如何用C++實現自己的Tensorflow
原文:How To Write Your Own Tensorflow in C++
作者:Ray Zhang
翻譯:無阻我飛揚
摘要:TensorFlow是由谷歌基於DistBelief進行研發的第二代人工智慧學習系統,其命名來源於本身的執行原理,它完全開源,作者通過自己的一個小專案,闡述瞭如何用C++實現自己的TensorFlow,這篇文章看起來可能會有點晦澀,你需要對相關知識有所瞭解。以下是譯文。
在我們開始之前,以下是程式碼:
我和Minh Le一起做了這個專案。
為什麼?
如果你是CS專業的人員,可能聽過這句“不要使自己陷入_”的話無數次。CS有加密、標準庫、解析器等等。我覺得現在還應該包含ML庫。
不管事實如何,它仍然是一個值得學習的驚人的教訓。人們現在認為TensorFlow和類似的庫是理所當然的;把它們當成是一個黑盒子,讓其執行。沒有多少人知道後臺發生了什麼。這真是一個非凸的優化問題!不要停止攪拌那堆東西,直到它看起來合適為止(結合下圖及機器學習系統知識去理解這句話)。

Tensorflow
TensorFlow是由Google開源的一個深度學習庫。在TensorFlow的核心,有一個大的元件,將操作串在一起,行成一個叫做 運算子圖 的東西。這個運算子圖是一個有向圖
例如,如果我們有x + y = z,那麼
這對於評估算術表示式非常有用。我們可以通過尋找運算子圖中的 sinks來得到結果。 Sinks是諸如
對我們來說, 總是把值放在sources,值會傳播到Sinks。
反向模式求導
如果認為我的解釋不夠好,這裡有一些幻燈片。
求導是TensorFlow所需的許多模型的核心要求,因為需要它來執行 梯度下降演算法。每個高中畢業的人都知道什麼是求導; 它只是獲取函式的導數,如果函式是由基本函式組成的複雜組合,那麼就做 鏈式法則。
超級簡單的概述
如果有一個這樣的函式:
f(x,y) = x * y
那麼關於X的求導將產生:
關於Y的求導將產生:
另外一個例子:
這個導數是:
所以梯度就是:
鏈式法則,譬如應用於複雜的函式
5分鐘內反向模式
現在記住運算子圖的DAG結構,以及上一個例子中的鏈式法則。如果要評估,我們可以看到:
x -> h -> g -> f
作為圖表。會給出答案f。但是,我們也可以採取反向求解:
dx <- dh <- dg <- df
這看起來像鏈式法則!需要將導數相乘在一起,以獲得最終結果。
下圖是一個運算子圖的例子:
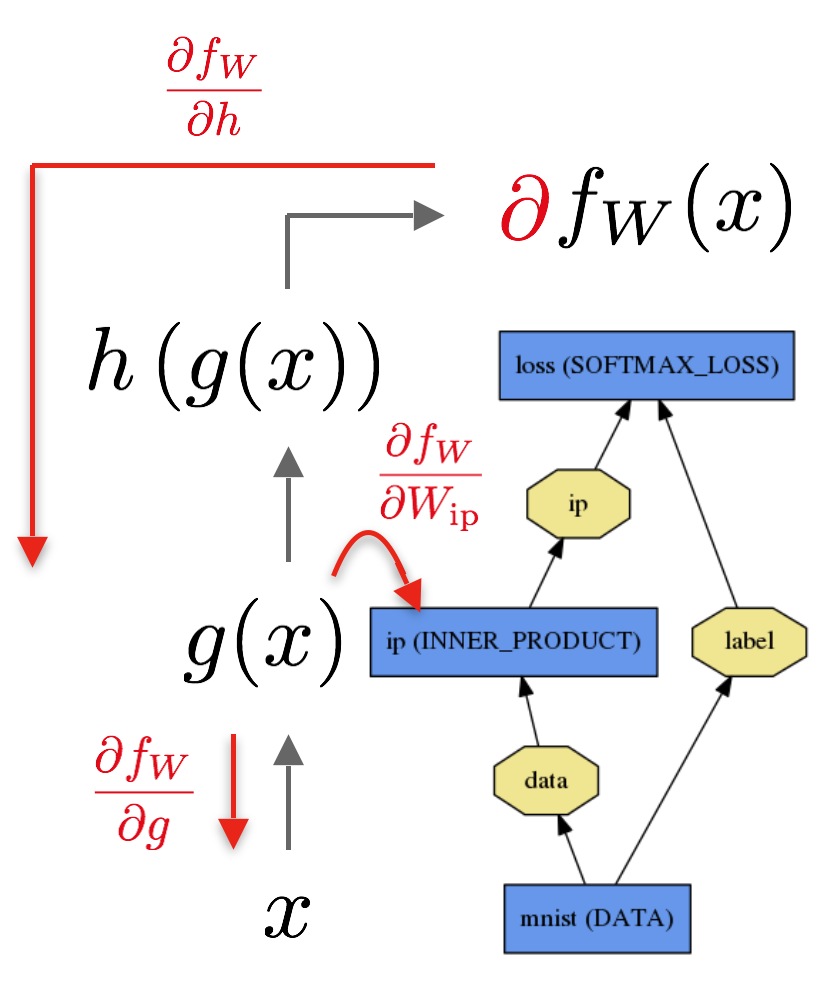
所以這基本上退化成圖遍歷問題。 有誰發覺拓撲排序和DFS / BFS嗎?
所以要支援雙向拓撲排序的話,需要包含一組父節點和一組子節點,Sinks是另一個方向的Sources, 反之亦然。
實施
在開學之前,Minh Le和我開始設計這個專案。我們決定使用Eigen 庫後臺進行線性代數運算。它們有一個稱為MatrixXd的矩陣類。我們在這裡使用它。
每個變數節點由var類表示:
class var {
// Forward declaration
struct impl;
public:
// For initialization of new vars by ptr
var(std::shared_ptr<impl>);
var(double);
var(const MatrixXd&);
var(op_type, const std::vector<var>&);
...
// Access/Modify the current node value
MatrixXd getValue() const;
void setValue(const MatrixXd&);
op_type getOp() const;
void setOp(op_type);
// Access internals (no modify)
std::vector<var>& getChildren() const;
std::vector<var> getParents() const;
...
private:
// PImpl idiom requires forward declaration of the class:
std::shared_ptr<impl> pimpl;
};
struct var::impl{
public:
impl(const MatrixXd&);
impl(op_type, const std::vector<var>&);
MatrixXd val;
op_type op;
std::vector<var> children;
std::vector<std::weak_ptr<impl>> parents;
};
在這裡,我們採用 pImpl慣用法,這意味著“通過指標來實現”。這在許多方面是非常好的,例如介面解耦實現, 當在堆疊上有一個本地shell介面時,允許在堆疊上例項化。pImpl的副作用是執行時間稍慢,但是編譯時間縮短了很多。這讓我們通過多個函式呼叫/返回來保持資料結構的永續性。像這樣的樹狀資料結構應該是持久的。
有幾個 列舉,告訴我們目前正在執行哪些操作:
enum class op_type {
plus,
minus,
multiply,
divide,
exponent,
log,
polynomial,
dot,
...
none // no operators. leaf.
};
執行該樹評價的實際類稱為expression:
class expression {
public:
expression(var);
...
// Recursively evaluates the tree.
double propagate();
...
// Computes the derivative for the entire graph.
// Performs a top-down evaluation of the tree.
void backpropagate(std::unordered_map<var, double>& leaves);
...
private:
var root;
};
在 反向傳播的內部,有一些類似於此的程式碼:
backpropagate(node, dprev):
derivative = differentiate(node)*dprev
for child in node.children:
backpropagate(child, derivative)
這相當於做一個DFS; 你看到了嗎?
為什麼選擇C ++?
事實上,C ++語言用於此不是特別合適。我們可以花 更少的時間用OCaml等功能性語言來開發。現在我明白了為什麼Scala被用於機器學習,主要看你喜歡;)。
然而,C ++有明顯的好處:
Eigen
例如,可以直接使用tensorflow的線性代數庫,稱之為Eigen。這是一個多模板惰性計算的線性代數庫。類似於表示式樹的樣子,構建表示式,只有在需要時才會對錶達式進行評估。然而,對於Eigen來說, 在編譯的時候就確定何時使用模板,這意味著執行時間的減少。我特別讚賞寫Eigen的人,因為審視模板的錯誤,讓我的眼睛充血。
Eigen的程式碼看起來像:
Matrix A(...), B(...);
auto lazy_multiply = A.dot(B);
typeid(lazy_multiply).name(); // the class name is something like Dot_Matrix_Matrix.
Matrix(lazy_multiply); // functional-style casting forces evaluation of this matrix.
Eigen庫是非常強大的,這就是為什麼它是tensorflow自我使用的主要後臺。這意味著除了這種惰性計算技術之外,還有其他方面的優化。
運算子過載
用Java開發這些庫會非常好—沒有shared_ptrs, unique_ptrs, weak_ptrs程式碼;我們可以採取 實際的,能勝任的,GC演算法。使用Java開發可以節省許多開發時間,更不用說執行速度也會變得更快。可是,Java不允許運算子過載,因而它們就不能這樣:
// These 3 lines code up an entire neural network!
var sigm1 = 1 / (1 + exp(-1 * dot(X, w1)));
var sigm2 = 1 / (1 + exp(-1 * dot(sigm1, w2)));
var loss = sum(-1 * (y * log(sigm2) + (1-y) * log(1-sigm2)));
順便說一下,上面的是實際程式碼。這不是很漂亮嗎?我認為 這比用於TensorFlow的python包裝更漂亮。只想讓你知道,這些也都是矩陣。
在Java語言中,這將是極其醜陋的,有著一堆add(), divide()…等等程式碼。更為重要的是, 使用者將被隱式強制使用PEMDAS(括號 ,指數、乘、除、加、減),這一點上,C++的運算子表現的很好。
效能,而不是Bug
有一些東西,你可以在這個庫中實際指定,TensorFlow沒有明確的API,或者我不知道。比如,如果想訓練某個特定子集的權重,可以只反向傳播到感興趣的具體來源。這對於卷積神經網路的 轉移學習非常有用,一些大的網路,如VGG19網路,很容易用TensorFlow實現,其附加的幾個額外的層的權重是根據新的域樣本進行訓練的。
基準
用Python的Tensorflow庫,在Iris資料集上對10000個歷史紀元進行分類訓練,這些歷史紀元具有相同的超引數,結果是:
- Tensorflow的神經網路
23812.5 ms - Scikit的神經網路庫:
22412.2 ms - Autodiff的神經網路,迭代,優化:
25397.2 ms - Autodiff的神經網路,具有迭代,無優化:
29052.4 ms - Autodiff的神經網路,具有遞迴,無優化:
28121.5 ms
如此看來,令人驚訝的是,Scikit在所有這些中執行最快。這可能是因為我們沒有做大量的矩陣乘法運算。也可能是因為tensorflown不得不通過變數初始化採用額外的編譯步驟。或者,也許可能不得不在python中執行迴圈,而不是在C語言中(python迴圈 真的很糟糕!)。我自己也不確定這到底是因為什麼。
我完全意識到這絕對不是一個全面的基準測試,因為它只適用於在特定情況下的單個資料點。不過,這個庫的效能並不是最先進的技術,因為我們不希望把自己捲進TensorFlow。
相關文章
- 如何用C++自己實現mysql資料庫的連線池?C++MySql資料庫
- 用Qt(C++)實現如蘋果般的亮屏效果QTC++蘋果
- 如何用 ANTLR 4 實現自己的指令碼語言?指令碼
- 如何用一天時間實現自己的RPC框架RPC框架
- 如何用C/C++實現去除字串頭和尾指定的字元C++字串字元
- 如何用C++在TensorFlow中訓練深度神經網路C++神經網路
- 實現自己的promisePromise
- 使用自己的資料集訓練MobileNet、ResNet實現影象分類(TensorFlow)
- 深度學習的TensorFlow實現深度學習
- 實現自己的http serverHTTPServer
- TensorFlow實現Batch NormalizationBATORM
- 自己實現AJAX
- 實現一個自己的mvvmMVVM
- DSSM模型和tensorflow實現SSM模型
- 如何用Python製作自己的遊戲Python遊戲
- 如何用Python建立自己的Dino Run?Python
- 如何用node開發自己的cli工具
- 如何用WordPress搭建自己的部落格(轉)
- 如何用iptables實現NAT(zt)
- 在 C/C++ 中使用 TensorFlow 預訓練好的模型—— 間接呼叫 Python 實現C++模型Python
- 在 C/C++ 中使用 TensorFlow 預訓練好的模型—— 直接呼叫 C++ 介面實現C++模型
- 如實實現不同資料庫之間的 (模型) Eloquent: 關聯資料庫模型
- 編譯 TensorFlow 的 C/C++ 介面編譯C++
- 自己實現一個java的arraylistJava
- 我該如何實現自己的理想
- TensorFlow實現seq2seq
- TensorFlow實現線性迴歸
- Flume 實現自己的實時日誌(2)
- LinkBlockedQueue的c++實現BloCC++
- 如何用Redis實現搜尋介面Redis
- 如何用 Redis 實現分散式鎖Redis分散式
- 如何用 UDP 實現可靠傳輸?UDP
- 如何用css實現"等高佈局"。CSS
- 如何用 Python 實現 Web 抓取?PythonWeb
- 利用tensorflow.js實現JS中的AIJSAI
- 如何用istio實現應用的灰度釋出
- 記錄自己在tensorflow中踩過的坑
- 自己動手實現OkHttpHTTP