薦系統“靠譜”
- 愛奇藝個性化推薦排序實踐排序
- 餐館個性化推薦應用
- 推薦系統應該如何保障推薦的多樣性?
- 基於深度學習的圖書管理推薦系統(附python程式碼)深度學習Python
- 大資料應用——資料探勘之推薦系統大資料
- 不到40行 Python 程式碼打造一個簡單的推薦系統Python
- 乾貨|個性化推薦系統五大研究熱點之強化學習(三)強化學習
- 基於Apriori關聯規則的電影推薦系統(附python程式碼)Python
- Netflix 推薦系統(part three)-個性主頁生成
- 電影推薦系統資料預處理
- 如何設計一個最簡化的推薦系統
- 基於使用者偏好的新聞推薦系統的設計與實現
- python酒店相似度推薦系統Python
- 推薦系統
- IDEA外掛和個性化配置推薦Idea
- 推薦一款Python資料視覺化神器Python視覺化
- 【推薦】常見的Python資料視覺化庫Python視覺化
- O'Reilly精品圖書推薦:Python網路資料採集Python
- 乾貨 | 個性化推薦系統五大研究熱點之深度學習(一)深度學習