紅色石頭的個人網站:redstonewill.com
上節課我們介紹了過擬合發生的原因:excessive power, stochastic/deterministic noise 和limited data。並介紹瞭解決overfitting的簡單方法。本節課,我們將介紹解決overfitting的另一種非常重要的方法:Regularization規則化。
一、Regularized Hypothesis Set
先來看一個典型的overfitting的例子:
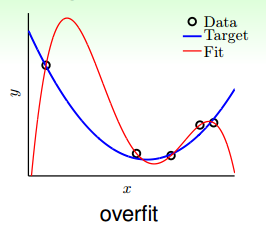
如圖所示,在資料量不夠大的情況下,如果我們使用一個高階多項式(圖中紅色曲線所示),例如10階,對目標函式(藍色曲線)進行擬合。擬合曲線波動很大,雖然Ein
E_{in}
很小,但是
EoutE_{out}
很大,也就造成了過擬合現象。
那麼如何對過擬合現象進行修正,使hypothesis更接近於target function呢?一種方法就是regularized fit。
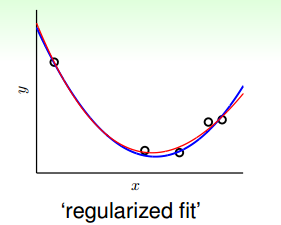
這種方法得到的紅色fit曲線,要比overfit的紅色曲線平滑很多,更接近與目標函式,它的階數要更低一些。那麼問題就變成了我們要把高階(10階)的hypothesis sets轉換為低階(2階)的hypothesis sets。通過下圖我們發現,不同階數的hypothesis存在如下包含關係:
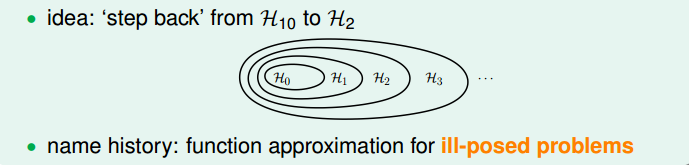
我們發現10階多項式hypothesis sets裡包含了2階多項式hypothesis sets的所有項,那麼在H10
H_{10}
中加入一些限定條件,使它近似為
H2H_2
即可。這種函式近似曾被稱之為不適定問題(ill-posed problem)。
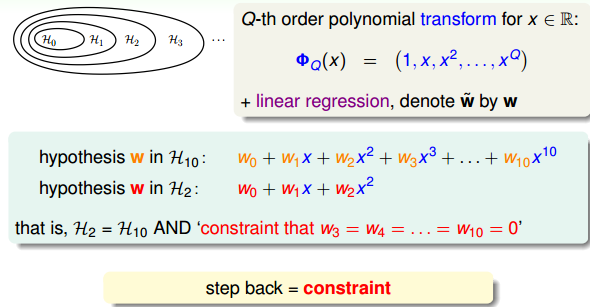
如何從10階轉換為2階呢?首先,H10
H_{10}
可表示為:
H10=w0+w1x+w2x2+w3x3+⋯+w10x10
H_{10}=w_0+w_1x+w_2x^2+w_3x^3+\cdots+w_{10}x^{10}
而H2
H_2
可表示為:
H2=w0+w1x+w2x2
H_2=w_0+w_1x+w_2x^2
所以,如果限定條件是w3=w4=⋯=w10=0
w_3=w_4=\cdots=w_{10}=0
,那麼就有
H2=H10H_2=H_{10}
。也就是說,對於高階的hypothesis,為了防止過擬合,我們可以將其高階部分的權重w限制為0,這樣,就相當於從高階的形式轉換為低階,fit波形更加平滑,不容易發生過擬合。
那有一個問題,令H10
H_{10}
高階權重w為0,為什麼不直接使用
H2H_2
呢?這樣做的目的是擴充我們的視野,為即將討論的問題做準備。剛剛我們討論的限制是
H10H_{10}
高階部分的權重w限制為0,這是比較苛刻的一種限制。下面,我們把這個限制條件變得更寬鬆一點,即令任意8個權重w為0,並不非要限定
w3=w4=⋯=w10=0w_3=w_4=\cdots=w_{10}=0
,這個Looser Constraint可以寫成:
∑q=010(wq≠0)≤3
\sum_{q=0}^{10}(w_q\neq0)\leq3
也就只是限定了w不為0的個數,並不限定必須是高階的w。這種hypothesis記為H′2
H_2'
,稱為sparse hypothesis set,它與
H2H_2
和
H10H_{10}
的關係為:
H2⊂H′2⊂H10
H_2\subset H_2'\subset H_{10}
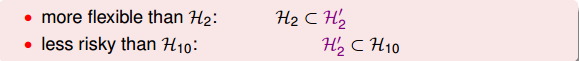
Looser Constraint對應的hypothesis應該更好解一些,但事實是sparse hypothesis set H′2
H_2'
被證明也是NP-hard,求解非常困難。所以,還要轉換為另一種易於求解的限定條件。
那麼,我們尋找一種更容易求解的寬鬆的限定條件Softer Constraint,即:
∑q=010w2q=||w||2≤C
\sum_{q=0}^{10}w_q^2=||w||^2\leq C
其中,C是常數,也就是說,所有的權重w的平方和的大小不超過C,我們把這種hypothesis sets記為H(C)
H(C)
。
H′2
H_2'
與
H(C)H(C)
的關係是,它們之間有重疊,有交集的部分,但是沒有完全包含的關係,也不一定相等。對應
H(C)H(C)
,C值越大,限定的範圍越大,即越寬鬆:
H(0)⊂H(1.126)⊂⋯⊂H(1126)⊂⋯⊂H(∞)=H10
H(0)\subset H(1.126)\subset \cdots \subset H(1126)\subset \cdots \subset H(\infty)=H_{10}
當C無限大的時候,即限定條件非常寬鬆,相當於沒有加上任何限制,就與H10
H_{10}
沒有什麼兩樣。
H(C)H(C)
稱為regularized hypothesis set,這種形式的限定條件是可以進行求解的,我們把求解的滿足限定條件的權重w記為
wREGw_{REG}
。接下來就要探討如何求解
wREGw_{REG}
。
二、Weight Decay Regularization
現在,針對H(c),即加上限定條件,我們的問題變成:
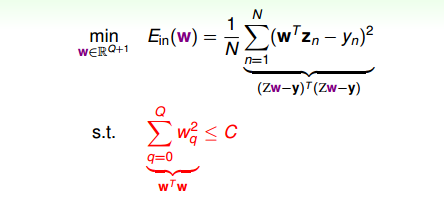
我們的目的是計算Ein(w)
E_{in}(w)
的最小值,限定條件是
||w2||≤C||w^2||\leq C
。這個限定條件從幾何角度上的意思是,權重w被限定在半徑為
C−−√\sqrt C
的圓內,而球外的w都不符合要求,即便它是靠近
Ein(w)E_{in}(w)
梯度為零的w。
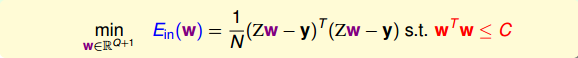
下面用一張圖來解釋在限定條件下,最小化Ein(w)
E_{in}(w)
的過程:

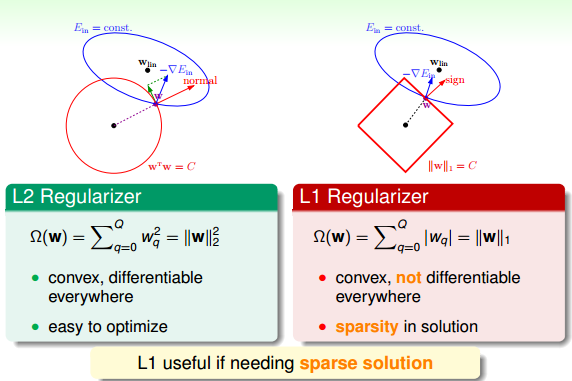
如上圖所示,假設在空間中的一點w,根據梯度下降演算法,w會朝著−∇Ein
-\nabla E_{in}
的方向移動(圖中藍色箭頭指示的方向),在沒有限定條件的情況下,w最終會取得最小值
wlinw_{lin}
,即“谷底”的位置。現在,加上限定條件,即w被限定在半徑為
C−−√\sqrt C
的圓內,w距離原點的距離不能超過圓的半徑,球如圖中紅色圓圈所示
wTw=Cw^Tw=C
。那麼,這種情況下,w不能到達
wlinw_{lin}
的位置,最大隻能位於圓上,沿著圓的切線方向移動(圖中綠色箭頭指示的方向)。與綠色向量垂直的向量(圖中紅色箭頭指示的方向)是圓切線的法向量,即w的方向,w不能靠近紅色箭頭方向移動。那麼隨著迭代優化過程,只要
−∇Ein-\nabla E_{in}
與w點切線方向不垂直,那麼根據向量知識,
−∇Ein-\nabla E_{in}
一定在w點切線方向上有不為零的分量,即w點會繼續移動。只有當
−∇Ein-\nabla E_{in}
與綠色切線垂直,即與紅色法向量平行的時候,
−∇Ein-\nabla E_{in}
在切線方向上沒有不為零的分量了,也就表示這時w達到了最優解的位置。
有了這個平行的概念,我們就得到了獲得最優解需要滿足的性質:
∇Ein(wREG)+2λNwREG=0
\nabla E_{in}(w_{REG})+\frac{2\lambda}{N}w_{REG}=0
上面公式中的λ
\lambda
稱為Lagrange multiplier,是用來解有條件的最佳化問題常用的數學工具,
2N\frac2N
是方便後面公式推導。那麼我們的目標就變成了求解滿足上面公式的
wREGw_{REG}
。
之前我們推導過,線性迴歸的Ein
E_{in}
的表示式為:
Ein=1N∑n=1N(xTnw−yn)2
E_{in}=\frac1N\sum_{n=1}^N(x_n^Tw-y_n)^2
計算Ein
E_{in}
梯度,並代入到平行條件中,得到:
2N(ZTZwREG−ZTy)+2λNwREG=0
\frac2N(Z^TZw_{REG}-Z^Ty)+\frac{2\lambda}Nw_{REG}=0
這是一個線性方程式,直接得到wREG
w_{REG}
為:
wREG=(ZTZ+λI)−1ZTy
w_{REG}=(Z^TZ+\lambda I)^{-1}Z^Ty
上式中包含了求逆矩陣的過程,因為ZTZ
Z^TZ
是半正定矩陣,如果
λ\lambda
大於零,那麼
ZTZ+λIZ^TZ+\lambda I
一定是正定矩陣,即一定可逆。另外提一下,統計學上把這叫做ridge regression,可以看成是linear regression的進階版。
如果對於更一般的情況,例如邏輯迴歸問題中,∇Ein
\nabla E_{in}
不是線性的,那麼將其代入平行條件中得到的就不是一個線性方程式,
wREGw_{REG}
不易求解。下面我們從另一個角度來看一下平行等式:
∇Ein(wREG)+2λNwREG=0
\nabla E_{in}(w_{REG})+\frac{2\lambda}{N}w_{REG}=0
已知∇Ein
\nabla E_{in}
是
EinE_{in}
對
wREGw_{REG}
的導數,而
2λNwREG\frac{2\lambda}{N}w_{REG}
也可以看成是
λNw2REG\frac{\lambda}Nw_{REG}^2
的導數。那麼平行等式左邊可以看成一個函式的導數,導數為零,即求該函式的最小值。也就是說,問題轉換為最小化該函式:
Eaug(w)=Ein(w)+λNwTw
E_{aug}(w)=E_{in}(w)+\frac{\lambda}Nw^Tw
該函式中第二項就是限定條件regularizer,也稱為weight-decay regularization。我們把這個函式稱為Augmented Error,即Eaug(w)
E_{aug}(w)
。
如果λ
\lambda
不為零,對應於加上了限定條件,若
λ\lambda
等於零,則對應於沒有任何限定條件,問題轉換成之前的最小化
Ein(w)E_{in}(w)
。
下面給出一個曲線擬合的例子,λ
\lambda
取不同的值時,得到的曲線也不相同:
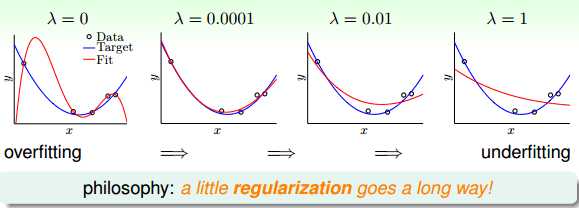
從圖中可以看出,當λ=0
\lambda=0
時,發生了過擬合;當
λ=0.0001\lambda=0.0001
時,擬合的效果很好;當
λ=0.01\lambda=0.01
和
λ=1\lambda=1
時,發生了欠擬合。我們可以把
λ\lambda
看成是一種penality,即對hypothesis複雜度的懲罰,
λ\lambda
越大,w就越小,對應於C值越小,即這種懲罰越大,擬合曲線就會越平滑,高階項就會削弱,容易發生欠擬合。
λ\lambda
一般取比較小的值就能達到良好的擬合效果,過大過小都有問題,但究竟取什麼值,要根據具體訓練資料和模型進行分析與除錯。

事實上,這種regularization不僅可以用在多項式的hypothesis中,還可以應用在logistic regression等其他hypothesis中,都可以達到防止過擬合的效果。
我們目前討論的多項式是形如x,x2,x3,⋯,xn
x,x^2,x^3,\cdots,x^n
的形式,若x的範圍限定在[-1,1]之間,那麼可能導致
xnx^n
相對於低階的值要小得多,則其對於的w非常大,相當於要給高階項設定很大的懲罰。為了避免出現這種資料大小差別很大的情況,可以使用Legendre Polynomials代替
x,x2,x3,⋯,xnx,x^2,x^3,\cdots,x^n
這種形式,Legendre Polynomials各項之間是正交的,用它進行多項式擬合的效果更好。關於Legendre Polynomials的概念這裡不詳細介紹,有興趣的童鞋可以看一下
維基百科。
三、Regularization and VC Theory
下面我們研究一下Regularization與VC理論之間的關係。Augmented Error表示式如下:
Eaug(w)=Ein(w)+λNwTw
E_{aug}(w)=E_{in}(w)+\frac{\lambda}Nw^Tw
VC Bound表示為:
Eout(w)≤Ein(w)+Ω(H)
E_{out}(w)\leq E_{in}(w)+\Omega(H)
其中wTw
w^Tw
表示的是單個hypothesis的複雜度,記為
Ω(w)\Omega(w)
;而
Ω(H)\Omega(H)
表示整個hypothesis set的複雜度。根據Augmented Error和VC Bound的表示式,
Ω(w)\Omega(w)
包含於
Ω(H)\Omega(H)
之內,所以,
Eaug(w)E_{aug}(w)
比
EinE_{in}
更接近於
EoutE_{out}
,即更好地代表
EoutE_{out}
,
Eaug(w)E_{aug}(w)
與
EoutE_{out}
之間的誤差更小。

根據VC Dimension理論,整個hypothesis set的dVC=d˘+1
d_{VC}=\breve d+1
,這是因為所有的w都考慮了,沒有任何限制條件。而引入限定條件的
dVC(H(C))=dEFF(H,A)d_{VC}(H(C))=d_{EFF}(H,A)
,即有效的VC dimension。也就是說,
dVC(H)d_{VC}(H)
比較大,因為它代表了整個hypothesis set,但是
dEFF(H,A)d_{EFF}(H,A)
比較小,因為由於regularized的影響,限定了w只取一小部分。其中A表示regularized演算法。當
λ>0\lambda>0
時,有:
dEFF(H,A)≤dVC
d_{EFF}(H,A)\leq d_{VC}
這些與實際情況是相符的,比如對多項式擬合模型,當λ=0
\lambda=0
時,所有的w都給予考慮,相應的
dVCd_{VC}
很大,容易發生過擬合。當
λ>0\lambda>0
且越來越大時,很多w將被捨棄,
dEFF(H,A)d_{EFF}(H,A)
減小,擬合曲線越來越平滑,容易發生欠擬合。
四、General Regularizers
那麼通用的Regularizers,即Ω(w)
\Omega(w)
,應該選擇什麼樣的形式呢?一般地,我們會朝著目標函式的方向進行選取。有三種方式:
target-dependent
plausible
friendly

其實這三種方法跟之前error measure類似,其也有三種方法:
user-dependent
plausible
friendly
regularizer與error measure是機器學習模型設計中的重要步驟。

接下來,介紹兩種Regularizer:L2和L1。L2 Regularizer一般比較通用,其形式如下:
Ω(w)=∑q=0Qw2q=||w||22
\Omega(w)=\sum_{q=0}^Qw_q^2=||w||_2^2
這種形式的regularizer計算的是w的平方和,是凸函式,比較平滑,易於微分,容易進行最優化計算。
L1 Regularizer的表示式如下:
Ω(w)=∑q=0Q|wq|=||w||1
\Omega(w)=\sum_{q=0}^Q|w_q|=||w||_1
L1計算的不是w的平方和,而是絕對值和,即長度和,也是凸函式。已知wTw=C
w^Tw=C
圍成的是圓形,而
||w||1=C||w||_1=C
圍成的是正方形,那麼在正方形的四個頂點處,是不可微分的(不像圓形,處處可微分)。根據之前介紹的平行等式推導過程,對應這種正方形,它的解大都位於四個頂點處(不太理解,歡迎補充賜教),因為正方形邊界處的w絕對值都不為零,若
−∇Ein-\nabla E_{in}
不與其平行,那麼w就會向頂點處移動,頂點處的許多w分量為零,所以,L1 Regularizer的解是稀疏的,稱為sparsity。優點是計算速度快。
下面來看一下λ
\lambda
如何取值,首先,若stochastic noise不同,那麼一般情況下,
λ\lambda
取值有如下特點:
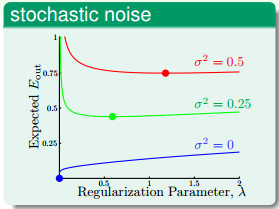
從圖中可以看出,stochastic noise越大,λ
\lambda
越大。
另一種情況,不同的deterministic noise,λ
\lambda
取值有如下特點:
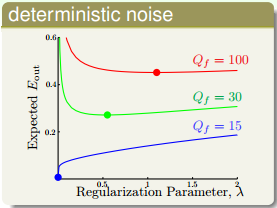
從圖中可以看出,deterministic noise越大,λ
\lambda
越大。
以上兩種noise的情況下,都是noise越大,相應的λ
\lambda
也就越大。這也很好理解,如果在開車的情況下,路況也不好,即noise越多,那麼就越會踩剎車,這裡踩剎車指的就是regularization。但是大多數情況下,noise是不可知的,這種情況下如何選擇
λ\lambda
?這部分內容,我們下節課將會討論。
五、總結
本節課主要介紹了Regularization。首先,原來的hypothesis set加上一些限制條件,就成了Regularized Hypothesis Set。加上限制條件之後,我們就可以把問題轉化為Eaug
E_{aug}
最小化問題,即把w的平方加進去。這種過程,實際上回降低VC Dimension。最後,介紹regularization是通用的機器學習工具,設計方法通常包括target-dependent,plausible,friendly等等。下節課將介紹如何選取合適的
λ\lambda
來建立最佳擬合模型。
註明:
文章中所有的圖片均來自臺灣大學林軒田《機器學習基石》課程
關注公眾號並輸入關鍵字“jspdf”獲得該筆記的pdf檔案哦~
更多AI資源請關注公眾號:紅色石頭的機器學習之路(ID:redstonewill)
