硬聚類(HCM)和模糊聚類(FCM)在彩色影象分割中的具體應用
示例工程見:
http://files.cnblogs.com/laviewpbt/%e5%9b%be%e5%83%8f%e6%a8%a1%e7%b3%8a%e8%81%9a%e7%b1%bb.rar
一年前我寫過模糊聚類演算法(FCM)和硬聚類演算法(HCM)的VB6.0實現及其應用 一文,之後,有不少同仁向我詢問如何將這個演算法應用在彩色影象的分割上,鑑於影象資料的特殊性,這裡簡單的談談在影象中聚類演算法的需要注意一些細節。
C均值聚類演算法較其他的聚類演算法的主要優點是可以對大資料量進行計算(我也寫過基於模糊等價關係的模糊聚類分析 ,這個方法只能分析很小的資料量),並且理論上已經證明該演算法是收斂的。因此,對於影象的分割,特別是多於2類的彩色影象分割(2類的分割即二值化的過程,已經有著很多的方法,參見幾種經典的二值化方法及其vb.net實現 ,但是這些方法很難擴充套件的多類分割中),有著廣泛的應用。
我們知道,彩色影象的資料可以看成一M*N*3的陣列,但是一方面三維陣列的處理速度要低於一維或二維陣列,另外從FCM通用性上講,一般要分割的物件為樣本組,而一個樣本可以看成是n維空間中的一個點,因此,用二維陣列來描述要分割的物件不僅意義明顯而且有利於計算速度的提高。在MATLAB以及前面我寫的那個FCM函式中第一維是樣本,第二維是樣本的具體資料,但是,影象資料在記憶體中的排列方式是BGRABRGABGRA.......(32位的),這樣,通過API函式直接讀取的資料一般為一(1 to 4,1 to M*N)陣列,因此,要把前面寫的那個FCM函式應用於影象分割,首先要改變下函式內部分迴圈的次序,這是其一。
彩色影象的資料量非常之大,要使得FCM或HCM函式具有實用價值,就必須把握好函式的每一個細節。下面我就在實際中我遇到的幾個問題向大家描述下。
1、初始中心的選取
初始中心的選取其否合理直接影響著計算的速度和結果。不合理的初始點,可能導致結果收斂至一個不希望的極小點。這裡提供幾個選取初始中心點的方法以供參考。
- 隨機值 當我們對樣本的來源或分佈沒有任何的先驗知識時,這不失為一種上策,但是要注意不要超過已知資料的分佈範圍,比如對於影象資料,可以用rnd*255保證資料在(0~255)之間。但是這種方法的計算速度是相當緩慢的。
- 從已知資料中隨機的選幾個 這種方法要比第一種稍微合理點,以已知的資料點為中心也要更加透明點。
- 從已知資料按等距離選區幾個點 類似於上述方法
- 均值-標準差法 。根據隨機函式的分佈知識,聚類的資料應主要分佈在所有資料的均值附近。標準差是評價資料分佈的又一重要指標,假設所有資料的均值為μ,標準差為σ,則資料應該主要分佈在(μ-σ,μ+σ)之間。假設分類數為N,選擇初始分類點為(μ-σ,μ+σ)之間的N 個等分點進行分類。影象資料可以分別在R/G/B上做上述計算,實際執行的結果也表明這種方法在大多數情況下要比上述三種方法速度快。
- 從縮圖得到中心 這一方法是專門針對影象的,通過先在一定大小縮圖中進行聚類,得到初始聚類中心,因為縮圖在資料可以看成原始資料的壓縮,並且這種壓縮對聚類中心的影響很小,而且生成縮圖有高速的演算法,同聚類相比,所需要的時間可以不計。
- 手工輸入資料 針對具體的一些列影象,比如醫學影象,我們一般情況下能夠知道大概的聚類中心,這樣通過人工指定初始聚類中心使得其和最終的中心接近以加快速度。
- 對於FCM演算法,還可以先用HCM產生中心點。
2. 樣本空間的選取
- 通常情況下,我們可以直接使用R|G|B值作為待聚類的資料。
- 如果考慮噪音的影響,可以先濾波或者選擇恰當的模板(比如3*3加權模板)生成的資料作為聚類資料來源。
- 採用HSB或其他顏色空間的資料
- 對於彩色影象的資料,實際上有很多畫素的顏色是一樣的,這樣採用對資料壓縮、合併的方法, 減少參與計算的資料量, 降低運算開銷, 極大地減少FCM演算法每次迭代過程的時間, 提高計算速度。我們先計算出影象中實際使用的不同的顏色數以及每個顏色數所具有的畫素數量,則在迭代中需要計算的資料量大為減少。但是這種方法對於HCM可能不是很合適,下面將繼續討論。
3. 距離的定義方式
不同的定義方式體現了不同的分割思想,以下是常用的集中距離定義方式。
- 歐式距離(Euclidean Distance)
(1)相信大家對這個距離公式是非常熟悉的,初中時就學了,也稱它為兩點間的距離。p和q之間的歐式距離定義如下:
De(p , q) = [(x - s)2 + (y - t)2]1/2
(2)距離直觀描述:距點(x , y)小於或等於某一值r的歐式距離是中心在(x , y)半徑為r的圓平面。 - 城區距離(City-Block Distance)
(1)p和q之間的城區距離定義如下:
D4(p , q) = |x - s| + |y - t|
(2)距離直觀描述:距點(x , y)小於或等於某一值r的城區距離是中心在(x , y)對角線為2r的菱形。 - 棋盤距離(Chess Board Distance)
(1)p和q之間的棋盤距離定義如下:
D8(p , q) = max(|x - s| , |y - t|)
(2)距離直觀描述:距點(x , y)小於或等於某一值r的棋盤距離是中心在(x , y)對角線為2r的正方形。
詳見:http://www.ownsoft.com/blog/blogview.asp?logID=48
4. 優化技巧
- 利用臨時陣列儲存常用的一些計算值,比如在才採用城區距離和棋盤距離時,定義TempArray陣列並賦值如下:
For i = -255 To 255
TempArray(i) = Abs(i)
Next
這樣比直接在程式碼裡用abs函式效率要高很多,即使用下述程式碼
Dist = TempArray(Data(1, i) - OldCenter(j, 1)) + TempArray(Data(2, i) - OldCenter(j, 2)) + TempArray(Data(3, i) - OldCenter(j, 3))
代替語句:
Dist = Abs(Data(1, i) - OldCenter(j, 1)) + Abs(Data(2, i) - OldCenter(j, 2)) + Abs(Data(3, i) - OldCenter(j, 3))
一個誤區 :我曾在計算歐式距離的時候也定義了一個256個元素的陣列記錄n^2,然後用陣列代替n*n計算,結果發現這樣會導致計算速度的下降,所以在VB中這種簡單的加減乘除還是很快的,只有在用像abs,Exp等函式時,如果方便在事前計算好查詢表才會加快速度。
- 中間的二維陣列變數全部用一維陣列代替,同樣的資料量一維陣列要快些,這樣大約可以提速10%。
- 用n*n代替n^2,用 Exp(Log(Degree(i, j)) * Exponent)代替Degree(i, j)^Exponent,可能時用右除代替左除。對於大量迴圈中的這種運算,前者的速度絕對要比後者快很多。
- 不要偷懶用for k=1 to 3 ,要手工展開每一項
- 最小收斂距離取12的理由是 2^2+2^2+2^2,取得更小沒有意義,因為影象資料的聚類中心始終是整型。同樣,在大部分的資料型別的選擇中,都可以用整型代替雙精度型。
下面以部分分割效果來說明上述問題:
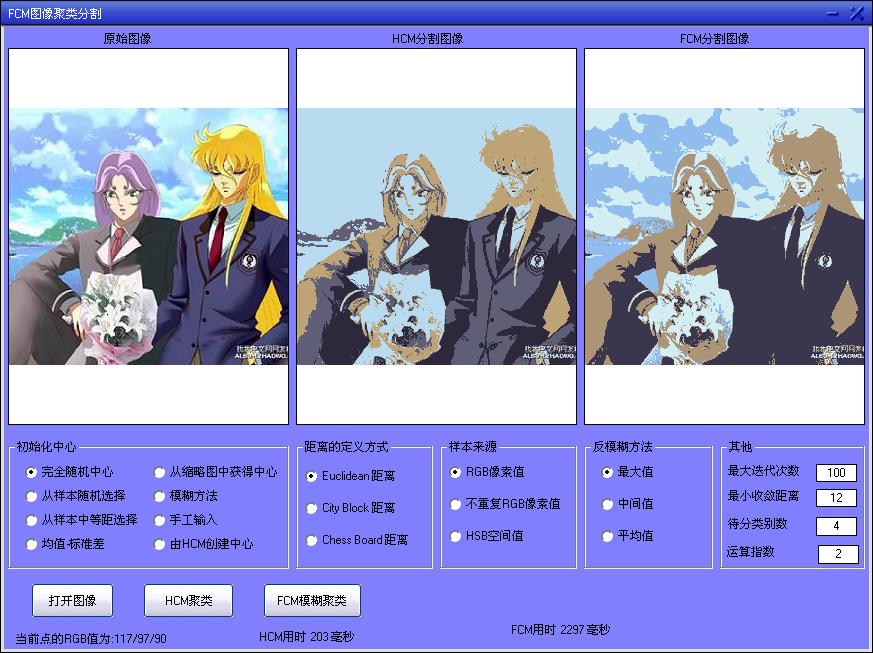
可以看出,採用隨機中心,特別是對於FCM演算法,要經過很長時間才能收斂。
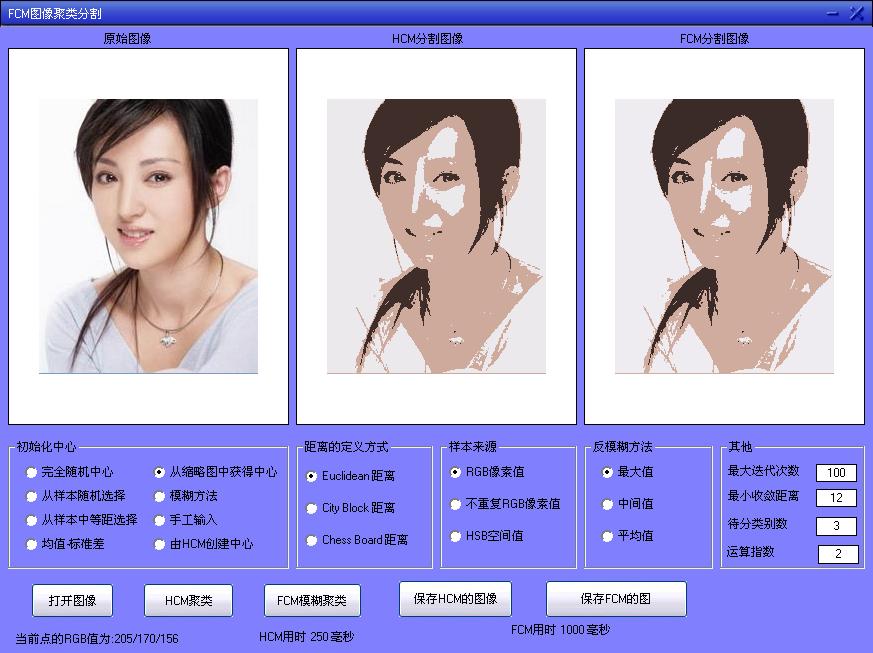
對美女分類, 採用從縮圖獲得中心、樣本來源於RGB畫素值。HCM用時0.25s,FCM用時1s。
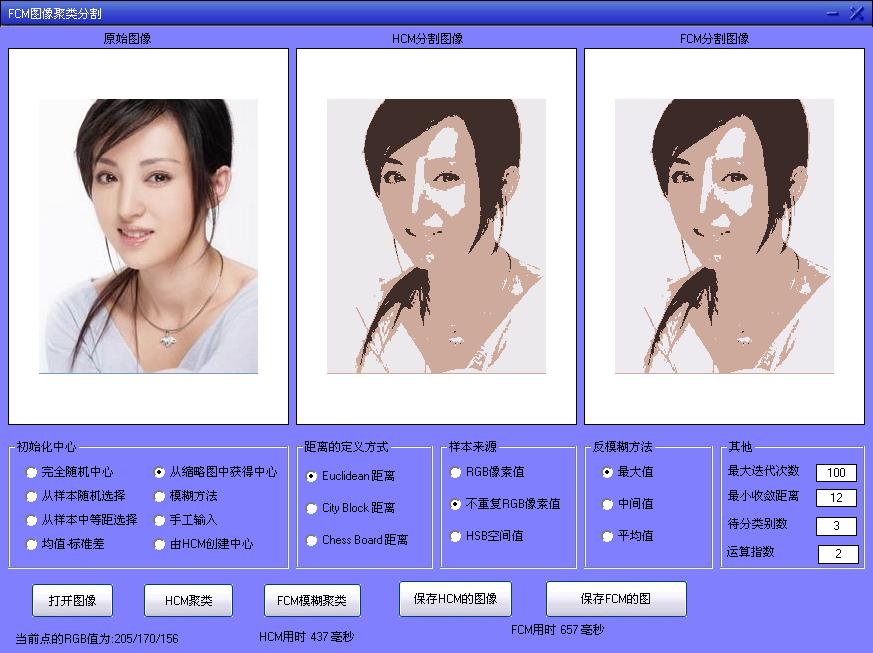
其他條件不變,樣本來源選擇不重複的RGB畫素值,HCM用時增加為437ms,FCM用時降低為657ms,這是因為針對這幅影象,HCM演算法中分析不重複顏色值所需要的時間增量比迴圈時所節省時間要多,而FCM演算法由於其迴圈的複雜度要高很多,當減小迴圈量時節省的時間特別明顯。
一般情況下,一副彩色影象中不重複的顏色值和總的畫素個數的比例可以達到1:5,當這個比值越明顯的時候,採用不重複的RGB畫素值時則速度提升越明顯,特別是對於FCM演算法,時間可以降為原來的1/3左右。
相關文章
- 分類 和 聚類聚類
- 統計分析和智慧聚類在遊戲資料中的應用聚類遊戲
- 聚類之K均值聚類和EM演算法聚類演算法
- 聚類kmeans演算法在yolov3中的應用聚類演算法YOLO
- 聚類演算法在 D2C 佈局中的應用聚類演算法
- 【機器學習】--譜聚類從初始到應用機器學習聚類
- 聚類分析聚類
- 推薦系統中的產品聚類:一種文字聚類的方法聚類
- 【機器學習】---密度聚類從初識到應用機器學習聚類
- 聚類(part3)--高階聚類演算法聚類演算法
- Spark中的聚類演算法Spark聚類演算法
- 聚類分析軟體操作流程聚類
- 教你文字聚類聚類
- FCM聚類演算法詳解(Python實現iris資料集)聚類演算法Python
- 聚類分析-案例:客戶特徵的聚類與探索性分析聚類特徵
- 【機器學習】--層次聚類從初識到應用機器學習聚類
- 【Python機器學習實戰】聚類演算法(2)——層次聚類(HAC)和DBSCANPython機器學習聚類演算法
- 用Python實現文件聚類Python聚類
- 聚類演算法聚類演算法
- 機器學習——dbscan密度聚類機器學習聚類
- 【scipy 基礎】--聚類聚類
- 機器學習(8)——其他聚類機器學習聚類
- 09聚類演算法-層次聚類-CF-Tree、BIRCH、CURE聚類演算法
- Clustering and Projected Clustering with Adaptive Neighbors(自適應鄰域聚類CAN和自適應鄰域投影聚類PCAN)ProjectAPT聚類PCA
- java寫的 聚類搜尋Java聚類
- 用scikit-learn學習DBSCAN聚類聚類
- 用scikit-learn學習BIRCH聚類聚類
- 用scikit-learn學習譜聚類聚類
- 04聚類演算法-程式碼案例一-K-means聚類聚類演算法
- 應用聚類模型獲得聊天機器人語料聚類模型機器人
- 機器學習 之 層次聚類機器學習聚類
- 譜聚類原理總結聚類
- 機器學習-聚類分析之DBSCAN機器學習聚類
- k-means聚類聚類
- 機器學習入門|聚類(二)機器學習聚類
- unit3 文字聚類聚類
- K-均值聚類分析聚類
- 【Python機器學習實戰】聚類演算法(1)——K-Means聚類Python機器學習聚類演算法