機器學習之統計分析(2)
前言
最近在阿里雲數加平臺上學習一下機器學習,把學習中整理的資料記錄於此,已備檢視,以下資料主要是概念解釋及應用。
相關係數矩陣
瞭解相關矩陣前先了解相關係數。
相關係數的取值範圍為[-1,1],當相關係數為1時,表示正相關;當相關係數為-1時,表示負相關;當相關係數為0時,表示不相關。
正相關:因變數隨著自變數的增大而增大
負相關:因變數隨著自變數的增大而減小
計算公式:
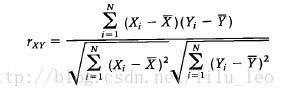
相關矩陣
相關矩陣中每個值都是代表原矩陣中各列之間的相關係數(相關矩陣為方陣,階數為原矩陣的列數),對角線上都是原矩陣各列與自身的相關係數,所以對角線的值均為1。
參考資料
樣本檢驗
雙樣本T檢驗
- 獨立樣本是指兩個樣本之間彼此獨立。獨立樣本T檢驗是檢測兩個樣本之間是否有顯著性差異。前提是兩個樣本相互獨立,來自的兩個總體服從正態分佈。
- 配對樣本T檢驗是檢驗來自兩配對總體的均值是否有顯著性差異。
來自維基百科的定義:
其零假設為兩個正態分佈的總體的均值之差為某實數,例如檢驗二群人的身高之平均是否相等。這一檢驗通常被稱為學生t檢驗。但更為嚴格地說,只有兩個總體的方差是相等的情況下,才稱為學生t檢驗;否則,有時被稱為Welch檢驗。以上談到的檢驗一般被稱作“未配對”或“獨立樣本”t檢驗,我們特別是在兩個被檢驗的樣本沒有重疊部分時用到這種檢驗方式。
單樣本T檢驗
單樣本T檢驗是檢驗某個變數的總體均值和某指定值之間是否存在顯著差異。T檢驗的前提是樣本總體服從正態分佈。
來自維基百科的定義:
檢驗一個正態分佈的總體的均值是否在滿足零假設的值之內,例如檢驗一群人的身高的平均是否符合170公分。
參考資料
正態檢驗
正態性檢驗是檢驗觀測值是否服從正態分佈,本元件由三種檢驗方法組成,包括Anderson-Darling Test, Kolmogorov-Smirnov Test,以及QQ圖。
原假設H0:觀測值服從正態分佈,H1:觀測值不服從正態分佈
KS的p值計算方法採用漸進計算KS分佈的CDF,無論樣本量多大都採用的是該方法
QQ圖在樣本量>1000時,會取樣進行計算和畫圖輸出,因此圖中的資料點不一定覆蓋所有樣本
效果圖
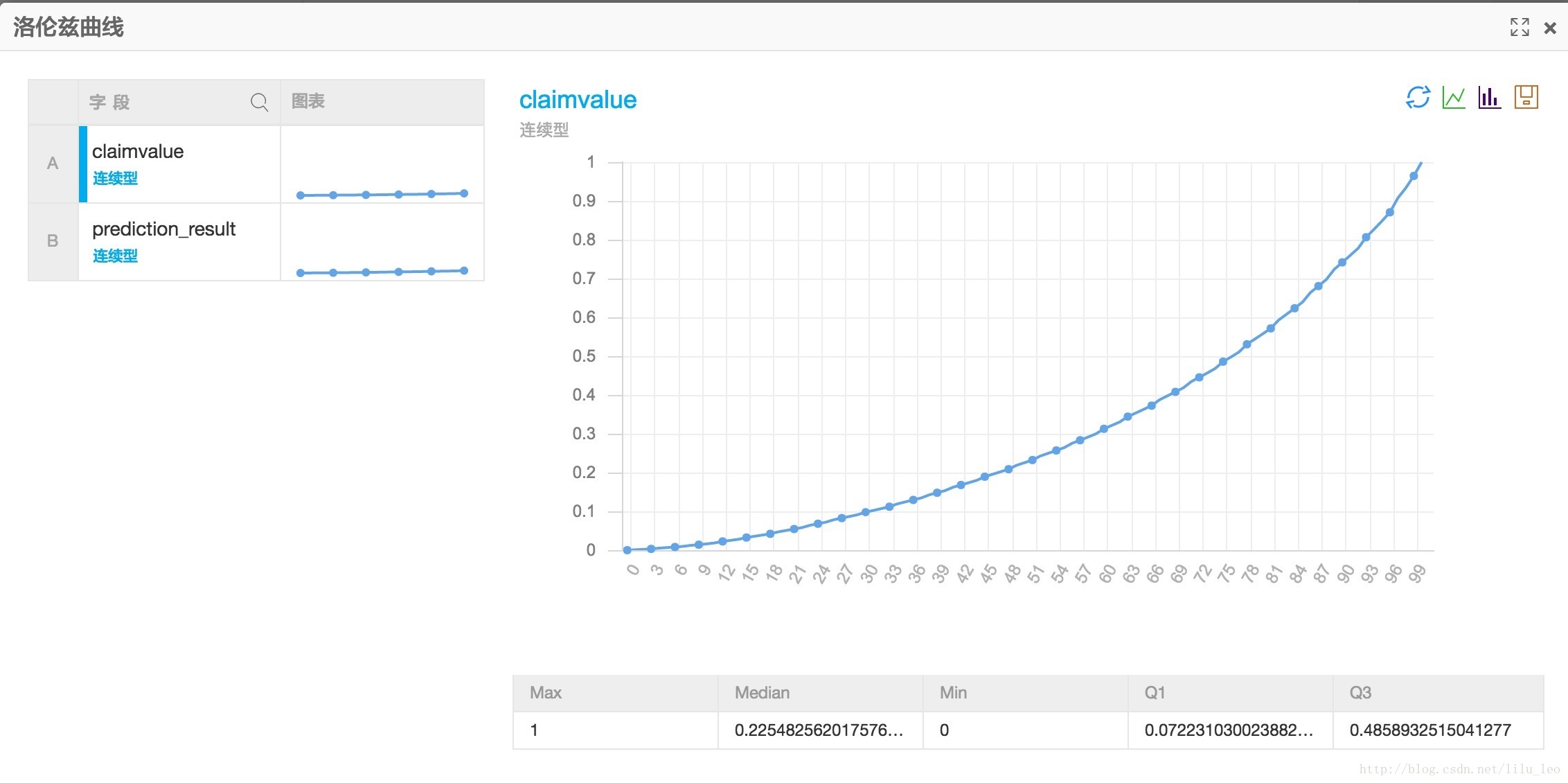
洛倫茲曲線
洛倫茲曲線研究的是國民收入在國民之間的分配問題。為了研究國民收入在國民之間的分配問題,美國統計學家(或說奧地利統計學家)M.O.洛倫茲(Max Otto Lorenz,1903- )1907年(或說1905年)提出了著名的洛倫茲曲線。義大利經濟學家基尼在此基礎上定義了基尼係數。 畫一個矩形,矩形的高衡量社會財富的百分比,將之分為N等份,每一等分為1/N的社會總財富。在矩形的長上,將所有家庭從最貧者到最富者自左向右排列,也分為N等分,第一個等份代表收入最低的1/N的家庭。在這個矩形中,將每1/N的家庭所有擁有的財富的佔比累積起來,並將相應的點畫在圖中,便得到了一條曲線就是洛倫茲曲線。
效果圖
參考資料
分位數及百分位數
Quartile(四分位數)
四分位數(Quartile)是統計學中分位數的一種,即把所有數值由小到大排列並分成四等份,處於三個分割點位置的數值就是四分位數。
第一四分位數 (Q1),又稱“較小四分位數”,等於該樣本中所有數值由小到大排列後第25%的數字。
第二四分位數 (Q2),又稱“中位數”,等於該樣本中所有數值由小到大排列後第50%的數字。
第三四分位數 (Q3),又稱“較大四分位數”,等於該樣本中所有數值由小到大排列後第75%的數字。
第三四分位數與第一四分位數的差距又稱四分位距(InterQuartile Range, IQR)
百分位
計算某列的百分位。
維基百科定義:
百分位數,統計學術語,如果將一組資料從小到大排序,並計算相應的累計百分位,則某一百分位所對應資料的值就稱為這一百分位的百分位數。運用在教育統計學中,例如表現測驗成績時。(維基百科)
參考資料
皮爾森係數
在統計學中,皮爾遜積矩相關係數(英語:Pearson product-moment correlation coefficient,又稱作 PPMCC或PCCs[1], 文章中常用r或Pearson’s r表示)用於度量兩個變數X和Y之間的相關(線性相關),其值介於-1與1之間。在自然科學領域中,該係數廣泛用於度量兩個變數之間的相關程度。它是由卡爾·皮爾遜從弗朗西斯·高爾頓在19世紀80年代提出的一個相似卻又稍有不同的想法演變而來的。[2][3]這個相關係數也稱作“皮爾森相關係數r”。
公式定義
兩個變數之間的皮爾遜相關係數定義為兩個變數之間的協方差和標準差的商:

數值含義
樣本的簡單相關係數一般用r表示,其中n 為樣本量, 分別為兩個變數的觀測值和均值。r描述的是兩個變數間線性相關強弱的程度。r的取值在-1與+1之間,若r>0,表明兩個變數是正相關,即一個變數的值越大,另一個變數的值也會越大;若r<0,表明兩個變數是負相關,即一個變數的值越大另一個變數的值反而會越小。r 的絕對值越大表明相關性越強,要注意的是這裡並不存在因果關係。若r=0,表明兩個變數間不是線性相關,但有可能是其他方式的相關(比如曲線方式)
參考資料
直方圖(多欄位)
可選擇多個欄位檢視直方圖
離散值特徵分析
- 統計離散值的gini係數、entropy、對應label個數等
- 空值不過濾,當做一個列舉值計算
- 稀疏格式表示,某列的某個列舉值如果只有1個Label,對於未出現的label不輸出0
- 對於每個離散值的gini,entropy都乘以該離散值的概率
圖示如下:

gini 係數
維基百科定義:
基尼係數(英語:Gini coefficient),是20世紀初義大利學者科拉多·基尼根據勞倫茨曲線所定義的判斷年收入分配公平程度的指標[2]。是比例數值,在0和1之間。基尼指數(Gini index)是指基尼係數乘100倍作百分比表示。在民眾收入中,如基尼係數最大為“1”,最小為“0”。前者表示居民之間的年收入分配絕對不平均(即該年所有收入都集中在一個人手裡,其餘的國民沒有收入),而後者則表示居民之間的該年收入分配絕對平均,即人與人之間收入絕對平等,這基尼係數的實際數值只能介於這兩種極端情況,即0~1之間。基尼係數越小,年收入分配越平均,基尼係數越大,年收入分配越不平均。要注意基尼係數只計算某一時段,如一年的收入,不計算已有財產,因此它不能反映國民的總積累財富分配情況。
entropy(熵)
系統的熵值直接反映了它所處狀態的均勻程度,系統的熵值越小,它所處的狀態越是有序,越不均勻;系統的熵值越大,它所處的狀態越是無序,越均勻。
連結資料
相關文章
- 機器學習之統計分析(1)機器學習
- 統計機器學習機器學習
- 機器學習_統計模型之(一)貝葉斯公式機器學習模型公式
- 機器學習-聚類分析之DBSCAN機器學習聚類
- oracle之autotrace統計資訊分析Oracle
- 分析函式之排名統計函式
- 機器學習_統計模型之(二)貝葉斯網路機器學習模型
- 機器學習數學知識積累之數理統計機器學習
- 統計機器學習 -- 目錄機器學習
- 機器學習之迴歸分析--預測值機器學習
- 【week2】 詞頻統計效能分析
- 空間統計之點資料分析
- 機器學習中的概率統計機器學習
- 機器學習降維之線性判別分析機器學習
- 多元統計之因子分析模型及Python分析示例模型Python
- 談談機器學習與傳統程式設計之間的區別機器學習程式設計
- 生產sql調優之統計資訊分析SQL
- 機器學習之機器學習概念機器學習
- Spark2 探索性資料統計分析Spark
- 機器學習-2機器學習
- 機器學習(2)機器學習
- 吳恩達機器學習筆記 —— 12 機器學習系統設計吳恩達機器學習筆記
- 史丹佛機器學習教程學習筆記之2機器學習筆記
- 多元統計分析01:多元統計分析基礎
- 機器學習可視分析框架設計與實現機器學習框架
- 機器學習之邏輯迴歸:計算概率機器學習邏輯迴歸
- Hive(統計分析)Hive
- 《Linux核心分析》 之 作業系統是如何工作的。2Linux作業系統
- Python資料分析之 pandas彙總和計算描述統計Python
- 機器學習之邏輯迴歸:計算機率機器學習邏輯迴歸計算機
- 機器學習之皮毛機器學習
- 機器學習之pca機器學習PCA
- 機器學習--白板推導系列筆記2 概率:高斯分佈之極大似然估計機器學習筆記
- 效能工具之linux常見日誌統計分析命令Linux
- NLP之統計句法分析(PCFG+CYK演算法)演算法
- 【機器學習】--Python機器學習庫之Numpy機器學習Python
- 《機器學習導論》和《統計機器學習》學習資料:張志華教授機器學習
- Tomcat原始碼分析2 之 Protocol實現分析Tomcat原始碼Protocol