教你用深度學習LSTM網路預測流行音樂趨勢(附程式碼)
一、 LSTM網路原理
1.1 要點介紹
- LSTM網路用來處理帶“序列”(sequence)性質的資料。比如時間序列的資料,像每天的股價走勢情況,機械振動訊號的時域波形,以及類似於自然語言這種本身帶有順序性質的由有序單片語合的資料。
- LSTM本身不是一個獨立存在的網路結構,只是整個神經網路的一部分,即由LSTM結構取代原始網路中的隱層單元部分。
- LSTM網路具有“記憶性”。其原因在於不同“時間點”之間的網路存在連線,而不是單個時間點處的網路存在前饋或者反饋。如下圖2中的LSTM單元(隱層單元)所示。圖3是不同時刻情況下的網路展開圖。圖中虛線連線代表時刻,“本身的網路”結構連線用實線表示。
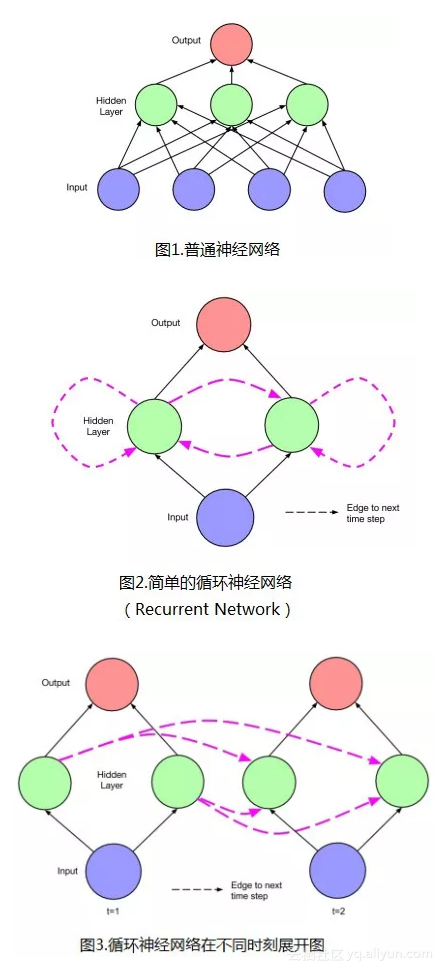
1.2 LSTM單元結構圖
圖4,5是現在比較常用的LSTM單元結構示意圖:
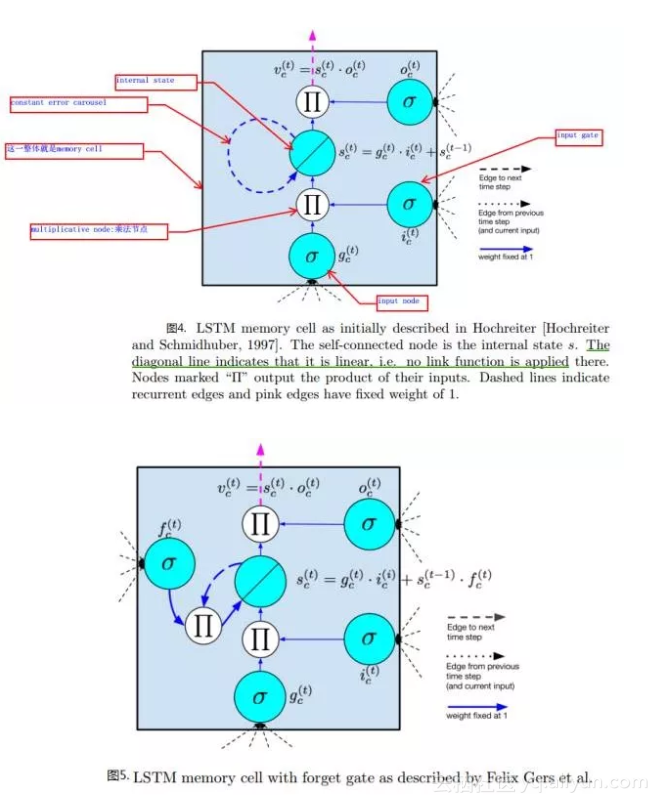
其主要結構成分包含如下:
- 輸入節點input
node:接受上一時刻隱層單元的輸出及當前時刻是樣本輸入;
- 輸入門input
gate:可以看到輸入門會和輸入節點的值相乘,組成LSTM中internal state單元值的一部分,當門的輸出為1時,輸入節點的啟用值全部流向internal state,當門的輸出為0時,輸入節點的值對internal state沒有影響。
- 內部狀態internal state。
- 遺忘門forget gate:用於重新整理internal state的狀態,控制internal state的上一狀態對當前狀態的影響。
各節點及門與隱藏單元輸出的關係參見圖4,圖5所示。
二、程式碼示例
後臺回覆關鍵詞“音樂”,下載完整程式碼及資料集
執行環境:windows下的spyder
語言:python 2.7,以及Keras深度學習庫。
由於看這個賽題前,沒有一點Python基礎,所以也是邊想思路邊學Python,對Python中的資料結構不怎麼了解,所以程式碼寫得有點爛。但整個程式碼是可以執行無誤的。這也是初賽時程式碼的最終版本。
2.1 示例介紹
主要以今年參加的“2016年阿里流行音樂趨勢預測”為例。
時間過得很快,今天已是第二賽季的最後一天了,我從5.18開始接觸賽題,到6.14上午10點第一賽季截止,這一期間,由於是線下賽,可以用到各種模型,而自已又是做深度學習(deep learning)方向的研究,所以選擇了基於LSTM的迴圈神經網路模型,結果也很幸運,進入到了第二賽季。開始接觸深度學習也有大半年了,能夠將自已所學用到這次真正的實際生活應用中,結果也還可以,自已感覺很欣慰。突然意識到,自已學習生涯這麼多年,我想“學有所成,學有所用”該是我今後努力的方向和動力了吧。
下面我簡單的介紹一下賽題:
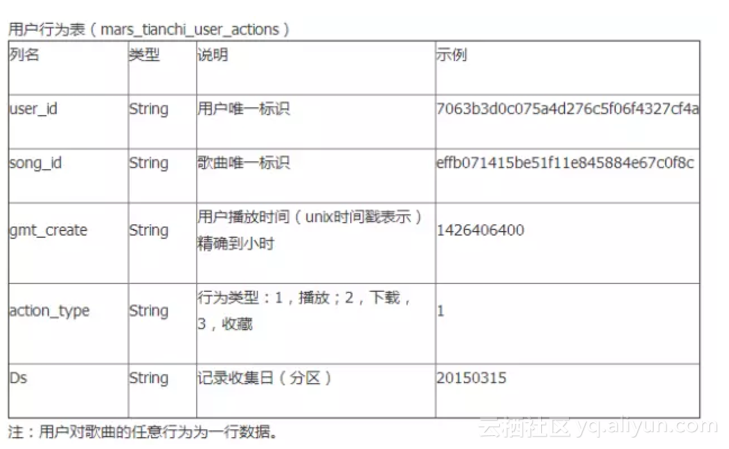
官方給的“輸入”,共兩張表:
- 一張是使用者行為表(時間跨度20150301-20150830)mars_tianchi_user_actions,主要描述使用者對歌曲的收藏,下載,播放等行為;
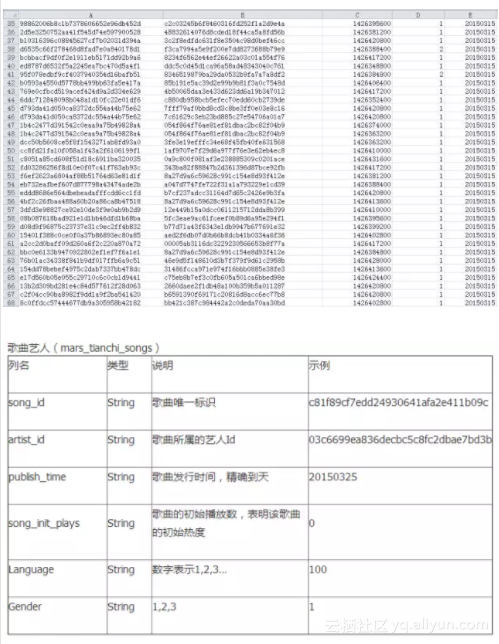
- 一張是歌曲資訊表mars_tianchi_songs,主要用來描述歌曲所屬的藝人,及歌曲的相關資訊,如發行時間,初始熱度,語言等。
樣例:
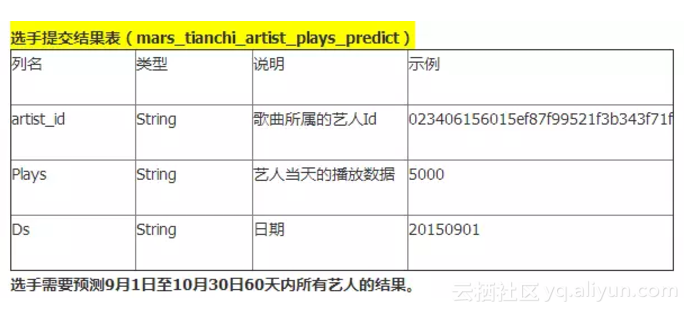
官方要求“輸出”:預測隨後2個月(20150901-20151030)每個歌手每天的播放量。輸出格式:
由於是對歌手的播放量進行預測,所以直接對每個歌手的“播放量”這一物件進行統計,檢視在20150301-20151030這8個月內歌手的播放量變化趨勢,並以每天的播放量,連續3天的播放均值,連續3天的播放方差,作為一個時間點的樣本,“滑動”構建神經網路的訓練集。網路的構成如下:
- 輸入層:3個神經元,分別代表播放量,播放均值,播放方差;
- 第一隱層:LSTM結構單元,帶有35個LSTM單元;
- 第二隱層:LSTM結構單元,帶有10個LSTM單元;
- 輸出層:3個神經元,代表和輸入層相同的含義。

相關文章
- 『阿里大資料競賽』音樂流行趨勢預測_不斷更新阿里大資料
- 如何用LSTMs做預測?(附程式碼)| 博士帶你學LSTM
- 利用深度學習和機器學習預測股票市場(附程式碼)深度學習機器學習
- 深度學習-LSTM深度學習
- 網路流量預測入門(三)之LSTM預測網路流量
- 深度學習四從迴圈神經網路入手學習LSTM及GRU深度學習神經網路
- 深度學習和神經網路的七大顯著趨勢深度學習神經網路
- LSTM機器學習生成音樂機器學習
- 趨勢預測:2021年五大流行的程式語言
- NLP&深度學習:近期趨勢概述深度學習
- 2016年網頁設計領域11個流行趨勢預測網頁
- 深度學習(三)之LSTM寫詩深度學習
- 手把手教你用Python庫Keras做預測(附程式碼)PythonKeras
- 2014年社交網路八大趨勢預測
- 深度學習技術發展趨勢淺析深度學習
- 網路安全預測:2019年五大網路安全趨勢展望
- 可微分式程式設計:深度學習發展的新趨勢?程式設計深度學習
- 2019年九大網路安全發展趨勢預測
- 安全專家:2007年網路安全趨勢預測
- 【深度學習】深度學習md筆記總結第1篇:深度學習課程,要求【附程式碼文件】深度學習筆記
- 最後一期:如何更新LSTM模型?(附程式碼)| 博士帶你學LSTM模型
- 深度學習一:深度前饋網路深度學習
- IDC:2021年中國網路市場發展趨勢預測
- 用深度學習打造自己的音樂推薦系統深度學習
- 深度學習系列(2)——神經網路與深度學習深度學習神經網路
- 2011年網際網路安全發展趨勢五大預測
- 【論文閱讀】增量學習近期進展及未來趨勢預測
- 用科學知識圖譜預測學科前沿趨勢
- 2020年程式設計趨勢預測程式設計
- 迴圈神經網路LSTM RNN迴歸:sin曲線預測神經網路RNN
- 音數協敖然:立足全球視野,預測產業發展趨勢產業
- 深度學習——如何用LSTM進行文字分類深度學習文字分類
- Facebook AI 負責人:深度學習技術趨勢報告AI深度學習
- 歐美流行音樂資料庫資料庫
- 網頁背景音樂程式碼 — 終極篇網頁
- 深度學習(五)之原型網路深度學習原型
- 深度學習之Transformer網路深度學習ORM
- 深度學習之殘差網路深度學習