資料探勘十大演算法之Apriori詳解
在2006年12月召開的 IEEE 資料探勘國際會議上(ICDM, International Conference on Data Mining),與會的各位專家選出了當時的十大資料探勘演算法( top 10 data mining algorithms ),可以參見文獻【1】。本部落格已經介紹過的位列十大演算法之中的演算法包括:
- [1] k-means演算法(http://blog.csdn.net/baimafujinji/article/details/50570824)
- [2] 支援向量機SVM(http://blog.csdn.net/baimafujinji/article/details/49885481)
- [3] EM演算法(http://blog.csdn.net/baimafujinji/article/details/50626088)
- [4] 樸素貝葉斯演算法(http://blog.csdn.net/baimafujinji/article/details/50441927)
- [5]
k kNN演算法(http://blog.csdn.net/baimafujinji/article/details/6496222) - [6] C4.5決策樹演算法(http://blog.csdn.net/baimafujinji/article/details/53239581)
- [7] CART演算法(http://blog.csdn.net/baimafujinji/article/details/53269040)
Apriori演算法是一種用於關聯規則挖掘(Association rule mining)的代表性演算法,它同樣位居十大資料探勘演算法之列。關聯規則挖掘是資料探勘中的一個非常重要的研究方向,也是一個由來已久的話題,它的主要任務就是設法發現事物之間的內在聯絡。
歡迎關注白馬負金羈的部落格 http://blog.csdn.net/baimafujinji,為保證公式、圖表得以正確顯示,強烈建議你從該地址上檢視原版博文。本部落格主要關注方向包括:數字影象處理、演算法設計與分析、資料結構、機器學習、資料探勘、統計分析方法、自然語言處理。
引言:資料探勘與機器學習
有時候,人們會對機器學習與資料探勘這兩個名詞感到困惑。如果你翻開一本冠以機器學習之名的教科書,再同時翻開一本名叫資料探勘的教材,你會發現二者之間有相當多重合的內容。比如機器學習中也會講到決策樹和支援向量機,而資料探勘的書裡也必然要在決策樹和支援向量機上花費相當的篇幅。可見二者確有相當大的重合面,但如果細研究起來,二者也的確是各自不同的領域。
大體上看,資料探勘可以視為資料庫、機器學習和統計學三者的交叉。簡單來說,對資料探勘而言,資料庫提供了資料管理技術,而機器學習和統計學則提供了資料分析技術。所以你可以認為資料探勘包含了機器學習,或者說機器學習是資料探勘的彈藥庫中一類相當龐大的彈藥集。既然是一類彈藥,其實也就是在說資料探勘中肯定還有其他非機器學習範疇的技術存在。Apriori演算法就屬於一種非機器學習的資料探勘技術。
我們都知道資料探勘是從大量的、不完全的、有噪聲的、模糊的、隨機的資料中,提取隱含在其中的、人們事先不知道的、但又是潛在有用的資訊和知識的過程。 而機器學習是以資料為基礎,設法構建或訓練出一個模型,進而利用這個模型來實現資料分析的一類技術。這個被訓練出來的機器學習模型當然也可以認為是我們從資料中挖掘出來的那些潛在的、有意義的資訊和知識。在非機器學習的資料探勘技術中,我們並不會去建立這樣一個模型,而是直接從原資料集入手,設法分析出隱匿在資料背後的某些資訊或知識。在後續介紹Apriori演算法時,你會相當明顯地感受到這一特點。
基本概念
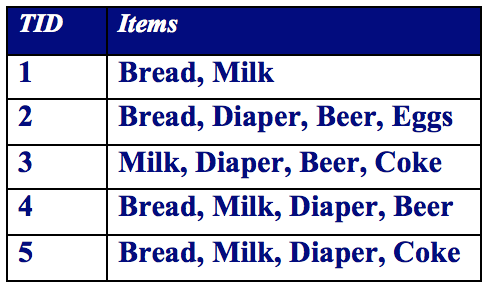
許多商業企業在日復一日的運營中積聚了大量的交易資料。例如,超市的收銀臺每天都收集大量的顧客購物資料。例如,下表給出了一個這種資料集的例子,我們通常稱其為購物籃交易(market basket transaction)。表中每一行對應一個交易,包含一個唯一標識TID和特定顧客購買的商品集合。零售商對分析這些資料很感興趣,以便了解其顧客的購買行為。可以使用這種有價值的資訊來支援各種商業中的實際應用,如市場促銷,庫存管理和顧客關係管理等等。
令
關聯規則是形如
例如考慮規則{Milk, Diaper}
Association Rule Mining Task:Given a set of transactions T, the goal of association rule mining is to find all rules having
- support ≥ minsup threshold
- confidence ≥ minconf threshold
因此,大多數關聯規則挖掘演算法通常採用的一種策略是,將關聯規則挖掘任務分解為如下兩個主要的子任務。
- 頻繁項集產生:其目標是發現滿足最小支援度閾值的所有項集,這些項集稱作頻繁項集(frequent itemset)。
- 規則的產生:其目標是從上一步發現的頻繁項集中提取所有高置信度的規則,這些規則稱作強規則(strong rule)。
通常,頻繁項集產生所需的計算開銷遠大於產生規則所需的計算開銷。
最容易想到、也最直接的進行關聯關係挖掘的方法或許就是暴力搜尋(Brute-force)的方法:
- List all possible association rules
- Compute the support and confidence for each rule
- Prune rules that fail the minsup and minconf thresholds
然而,由於Brute-force的計算量過大,所以取樣這種方法並不現實!格結構(Lattice structure)常被用來列舉所有可能的項集。如下圖所示為
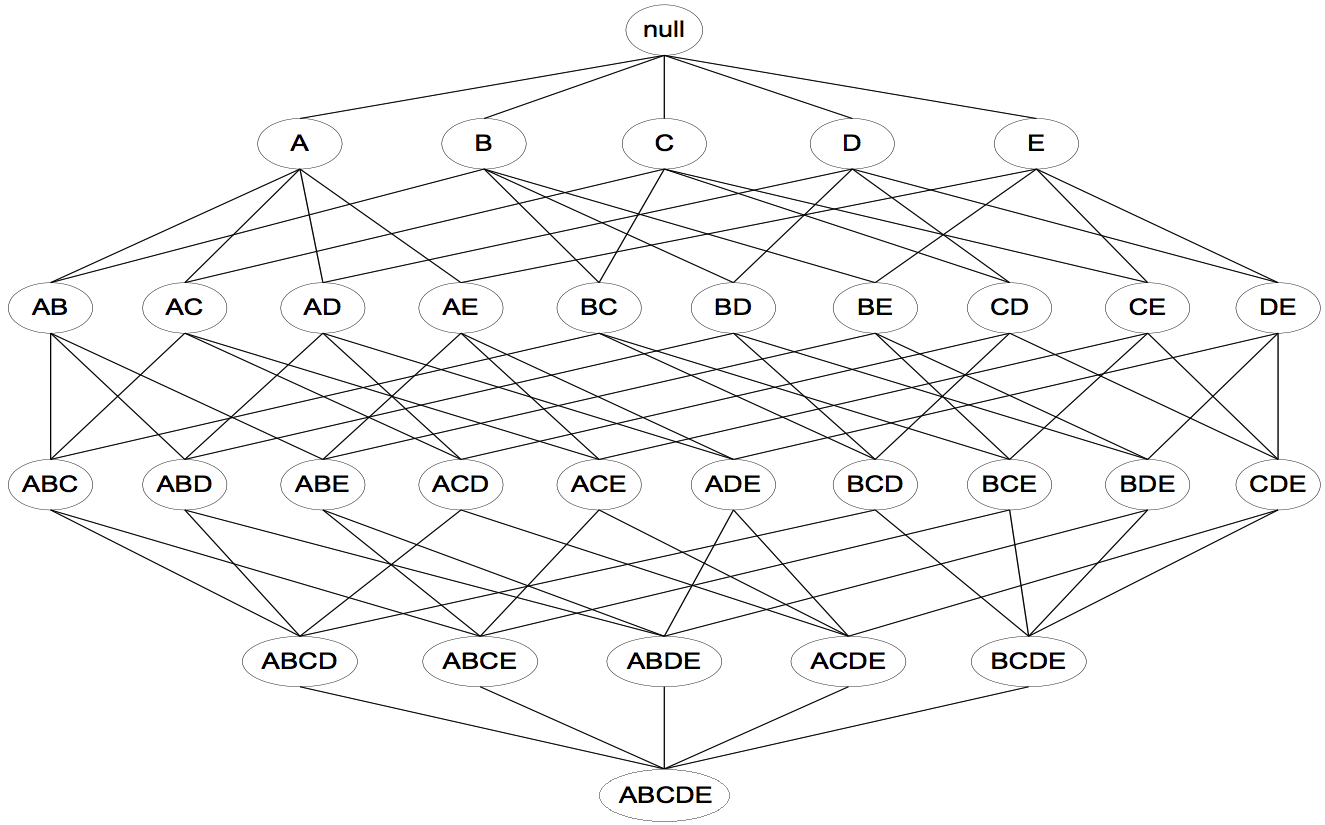
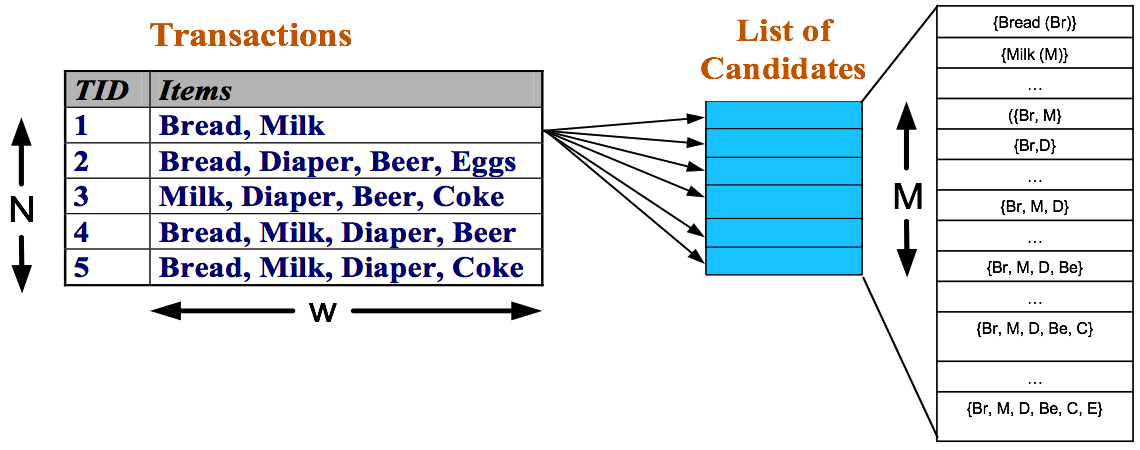
發現頻繁項集的一種原始方法是確定格結構中每個候選項集(candidate itemset)的支援度計 數。為了完成這一任務,必須將每個候選項集與每個交易進行比較,如下圖所示。如果候選項集包含在交易中,則候選項集的支援度計數增加。例如,由於項集{Bread, Milk}出現在事務1、4 和5中,其支援度計數將增加3次。這種方法的開銷可能非常大,因為它需要進行
先驗原理
在上一小節的末尾,我們已經看到Brute-force在實際中並不可取。我們必須設法降低產生頻繁項集的計算複雜度。此時我們可以利用支援度對候選項集進行剪枝,這也是Apriori所利用的第一條先驗原理:
Apriori定律1:如果一個集合是頻繁項集,則它的所有子集都是頻繁項集。
例如:假設一個集合{A,B}是頻繁項集,即A、B同時出現在一條記錄的次數大於等於最小支援度min_support,則它的子集{A},{B}出現次數必定大於等於min_support,即它的子集都是頻繁項集。
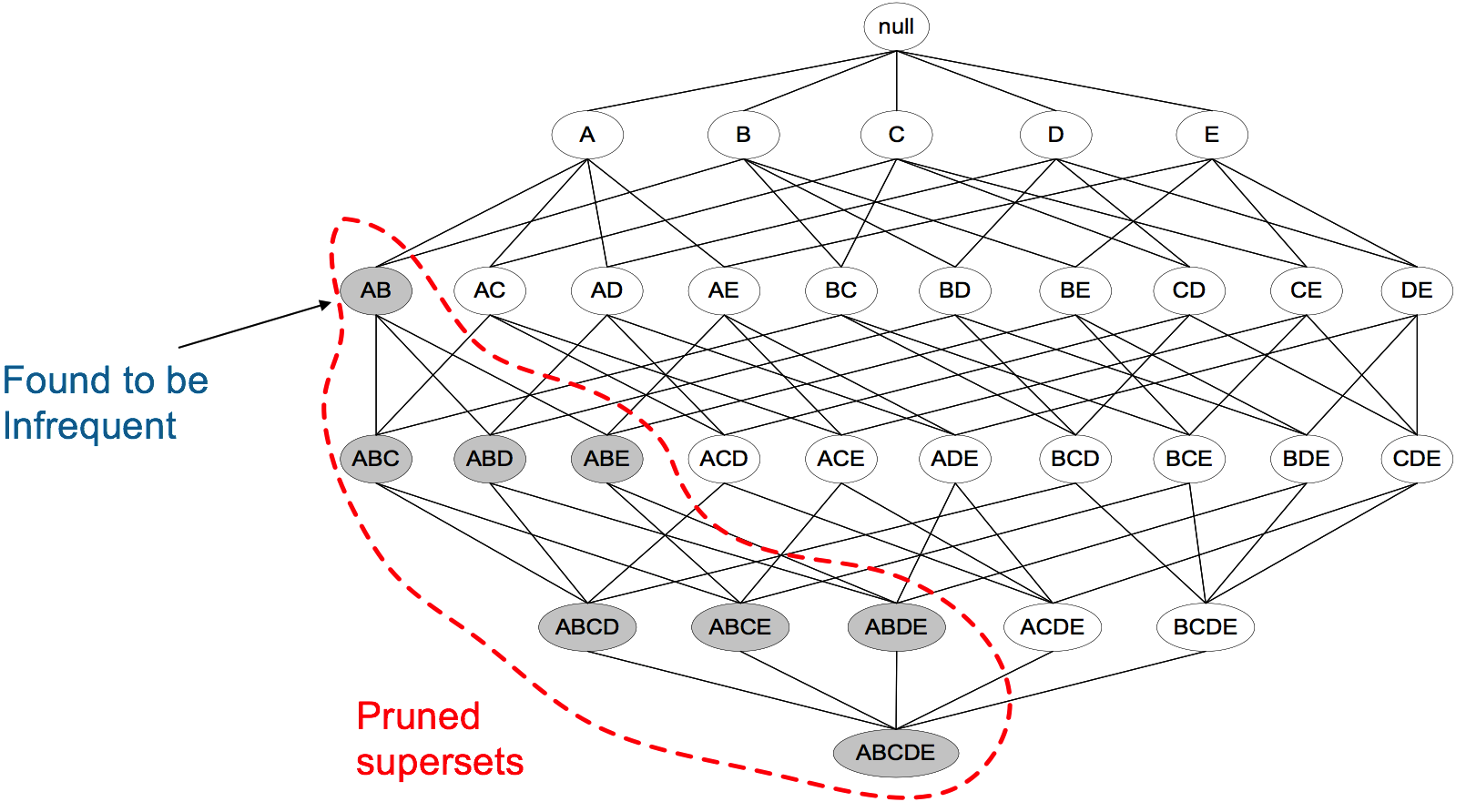
Apriori定律2:如果一個集合不是頻繁項集,則它的所有超集都不是頻繁項集。
舉例:假設集合{A}不是頻繁項集,即A出現的次數小於 min_support,則它的任何超集如{A,B}出現的次數必定小於min_support,因此其超集必定也不是頻繁項集。
下圖表示當我們發現{A,B}是非頻繁集時,就代表所有包含它的超級也是非頻繁的,即可以將它們都剪除。
Apriori演算法與例項
R. Agrawal 和 R. Srikant於1994年在文獻【2】中提出了Apriori演算法,該演算法的描述如下:
- Let
k k=1 - Generate frequent itemsets of length
k k - Repeat until no new frequent itemsets are identified
- Generate length (
k k+1) candidate itemsets from lengthk kfrequent itemsets - Prune candidate itemsets containing subsets of length
k k+1 that are infrequent - Count the support of each candidate by scanning the DB
- Eliminate candidates that are infrequent, leaving only those that are frequent
- Generate length (
或者在其他資料上更為常見的是下面這種形式化的描述(注意這跟前面的文字描述是一致的):

下面是一個具體的例子,最開始資料庫裡有4條交易,{A、C、D},{B、C、E},{A、B、C、E},{B、E},使用min_support=2作為支援度閾值,最後我們篩選出來的頻繁集為{B、C、E}。
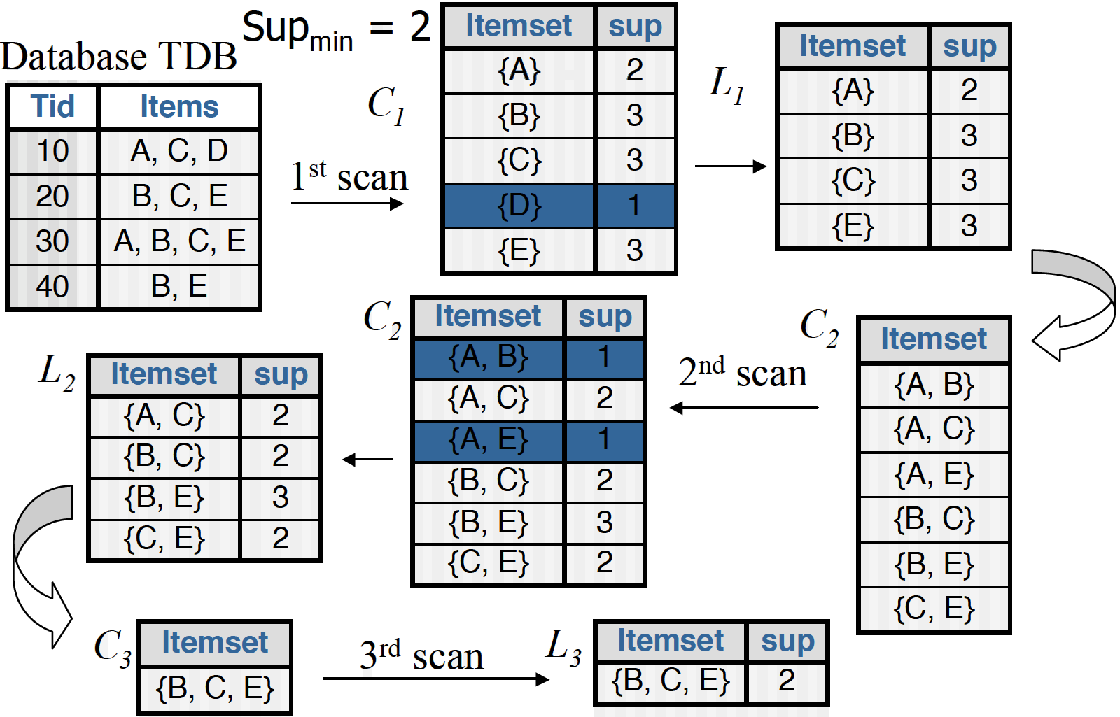
上述例子中,最值得我們從

可見生成策略由兩部分組成,首先是self-joining部分。例如,假設我們有一個
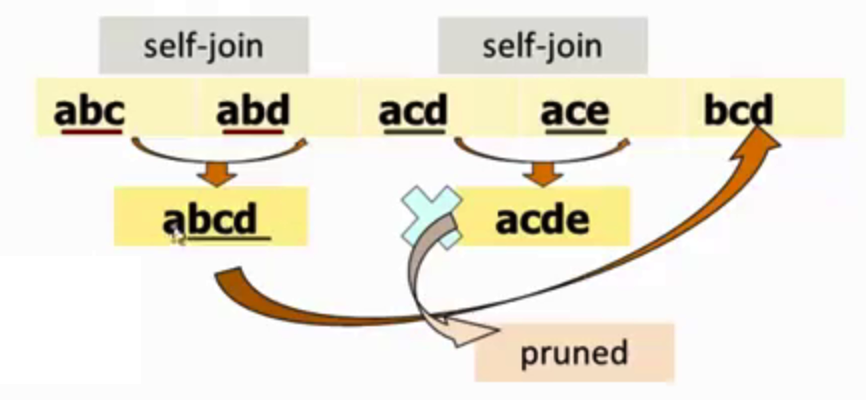
回到之前的例子,從
參考文獻
【1】Wu, X., Kumar, V., Quinlan, J.R., Ghosh, J., Yang, Q., Motoda, H., McLachlan, G.J., Ng, A., Liu, B., Philip, S.Y. and Zhou, Z.H., 2008. Top 10 algorithms in data mining. Knowledge and information systems, 14(1), pp.1-37. (http://www.cs.uvm.edu/~icdm/algorithms/10Algorithms-08.pdf)
【2】Rakesh Agrawal and Ramakrishnan Srikant Fast algorithms for mining association rules in large databases. Proceedings of the 20th International Conference on Very Large Data Bases, VLDB, pages 487-499, Santiago, Chile, September 1994. (http://rakesh.agrawal-family.com/papers/vldb94apriori.pdf)
【3】Pang-Ning Tan, Micheale Steinbach, Vipin Kumar. 資料探勘導論,範明,等譯. 人民郵電出版社,2011
相關文章
- 資料探勘十大演算法演算法
- 資料探勘十大經典演算法演算法
- 十大資料探勘演算法及各自優勢大資料演算法
- 詳細解釋資料探勘中的 10 大演算法(上)演算法
- 圖說十大資料探勘演算法(一)K最近鄰演算法大資料演算法
- 資料探勘領域十大經典演算法之—樸素貝葉斯演算法(附程式碼)演算法
- 常用資料探勘演算法演算法
- Apriori演算法演算法
- 資料探勘演算法之-關聯規則挖掘(Association Rule)演算法
- 關聯規則方法之apriori演算法演算法
- 關聯規則挖掘之apriori演算法演算法
- 資料探勘之預測篇
- 十大排序演算法詳解排序演算法
- 資料探勘之KMeans演算法應用與簡單理解演算法
- 資料探勘聚類之k-medoids演算法實現聚類演算法
- 28頁PPT詳解騰訊資料探勘體系及應用
- 資料探勘之 層次聚類聚類
- 資料探勘之關聯規則
- python 資料探勘演算法簡要Python演算法
- 資料探勘與分析 概念與演算法演算法
- 資料探勘中分類演算法總結演算法
- 資料探勘之資料準備——原始資料的特性
- 程式設計師必須知道機器學習與資料探勘十大經典演算法:PageRank演算法篇程式設計師機器學習演算法
- 《資料探勘導論》實驗課——實驗四、資料探勘之KNN,Naive BayesKNNAI
- 【Python資料探勘課程】八.關聯規則挖掘及Apriori實現購物推薦Python
- 圖資料探勘:社群檢測演算法(一)演算法
- 資料探勘(7):分類演算法評價演算法
- 【大資料】你務必要搞清楚的十大資料探勘知識點大資料
- Apriori演算法原理總結演算法
- Apriori演算法 java程式碼演算法Java
- Apriori演算法的介紹演算法
- 大資料應用——資料探勘之推薦系統大資料
- 【python資料探勘課程】二十.KNN最近鄰分類演算法分析詳解及平衡秤TXT資料集讀取PythonKNN演算法
- 《資料結構與演算法》之十大基礎排序演算法資料結構演算法排序
- 自學資料探勘
- Web資料探勘Web
- 序列資料探勘
- 資料探勘概念