深度學習-->NLP-->Seq2Seq Learning(Encoder-Decoder,Beam Search,Attention)
之前總結過
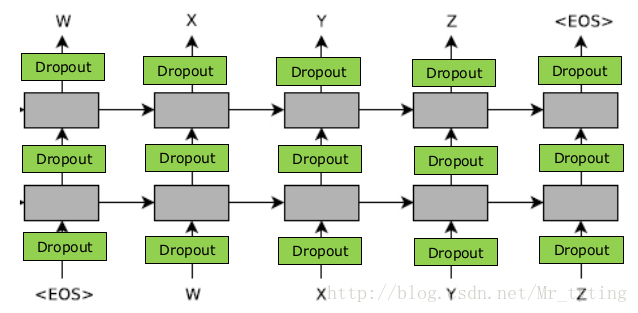
這裡面是一個一個的輸出。我們如果以這種方式做機器翻譯,每一個時刻輸入一個詞,相應的翻譯一個詞,顯然這種一個一個單詞的翻譯方式不是很好,因為沒有聯絡上下文進行翻譯。我們希望先把一整句話餵給模型,然後模型在這一個整句的角度上來進翻譯。這樣翻譯的效果更好。
所以本篇博文要總結的是Seq2Seq Model,給出一個完整的句子,能得出另外一個完整的句子。
下面我們以機器翻譯來講解下面幾個要點。
Encoder-Decoder模型
網路結構
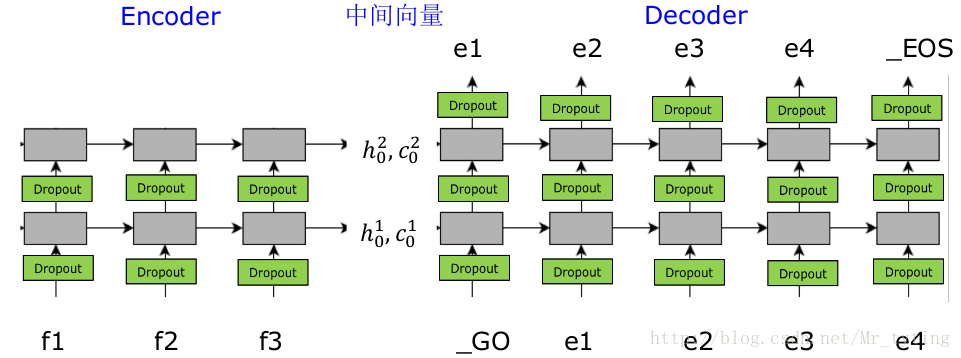
其中
注意在
Encoder−Decoder Encoder-Decoder 的引數集合
首先注意
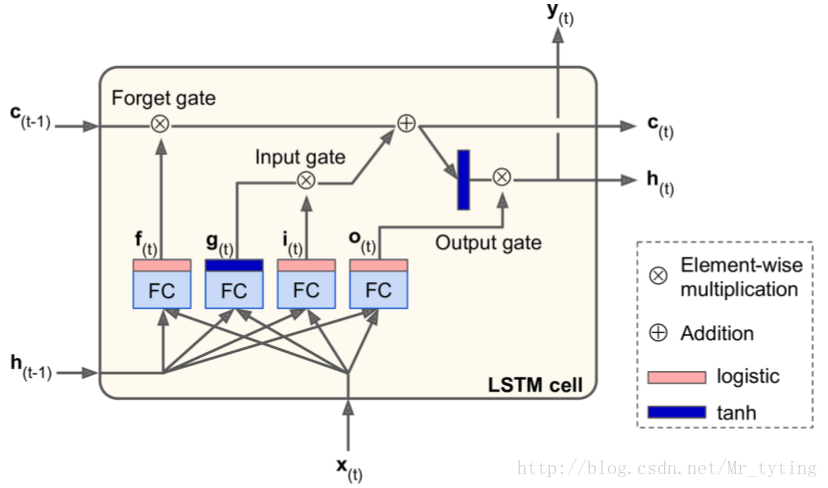
以及它的計算公式:
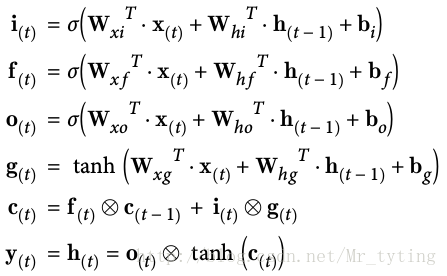
num_layers=n,hidden size=d(embedding的維度) num\_layers=n, hidden\ size=d(embedding的維度)vocab for F=VF(輸入單詞的個數),vocab for E=VE(輸出單詞的個數) vocab\ for\ F = {V}_{F}(輸入單詞的個數) , vocab\ for\ E = {V}_{E}(輸出單詞的個數)
Input:input embedding for f:VF∗d Input: input\ embedding\ for\ f : {V}_{F} ∗ dLSTM LSTM: 第一層,第二層:2∗(8d2+4d) 2*(8{d}^{2} +4d)(我們可以看上面LSTM LSTM的計算公式,對於i,f,o,g i,f,o,g四個公式,每個公式都有兩個引數矩陣,每個矩陣大小都是d∗d d*d,再加上四個bias bias引數矩陣,故每層共有(8d2+4d) (8{d}^{2} +4d)個引數)
Input:input embedding for e:VE∗d Input: input\ embedding\ for\ e: {V}_{E} ∗ dLSTM LSTM: 第一層,第二層:2∗(8d2+4d) 2*(8{d}^{2} +4d)Output Output
output embedding for e:VE∗d output\ embedding\ for\ e: {V}_{E} ∗ d
output bias for e:VE output\ bias\ for\ e: {V}_{E}
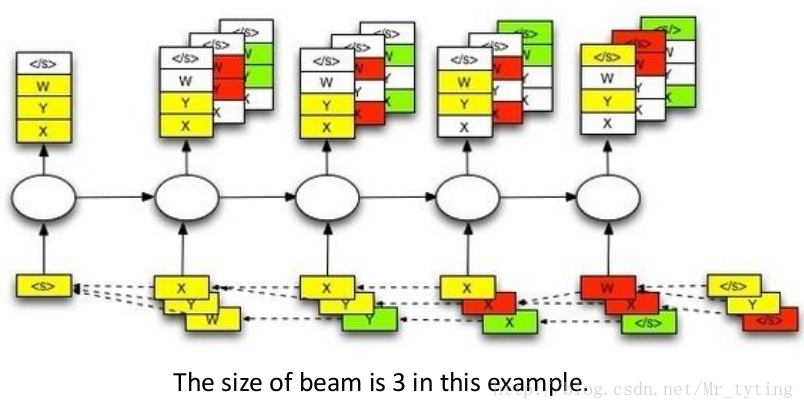
Beam Search
Mismatch between Train and Test Mismatch\ between\ Train\ and\ Test
首先需要注意到模型訓練和模型預測是兩個不同的過程,在訓練時,我們知道每一步真正的
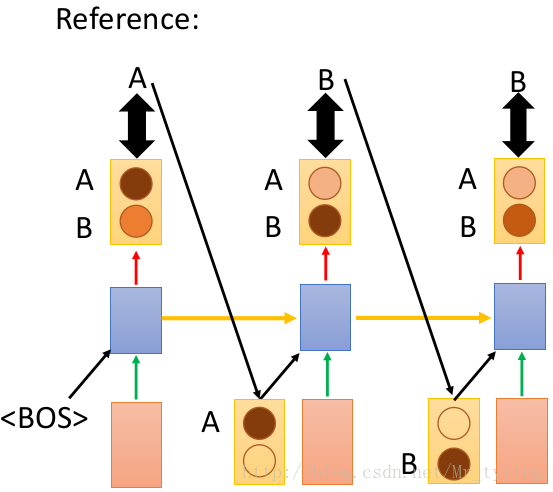
在上圖的網路結構中,都是以上一時刻真正的
那麼
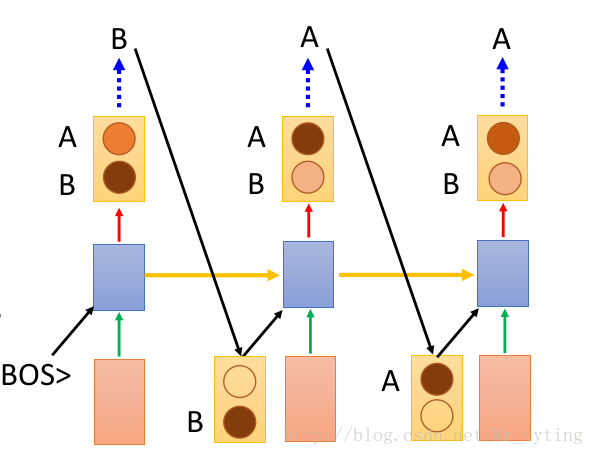
很顯然,這樣做的後果很嚴重:
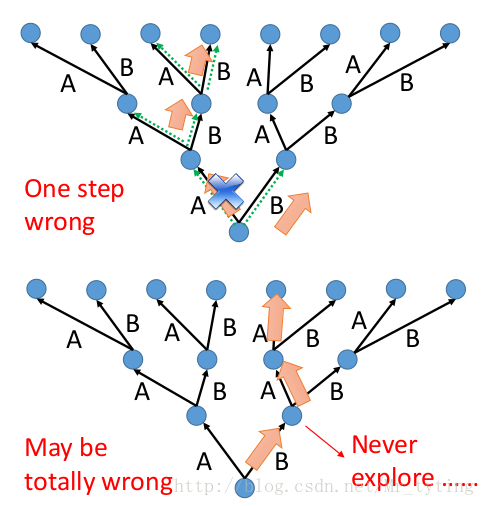
一步錯,步步錯!
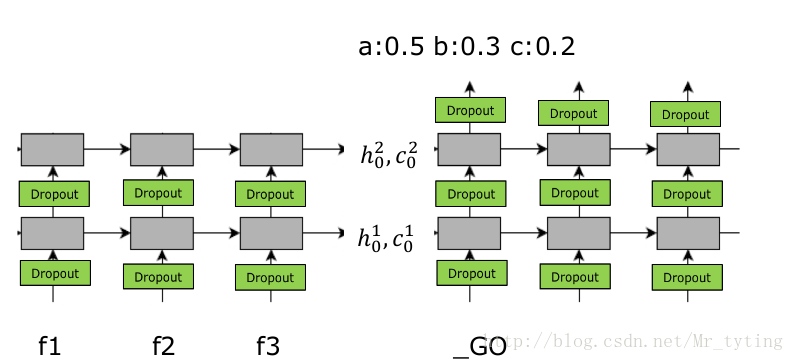
那麼應如何解決上面這個問題呢?我們嘗試這樣做,現在假設語料庫只有
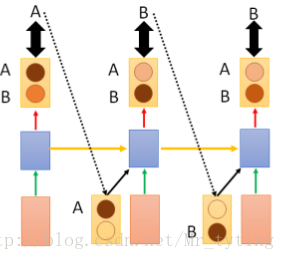
我們看上圖的
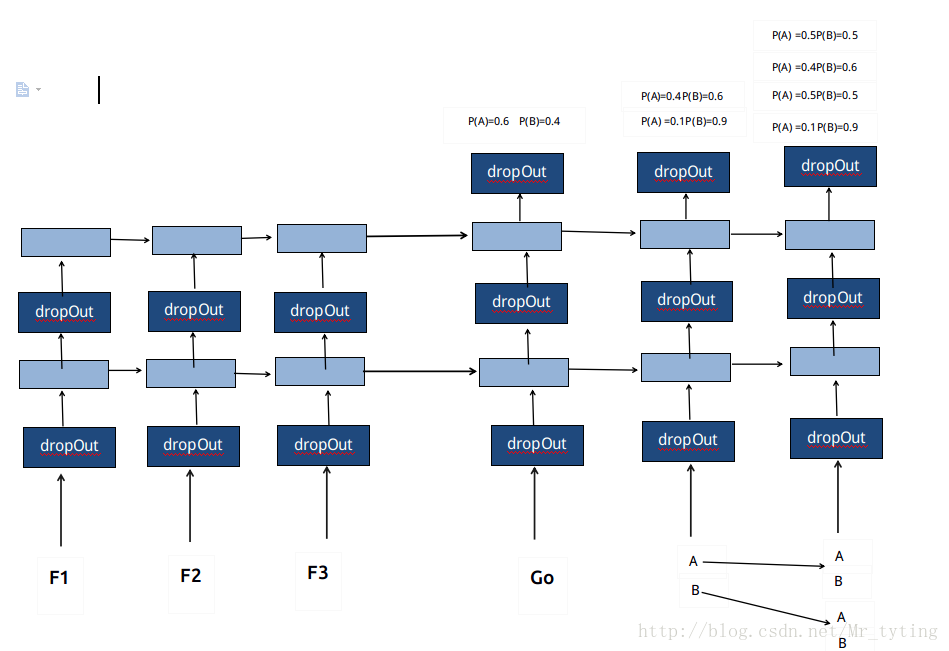
這裡需要注意,在
這樣我們可以計算出輸出序列
在語料庫中的
可以嘗試這樣做,例如語料庫有3個
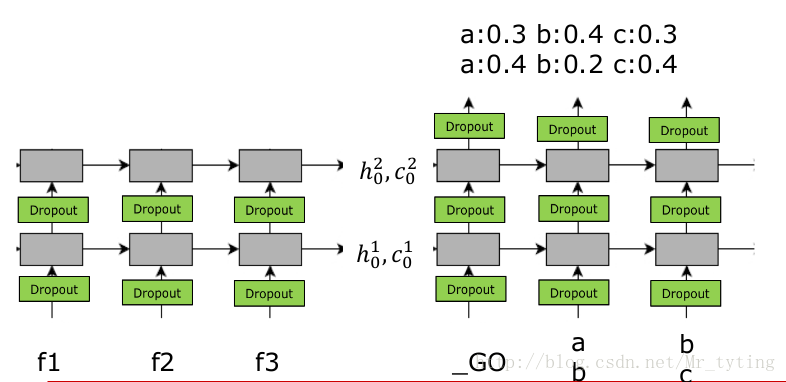
這裡需要注意,當對應輸入是
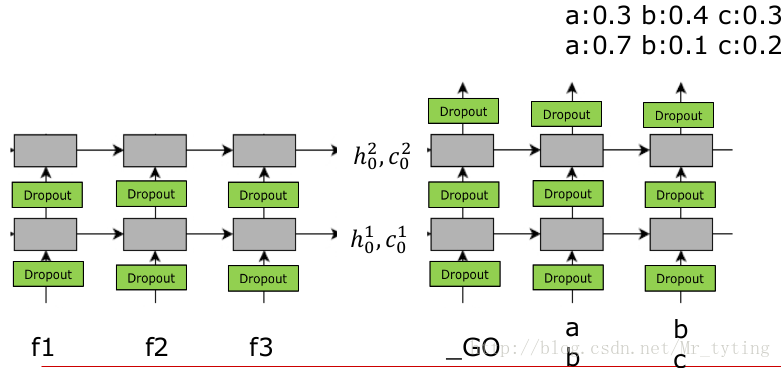
當語料庫中只有兩個
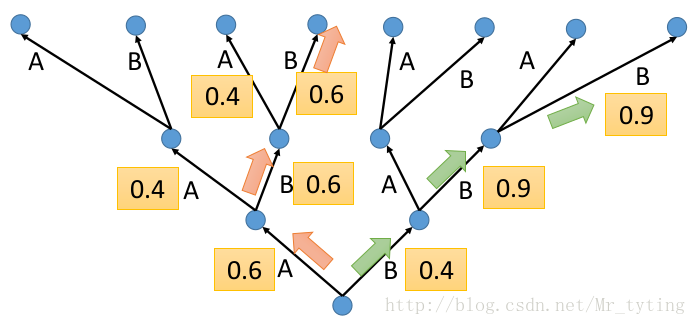
可以以下面這張圖更好的理解
注意在每個時間步時,可能有相同的
Attention
上面講的傳統的
簡單來說,例如將“我 愛 你”翻譯成
例如下圖:
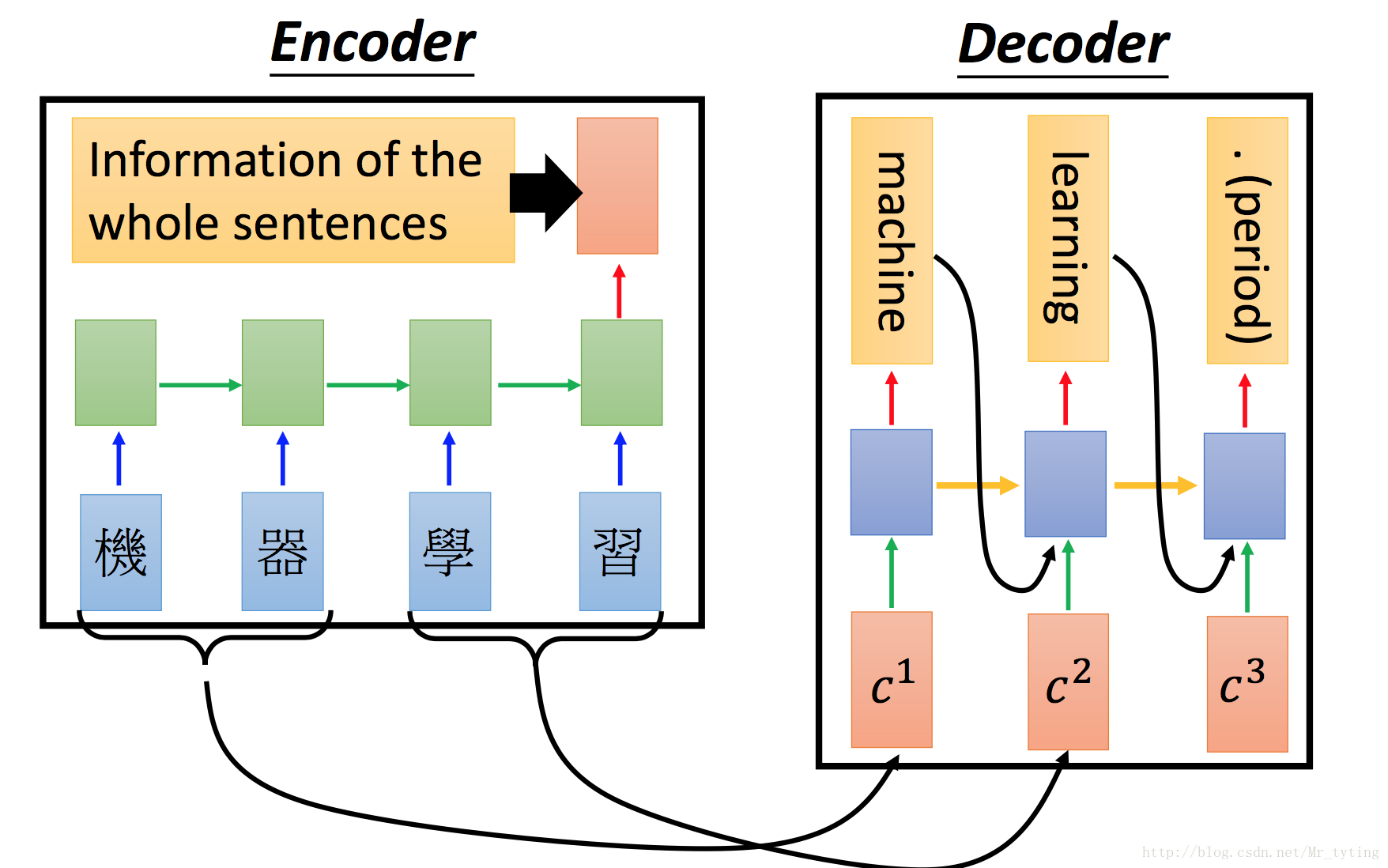
那麼問題來了,如何讓模型學習對其(
在
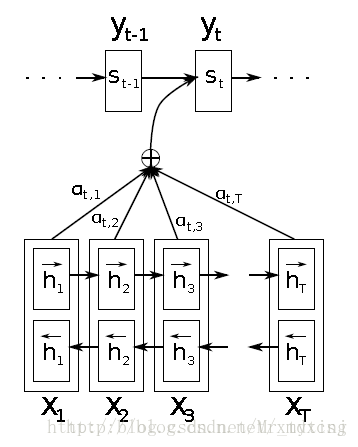
這裡我久不從數學公式角度來說明,只說下它的大致思路。
上圖中上半部分為
假設在
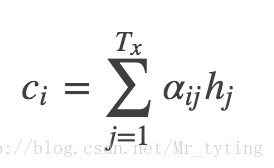
將得出的
這樣講的估計有許多人沒明白咋回事,為什麼這樣做就能
我覺得這篇原始論文講的雖然詳細但是不夠直觀。我引用下臺大李宏毅教授所講
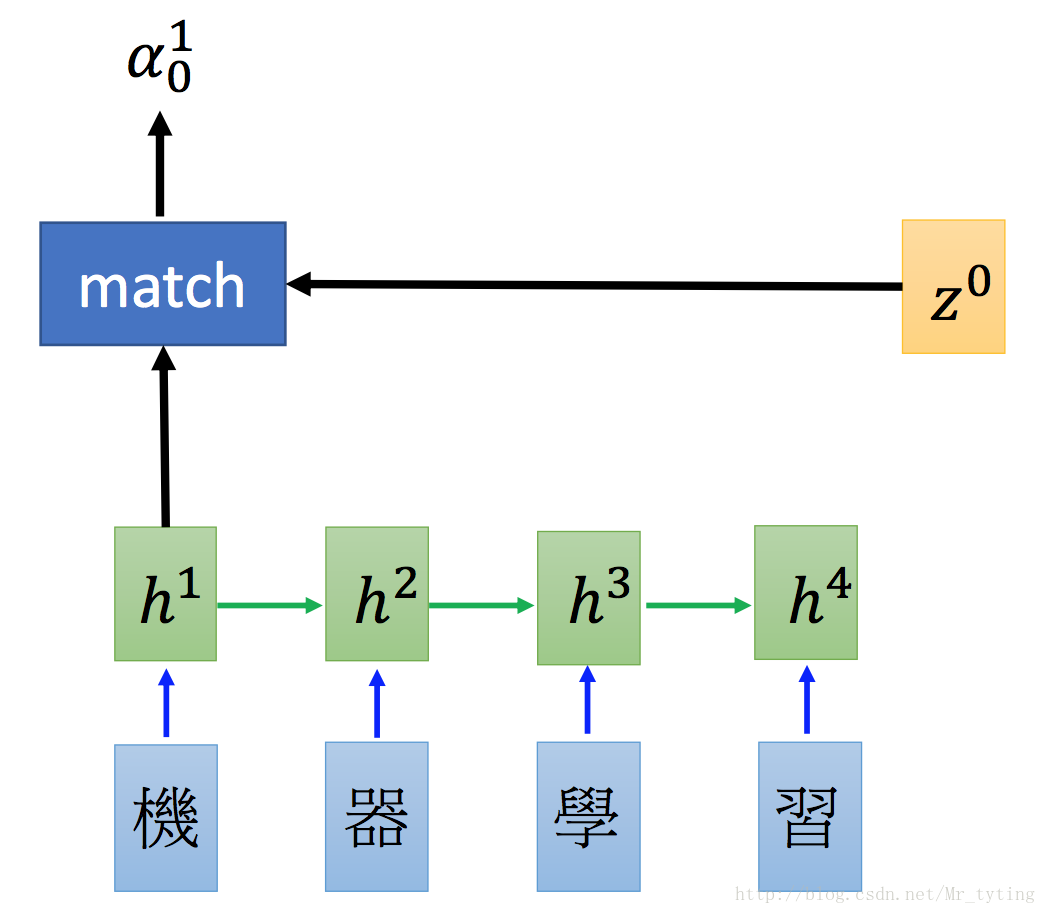
假設我們再

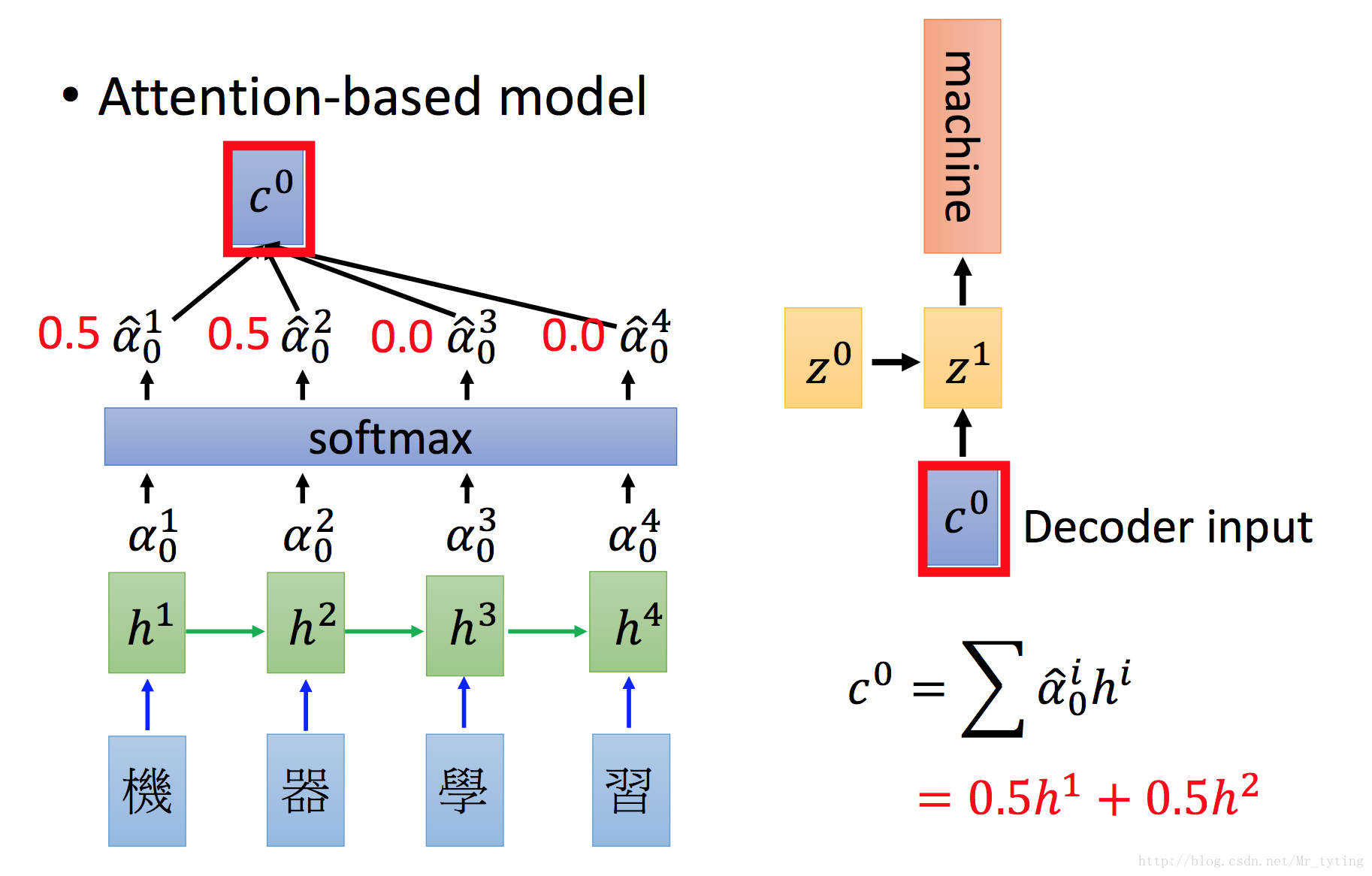
我們可以看出
得出的
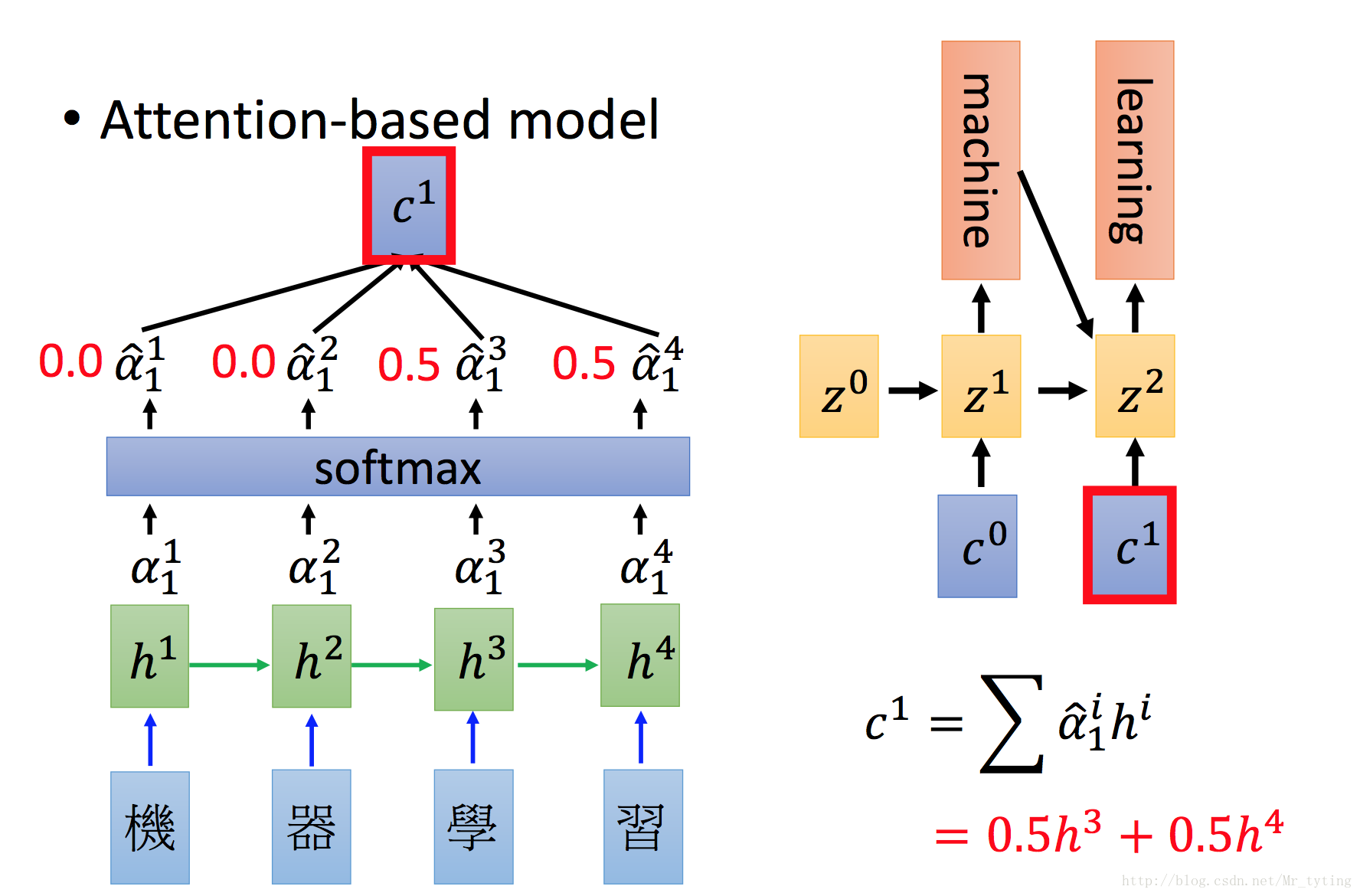
其實對於
相關文章
- 深度學習的Attention模型深度學習模型
- 深度學習的seq2seq模型深度學習模型
- 深度學習中的序列模型演變及學習筆記(含RNN/LSTM/GRU/Seq2Seq/Attention機制)深度學習模型筆記RNN
- 深度學習(Deep Learning)深度學習
- 《DEEP LEARNING·深度學習》深度學習
- 語言模型(五)—— Seq2Seq、Attention、Transformer學習筆記模型ORM筆記
- 深度學習 DEEP LEARNING 學習筆記(一)深度學習筆記
- 深度學習 DEEP LEARNING 學習筆記(二)深度學習筆記
- 【深度學習系列】遷移學習Transfer Learning深度學習遷移學習
- Beam Search快速理解及程式碼解析
- 機器學習(Machine Learning)&深度學習(Deep Learning)資料機器學習Mac深度學習
- Deep Learning(深度學習)學習筆記整理系列深度學習筆記
- 【深度學習】大牛的《深度學習》筆記,Deep Learning速成教程深度學習筆記
- 深度學習(Deep Learning)優缺點深度學習
- 深度學習中的注意力機制(Attention Model)深度學習
- 深度學習模型調優方法(Deep Learning學習記錄)深度學習模型
- Deep Learning(深度學習)學習筆記整理系列之(一)深度學習筆記
- 《深度學習》PDF Deep Learning: Adaptive Computation and Machine Learning series深度學習APTMac
- 【深度學習篇】--Seq2Seq模型從初識到應用深度學習模型
- 深度學習不得不會的遷移學習Transfer Learning深度學習遷移學習
- 貝葉斯深度學習(bayesian deep learning)深度學習
- Deep Reinforcement Learning 深度增強學習資源
- 深度學習教程 | Seq2Seq序列模型和注意力機制深度學習模型
- 注意力(Attention)與Seq2Seq的區別
- 使用Python實現深度學習模型:序列到序列模型(Seq2Seq)Python深度學習模型
- Searching with Deep Learning 深度學習的搜尋應用深度學習
- Seq2Seq那些事:詳解深度學習中的“注意力機制”深度學習
- Neural Networks and Deep Learning(神經網路與深度學習) - 學習筆記神經網路深度學習筆記
- Sphinx Search 學習 (一)
- Machine Learning Mastery 部落格文章翻譯:深度學習與 KerasMacAST深度學習Keras
- deep learning深度學習之學習筆記基於吳恩達coursera課程深度學習筆記吳恩達
- 系統學習NLP(十五)--seq2seq
- 乾貨|當深度學習遇見自動文字摘要,seq2seq+attention深度學習
- 深度學習FPGA實現基礎知識6(Deep Learning(深度學習)學習資料大全及CSDN大牛部落格推薦)深度學習FPGA
- attention注意力機制學習
- 圖學習(一)Graph Attention Networks
- 深度學習(一)深度學習學習資料深度學習
- 小白的深度優先搜尋(Depth First Search)學習日記(Python)Python