論文提要 Deep Face Recognition
本文是關於深度人臉識別,British Machine Vision Conference, 2015
Visual Geometry Group Department of Engineering Science
University of Oxford
VGG網路提出的那幫傢伙
開原始碼 http://www.robots.ox.ac.uk/~vgg/software/vgg_face/
本文主要說了兩件事:
1)從零開始構建一個人臉識別資料庫,一共 2.6M images, over 2.6K people,構建過 程主要是程式實現的,少量人工參與。
2)通過對比各種CNN網路,提出了一個簡單有效的CNN網路,在各種公開的人臉識別資料庫上得到很好的效果。
首先來看看各種資料庫的比較:
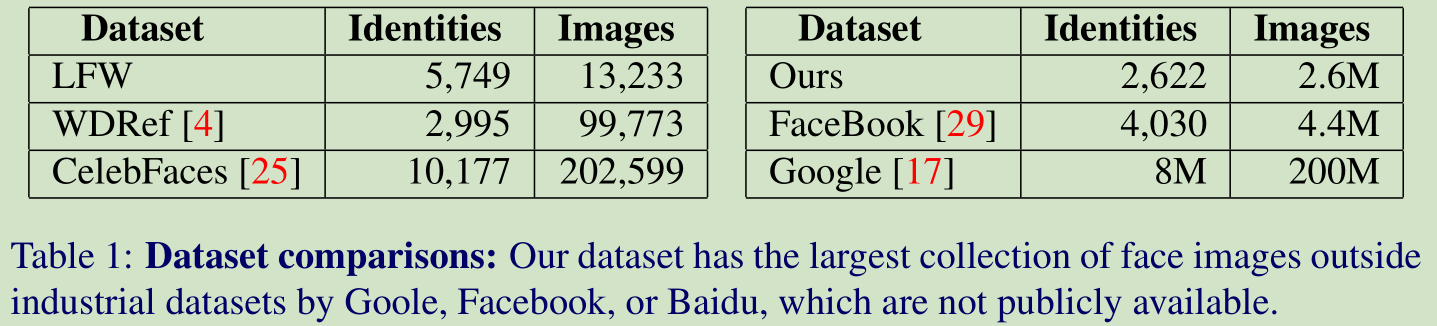
Google 的資料庫資料量最大,但是人家不是公開的。
下圖是我們資料庫裡的六個人的人臉照片

2 Related Work
人臉識別一開始大家都是基於 shallow 方法來解決, SIFT, LBP, HOG等。最近隨著CNN網路的優異表現,很多學者用CNN來做人臉識別, DeepFace,一系列DeepID, Facenet。
3 Dataset Collection
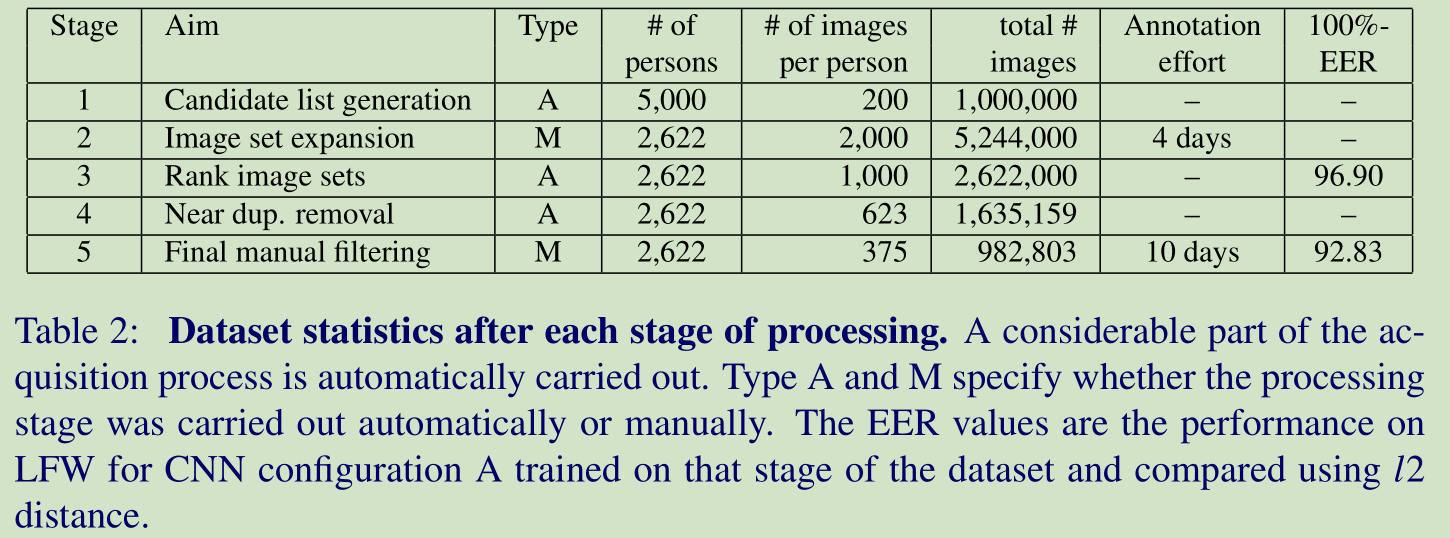
下面來說說我們的資料庫是怎麼構建的。
Stage 1. Bootstrapping and filtering a list of candidate identity names
Stage 2. Collecting more images for each identity
Stage 3. Improving purity with an automatic filter
Stage 4. Near duplicate removal
Stage 5. Final manual filtering
4 Network architecture and training
受文獻【19】的啟發,我們使用了 很深的網路
這裡我們將人臉識別看做分類問題,有多少個人臉就有多少個類。參考文獻【17】,我們使用 triplet loss 來訓練得到一個 face embedding,這可以提高效果。最小化triplet loss 如下:
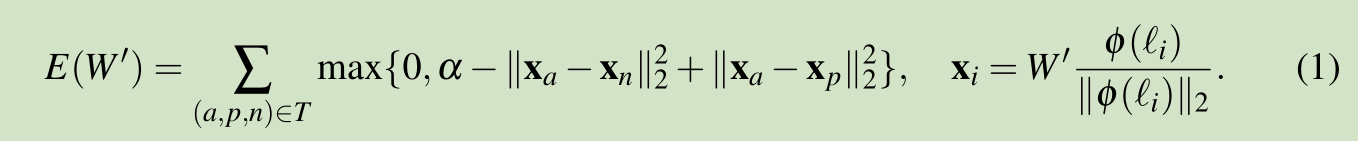
4.3 Architecture
這裡我們考慮了三個網路結構,A,B,D。 網路A 的結構如下:
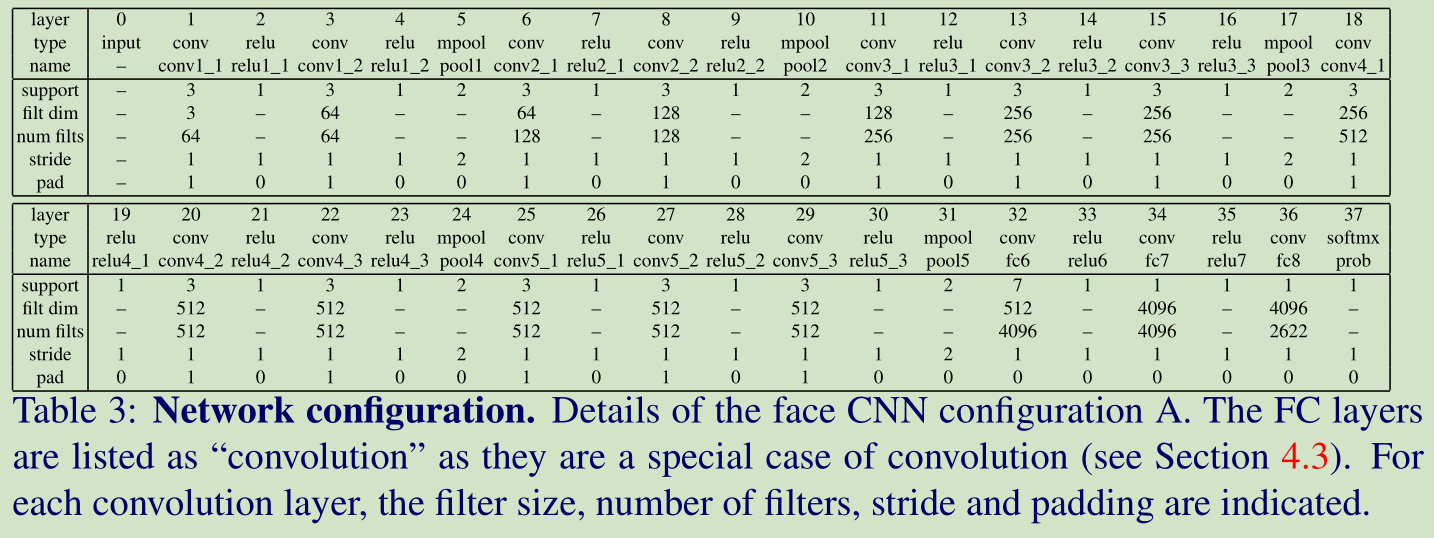
這裡我們將全連結層看做卷積層。網路B,D比網路A分別多了2個和5個卷積層。輸入的人臉影象大小是 224*224。
4.4 Training
這裡主要說了一下訓練時的一些引數設定。
5 Datasets and evaluation protocols
在兩個資料庫上進行了測試 :
Labeled Faces in the Wild dataset (LFW), YouTube Faces (YTF)
6 Experiments and results
硬體配置: NVIDIA Titan Black GPUs with 6GB of onboard memory, using
four GPUs together
不同網路結構效果如下:
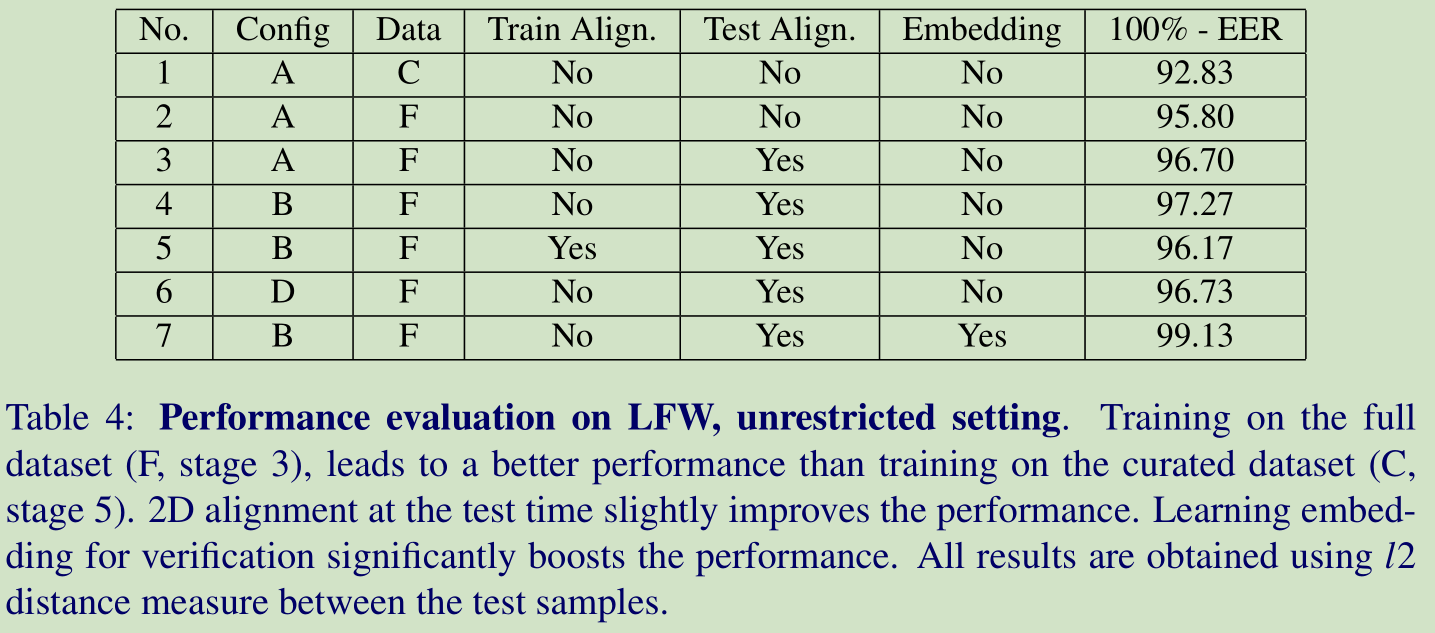
在LFW上和其他演算法的結果對比:
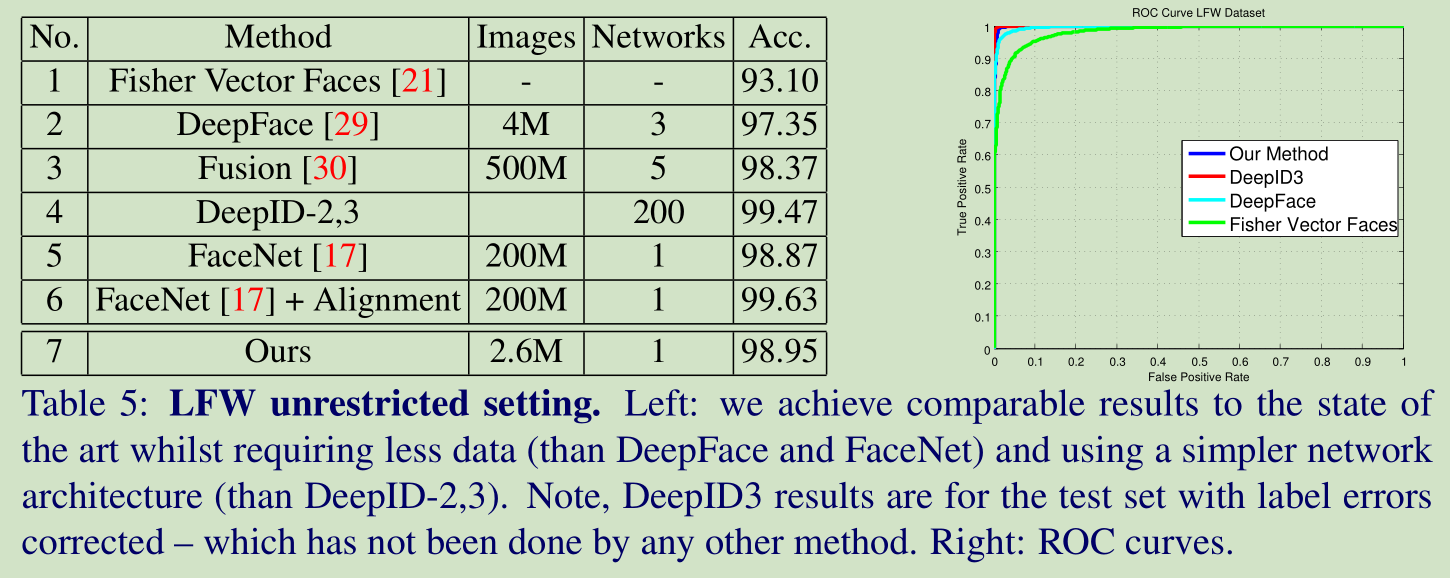
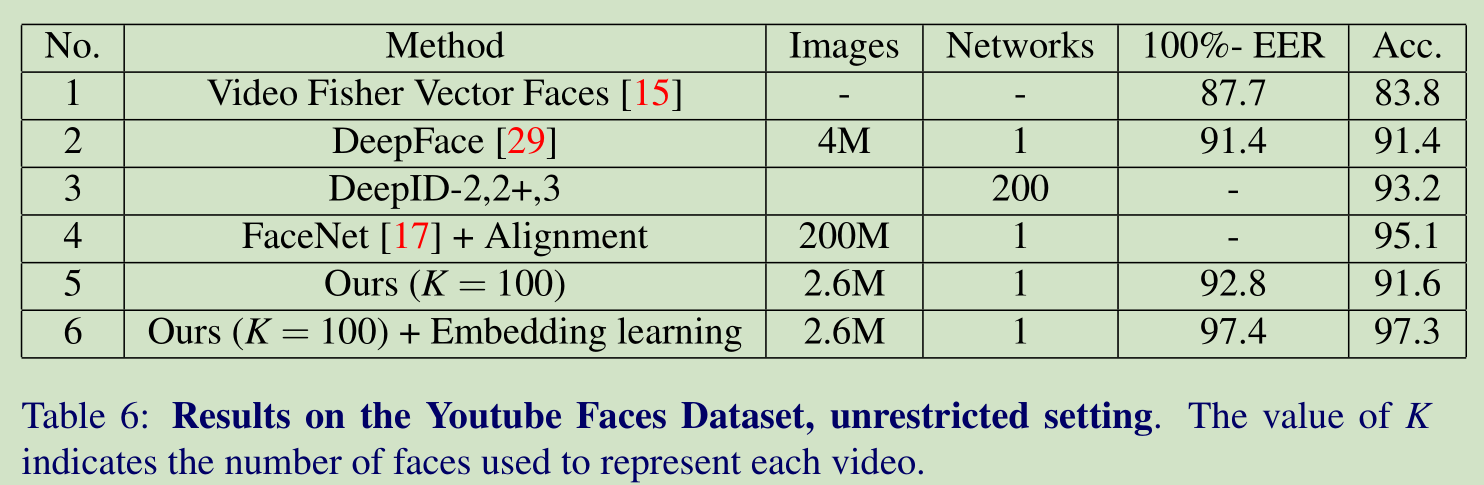
在 Youtube 上和其他演算法的結果對比:
6.1 Component analysis
Dataset curation: 在網路A上,資料淨化後的效果要差一下,可能原因有兩個:1)更多的有噪聲的資料會好些,2)可能是淨化後把一下較難的訓練資料去除了。
Alignment: 對測試影象進行 2D對齊是有幫助的,但是對訓練影象進行2D對齊沒有幫助
Architecture: 網路B的效果最好。可能的原因比較多。
Triplet-loss embedding: 這個對結果的改善還是挺大的。
相關文章
- 【論文筆記】A Survey on Deep Learning for Named Entity Recognition筆記
- 《A Discriminative Feature Learning Approach for Deep Face Recognition》閱讀筆記APP筆記
- [論文閱讀] VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
- face-recognition
- [論文][表情識別]Towards Semi-Supervised Deep Facial Expression Recognition with An Adaptive Confidence MarginExpressAPTIDE
- 深度學習論文翻譯解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition深度學習
- [論文閱讀] Residual Attention(Multi-Label Recognition)
- 論文解讀(DGI)《DEEP GRAPH INFOMAX》
- face_recognition的5個應用例項
- 論文解讀SDCN《Structural Deep Clustering Network》Struct
- 論文解讀(DFCN)《Deep Fusion Clustering Network》
- 論文解讀(SDNE)《Structural Deep Network Embedding》Struct
- Ranked List Loss for Deep Metric Learning | 論文分享
- 論文閱讀:End to End Chinese Lexical Fusion Recognition with Sememe Knowledge
- [論文閱讀] Temporal Extension Module for Skeleton-Based Action Recognition
- Reading Face, Read Health論文閱讀筆記筆記
- 論文翻譯五:A New Method of Automatic Modulation Recognition Based on Dimension Reduction
- 論文解讀(GRACE)《Deep Graph Contrastive Representation Learning》AST
- 論文解讀DEC《Unsupervised Deep Embedding for Clustering Analysis》
- [論文閱讀筆記] Structural Deep Network Embedding筆記Struct
- Hugging Face 論文平臺 Daily Papers 功能全解析Hugging FaceAI
- 【論文研讀】Recurrent convolutional strategies for face manipulation detection in videosIDE
- asp.net core 實現 face recognition 使用 tensorflowjs(原始碼)ASP.NETJS原始碼
- 論文解讀(GraphDA)《Data Augmentation for Deep Graph Learning: A Survey》
- 論文閱讀 TEMPORAL GRAPH NETWORKS FOR DEEP LEARNING ON DYNAMIC GRAPHS
- 論文閱讀:《Deep Compositional Question Answering with Neural Module Networks》
- Deep Unfolding Network for Image Super-Resolution 論文解讀
- 論文解讀(DCRN)《Deep Graph Clustering via Dual Correlation Reduction》
- 論文翻譯:2021_Performance optimizations on deep noise suppression modelsORM
- 論文解讀(DAEGC)《Improved Deep Embedded Clustering with Local Structure Preservation》GCStruct
- 論文解讀GCN 1st《 Deep Embedding for CUnsupervisedlustering Analysis》GC
- 論文解讀(IDEC)《Improved Deep Embedded Clustering with Local Structure Preservation》IDEStruct
- [論文解讀] DXSLAM: A Robust and Efficient Visual SLAM System with Deep FeaturesSLAM
- 論文筆記 Deep Patch Learning for Weakly Supervised Object Classication and Discovery筆記Object
- [論文翻譯][1809 09294]Object Detection from Scratch with Deep SupervisionObject
- 在win10上安裝face_recognition(人臉識別)Win10
- 論文閱讀:Borrowing wisdom from world: modeling rich external knowledge for Chinese named entity recognition
- 論文閱讀翻譯之Deep reinforcement learning from human preferences
- 論文閱讀《Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising》CNN