關聯規則apriori演算法的python實現
學了兩天python,想實踐下,正好最近在學習資料探勘,先用python實現下
注:由於後面加了註釋,由於編碼問題,可能即使是註釋,有的環境也不支援漢字的編碼,執行報錯的話可以將漢字刪除後再執行
環境 ubuntu 13.4 python 2
import itertools
import copy
'''
定義全域性變數k,即支援度計數k,此k也可以在執行程式之前輸入,簡單改動即可
'''
k = 2
'''
儲存頻繁項集的列表
'''
frequenceItem = []
'''
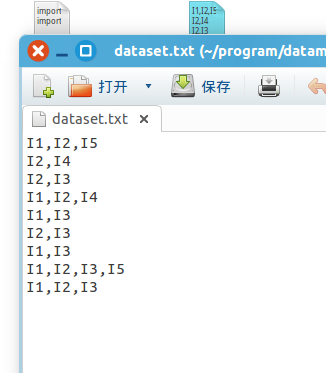
從txt檔案dataset.txt裡獲取事務集
'''
def getDataSet(args):
f = open(args,'r')
source = f.readlines()
f.close()
dataset = []
for line in source:
temp1 = line.strip('\r\n')
temp2 = temp1.split(',')
dataset.append(temp2)
return dataset
'''
初步掃描事務集,從事務集裡獲取候選1項集
方法的基本思路是:
定義一個集合tmp,將事務集的第一項作為tmp的初始集合
然後掃描事務集,將不在tmp裡的資料項加入tmp中
'''
def find_item( dataset ):
length = len(dataset)
for i in range(0, length):
if i == 0:
tmp = set(dataset[i])
tmp.update(set(dataset[i]))
candidate=list(tmp)
candidate.sort()
return candidate
'''
從候選項集裡找出頻繁項集,其中num代表頻繁num+1項集
如num為0的為從候選1項集裡找出頻繁1項集
方法基本思路:
1、定義一個支援度列表count
2、對於每一個候選項,依次掃描事務集,如果該項出現在事務集中就將該項對應的count+1、定義一個支援度列表count+1
3、將每一項的count和k(支援度計數)進行比較,將count小於k的項剔除
'''
def find_frequent( candidate, dataset, num):
frequence = []
length = len(candidate)
count = []
for i in range(0, length):
count.append(0)
count[i] = 0
if num == 0:
'''
其實不管num為0還是別的值演算法應該是一樣的,但是由於程式實現上的問題
num為0的時候選項集是一維列表,其它的時候,候選項集是二維列表,
畢竟只是自己寫著玩的,python還不熟,牽一髮而動全身,懶得改了
'''
child= set([candidate[i]])
else:
child = set(candidate[i])
for j in dataset:
parent = set(j)
if child.issubset(parent):
count[i] = count[i]+1
for m in range(0, length):
if count[m] >= k:
frequence.append(candidate[m])
return frequence
'''
先驗定理,剪枝掉不必要的候選n項集
方法思路:
1、依次取出候選項集裡的項
2、取出n項集裡的n-1項子集
3、如果所有的n-1項集不都都是頻繁n-1項集的子集,則刪除該候選項集
'''
def pre_test(candidate, num,frequence):
r_candidate = copy.deepcopy(candidate)
for each in candidate:
for each2 in itertools.combinations(each,num):
tmp= (list(each2))
tag = 0
for j in frequence:
if num == 1:
if (tmp[0] == j):
tag = 1
break
else:
if tmp == j:
tag = 1
break
if tag == 0:
r_candidate.remove(each)
break
return r_candidate
'''
通過頻繁n-1項集產生候選n項集,並通過先驗定理對候選n項集進行剪枝
方法思路:
1、如果是頻繁1項集,則通過笛卡爾積產生頻繁2項集
2、如果不是頻繁一項集,採用F(k-1) * F(k-1)方法通過頻繁n-1項集產生候選n項集
注:F(k-1) * F(k-1)方法在我的另一篇關聯演算法部落格上做了理論上的簡單介紹,或者也可以直接參看《資料探勘導論》
'''
def get_candidata( frequence, num ):
length = len(frequence)
candidate =[]
if num == 1:
for each in itertools.combinations(frequence,2):
tmp = list(each)
tmp3 = []
tmp3.append(tmp[0])
tmp3.append(tmp[1])
candidate.append(tmp3)
else:
for i in range(0,length-1):
tmp1 = copy.deepcopy(frequence[i])
tmp1.pop(num-1)
for j in range(i+1, length):
tmp2 = copy.deepcopy(frequence[j])
tmp2.pop(num-1)
if tmp1 == tmp2:
tmp3 = copy.deepcopy(frequence[i])
tmp3.append(frequence[j][num-1])
candidate.append(tmp3)
candidate2 = pre_test(candidate, num, frequence)
return candidate2
'''
main程式
'''
if __name__=='__main__':
dataset = getDataSet('dataset.txt')
Item = find_item(dataset)
num = 0
frequenceItem= []
'''
通過事務集找到頻繁項集,直至頻繁n項集為空,則退出迴圈
'''
while 1:
if num == 0:
candidate = Item
else:
candidate = get_candidata(frequenceItem[num-1],num)
frequenceItem.append(find_frequent( candidate, dataset, num))
if frequenceItem[num] == []:
frequenceItem.pop(num)
break
num = num+1
'''
列印出頻繁項集
'''
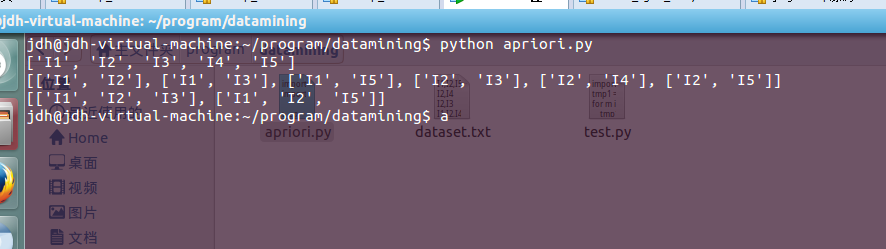
for each in frequenceItem:
print each
目錄位置:
編譯結果:
事務集合
相關文章
- 關聯規則方法之apriori演算法演算法
- 關聯規則挖掘(二)-- Apriori 演算法演算法
- 關聯規則挖掘之apriori演算法演算法
- 關聯規則挖掘:Apriori演算法的深度探討演算法
- Apriori 演算法-如何進行關聯規則挖掘演算法
- 關聯規則分析 Apriori 演算法 簡介與入門演算法
- 機器學習系列文章:Apriori關聯規則分析演算法原理分析與程式碼實現機器學習演算法
- 【Python資料探勘課程】八.關聯規則挖掘及Apriori實現購物推薦Python
- 基於Apriori關聯規則的電影推薦系統(附python程式碼)Python
- 關聯分析(二)--Apriori演算法演算法
- 直播系統,利用關聯規則實現推薦演算法演算法
- 使用apriori演算法進行關聯分析演算法
- 第十四篇:Apriori 關聯分析演算法原理分析與程式碼實現演算法
- 基於關聯規則的分類演算法演算法
- 關聯分析Apriori演算法和FP-growth演算法初探演算法
- 【機器學習】--關聯規則演算法從初識到應用機器學習演算法
- 資料探勘演算法之-關聯規則挖掘(Association Rule)演算法
- 資料探勘之關聯規則
- 推薦系統:關聯規則(2)
- Frequent Pattern 資料探勘關聯規則演算法(Aprior演算法) FT-Tree演算法
- Apriori演算法演算法
- 資料探勘(1):關聯規則挖掘基本概念與Aprior演算法演算法
- 大資料下的關聯規則,你知多少?大資料
- Apriori演算法的介紹演算法
- 市場購物籃分析(規則歸納/C5.0)+apriori
- Rational Performance Tester 資料關聯規則詳解ORM
- Java中動態規則的實現方式Java
- Apriori演算法原理總結演算法
- Apriori演算法 java程式碼演算法Java
- 關聯物件的實現原理【OC】物件
- DDD中實現業務規則的驗證 - Marcin
- 如何用Go快速實現規則引擎Go
- 用css實現不規則背景填充CSS
- 【java規則引擎】一個基於drools規則引擎實現的數學計算例子Java
- MyCat分片:分片規則的十四種演算法詳細解讀&程式碼實現(上篇)演算法
- hyperjumptech/grule-rule-engine: Golang的規則引擎實現Golang
- AssociatedObject關聯物件原理實現Object物件
- 模式識別中的Apriori演算法和FPGrowth演算法模式演算法