CUDA之Dynamic Parallelism詳解(二)
CUDA 5.0中引入動態並行化,使得在device端執行的kernel的執行緒也能跟在host上一樣launch kernels,只有支援CC3.5或者以上的裝置中才能支援。動態並行化使用CUDA Device Runtime library(cudadevrt),它是一個能在device code中呼叫的CUDA runtime子集。
編譯連結
為了支援動態並行化,必須使用兩步分離編譯和連結的過程:首先,設定-c和-rdc=true(–relocatable-device-code=true)來生成relocatable device code來進行後續連結,可以使用-dc(–device -c)來合併這兩個選項;然後將上一步目標檔案和cudadevrt庫進行連線生成可執行檔案,-lcudadevrt。過程如下圖
1 2 | nvcc -arch=sm_35 -dc myprog.cu -o myprog.o nvcc -arch=sm_35 myprog.o -lcudadevrt -o myprog |
或者簡化成一步
|
1
|
nvcc
-arch=sm_35
-rdc=true
myprog.cu
-lcudadevrt
-o
myprog.o
|
執行、同步
在CUDA程式設計模型中,一組執行的kernel的執行緒塊叫做一個grid。在CUDA動態並行化,parent grid能夠呼叫child grids。child grid繼承parant grid的特定屬性和限制,如L1 cache、shared_memory、棧大小。如果一個parent grid有M個block和N個thread,如果對child kernel launch沒有控制的話,那個將產生M*N個child kernel launch。如果想一個block產生一個child kernel,那麼只需要其中一個執行緒launch a kernel就行。如下
1 2 3 | if(threadIdx.x == 0) { child_k <<< (n + bs - 1) / bs, bs >>> (); } |
grid lanuch是完全巢狀的,child grids總是在發起它們的parent grids結束前完成,這可以看作是一個一種隱式的同步。

如果parent kernel需要使用child kernel的計算結果,也可以使用CudaDeviceSynchronize(void)進行顯示的同步,這個函式會等待一個執行緒塊發起的所有子kernel結束。往往不知道一個執行緒塊中哪些子kernel已經執行,可以通過下述方式進行一個執行緒塊級別的同步
|
1
2
3
4
5
6
|
void
threadBlockDeviceSynchronize(void)
{
__syncthreads();
if(threadIdx.x
==
0)
cudaDeviceSynchronize();
__syncthreads();
}
|
CudaDeviceSynchronize(void)呼叫開銷較大,不是必須的時候,儘量減少使用,同時不要在父kernel退出時呼叫,因為結束時存在上述介紹的隱式同步。
記憶體一致
當子 grids開始與結束之間,父grids和子grids有完全一致的global memory view。
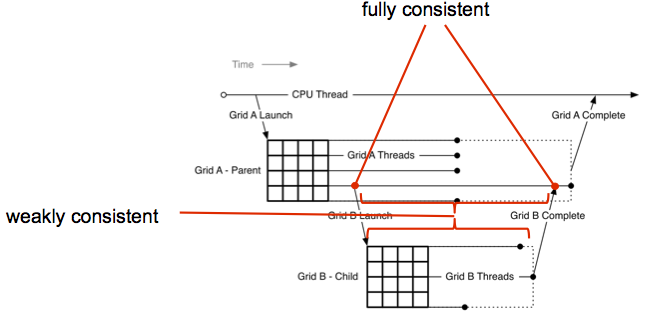
當子kernel launch的時候,global memory檢視不一致。
1 2 3 4 5 6 7 8 9 10 11 12 | __device__ int v = 0; __global__ void child_k(void) { printf("v = %d\n", v); } __global__ void parent_k(void) { v = 1; child_k <<< 1, 1 >>>> (); v = 2; // RACE CONDITION cudaDeviceSynchronize(); } |
在子kernel launch之後,顯示同步之前,parent grid不能對 child grid讀取的記憶體做寫入操作,否則會造成race condition。
向Child grids傳遞指標
指標的傳遞存在限制:
- 可以傳遞的指標:global memory(包括__device__變數和malloc分配的記憶體),zero-copy host端記憶體,常量記憶體。
- 不可以傳遞的指標:shared_memory(__shared__變數), local memory(包括stack變數)
Device Streams和Events
所有在device上建立的streams都是non-blocking的,不支援預設NULL stream的隱式同步。建立流的方式如下
|
1
2
|
cudaStream_t
s;
cudaStreamCreateWithFlags(&s,
cudaStreamNonBlocking);
|
一旦一個device stream被建立,它能被一個執行緒塊中其他執行緒使用。只有當這個執行緒塊完成執行的時候,這個stream才能被其他執行緒塊或者host使用。反之亦然。
Event也是支援的,不過有限制,只支援在不同stream之間使用cudaStreamWaitEvent()指定執行順序,而不能使用event來計時或者同步。
Recursion Depth和Device Limits
遞迴深度包括兩個概念:
- nesting depth:遞迴grids的最大巢狀層次,host端的為0;
-
synchronization depth:cudaDeviceSynchronize()能呼叫的最大巢狀層次,host端為1,cudaLimitDevRuntimeSyncDepth應該設定為maximum 所以你吃肉你咋體on depth加1,設定方式如
cudaDeviceLimit(cudaLimitDevRuntimeSyncDepth, 4).
maximum nesting depth有硬體限制,在CC3.5中, 對depth 的限制為24. synchronization depth也一樣。
從外到內,直到最大同步深度,每一次層會保留一部分記憶體來儲存父block的上下文資料,即使這些記憶體沒有被使用。所以遞迴深度的設定需要考慮到每一層所預留的記憶體。
另外還有一個限制是待處理的子grid數量。pending launch buffer用來維持launch queue和追蹤當前執行kernel的狀態。通過
|
1
|
cudaDeviceSetLimit(cudaLimitDevRuntimePendingLaunchCount,
32768);
|
來設定合適的限制。否則通過cudaGetLastError()呼叫可以返回CudaErrorLaunchPendingCountExceeded的錯誤。
動態並行化執行有點類似樹的結構,但與CPU上樹處理也有些不同。類似深度小,分支多,比較茂密的樹的執行結構,比較適合動態並行化的處理。深度大,每層節點少的樹的執行結構,則不適合動態並行化。
| characteristic | tree processing | dynamic parallelism |
| node | thin (1 thread) | thick (many threads) |
| branch degree | small (usually < 10) | large (usually > 100) |
| depth | large |
small |
相關文章
- CUDA3.0的C++支援詳解C++
- iOS之runtime詳解api(二)iOSAPI
- MySQL之SQL優化詳解(二)MySql優化
- 優化器革命之-Dynamic Sampling(二)優化
- 第二個 CUDA 程式
- ORM框架之GreenDao3.0使用詳解(二)ORM框架
- Redis資料結構詳解之List(二)Redis資料結構
- VC++深入詳解--之複習筆記(二)C++筆記
- 【Android 動畫】動畫詳解之插值器(二)Android動畫
- Storm Topology ParallelismORMParallel
- 【CUDA】CUDA9.0+VS2017+win10詳細配置Win10
- CTMediator 原理詳解(二)
- Flutter 動畫詳解(二)Flutter動畫
- Java集合詳解(二)Java
- Oracle checkpoint詳解二Oracle
- JavaScript之this詳解JavaScript
- CUDA優化之指令優化優化
- Android Service詳解(二)Android
- JavaScript繼承詳解(二)JavaScript繼承
- Spring Aop 詳解二Spring
- jquery validate 詳解二jQuery
- SpringMVC詳解(二)------詳細架構SpringMVC架構
- SVG之Path路徑詳解(二),全面解析貝塞爾曲線SVG
- BeetleX之WebSocket詳解Web
- MySql之EXPLAN詳解MySql
- Flutter之ElevatedButton詳解Flutter
- Java之Super詳解Java
- CSS之Position詳解CSS
- Java 之 synchronized 詳解Javasynchronized
- CUDA 學習筆記之程式棧筆記
- Flutter常用Widget詳解(二)Flutter
- Go 語言介面詳解(二)Go
- 詳解C#泛型(二)C#泛型
- Scrapy基礎(二): 使用詳解
- Azure Terraform(二)語法詳解ORM
- 元件化實踐詳解(二)元件化
- MapReduce 二次排序詳解排序
- 面試問答詳解(二) (轉)面試