Java程式設計基礎
Java的基本語法
Java程式碼的基本格式
Java中的程式程式碼都必須放在一個類中。類需要使用class關鍵字定義,在class前面可以有一些修飾符,格式如下:
修飾符 class 類名{
程式程式碼
}- Java中的程式程式碼可以分為結構定義語句和功能執行語句,其中,結構定義語句用於宣告一個類或方法,功能執行語句用於實現具體的功能。每條功能執行語句的最後都必須用分號(;)結束。
- Java語言是嚴格區分大小寫的。
- 編寫Java程式碼時,可以在兩個單詞或符號之間任意的換行。但為了便於閱讀,我們通常會使用一種良好的格式進行排版。
- Java程式中一句連續的字串不能分開在兩行中書寫,例如,下面這條語句在編譯時將會出錯:
System.out.println("這是第一個
Java程式"); 如果為了便於閱讀,想將一個太長的字串分在兩行中書寫,可以先將這個字串分成兩個字串,然後用加好(+)將兩個字串連起來,在加好(+)處斷行。
System.out.println("這是第一個"+
"Java程式");Java中的註釋
在編寫程式時,為了使程式碼易於閱讀,通常會在實現功能的同時為程式碼加一些註釋。註釋是對程式某個功能或者某行程式碼的解釋說明,它只在Java原始檔中有效,在編譯程式時編譯器會忽略這些註釋資訊,不會將其編譯到class位元組碼檔案中去。
註釋還經常用於除錯程式碼,註釋掉一段程式碼,來逐步縮小除錯範圍,找到出錯程式碼。
- 單行註釋:通常用於對程式中中的某一行程式碼進行解釋,用符號“//”表示,“//”後面為被註釋的內容。
- 多行註釋:以符號“/*”開頭,以符號“*/”結尾。
- 文件註釋:以“/**”開頭,以“*/”結尾。可以使用javadoc命令將文件註釋提取出來生成幫助文件。
Java中識別符號
在程式設計過程中,經常需要在程式中定義一些符號來標記一些名詞,如包名、類名、方法名、引數名、變數名等,這些符號被稱為識別符號。
- 識別符號可以由任意順序的大小寫字元、數字、下劃線(_)和美元符號($)組成
- 但識別符號不能以數字開頭
- 不能是Java中的關鍵字
在Java中定義的識別符號必須要嚴格遵守上面列出的規範,否則程式在編譯時會報錯。
除了上面列出的規範,為了增強程式碼的可讀性,還應遵循以下規則:
- 包名所有字母一律小寫
- 類名和介面名每個單詞的首字母都要大寫
- 變數名和方法名的第一個單詞首字母小寫,從第二個單詞開始每個單詞首字母大寫
- 常量名所有字母都大寫,單詞之間用下劃線連線
- 應該儘量使用有意義的英文單詞來定義識別符號
Java中的關鍵字
關鍵字是程式語言裡事先定義好並賦予了特殊含義的單詞,也稱作保留字。
下面列舉的是Java中所有的關鍵字。
| abstract | boolean | break | byte | case |
|---|---|---|---|---|
| catch | char | const | class | continue |
| default | do | double | else | extends |
| false | final | finally | float | for |
| goto | if | implements | inport | instanceof |
| int | interface | long | native | new |
| null | package | private | protected | public |
| return | short | static | strictfp | super |
| switch | this | throw | throws | transient |
| true | try | void | volatile | while |
| synchronized |
- 所有關鍵字都是小寫的
- 程式中的識別符號不能以關鍵字命名。
Java中的常量
常量就是在程式中固定不變的值,是不能改變的資料。例如數字1,字元‘a’,浮點數3.2
整型常量
- 二進位制:由數字0和1組成的數字序列。允許使用字面值來表示二進位制數,前面要以0b或0B開頭,目的是為了和十進位制進行區分,如0b10110010。
- 八進位制:以0開頭並且其後由0~7範圍內(包括0和7)的整陣列成的數字序列,如0342
- 十六進位制:以0x或者0X開頭並且其後由0\~9、A~F(包括0和9、A和F)組成的數字序列,如0x23AF。
- 十進位制
浮點數常量
浮點數常量就是數學中用到的小數,分為float單精度浮點數和double雙精度浮點數兩種型別。
單精度浮點數後面以F或f結尾,而雙精度浮點數則以D或d結尾。在使用浮點數時也可以在結尾處不加任何的字尾,此時虛擬機器會預設為double雙精度浮點數。
字元常量
字元常量用於表示一個字元,且必須包含一個字元。一個字元常量要用一對英文半形格式的單引號”引起來,它可以是英文字母、數字、標點符號以及由轉義序列來表示的特殊字元。
'a' '\r' '&' '\u0000'‘\u0000’表示一個空白字元,即在單引號之間沒有任何字元。之所以能這樣表示,是因為Java採用的是Unicode字符集,Unicode字元以\u開頭,空白字元在Unicode碼錶中對應的值為’\u0000’。
字串常量
字串常量用於表示一串連續的字元,一個字串常量要用一對英文半形格式的雙引號”“引起來。
一個字串可以包含一個字元或多個字元,也可以不包含任何字元,即長度為零。
布林常量
布林常量即布林型的兩個值true和false。
null常量
null常量只有一個值null,表示物件的引用為空。
反斜槓(\)
在字元常量中,反斜槓(\)是一個特殊的字元,被稱為轉義字元,它的作業是用來轉義後面一個字元。轉義後的字元通常用於表示一個不可見的字元或具有特殊含義的字元。
- \r表示回車符,將游標定位到當前行的開頭,不會跳到下一行。
- \n表示換行符,換到下一行的開頭。
- \t表示製表符,將游標移到下一個製表符的位置,就像在文件中用Tab鍵一樣。
- \b表示退格符號,就像鍵盤上的Backspace鍵。
以下的字元都有特殊意義,無法直接表示,所以用斜槓加上另外一個字元表示。
- \’表示單引號字元,Java程式碼中單引號表示字元的開始和結束,如果直接寫單引號字元(’),程式會認為前兩個是一對,會報錯,因此需要使用轉移符(\’).
- \”表示雙引號字元。
- \\表示反斜槓字元,由於在Java程式碼中的斜槓(\)是轉義字元,因此需要表示字面上的\,就需要使用雙斜槓(\\)。
Java中的變數
變數的定義
在程式執行期間,隨時可能產生一些臨時資料,應用程式會將這些資料儲存在一些記憶體單元中,每個記憶體單元都用一個識別符號來標識。這些記憶體單元被稱為變數,定義的識別符號就是變數名,記憶體單元中儲存的資料就是變數的值。
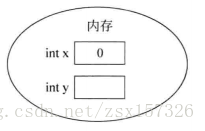
int x=0,y;
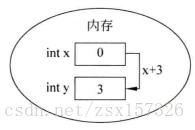
y=x+3;第一行程式碼的作用 是定義了兩個變數x和y,也就相當於分配了兩塊記憶體單元,在定義變數的同時為變數x分配了一個初始值0,而變數y沒有分配初始值,變數x和y在記憶體中的狀態為。
第二行程式碼的作用是為變數賦值,在執行第二行程式碼時,程式首先取出變數x的值,與3相加後,將結果賦值給變數y,此時變數x和y在記憶體中的狀態發生了變化。
變數的資料型別
Java是一門強型別的語言,它對變數的資料型別有嚴格的限定。在定義變數時必須宣告變數的型別,在為變數賦值時必須賦予和變數同一種型別的值,否則程式會報錯。
在Java中變數的資料型別分為兩種,即基本資料型別和引用資料型別。
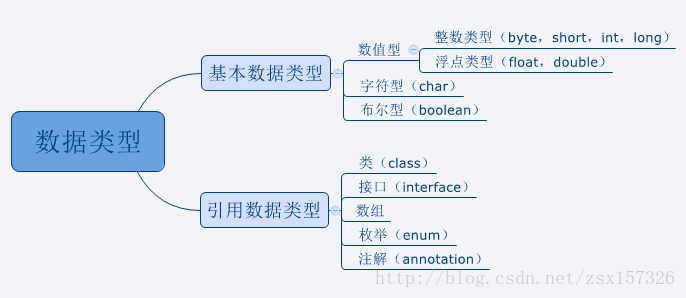
8種基本資料型別是Java語言內嵌的,在任何作業系統中都具有相同大小和屬性,而引用資料型別是在Java程式中由程式設計人員自己定義的變數型別。
整數型別變數
整數型別變數用來儲存整數數值,即沒有小數部分的值。在Java中,為了給不同大小範圍內的整數合理地分配儲存空間,整數型別分為4中不同的型別:位元組型(byte)、短整型(short)、整型(int)和長整型(long)。
| 型別名 | 佔用空間 | 取值範圍 |
|---|---|---|
| byte | 8位(1個位元組) | -2^7 ~2^7-1 |
| short | 16位(2個位元組) | -2^{15} ~2^{15}-1 |
| int | 32位(4個位元組) | -2^{31} ~2^{31}-1 |
| long | 64位(8個位元組) | -2^{63} ~2^{63}-1 |
在為一個long型別的變數賦值時,所賦值的後面要加上一個字母L(或小寫l),說明賦值為long型別。如果賦的值未超過int型的取值範圍,則可以省略字母L(或小寫l)。
浮點數型別變數
浮點數型別變數用來儲存小數數值。在Java中,浮點數型別分為兩種:單精度浮點數(float)和雙精度浮點數(double)。double型所表示的浮點數比float型更精確。
| 型別名 | 佔用空間 | 取值範圍 |
|---|---|---|
| float | 32位(4個位元組) | 1.4E-45~3.4E+38,-1.4E-45~-3.4E+38 |
| double | 64位(8個位元組) | 4.9E-324~1.7E+308,-4.9E-324~-1.7E+308 |
E表示以10為底的指數,E後面的+號和-號代表正指數和負指數,例如
在Java中,一個小數會被預設為double型別的值,因此在為一個float型別的變數賦值時,所賦值的後面一定要加上字母F(或者小寫f)。
在程式中,也可以為一個浮點數型別變數賦予一個整數數值。
字元型別變數
字元型別變數用於儲存一個單一字元,在Java中用char表示。Java中每個char型別的字元變數都會佔用2個位元組。在給char型別的變數賦值時,需要用一對英文半形格式的單引號”把字元括起來,如’a’,也可以將char型別的變數賦值為0~65535範圍內的整數,計算機會自動將這些整數轉化為所對應的字元,如數值97對應的字元為’a’。
char c='a'; char ch=97;布林型別變數
布林型別變數用來儲存布林值,在Java中用boolean表示,該型別的變數只有兩個值,即true和false。
變數型別的轉換
在程式中,當把一種資料型別的值賦給另一種資料型別的變數時,需要進行資料型別轉換。
自動型別轉換
自動型別轉換也叫隱式型別轉換,指的是兩種資料型別在轉換的過程中不需要顯式地進行宣告。
要實現自動型別轉換,必須同時滿足兩個條件,第一是兩種資料型別彼此相容,第二是目標型別的取值範圍大於源型別的取值範圍。
byte b=3; int x=b;- 整數型別之間可以實現轉換:byte–>short、int、long;short、char–>int、long;int–>long
- 整數型別轉換為float:byte、char、short、int、long–>float
- 其他型別轉換為double型別:byte、char、short、int、long、float–>double
強制型別轉換
強制型別轉換也叫顯示型別轉換,指的是兩種資料型別之間的轉換需要進行顯示地宣告。當兩種型別彼此不相容,或者目標型別取值範圍小於源型別,自動型別轉換無法進行,這時就需要進行強制型別轉換。
int a=4; byte b=(byte)a;一個位元組的變數b無法儲存四個位元組的變數a,在這種情況下就需要進行強制型別轉換。
但強制型別轉換極容易造成 資料精度的丟失。
int a=298; byte b=(byte)a; System.out.println("a="+a); System.out.println("b="+b);輸出結果為
a=298 b=42變數a的值本來為298,然而在賦值給變數b之後,其值為42,明顯丟失了精讀。
因為a是int型別,在記憶體中佔用4個位元組,byte型別的資料在記憶體中佔用1個位元組。當將變數b的型別強轉為byte型別之後,前面3個高位位元組的資料丟失,數值發生改變。
int 00000000 00000000 00000001 00101010 byte 00101010表示式型別自動提升
表示式是指由變數和運算子組成的一個算式。變數在表示式中進行運算時,也可能發生自動型別轉換,這就是表示式資料型別的自動提升,如一個byte型的變數在運算期間型別會自動提升為int型。
byte b1=3; byte b2=4; byte b3=b1+b2; System.out.println("b3="+b3);執行時會報錯,因為表示式b1+b2運算期間,變數b1和b2都會被自動提升為int型,表示式的運算結果也就變成了int型,這時如果將結果賦給byte型的變數就會報錯,需要進行強制型別轉換。
byte b3=(byte)b1+b2;
變數的作用域
變數需要在它的作用範圍內才可以被使用,這個作用範圍稱為變數的作用域。
在程式中,變數一定會被定義在某一對大括號中,該大括號所包含的程式碼區域便是這個變數的作用域。

Java中的運算子
算數運算子
| 運算子 | 運算 | 範例 | 結果 |
|---|---|---|---|
| + | 正號 | +3 | 3 |
| - | 負號 | b=4;-b; | -4 |
| + | 加 | 5+5 | 10 |
| - | 減 | 6-4 | 2 |
| * | 乘 | 3*4 | 12 |
| / | 除 | 5/5 | 1 |
| % | 取模(即算數中的求餘數) | 7%5 | 2 |
| ++ | 自增(前) | a=2;b=++a; | a=3;b=3 |
| ++ | 自增(後) | a=2;b=a++; | a=3;b=2 |
| – | 自增(前) | a=2;b=–a; | a=1;b=1 |
| – | 自增(後) | a=2;b=a–; | a=1;b=2 |
- 在進行自增++和自增–的運算時,如果運算子++或–放在運算元的前面則是先進行自增或自減運算,再進行其他運算。反之,如果運算子放在運算元的後面則是先進行其他運算再進行自增或自減運算。
- 在進行除法運算時,當除數和被除數都為整數時,得到的結果也是一個整數。如果除法運算有小數參與,得到的結果會是一個小數。
- 在進行取模(%)運算時,運算結果的正負取決於被模數(%左邊的數)的符號,與模數(%右邊的數)的符號無關。
賦值運算子
賦值運算子的作用就是將常量、變數或表示式的值賦給某一個變數。
| 運算子 | 運算 | 範例 | 結果 |
|---|---|---|---|
| = | 賦值 | a=3;b=2; | a=3;b=2; |
| += | 加等於 | a=3;b=2;a+=b; | a=5;b=2; |
| -= | 減等於 | a=3;b=2;a-=b; | a=1;b=2; |
| *= | 乘等於 | a=3;b=2;a*=b; | a=6;b=2; |
| /= | 除等於 | a=3;b=2;a/=b; | a=1;b=2; |
| %= | 模等於 | a=3;b=2;a%=b; | a=1;b=2; |
在賦值過程中,運算順序從右往左,將右邊表示式的結果賦值給左邊的變數。
x+=3;就相當於x=x+3;
將一個int型別的值賦給一個short型別的變數,需要顯示地進行強制型別轉換。然而在使用+=,-+,*=,/=,%=運算子進行賦值時,強制型別轉換會自動完成,程式不需要做任何顯式子地宣告。
比較運算子
比較運算子用於對兩個數值或變數進行比較,其結果是一個布林值,即true或false。
| 運算子 | 運算 | 範例 | 結果 |
|---|---|---|---|
| == | 相等於 | 4==3 | false |
| != | 不等於 | 4!=3 | true |
| < | 小於 | 4<3 | false |
| > | 大於 | 4>3 | true |
>= |
小於等於 | 4<=3 | false |
| <= | 大於等於 | 4>=3 | true |
注意不能將比較運算子==誤寫成賦值運算子=。
邏輯運算子
邏輯運算子用於對布林型的資料進行操作,其結果仍是一個布林型。
| 運算子 | 運算 | ||
|---|---|---|---|
| & | 與 | 兩邊都是true才為true | |
| | | 或 | 有一個true就為true | |
| ^ | 異或 | 兩邊不同為true | |
| ! | 非 | ||
| && | 短路與 | ||
| || | 短路或 |
在使用&進行運算時,無論左邊為true或者false,右邊的表示式都會進行運算。
如果使用&&進行運算,當左邊為false時,右邊的表示式不會進行運算。
位運算子
位運算子是針對二進位制數的每一位進行運算的符號,它是專門針對數字0和1進行操作的。
| 運算子 | 運算 | ||
|---|---|---|---|
| & | 按位與 | ||
| | | 按位或 | ||
| ~ | 取反 | ||
| ^ | 按位異或 | ||
| << | 左移 | 10010011<<2 | 01001100 |
| >> | 右移 | ||
| >>> | 無符號右移 |
1代表true
位運算<<就是將運算元所有二進位制位向左移動。運算時,右邊的空位補0。左邊移走的部分捨去。
位運算子>>就是將運算元所有二進位制位向右移動。運算時,左邊的空位根據原數的符號位補0或者1(原來是負數就補1,是正數就補0)。
位運算子>>>就是將運算元所有二進位制位向右移動一位。運算時,左邊的空位補0(不考慮原數正負)
運算子的優先順序
在對一些比較複雜的表示式進行運算時,要明確表示式中所有運算子參與運算的先後順序。
數字越小優先順序越高。
| 優先順序 | 運算子 |
|---|---|
| 1 | . [ ] ( ) |
| 2 | ++ - - ~ ! (資料型別) |
| 3 | * / % |
| 4 | + - |
| 5 | << >> >>> |
| 6 | < > <= >= |
| 7 | == != |
| 8 | & |
| 9 | ^ |
| 10 | | |
| 11 | && |
| 12 | || |
| 13 | ?: |
| 14 | = *= /= %= += -= <<= >>= >>>= &= ^= |= |
編寫程式時,儘量使用括號()來實現想要的運算順序,以免產生歧義。
選擇結構語句
if條件語句
if語句:判斷條件是一個布林值,當判斷條件為true時,{}中的執行語句才會執行。
if(判斷條件){ 程式碼塊 }if···else語句:判斷條件為真,執行語句1,為false執行語句2
if(判斷條件){ 執行語句1 }else{ 執行語句2 }三元運算子
判斷條件?表示式1:表示式2三元運算子會得到一個結果,通常用於對某個變數進行賦值,當判斷條件為真時,結果為1的值,否則結果為表示式2的值。
int max=x>y?x:y;if···else if···else語句
if···else if···else語句用於對多個條件進行判斷,進行多種不同的處理。
if(判斷條件1){ 執行語句1 }else if(判斷條件2){ 執行語句2 } ... else if(判斷條件n){ 執行語句n }else{ 執行語句n+1 }當判斷條件1為true時,會執行語句1。為false時,會執行判斷條件2,如果為true則執行語句2,依次類推,如果所有的判斷條件都為false,則意味著所有條件均為滿足,else後面{}中的執行語句n+1會執行。
switch條件語句
switch(表示式){
case 目標值1:
執行語句1
break;
case 目標值2:
執行語句2
break;
...
case 目標值n:
執行語句n
break;
default:
執行語句n+1
break;
}switch語句將表示式的值與每個case中的目標值進行匹配,如果找到了匹配的值,會執行對應case後的語句,如果沒有找到任何匹配的值,就會執行default後的語句。
在switch語句中的表示式只能是byte、short、char、int型別的值,如果傳入其他型別的值,程式會報錯。但這樣說也不嚴謹,在JDK5.0中引入的新特性enum列舉和在JDK7.0中引入的新特性String型別也可以。
在使用switch語句中,如果多個case條件後面的執行語句是一樣的,則該執行語句只需書寫一次即可,這是一種簡寫的方式。
int week=2;
switch(week){
case 1:
case 2:
case 3:
case 4:
case 5:
System.out.println("今天是工作日");
break;
case 6:
case 7:
System.out.println("今天是休息日");
break;
}迴圈結構語句
while迴圈語句
while(迴圈條件){ 執行語句 }{}中的執行語句被稱作迴圈體。當迴圈條件為true時,迴圈體就會執行。迴圈體執行完畢時會繼續判斷迴圈條件,如條件仍為true則會繼續執行,直到迴圈條件為false時,整個迴圈過程才會結束。
do···while迴圈語句
do{ 執行語句 }while(迴圈條件);迴圈體會無條件執行一次,然後再根據迴圈條件來決定是否繼續執行。
for迴圈語句
for迴圈語句是最常用的迴圈語句,一般用在迴圈次數已知的情況下。
for(初始化表示式;迴圈條件;操作表示式){ 執行語句 }先執行初始化表示式,然後判斷迴圈條件,為false就退出迴圈,為true的話就執行語句,然後執行操作表示式,然後再判斷迴圈條件。。。
巢狀迴圈
巢狀迴圈是指在一個迴圈語句的迴圈體中再定義一個迴圈語句的語法結構。while、do···while、for迴圈語句都有可以進行巢狀,並且它們之間也可以互相巢狀。
跳轉語句(break、continue)
break語句
在switch條件語句和迴圈語句中都可以使用break語句。當它出現在switch條件語句中時,作用是終止某個case並跳出switch結構。當它出現在迴圈語句中,作用是跳出迴圈語句,執行後面的程式碼。
continue語句
continue語句用在迴圈語句中,它的作用是終止本次迴圈,執行下一次迴圈。
方法
什麼是方法
將重複的程式碼提取出來封裝成一個方法。
修飾符 返回值型別 方法名([引數型別 引數名1,引數型別 引數名2,···]){
執行語句
return 返回值;
}- 修飾符:對訪問許可權進行限定。
- 返回值型別: 用於限定返回值的資料型別
- 引數型別:用於限定呼叫方法時傳入引數的資料型別
- 引數名:是一個變數,用於接收呼叫方法時傳入的資料。
- return關鍵字:用於結束方法及返回方法指定型別的值。
- 返回值:被return語句返回的值,該值會返回給呼叫者。
方法中的“引數型別 引數名1,引數型別 引數名2”被稱作引數列表,它用於描述方法在被呼叫時需要接收的引數,如果方法不需要接收任何引數,則引數列表為空,即()內不寫任何內容。方法的返回值必須為方法宣告的返回值型別,如果方法中沒有返回值,返回值型別要宣告為void,此時,方法中return語句可以省略。
方法的過載
在一個程式中定義多個名稱相同的方法,但是引數的型別或個數必須不同,這就是方法的過載。
方法的過載與返回值型別無關,它只需要滿足兩個條件,一是方法名相同,二是引數個數或引數型別不相同。
方法的遞迴
方法的遞迴是指在一個方法的內部呼叫自身的過程,遞迴必須要有結束條件,不然就會陷入無限遞迴的狀態,永遠無法結束呼叫。
陣列
陣列是指一組資料的集合,陣列中的每個資料都被稱作元素。在陣列中可以存放任意型別的元素,但同一個陣列裡存放的元素型別必須一致。陣列可以分為一維陣列和多維陣列。
陣列的定義
int[] x=new int[100];
上述語句就相當於在記憶體中定義了100個int型別的變數,第一個變數的名稱為x[0],第二個變數的名稱為x[1],依此類推,第100個變數的名稱為x[99],這些變數的初始值都是0。
上面的一句程式碼可以分成兩句話來寫。
int[] x; //宣告一個int[]型別的變數
x=new int[100];//建立一個長度為100的陣列第一行程式碼int[] x;宣告瞭一個變數x,該變數的型別為int[],即一個int型別的陣列。變數x會佔用一塊記憶體單元,它沒有被分配初始值。
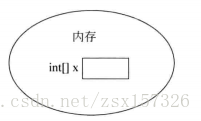
第二行程式碼x=new int[100],建立了一個陣列,將陣列的地址賦值給變數x。
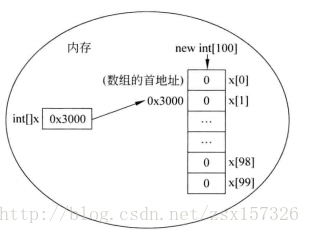
陣列中的每個元素都有一個索引(也可稱為角標),要想訪問陣列中的元素可以通過x[0]、x[1]···x[98]、x[99]的形式。
陣列中最小的索引是0,最大的索引是“陣列的長度-1”。
為了方便獲取陣列的長度,提供了一個length屬性,在程式中可以通過“陣列名.length”的方式來獲得陣列的長度,即元素的個數。
| 資料型別 | 預設初始化值 |
|---|---|
| byte、short、int、long | 0 |
| float、double | 0.0 |
| char | 一個空字元,即‘\u0000’ |
| boolean | false |
| 引用資料型別 | null,表示變數不引用任何物件 |
在定義陣列時只指定陣列的長度,由系統自動為元素賦初值的方式稱作動態初始化。
在初始化陣列時還有一種方式叫做靜態初始化,就是定義陣列的同時就為陣列的每個元素賦值。陣列的靜態初始化有兩種方式。
型別 [] 陣列名=new 型別 []{元素,元素,······};
型別 [] 陣列名={元素,元素,······};為了簡便,建議採用第二種方式。
陣列的常見操作
陣列遍歷
在運算元組時,經常需要依次訪問陣列中的每個元素,這種操作稱作陣列的遍歷。
int[] arr={1,2,3,4,5}; for(int i=0;i<arr.length;i++){ System.out.println(arr[i]); }陣列最值
陣列排序
多維陣列
相關文章
- Java 基礎02Java程式設計基礎Java程式設計
- 【Java基礎】通用程式設計Java程式設計
- 《java程式設計基礎》java的基礎知識(三)Java程式設計
- JAVA網路程式設計基礎Java程式設計
- Java 基礎程式設計筆記Java程式設計筆記
- Java程式設計基礎33——JDBCJava程式設計JDBC
- Java併發程式設計基礎Java程式設計
- Java基礎——程式設計之路的開始,Java基礎知識Java程式設計
- 《java程式設計基礎》例題5.6Java程式設計
- Java入門之基礎程式設計Java程式設計
- Java 基礎(十六)網路程式設計Java程式設計
- java程式設計師程式設計筆試基礎學習Java程式設計師筆試
- Java程式設計基礎29——JavaSE總結Java程式設計
- Java程式設計基礎17——集合(List集合)Java程式設計
- Java程式設計基礎05——方法(函式)Java程式設計函式
- Java基礎之多執行緒程式設計Java執行緒程式設計
- 《java程式設計基礎》方法的過載Java程式設計
- Java擴充-網路程式設計基礎Java程式設計
- Java多執行緒程式設計基礎Java執行緒程式設計
- 程式設計基礎程式設計
- java 設計模式基礎Java設計模式
- 好程式設計師Java培訓分享20個Java程式設計師基礎題程式設計師Java
- Java網路程式設計快速上手(SE基礎)Java程式設計
- Java程式設計基礎23——IO(其他流)&PropertiesJava程式設計
- Java程式設計基礎28——反射&JDK新特性Java程式設計反射JDK
- Java程式設計基礎24——遞迴練習Java程式設計遞迴
- Java程式設計基礎31——MySql資料庫Java程式設計MySql資料庫
- Java程式設計基礎32——MySQL多表聯查Java程式設計MySql
- Java併發程式設計——基礎知識(一)Java程式設計
- Java-基礎程式設計-多執行緒Java程式設計執行緒
- Java併發程式設計-執行緒基礎Java程式設計執行緒
- Java併發程式設計——基礎知識(二)Java程式設計
- 50道Java基礎程式設計練習題Java程式設計
- java多執行緒程式設計--基礎篇Java執行緒程式設計
- Socket程式設計基礎程式設計
- Go程式設計基礎Go程式設計
- Shell程式設計-基礎程式設計
- C程式設計基礎C程式程式設計