Linux核心中的軟中斷、tasklet和工作佇列詳解
[TOC]
本文基於Linux2.6.32核心版本。
引言
軟中斷、tasklet和工作佇列並不是Linux核心中一直存在的機制,而是由更早版本的核心中的“下半部”(bottom half)演變而來。下半部的機制實際上包括五種,但2.6版本的核心中,下半部和任務佇列的函式都消失了,只剩下了前三者。
介紹這三種下半部實現之前,有必要說一下上半部與下半部的區別。
上半部指的是中斷處理程式,下半部則指的是一些雖然與中斷有相關性但是可以延後執行的任務。舉個例子:在網路傳輸中,網路卡接收到資料包這個事件不一定需要馬上被處理,適合用下半部去實現;但是使用者敲擊鍵盤這樣的事件就必須馬上被響應,應該用中斷實現。
兩者的主要區別在於:中斷不能被相同型別的中斷打斷,而下半部依然可以被中斷打斷;中斷對於時間非常敏感,而下半部基本上都是一些可以延遲的工作。由於二者的這種區別,所以對於一個工作是放在上半部還是放在下半部去執行,可以參考下面4條:
- 如果一個任務對時間非常敏感,將其放在中斷處理程式中執行。
- 如果一個任務和硬體相關,將其放在中斷處理程式中執行。
- 如果一個任務要保證不被其他中斷(特別是相同的中斷)打斷,將其放在中斷處理程式中執行。
- 其他所有任務,考慮放在下半部去執行。
有寫核心任務需要延後執行,因此才有的下半部,進而實現了三種實現下半部的方法。這就是本文要討論的軟中斷、tasklet和工作佇列。
下表可以更直觀的看到它們之間的關係。
軟中斷
軟中斷作為下半部機制的代表,是隨著SMP(share memory processor)的出現應運而生的,它也是tasklet實現的基礎(tasklet實際上只是在軟中斷的基礎上新增了一定的機制)。軟中斷一般是“可延遲函式”的總稱,有時候也包括了tasklet(請讀者在遇到的時候根據上下文推斷是否包含tasklet)。它的出現就是因為要滿足上面所提出的上半部和下半部的區別,使得對時間不敏感的任務延後執行,而且可以在多個CPU上並行執行,使得總的系統效率可以更高。它的特性包括:
- 產生後並不是馬上可以執行,必須要等待核心的排程才能執行。軟中斷不能被自己打斷(即單個cpu上軟中斷不能巢狀執行),只能被硬體中斷打斷(上半部)。
- 可以併發執行在多個CPU上(即使同一型別的也可以)。所以軟中斷必須設計為可重入的函式(允許多個CPU同時操作),因此也需要使用自旋鎖來保其資料結構。
相關資料結構
- 軟中斷描述符
struct softirq_action{ void (*action)(struct softirq_action *);};
描述每一種型別的軟中斷,其中void(*action)是軟中斷觸發時的執行函式。 - 軟中斷全域性資料和型別
static struct softirq_action softirq_vec[NR_SOFTIRQS] __cacheline_aligned_in_smp;
enum
{
HI_SOFTIRQ=0, /*用於高優先順序的tasklet*/
TIMER_SOFTIRQ, /*用於定時器的下半部*/
NET_TX_SOFTIRQ, /*用於網路層發包*/
NET_RX_SOFTIRQ, /*用於網路層收報*/
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ, /*用於低優先順序的tasklet*/
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */
NR_SOFTIRQS
};相關API
- 註冊軟中斷
void open_softirq(int nr, void (*action)(struct softirq_action *))即註冊對應型別的處理函式到全域性陣列softirq_vec中。例如網路發包對應型別為NET_TX_SOFTIRQ的處理函式net_tx_action.
- 觸發軟中斷
void raise_softirq(unsigned int nr)實際上即以軟中斷型別nr作為偏移量置位每cpu變數irq_stat[cpu_id]的成員變數__softirq_pending,這也是同一型別軟中斷可以在多個cpu上並行執行的根本原因。
- 軟中斷執行函式
do_softirq-->__do_softirq執行軟中斷處理函式__do_softirq前首先要滿足兩個條件:
(1)不在中斷中(硬中斷、軟中斷和NMI) 。1
(2)有軟中斷處於pending狀態。
系統這麼設計是為了避免軟體中斷在中斷巢狀中被呼叫,並且達到在單個CPU上軟體中斷不能被重入的目的。對於ARM架構的CPU不存在中斷巢狀中呼叫軟體中斷的問題,因為ARM架構的CPU在處理硬體中斷的過程中是關閉掉中斷的。只有在進入了軟中斷處理過程中之後才會開啟硬體中斷,如果在軟體中斷處理過程中有硬體中斷巢狀,也不會再次呼叫軟中斷,because硬體中斷是軟體中斷處理過程中再次進入的,此時preempt_count已經記錄了軟體中斷!對於其它架構的CPU,有可能在觸發呼叫軟體中斷前,也就是還在處理硬體中斷的時候,就已經開啟了硬體中斷,可能會發生中斷巢狀,在中斷巢狀中是不允許呼叫軟體中斷處理的。Why?我的理解是,在發生中斷巢狀的時候,表明這個時候是系統突發繁忙的時候,核心第一要務就是趕緊把中斷中的事情處理完成,退出中斷巢狀。避免多次巢狀,哪裡有時間處理軟體中斷,所以把軟體中斷推遲到了所有中斷處理完成的時候才能觸發軟體中斷。
實現原理和例項
軟中斷的排程時機:
- do_irq完成I/O中斷時呼叫irq_exit。
- 系統使用I/O APIC,在處理完本地時鐘中斷時。
- local_bh_enable,即開啟本地軟中斷時。
- SMP系統中,cpu處理完被CALL_FUNCTION_VECTOR處理器間中斷所觸發的函式時。
- ksoftirqd/n執行緒被喚醒時。
下面以從中斷處理返回函式irq_exit中呼叫軟中斷為例詳細說明。
觸發和初始化的的流程如圖所示:
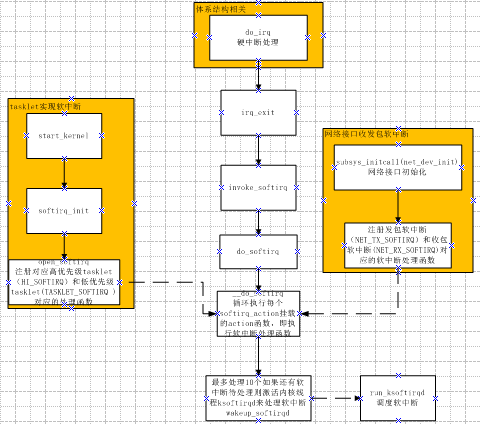
軟中斷處理流程
asmlinkage void __do_softirq(void)
{
struct softirq_action *h;
__u32 pending;
int max_restart = MAX_SOFTIRQ_RESTART;
int cpu;
pending = local_softirq_pending();
account_system_vtime(current);
__local_bh_disable((unsigned long)__builtin_return_address(0));
lockdep_softirq_enter();
cpu = smp_processor_id();
restart:
/* Reset the pending bitmask before enabling irqs */
set_softirq_pending(0);
local_irq_enable();
h = softirq_vec;
do {
if (pending & 1) {
int prev_count = preempt_count();
kstat_incr_softirqs_this_cpu(h - softirq_vec);
trace_softirq_entry(h, softirq_vec);
h->action(h);
trace_softirq_exit(h, softirq_vec);
if (unlikely(prev_count != preempt_count())) {
printk(KERN_ERR "huh, entered softirq %td %s %p"
"with preempt_count %08x,"
" exited with %08x?\n", h - softirq_vec,
softirq_to_name[h - softirq_vec],
h->action, prev_count, preempt_count());
preempt_count() = prev_count;
}
rcu_bh_qs(cpu);
}
h++;
pending >>= 1;
} while (pending);
local_irq_disable();
pending = local_softirq_pending();
if (pending && --max_restart)
goto restart;
if (pending)
wakeup_softirqd();
lockdep_softirq_exit();
account_system_vtime(current);
_local_bh_enable();
}- 首先呼叫local_softirq_pending函式取得目前有哪些位存在軟體中斷。
- 呼叫__local_bh_disable關閉軟中斷,其實就是設定正在處理軟體中斷標記,在同一個CPU上使得不能重入__do_softirq函式。
- 重新設定軟中斷標記為0,set_softirq_pending重新設定軟中斷標記為0,這樣在之後重新開啟中斷之後硬體中斷中又可以設定軟體中斷位。
- 呼叫local_irq_enable,開啟硬體中斷。
- 之後在一個迴圈中,遍歷pending標誌的每一位,如果這一位設定就會呼叫軟體中斷的處理函式。在這個過程中硬體中斷是開啟的,隨時可以打斷軟體中斷。這樣保證硬體中斷不會丟失。
- 之後關閉硬體中斷(local_irq_disable),檢視是否又有軟體中斷處於pending狀態,如果是,並且在本次呼叫__do_softirq函式過程中沒有累計重複進入軟體中斷處理的次數超過max_restart=10次,就可以重新呼叫軟體中斷處理。如果超過了10次,就呼叫wakeup_softirqd()喚醒核心的一個程式來處理軟體中斷。設立10次的限制,也是為了避免影響系統響應時間。
- 呼叫_local_bh_enable開啟軟中斷。
軟中斷核心執行緒
之前我們分析的觸發軟體中斷的位置其實是中斷上下文中,而在軟中斷的核心執行緒中實際已經是程式的上下文。
這裡說的軟中斷上下文指的就是系統為每個CPU建立的ksoftirqd程式。
軟中斷的核心程式中主要有兩個大迴圈,外層的迴圈處理有軟體中斷就處理,沒有軟體中斷就休眠。內層的迴圈處理軟體中斷,每迴圈一次都試探一次是否過長時間佔據了CPU,需要排程就釋放CPU給其它程式。具體的操作在註釋中做了解釋。
set_current_state(TASK_INTERRUPTIBLE);
//外層大迴圈。
while (!kthread_should_stop()) {
preempt_disable();//禁止核心搶佔,自己掌握cpu
if (!local_softirq_pending()) {
preempt_enable_no_resched();
//如果沒有軟中斷在pending中就讓出cpu
schedule();
//排程之後重新掌握cpu
preempt_disable();
}
__set_current_state(TASK_RUNNING);
while (local_softirq_pending()) {
/* Preempt disable stops cpu going offline.
If already offline, we'll be on wrong CPU:
don't process */
if (cpu_is_offline((long)__bind_cpu))
goto wait_to_die;
//有軟中斷則開始軟中斷排程
do_softirq();
//檢視是否需要排程,避免一直佔用cpu
preempt_enable_no_resched();
cond_resched();
preempt_disable();
rcu_sched_qs((long)__bind_cpu);
}
preempt_enable();
set_current_state(TASK_INTERRUPTIBLE);
}
__set_current_state(TASK_RUNNING);
return 0;
wait_to_die:
preempt_enable();
/* Wait for kthread_stop */
set_current_state(TASK_INTERRUPTIBLE);
while (!kthread_should_stop()) {
schedule();
set_current_state(TASK_INTERRUPTIBLE);
}
__set_current_state(TASK_RUNNING);
return 0;tasklet
由於軟中斷必須使用可重入函式,這就導致設計上的複雜度變高,作為裝置驅動程式的開發者來說,增加了負擔。而如果某種應用並不需要在多個CPU上並行執行,那麼軟中斷其實是沒有必要的。因此誕生了彌補以上兩個要求的tasklet。它具有以下特性:
a)一種特定型別的tasklet只能執行在一個CPU上,不能並行,只能序列執行。
b)多個不同型別的tasklet可以並行在多個CPU上。
c)軟中斷是靜態分配的,在核心編譯好之後,就不能改變。但tasklet就靈活許多,可以在執行時改變(比如新增模組時)。
tasklet是在兩種軟中斷型別的基礎上實現的,因此如果不需要軟中斷的並行特性,tasklet就是最好的選擇。也就是說tasklet是軟中斷的一種特殊用法,即延遲情況下的序列執行。
相關資料結構
- tasklet描述符
struct tasklet_struct
{
struct tasklet_struct *next;//將多個tasklet連結成單向迴圈連結串列
unsigned long state;//TASKLET_STATE_SCHED(Tasklet is scheduled for execution) TASKLET_STATE_RUN(Tasklet is running (SMP only))
atomic_t count;//0:啟用tasklet 非0:禁用tasklet
void (*func)(unsigned long); //使用者自定義函式
unsigned long data; //函式入參
};- tasklet連結串列
static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);//低優先順序
static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);//高優先順序相關API
- 定義tasklet
#define DECLARE_TASKLET(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(0), func, data }
//定義名字為name的非啟用tasklet
#define DECLARE_TASKLET_DISABLED(name, func, data) \
struct tasklet_struct name = { NULL, 0, ATOMIC_INIT(1), func, data }
//定義名字為name的啟用tasklet
void tasklet_init(struct tasklet_struct *t,void (*func)(unsigned long), unsigned long data)
//動態初始化tasklet- tasklet操作
static inline void tasklet_disable(struct tasklet_struct *t)
//函式暫時禁止給定的tasklet被tasklet_schedule排程,直到這個tasklet被再次被enable;若這個tasklet當前在執行, 這個函式忙等待直到這個tasklet退出
static inline void tasklet_enable(struct tasklet_struct *t)
//使能一個之前被disable的tasklet;若這個tasklet已經被排程, 它會很快執行。tasklet_enable和tasklet_disable必須匹配呼叫, 因為核心跟蹤每個tasklet的"禁止次數"
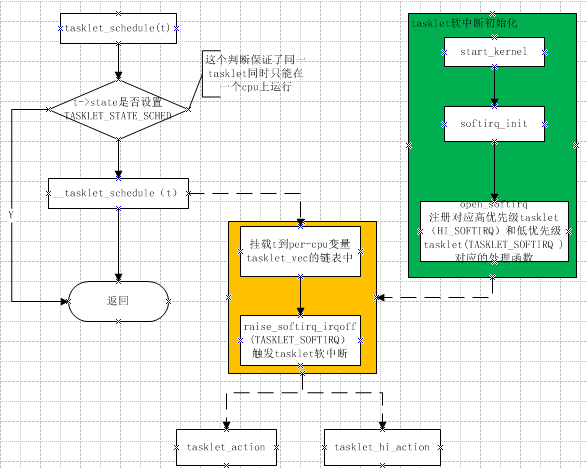
static inline void tasklet_schedule(struct tasklet_struct *t)
//排程 tasklet 執行,如果tasklet在執行中被排程, 它在完成後會再次執行; 這保證了在其他事件被處理當中發生的事件受到應有的注意. 這個做法也允許一個 tasklet 重新排程它自己
tasklet_hi_schedule(struct tasklet_struct *t)
//和tasklet_schedule類似,只是在更高優先順序執行。當軟中斷處理執行時, 它處理高優先順序 tasklet 在其他軟中斷之前,只有具有低響應週期要求的驅動才應使用這個函式, 可避免其他軟體中斷處理引入的附加週期.
tasklet_kill(struct tasklet_struct *t)
//確保了 tasklet 不會被再次排程來執行,通常當一個裝置正被關閉或者模組解除安裝時被呼叫。如果 tasklet 正在執行, 這個函式等待直到它執行完畢。若 tasklet 重新排程它自己,則必須阻止在呼叫 tasklet_kill 前它重新排程它自己,如同使用 del_timer_sync 實現原理
- 排程原理
static inline void tasklet_schedule(struct tasklet_struct *t)
{
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_schedule(t);
}
void __tasklet_schedule(struct tasklet_struct *t)
{
unsigned long flags;
local_irq_save(flags);
t->next = NULL;
*__get_cpu_var(tasklet_vec).tail = t;
__get_cpu_var(tasklet_vec).tail = &(t->next);//加入低優先順序列表
raise_softirq_irqoff(TASKLET_SOFTIRQ);//觸發軟中斷
local_irq_restore(flags);
}- tasklet執行過程
TASKLET_SOFTIRQ對應執行函式為tasklet_action,HI_SOFTIRQ為tasklet_hi_action,以tasklet_action為例說明,tasklet_hi_action大同小異。
static void tasklet_action(struct softirq_action *a)
{
struct tasklet_struct *list;
local_irq_disable();
list = __get_cpu_var(tasklet_vec).head;
__get_cpu_var(tasklet_vec).head = NULL;
__get_cpu_var(tasklet_vec).tail = &__get_cpu_var(tasklet_vec).head;//取得tasklet連結串列
local_irq_enable();
while (list) {
struct tasklet_struct *t = list;
list = list->next;
if (tasklet_trylock(t)) {
if (!atomic_read(&t->count)) {
//執行tasklet
if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
BUG();
t->func(t->data);
tasklet_unlock(t);
continue;
}
tasklet_unlock(t);
}
//如果t->count的值不等於0,說明這個tasklet在排程之後,被disable掉了,所以會將tasklet結構體重新放回到tasklet_vec連結串列,並重新排程TASKLET_SOFTIRQ軟中斷,在之後enable這個tasklet之後重新再執行它
local_irq_disable();
t->next = NULL;
*__get_cpu_var(tasklet_vec).tail = t;
__get_cpu_var(tasklet_vec).tail = &(t->next);
__raise_softirq_irqoff(TASKLET_SOFTIRQ);
local_irq_enable();
}
}
工作佇列
從上面的介紹看以看出,軟中斷執行在中斷上下文中,因此不能阻塞和睡眠,而tasklet使用軟中斷實現,當然也不能阻塞和睡眠。但如果某延遲處理函式需要睡眠或者阻塞呢?沒關係工作佇列就可以如您所願了。
把推後執行的任務叫做工作(work),描述它的資料結構為work_struct ,這些工作以佇列結構組織成工作佇列(workqueue),其資料結構為workqueue_struct ,而工作執行緒就是負責執行工作佇列中的工作。系統預設的工作者執行緒為events。
工作佇列(work queue)是另外一種將工作推後執行的形式。工作佇列可以把工作推後,交由一個核心執行緒去執行—這個下半部分總是會在程式上下文執行,但由於是核心執行緒,其不能訪問使用者空間。最重要特點的就是工作佇列允許重新排程甚至是睡眠。
通常,在工作佇列和軟中斷/tasklet中作出選擇非常容易。可使用以下規則:
- 如果推後執行的任務需要睡眠,那麼只能選擇工作佇列。
- 如果推後執行的任務需要延時指定的時間再觸發,那麼使用工作佇列,因為其可以利用timer延時(核心定時器實現)。
- 如果推後執行的任務需要在一個tick之內處理,則使用軟中斷或tasklet,因為其可以搶佔普通程式和核心執行緒,同時不可睡眠。
- 如果推後執行的任務對延遲的時間沒有任何要求,則使用工作佇列,此時通常為無關緊要的任務。
實際上,工作佇列的本質就是將工作交給核心執行緒處理,因此其可以用核心執行緒替換。但是核心執行緒的建立和銷燬對程式設計者的要求較高,而工作佇列實現了核心執行緒的封裝,不易出錯,所以我們也推薦使用工作佇列。
相關資料結構
- 正常工作結構體
struct work_struct {
atomic_long_t data; //傳遞給工作函式的引數
#define WORK_STRUCT_PENDING 0 /* T if work item pending execution */
#define WORK_STRUCT_FLAG_MASK (3UL)
#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)
struct list_head entry; //連結串列結構,連結同一工作佇列上的工作。
work_func_t func; //工作函式,使用者自定義實現
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
//工作佇列執行函式的原型:
void (*work_func_t)(struct work_struct *work);
//該函式會由一個工作者執行緒執行,因此其在程式上下文中,可以睡眠也可以中斷。但只能在核心中執行,無法訪問使用者空間。- 延遲工作結構體(延遲的實現是在排程時延遲插入相應的工作佇列)
struct delayed_work {
struct work_struct work;
struct timer_list timer; //定時器,用於實現延遲處理
};- 工作佇列結構體
struct workqueue_struct {
struct cpu_workqueue_struct *cpu_wq; //指標陣列,其每個元素為per-cpu的工作佇列
struct list_head list;
const char *name;
int singlethread; //標記是否只建立一個工作者執行緒
int freezeable; /* Freeze threads during suspend */
int rt;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};- 每cpu工作佇列(每cpu都對應一個工作者執行緒worker_thread)
struct cpu_workqueue_struct {
spinlock_t lock;
struct list_head worklist;
wait_queue_head_t more_work;
struct work_struct *current_work;
struct workqueue_struct *wq;
struct task_struct *thread;
} ____cacheline_aligned;相關API
- 預設工作佇列
靜態建立
DECLARE_WORK(name,function); //定義正常執行的工作項
DECLARE_DELAYED_WORK(name,function);//定義延後執行的工作項
動態建立
INIT_WORK(_work, _func) //建立正常執行的工作項
INIT_DELAYED_WORK(_work, _func)//建立延後執行的工作項
排程預設工作佇列
int schedule_work(struct work_struct *work)
//對正常執行的工作進行排程,即把給定工作的處理函式提交給預設的工作佇列和工作者執行緒。工作者執行緒本質上是一個普通的核心執行緒,在預設情況下,每個CPU均有一個型別為“events”的工作者執行緒,當呼叫schedule_work時,這個工作者執行緒會被喚醒去執行工作連結串列上的所有工作。
系統預設的工作佇列名稱是:keventd_wq,預設的工作者執行緒叫:events/n,這裡的n是處理器的編號,每個處理器對應一個執行緒。比如,單處理器的系統只有events/0這樣一個執行緒。而雙處理器的系統就會多一個events/1執行緒。
預設的工作佇列和工作者執行緒由核心初始化時建立:
start_kernel()-->rest_init-->do_basic_setup-->init_workqueues
排程延遲工作
int schedule_delayed_work(struct delayed_work *dwork,unsigned long delay)
重新整理預設工作佇列
void flush_scheduled_work(void)
//此函式會一直等待,直到佇列中的所有工作都被執行。
取消延遲工作
static inline int cancel_delayed_work(struct delayed_work *work)
//flush_scheduled_work並不取消任何延遲執行的工作,因此,如果要取消延遲工作,應該呼叫cancel_delayed_work。以上均是採用預設工作者執行緒來實現工作佇列,其優點是簡單易用,缺點是如果預設工作佇列負載太重,執行效率會很低,這就需要我們建立自己的工作者執行緒和工作佇列。
- 自定義工作佇列
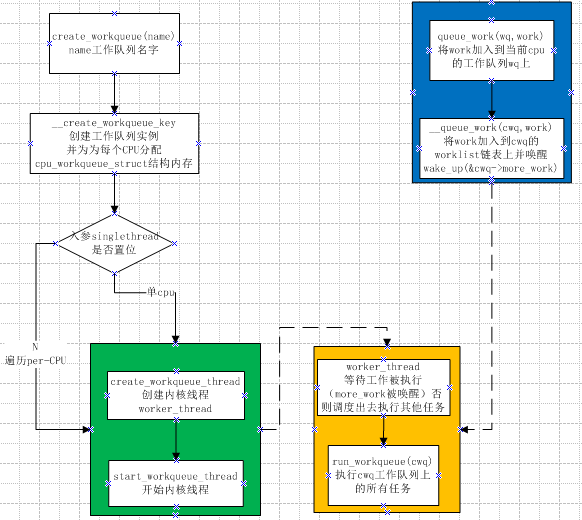
create_workqueue(name)
//巨集定義 返回值為工作佇列,name為工作執行緒名稱。建立新的工作佇列和相應的工作者執行緒,name用於該核心執行緒的命名。
int queue_work(struct workqueue_struct *wq, struct work_struct *work)
//類似於schedule_work,區別在於queue_work把給定工作提交給建立的工作佇列wq而不是預設佇列。
int queue_delayed_work(struct workqueue_struct *wq,struct delayed_work *dwork, unsigned long delay)
//排程延遲工作。
void flush_workqueue(struct workqueue_struct *wq)
//重新整理指定工作佇列。
void destroy_workqueue(struct workqueue_struct *wq)
//釋放建立的工作佇列。實現原理
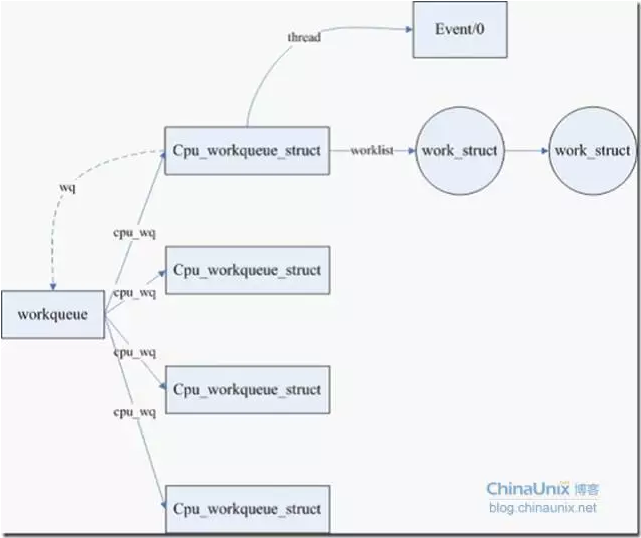
- 工作佇列的組織結構
即workqueue_struct、cpu_workqueue_struct與work_struct的關係。
一個工作佇列對應一個work_queue_struct,工作佇列中每cpu的工作佇列由cpu_workqueue_struct表示,而work_struct為其上的具體工作。
關係如下圖所示:
2.工作佇列的工作過程
- 應用例項
linux各個介面的狀態(up/down)的訊息需要通知netdev_chain上感興趣的模組同時上報使用者空間訊息。這裡使用的就是工作佇列。
具體流程圖如下所示:
- 是否處於中斷中在Linux中是通過preempt_count來判斷的,具體如下: 在linux系統的程式資料結構裡,有這麼一個資料結構:
#define preempt_count() (current_thread_info()->preempt_count)
利用preempt_count可以表示是否處於中斷處理或者軟體中斷處理過程中,如下所示:
# define hardirq_count() (preempt_count() & HARDIRQ_MASK)
#define softirq_count() (preempt_count() & SOFTIRQ_MASK)
#define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK | NMI_MASK))
#define in_irq() (hardirq_count())
#define in_softirq() (softirq_count())
#define in_interrupt() (irq_count())
preempt_count的8~23位記錄中斷處理和軟體中斷處理過程的計數。如果有計數,表示系統在硬體中斷或者軟體中斷處理過程中。 ↩

相關文章
- Linux 核心 tasklet 機制和工作佇列Linux佇列
- 中斷下半部機制 - 軟中斷及tasklet
- Linux 核心中斷和中斷處理(1)Linux
- 【原創】Linux中斷子系統(三)-softirq和taskletLinux
- linux下的工作佇列Linux佇列
- RabbitMQ的工作佇列和路由MQ佇列路由
- Linux核心中斷Linux
- JavaScript 中的工作佇列與PromiseJavaScript佇列Promise
- Linux中VIM的工作模式詳解!Linux模式
- Python實現堆疊和佇列詳解Python佇列
- JAVA中常見的阻塞佇列詳解Java佇列
- 訊息佇列ActiveMQ的使用詳解佇列MQ
- 如何使用Media Encoder中的「編碼」皮膚和「佇列」皮膚詳解佇列
- Softirq和tasklet
- 詳細瞭解IDM的佇列功能佇列
- Laravel RabbitMQ 工作佇列LaravelMQ佇列
- libuv工作佇列佇列
- 阻塞佇列一——java中的阻塞佇列佇列Java
- synchronized 中的同步佇列與等待佇列synchronized佇列
- 佇列 和 迴圈佇列佇列
- Linux核心軟中斷Linux
- 《單核工作法圖解》作者Staffan Nöteberg:讓生活和工作更高效的單核工作法單核圖解
- 詳解RPC遠端呼叫和訊息佇列MQ的區別RPC佇列MQ
- java自帶執行緒池和佇列詳細講解Java執行緒佇列
- 圖解--佇列、併發佇列圖解佇列
- RabbitMQ 入門 - 工作佇列MQ佇列
- java多執行緒:java佇列詳解Java執行緒佇列
- Python3 queue佇列模組詳解Python佇列
- jQuery佇列控制方法詳解queue()/dequeue()/clearQueue()jQuery佇列
- Linux 核心的軟中斷深入解析Linux
- Java中的阻塞佇列Java佇列
- Java 中佇列的使用Java佇列
- Java訊息佇列三道面試題詳解!Java佇列面試題
- 最詳細版圖解優先佇列(堆)圖解佇列
- 07-主佇列和全域性佇列佇列
- 佇列和棧佇列
- 棧和佇列佇列
- Nginx的工作原理和配置詳解Nginx