MapReduce:大型叢集上的簡單資料處理
摘要
MapReduce是一個設計模型,也是一個處理和產生海量資料的一個相關實現。使用者指定一個用於處理一個鍵值(key-value)對生成一組key/value對形式的中間結果的map函式,以及一個將中間結果鍵相同的鍵值對合併到一起的reduce函式。許多現實世界的任務都能滿足這個模型,如這篇文章所示。
使用這個功能形式實現的程式能夠在大量的普通機器上並行執行。這個執行程式的系統關心下面的這些細節:輸入資料的分割槽、一組機器上排程程式執行、處理機器失敗問題,以及管理所需的機器內部的通訊。這使沒有任何並行處理和分散式系統經驗的程式設計師能夠利用這個大型分散式系統的資源。
我們的MapReduce實現執行在一個由普通機器組成的大規模叢集上,具有很高的可擴充套件性:一個典型的MapReduce計算會在幾千臺機器上處理許多TB的資料。程式設計師們發現這個系統很容易使用:目前已經實現了幾百個MapReduce程式,在Google的叢集上,每天有超過一千個的MapReduce工作在執行。
一、 介紹
在過去的5年中,本文作者和許多Google的程式設計師已經實現了數百個特定用途的計算程式,處理了海量的原始資料,包括抓取到的文件、網頁請求日誌等,計算各種衍生出來的資料,如反向索引、網頁文件的圖形結構的各種表示、每個host下抓取到的頁面數量的總計、一個給定日期內的最頻繁查詢的集合等。大多數這種計算概念明確。然而,輸入資料通常都很大,並且計算必須分佈到數百或數千臺機器上以確保在一個合理的時間內完成。如何平行計算、分佈資料、處理錯誤等問題使這個起初很簡單的計算,由於增加了處理這些問題的很多程式碼而變得十分複雜。
為了解決這個複雜問題,我們設計了一個新的抽象模型,它允許我們將想要執行的計算簡單的表示出來,而隱藏其中平行計算、容錯、資料分佈和負載均衡等很麻煩的細節。我們的抽象概念是受最早出現在lisp和其它結構性語言中的map和reduce啟發的。我們認識到,大多數的計算包含對每個在輸入資料中的邏輯記錄執行一個map操作以獲取一組中間key/value對,然後對含有相同key的所有中間值執行一個reduce操作,以此適當的合併之前的衍生資料。由使用者指定map和reduce操作的功能模型允許我們能夠簡單的進行並行海量計算,並使用re-execution作為主要的容錯機制。
這項工作的最大貢獻是提供了一個簡單的、強大的介面,使我們能夠自動的進行並行和分散式的大規模計算,通過在由普通PC組成的大規模叢集上實現高效能的介面來進行合併。
第二章描述了基本的程式設計模型,並給出了幾個例子。第三章描述了一個為我們的聚類計算環境定製的MapReduce介面實現。第四章描述了我們發現對程式模型很有用的幾個優化。第六章探索了MapReduce在Google內部的使用,包括我們在將它作為生產索引系統重寫的基礎的一些經驗。第七章討論了相關的和未來的工作。
二、 程式設計模型
這個計算輸入一個key/value對集合,產生一組輸出key/value對。MapReduce庫的使用者通過兩個函式來標識這個計算:Map和Reduce。
Map,由使用者編寫,接收一個輸入對,產生一組中間key/value對。MapReduce庫將具有相同中間key I的聚合到一起,然後將它們傳送給Reduce函式。
Reduce,也是由使用者編寫的,接收中間key I和這個key的值的集合,將這些值合併起來,形成一個儘可能小的集合。通常,每個Reduce呼叫只產生0或1個輸出值。這些中間值經過一個迭代器(iterator)提供給使用者的reduce函式。這允許我們可以處理由於資料量過大而無法載入記憶體的值的連結串列。
2.1 例子
考慮一個海量檔案集中的每個單詞出現次數的問題,使用者會寫出類似於下面的偽碼:

Map函式對每個單詞增加一個相應的出現次數(在這個例子中僅僅為“1”)。Reduce函式將一個指定單詞所有的計數加到一起。
此外,使用者使用輸入和輸出檔案的名字、可選的調節引數編寫程式碼,來填充一個mapreduce規格物件,然後呼叫MapReduce函式,並把這個物件傳給它。使用者的程式碼與MapReduce庫(C++實現)連線到一起。。附錄A包含了這個例子的整個程式。
2.2 型別
儘管之前的虛擬碼中使用了字串格式的輸入和輸出,但是在概念上,使用者定義的map和reduce函式需要相關聯的型別:
map (k1, v1) --> list(k2, v2)
reduce (k2, list(v2)) --> list(v2)
也就是說,輸入的鍵和值和輸出的鍵和值來自不同的域。此外,中間結果的鍵和值與輸出的鍵和值有相同的域。
MapReduce的C++實現與使用者定義的函式使用字串型別進行引數傳遞,將型別轉換的工作留給使用者的程式碼來處理。
2.3 更多的例子
這裡有幾個簡單有趣的程式,能夠使用MapReduce計算簡單的表示出來。
分散式字串查詢(Distributed Grep):map函式將匹配一個模式的行找出來。Reduce函式是一個恆等函式,只是將中間值拷貝到輸出上。
URL訪問頻率計數(Count of URL Access Frequency):map函式處理web頁面請求的日誌,並輸出<URL, 1>。Reduce函式將相同URL的值累加到一起,生成一個<URL, total count>對。
翻轉網頁連線圖(Reverse Web-Link Graph):map函式為在一個名為source的頁面中指向目標(target)URL的每個連結輸出<target, source>對。Reduce函式將一個給定目標URL相關的所有源(source)URLs連線成一個連結串列,並生成對:<target, list(source)>。
主機關鍵向量指標(Term-Vector per Host):一個檢索詞向量將出現在一個文件或是一組文件中最重要的單詞概述為一個<word, frequency>對連結串列。Map函式為每個輸入文件產生一個<hostname, term vector>(hostname來自文件中的URL)。Reduce函式接收一個給定hostname的所有文件檢索詞向量,它將這些向量累加到一起,將罕見的向量丟掉,然後生成一個最終的<hostname, term vector>對。
倒排索引(Inverted Index):map函式解析每個文件,並生成一個<word, document ID>序列。Reduce函式接收一個給定單詞的所有鍵值對,所有的輸出對形成一個簡單的倒排索引。可以通過對計算的修改來保持對單詞位置的追蹤。
分散式排序(Distributed Sort):map函式將每個記錄的key抽取出來,並生成一個<key, record>對。Reduce函式不會改變任何的鍵值對。這個計算依賴了在4.1節提到的分割槽功能和4.2節提到的排序屬性。
三、 實現
MapReduce介面有很多不同的實現,需要根據環境來做出合適的選擇。比如,一個實現可能適用於一個小的共享記憶體機器,而另一個實現則適合一個大的NUMA多處理器機器,再另一個可能適合一個更大的網路機器集合。
這一章主要描述了針對在Google內部廣泛使用的計算環境的一個實現:通過交換乙太網將大量的普通PC連線到一起的叢集。在我們的環境中:
(1) 機器通常是雙核x86處理器、執行Linux作業系統、有2-4G的記憶體。
(2) 使用普通的網路硬體—通常是100Mb/s或者是1Gb/s的機器頻寬,但是平均值遠小於頻寬的一半。
(3) 由數百臺或者數千臺機器組成的叢集,因此機器故障是很平常的事
(4) 儲存是由直接裝在不同機器上的便宜的IDE磁碟提供。一個內部的分散式檔案系統用來管理儲存這些磁碟上的資料。檔案系統在不可靠的硬體上使用副本機制提供了可用性和可靠性。
(5) 使用者將工作提交給一個排程系統,每個工作由一個任務集組成,通過排程者對映到叢集中可用機器的集合上。
3.1 執行概述
通過自動的將輸入資料分割槽成M個分片,Map呼叫被分配到多臺機器上執行。資料的分片能夠在不同的機器上並行處理。使用分割槽函式(如,hash(key) mod R)將中間結果的key進行分割槽成R個分片,Reduce呼叫也被分配到多臺機器上執行。分割槽的數量(R)和分割槽函式是由使用者指定的。
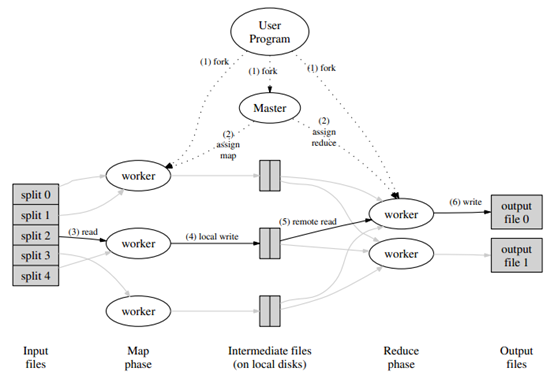
圖1:執行概述
圖1中顯示了我們實現的一個MapReduce操作的整個流程。當使用者程式呼叫MapReduce函式時,下面一系列的行為將會發生(圖1中所使用的數字標識將與下面列表中的相對應):
1. 使用者程式中的MapReduce庫會先將輸入檔案分割成M個通常為16MB-64MB大小的片(使用者可以通過可選引數進行控制)。然後它將在一個叢集的機器上啟動許多程式的拷貝。
2. 這些程式拷貝中的一個是比較特殊的——master。其它的拷貝都是工作程式,是由master來分配工作的。有M個map任務和R個reduce任務被分配。Master挑選出空閒的工作程式,並把一個map任務或reduce任務分配到這個程式上。
3. 一個分配了map任務的工作程式讀取相關輸入分片的內容,它將從輸入資料中解析出key/value對,並將其傳遞給使用者定義的Map函式。Map函式生成的中間key/value對快取在記憶體中。
4. 快取中的鍵值對週期性的寫入到本地磁碟,並通過分割槽函式分割為R個區域。將這些快取在磁碟上的鍵值對的位置資訊傳回給master,master負責將這些位置資訊傳輸給reduce工作程式。
5. 當一個reduce工作程式接收到master關於位置資訊的通知時,它將使用遠端呼叫函式(RPC)從map工作程式的磁碟上讀取快取的資料。當reduce工作程式讀取完所有的中間資料後,它將所有的中間資料按中間key進行排序,以保證相同key的資料聚合在一起。這個排序是需要的,因為通常許多不同的key對映到相同的reduce任務上。如果中間資料的總量太大而無法載入到記憶體中,則需要進行外部排序。
6. reduce工作程式迭代的訪問已排序的中間資料,並且對遇到的每個不同的中間key,它會將key和相關的中間values傳遞給使用者的Reduce函式。Reduce函式的輸出追加到當前reduce分割槽一個最終的輸出檔案上。
7. 當所有的map任務和reduce任務完成後,master會喚醒使用者程式。這時候,使用者程式中的MapReduce呼叫會返回到使用者程式碼上。
在成功完成後,MapReduce操作輸出到R個輸出檔案(每個reduce任務生成一個,檔名是由使用者指定的)中的結果是有效的。通常,使用者不需要合併這R個輸出檔案,它們經常會將這些檔案作為輸入傳遞給另一個MapReduce呼叫,或者在另一個處理這些輸入分割槽成多個檔案的分散式應用中使用。
3.2 Master資料結構
Master保留了幾個資料結構。對於每個Map和Reduce任務,它儲存了它們的狀態(idle、in-progress或者completed),以及工作程式機器的特性(對於非空閒任務)。
Master是中間檔案區域的位置資訊從map任務傳送到reduce任務的一個通道。因此,對於每個完成的map任務來說,master儲存了map任務產生的R箇中間檔案區域的位置資訊和大小。在map任務完成時,master會接收到更新這個含有位置資訊和大小資訊的訊息。資訊被增量的傳輸到執行in-progress的reduce任務的工作程式上。
3.3 容錯
因為MapReduce庫是被設計成執行在數百或數千臺機器上幫助處理海量資料的,所以這個庫必須能夠優雅的處理機器故障。
工作程式故障
Master週期性的ping每個工作程式,如果在一個特定的時間內沒有收到響應,則master會將這個工作程式標記為失效。任何由失效的工作程式完成的map任務都被標記為初始idle狀態,因此這個map任務會被重新分配給其它的工作程式。同樣的,任何正在處理的map任務或reduce任務也會被置為idle狀態,進而可以被重新排程。
在一個失效的節點上完成的map任務會被重新執行,因為它們的輸出被存放在失效機器的本地磁碟上,而磁碟不可訪問。完成的reduce任務不需要重新執行,因為它們的輸出被儲存在全域性檔案系統上。
當一個map任務先被工作程式A執行,然後再被工作程式B執行(因為A失效了),所有執行reduce任務的工作程式都會接收到重新執行的通知,任何沒有從工作程式A上讀取資料的reduce任務將會從工作程式B上讀取資料。
MapReduce對於大規模工作程式失效有足夠的彈性。比如,在一個MapReduce操作處理過程中,網路維護造成了80臺機器組成的叢集幾分鐘內不可達。MapReduce的master會重新執行那些在不可達機器上完成的工作,並持續推進,最終完成MapReduce操作。
Master故障
將上面提到的master資料結構週期性的進行寫檢查點操作(checkpoint)是比較容易的。如果master任務死掉,一個新的拷貝會從最近的檢查點狀態上啟動。然而,假定只有一個單獨的master,它的故障是不大可能的。因此,如果master故障,我們當前的實現是中止MapReduce計算。
當前故障的語義
當使用者提供的map和reduce操作是輸入確定性函式,我們的分散式實現與無故障序列執行整個程式所生成的結果相同。
我們依靠map和reduce任務輸出的原子性提交來實現這個屬性。每個in-progress任務將它們的輸出寫入到一個私有的臨時檔案中。一個reduce任務產生一個這樣的檔案,一個map任務產生R個這樣的檔案(每個reduce任務一個)。當一個map任務完成時,它將傳送給master一個訊息,其中包括R個臨時檔案的名字。如果master收到一個已經完成的map任務的完成訊息,則忽略這個訊息。否則,它將這R個檔名記錄在master的資料結構中。
當一個reduce任務完成後,reduce的工作程式自動的將臨時檔案更名為最終的輸出檔案,如果相同的reduce任務執行在多臺機器上,會呼叫多個重新命名操作將這些檔案更名為最終的輸出檔案。
絕大部分的map和reduce操作是確定性的,事實上,在這種情況下我們的語義與一個序列化的執行是相同的,這使程式開發者能夠簡單的推出他們程式的行為。當map和/或reduce操作是不確定性的時,我們提供較弱但依然合理的語義。在不確定性的操作面前,一個特定的reduce任務R1的輸出與一個序列執行的不確定性程式生成的輸出相同。然而,一個不同的reduce任務R2的輸出可能與一個不同的序列執行的不確定性程式生成的輸出可能一致。
考慮map任務M和reduce任務R1和R2。假定e(Ri)是提交的Ri的執行過程(有且僅有這樣一個過程)。e(R1)可能從M的一個執行生成的輸出中讀取資料,e(R2)可能從M的一個不同執行生成的輸出中讀取資料,則會產生較弱的語義。
3.4 位置
在我們的計算環境中,網路頻寬是一個相對不足的資源。我們通過將輸入資料存放在組成叢集的機器的本地磁碟來節省網路頻寬。GFS將每個檔案分割成64MB大小的塊,每個塊會在不同的機器上儲存幾個拷貝(通常為3個)。MapReduce master會考慮檔案的位置資訊,並試圖將一個map任務分配到包含相關輸入資料副本的機器上。如果這樣做失敗,它會試圖將map任務排程到一個包含任務輸入資料的臨近的機器上(例如,與包含輸入資料機器在同一個網路下進行互動的一個工作程式)。當在叢集的一個有效部分上執行大規模的MapReduce操作時,大多數輸入資料都從本地讀取,不消耗任何網路頻寬。
3.5 任務粒度
根據上面所提到的,我們將map階段細分為M個片,將reduce階段細分為R個片。理想情況下,M和R應該比工作機器的數量大得多,每個工作程式執行很多不同的任務來促使負載均衡,在一個工作程式失效時也能夠快速的恢復:許多完成的map任務可以傳播到其它所有的工作機器上。
在我們的實現中,對於取多大的M和R有一個實際的界限,因為如上面提到的那樣,master必須進行O(M+R)次排程,在記憶體中保持O(M*R)個狀態。(對記憶體使用的恆定因素影響較小,然而:對由每個map任務/reduce任務對佔用大約一個位元組所組成的O(M*R)片的狀態影響較大。)
此外,R經常是由使用者約束的,因為每個reduce任務的輸出最終放在一個分開的輸出檔案中。實際中,我們傾向選擇M值,以使每一個獨立的任務能夠處理大約16MB到64MB的輸入資料(可以使上面提到的位置優化有更好的效果),把R值設定為我們想使用的工作機器的一個小的倍數。我們經常使用2000個工作機器,設定M=200000和R=5000,來執行MapReduce計算。
3.6 備用任務
影響一個MapReduce操作整體執行時間的一個通常因素是“落後者”:一個使用了異常的時間完成了計算中最後幾個map任務或reduce任務中的一個的機器。可能有很多因素導致落後者的出現,例如,一個含有損壞磁碟的機器頻繁的處理可校正的錯誤,使它的讀取速度從30MB/s下降到了1MB/s。叢集排程者可能將其它的任務分配到這個機器上,由於CPU、記憶體、磁碟或網路頻寬的競爭會導致MapReduce程式碼執行的更慢。我們遇到的最近一個問題是機器初始化程式碼中的一個bug,它會使處理器的快取不可用:受到這個問題影響的機器會慢上百倍。
我們使用一個普通的機制來緩解落後者問題。當一個MapReduce操作接近完成時,master排程備用(backup)任務執行剩下的、處於in-process狀態的任務。一旦主任務或是備用任務完成,則將這個任務標識為已經完成。我們優化了這個機制,使它通常能夠僅僅增加少量的操作所使用的計算資源。我們發現這能有效的減少完成大規模MapReduce操作所需要的時間。作為一個例子,5.3節所描述的那種程式在禁用備用任務機制的情況下,會需要多消耗44%的時間。
四、 細化
儘管簡單的編寫Map和Reduce函式提供的基本功能足夠滿足大多數需要,但是,我們發現一些擴充套件是很有用的。這會在本章進行描述。
4.1 分割槽函式
MapReduce的使用者指定所希望的reduce任務/輸出檔案的數量(R)。使用分割槽函式在中間鍵上將資料分割槽到這些任務上。一個預設的分割槽函式使用hash方法(如“hash(key) mod R”),它能產生相當平衡的分割槽。然而,在一些情況下,需要使用其它的在key上的分割槽函式對資料進行分割槽。為了支援這種情況,MapReduce庫的使用者能夠提供指定的分割槽函式。例如,使用“hash(Hostname(urlkey)) mod R”作為分割槽函式,使所有來自同一個host的URL最終放到同一個輸出檔案中。
4.2 順序保證
我們保證在一個給定的分割槽內,中間key/value對是根據key值順序增量處理的。順序保證可以使它易於生成一個有序的輸出檔案,這對於輸出檔案需要支援有效的隨機訪問,或者輸出的使用者方便的查詢排序的資料很有幫助。
4.3 組合(Combiner)函式
在一些情況下,每個map任務產生的中間key會有很多重複,並且使用者指定的reduce函式滿足結合律和交換律。2.1節中提到的單詞技術的例子就是一個很好的例子。因為單詞頻率傾向於zifp分佈,每個map任務都會產生數百或數千個<the, 1>形式的記錄。所有這些計數都會通過網路傳送給一個單獨的reduce任務,然後通過Reduce函式進行累加併產生一個數字。我們允許使用者指定一個可選的Combiner函式,它能在資料通過網路傳送前先對這些資料進行區域性合併。
Combiner函式在每臺執行map任務的機器上執行。通常情況下,combiner函式和reduce函式的程式碼是相同的,兩者唯一不同的是MapReduce庫如何處理函式的輸出。Reduce函式的輸出被寫入到一個最終的輸出檔案中,而combiner函式會寫入到一個將被髮送給reduce函式的中間檔案中。
區域性合併可以有效的對某類MapReduce操作進行加速。附錄A包含了一個使用combiner函式的例子。
4.4 輸入和輸出型別
MapReduce庫支援幾種不同格式的輸入資料。比如,“text”模式的輸入可以講每一行看出一個key/value對:key是該行在檔案中的偏移量,value是該行的內容。另一中常見的支援格式是根據key進行排序儲存一個key/value對的序列。每種輸入型別的實現知道如何將自己分割成對map任務處理有意義的區間(例如,text模式區間分割確保區間分割只在行的邊界進行)。使用者能夠通過實現一個簡單的讀取(reader)介面來增加支援一種新的輸入型別,儘管大多數使用者僅僅使用了預定義輸入型別中的一小部分。
Reader並不是必須從檔案中讀取資料,比如,我們可以容易的定義一個從資料庫中讀取記錄,或者從記憶體的資料結構中讀取資料的Reader。
類似的,我們提供一組輸出型別來產生不同格式的資料,使用者也可以簡單的通過程式碼增加對新輸出型別的支援。
4.5 副作用
在一些情況下,MapReduce的使用者發現為它們的map和/或reduce操作的輸出生成輔助的檔案很方便。我們依靠應用的writer將這個副作用變成原子的和冪等的。通常,應用會將結果寫入到一個臨時檔案,然後在資料完全生成後,原子的重新命名這個檔案。
如果一個單獨任務產生的多個輸出檔案,我們沒有提供兩階段提交的原子操作。因此,產生多個輸出檔案且對交叉檔案有一致性需求的任務應該是確定性的操作。但是在實際工作中,這個限制並不是一個問題。
4.6 跳過損壞的記錄
有時,在我們的程式碼中會存在一些bug,它們會導致Map或Reduce函式在處理特定的記錄上一定會Crash。這樣的bug會阻止MapReduce操作順利完成。通常的做法是解決這個bug,但有時,這是不可行的;可能是由於第三方的庫中的bug,而我們沒有這個庫的原始碼。有時,忽略一些記錄也是可以接受的,例如,當在海量的資料集上做資料統計時。我們提供了一個可選的執行模式,MapReduce庫探測出哪些記錄會導致確定性的Crash,並跳過這些記錄以繼續執行這個程式。
每個工作程式都安裝了一個訊號處理器,它能捕獲段錯誤和匯流排錯誤。在呼叫使用者的Map或Reduce操作之前,MapReduce庫將記錄的序號儲存到全域性變數中。如果使用者程式碼產生一個訊號,這個訊號處理器會向MapReudce master傳送一個“臨死前”的UDP包,其中包含了這個序號。當master看到對於一個特定的記錄有多個失敗訊號時,在相應的Map或Reduce任務下一次重新執行時,master會通知它跳過這個記錄。
4.7 本地執行
在Map或Reduce函式中除錯問題是很棘手的,因為實際的計算是發生在一個分散式系統上的,通常有幾千臺機器,並且是由master動態分配的。為了有助於除錯、效能分析和小規模測試,我們開發了一個MapReduce庫可供選擇的實現,它將在本地機器上序列化的執行一個MapReduce的所有工作。這為使用者提供了對MapReduce操作的控制,使計算能被限制在一個特定的map任務上。使用者使用標記呼叫他們的程式,並能夠簡單的使用它們找到的任何除錯或測試工具(如,gdb)。
4.8 狀態資訊
Master執行了一個內部的HTTP服務,並顯示出狀態集頁面供人們檢視,如,有多少任務已經完成、有多少正在處理、輸入的位元組數、中間資料的位元組數、輸出的位元組數、處理速率等。這些頁面也包含了指向每個任務生成的標準錯誤和標準輸出檔案的連結。使用者能使用這些資料預測這個計算將要持續多長時間,以及是否應該向這個計算新增更多的資源。這些頁面也有助於找出計算比預期執行慢的多的原因。
此外,頂層的狀態頁顯示了哪些工作程式失效,哪些map和reduce任務在處理時失敗。這個資訊對試圖診斷出使用者程式碼中的bug很有用。
4.9 計數器
MapReduce庫提供了一個計數器,用於統計不同事件的發生次數。比如,使用者程式碼想要統計已經處理了多少單詞,或者已經對多少德國的文件建立了索引等。
使用者程式碼可以使用這個計數器建立一個命名的計數器物件,然後在Map和/或Reduce函式中適當的增加這個計數器的計數。例如:

獨立的工作機器的計數器值週期性的傳送到master(附在ping的響應上)master將從成功的map和reduce任務上獲取的計數器值進行彙總,當MapReduce操作完成時,將它們返回給使用者的程式碼。當前的計數器值也被顯示在了master的狀態頁面上,使人們能夠看到當前計算的進度。當彙總計數器值時,master通過去掉同一個map或reduce任務的多次執行所造成的影響來防止重複計數。(重複執行可能會在我們使用備用任務和重新執行失敗的任務時出現。)
一些計數器的值是由MapReduce庫自動維護的,如已處理的輸入key/value對的數量和已生成的輸出key/value對的數量。
使用者發現計數器對檢查MapReduce操作的行為很有用處。例如,在一些MapReduce操作中,使用者程式碼可能想要確保生成的輸出對的數量是否精確的等於已處理的輸入對的數量,或者已處理的德國的文件數量在已處理的所有文件數量中是否被容忍。
五、 效能
在這章中,我們測試兩個執行在一個大規模叢集上的MapReduce計算的效能。一個計算在大約1TB的資料中進行特定的模式匹配,另一個計算對大約1TB的資料進行排序。
這兩個程式能夠代表實際中大量的由使用者編寫的MapReduce程式,一類程式將資料從一種表示方式轉換成另一種形式;另一類程式是從海里的資料集中抽取一小部分感興趣的資料。
5.1 叢集配置
所有的程式執行在一個由將近1800臺機器組成的叢集上。每個機器有兩個2GHz、支援超執行緒的Intel Xeon處理器、4GB的記憶體、兩個160GB的IDE磁碟和一個1Gbps的乙太網鏈路,這些機器部署在一個兩層的樹狀交換網路中,在根節點處有大約100-200Gbps的頻寬。所有的機器都採用相同的部署,因此任意兩個機器間的RTT都小於1ms。
在4GB記憶體裡,有接近1-1.5GB用於執行在叢集上的其它任務。程式在一個週末的下午開始執行,這時主機的CPU、磁碟和網路基本都是空閒的。
5.2 字串查詢(Grep)
這個grep程式掃描了大概1010個100位元組大小的記錄,查詢出現概率相對較小的3個字元的模式(這個模式出現在92337個記錄中)。輸入被分割成接近64MB的片(M=15000),整個輸出被放到一個檔案中(R=1)。

圖2:資料傳輸速率
圖2顯示了計算隨時間的進展情況。Y軸顯示了輸入資料的掃描速率,這個速率會隨著MapReduce計算的機器數量的增長而增長,當1764個工作程式參與計算時,總的速率超過30GB/s。隨著map任務的完成,速率開始下降,並在計算的大約第80秒變為0,整個計算從開始到結束大約持續了150秒,這包含了大約1分鐘的啟動時間開銷,這個開銷是由將程式傳播到所有工作機器的時間、等待GFS檔案系統開啟1000個輸入檔案集的時間和獲取位置優化所需資訊的時間造成的。
5.3 排序
排序程式對1010個100位元組大小的記錄(接近1TB的資料)進行排序,這個程式模仿了TeraSort benchmark。
排序程式由不到50行的使用者程式碼組成,一個三行的Map函式從一個文字行中抽取出一個10位元組的key,並將這個key和原始的文字行作為中間的key/value對進行輸出。我們使用內建的Identity函式作為Reduce操作。這個函式將中間key/value對不做任何修改的輸出,最終排序結果輸出到兩路複製的GFS檔案中(如,該程式輸出了2TB的資料)。
如前所述,輸入資料被分割為64MB大小的片(M=15000),將輸出結果分成4000個檔案(R=4000)。分割槽函式使用了key的開頭字元將資料分隔到R片中的一個。
這個基準測試的分割槽函式內建了key的分割槽資訊。在一個普通的排序程式中,我們將增加一個預處理MapReduce操作,它能夠對key進行抽樣,通過key的抽樣分佈來計算最終排序處理的分割點。
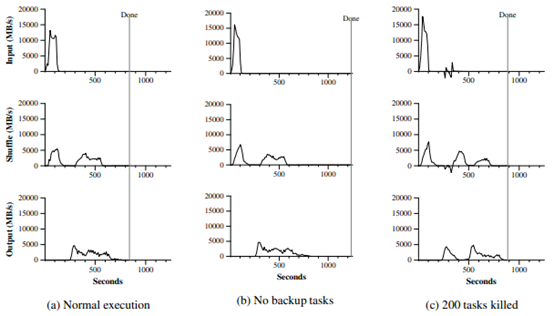
圖3:對於排序程式的不同執行過程隨時間的資料傳輸速率
圖3(a)顯示了排序程式的正常執行過程。左上方的圖顯示了輸入讀取的速率,這個速率峰值大約為13GB/s,因為所有的map任務執行完成,速率也在200秒前下降到了0。注意,這裡的輸入速率比字串查詢的要小,這是因為排序程式的map任務花費了大約一半的處理時間和I/O頻寬將終結結果輸出到它們的本地磁碟上,字串查詢相應的中間結果輸出幾乎可以忽略。
左邊中間的圖顯示了資料通過網路從map任務發往reduce任務的速率。這個緩慢的資料移動在第一個map任務完成時會盡快開始。圖中的第一個峰值是啟動了第一批大概1700個reduce任務(整個MapReduce被分配到大約1700臺機器上,每個機器每次最多隻執行一個reduce任務)。這個計算執行大概300秒後,第一批reduce任務中的一些執行完成,我們開始執行剩下的reduce任務進行資料處理。所有的處理在計算開始後的大約600秒後完成。
左邊下方的圖顯示了reduce任務就愛那個排序後的資料寫到最終的輸出檔案的速率。在第一個處理週期完成到寫入週期開始間有一個延遲,因為機器正在忙於對中間資料進行排序。寫入的速率會在2-4GB/s上持續一段時間。所有的寫操作會在計算開始後的大約850秒後完成。包括啟動的開銷,整個計算耗時891秒,這與TeraSort benchmark中的最好記錄1057秒相似。
一些事情需要注意:因為我們的位置優化策略,大多數資料從本地磁碟中讀取,繞開了網路頻寬的顯示,所以輸入速率比處理速率和輸出速率要高。處理速率要高於輸出速率,因為輸出過程要將排序後的資料寫入到兩個拷貝中(為了可靠性和可用性,我們將資料寫入到兩個副本中)。我們將資料寫入兩個副本,因為我們的底層檔案系統為了可靠性和可用性提供了相應的機制。如果底層檔案系統使用容錯編碼(erasure coding)而不是複製,寫資料的網路頻寬需求會降低。
5.4 備用任務的作用
在圖3(b)中,我們顯示了一個禁用備用任務的排序程式的執行過程。執行的流程與如3(a)中所顯示的相似,除了有一個很長的尾巴,在這期間幾乎沒有寫入行為發生。在960秒後,除了5個reduce任務的所有任務都執行完成。然而,這些落後者只到300秒後才執行完成。整個計算任務耗時1283秒,增加了大約44%的時間。
5.5 機器故障
在圖3(c)中,我們顯示了一個排序程式的執行過程,在計算過程開始都的幾分鐘後,我們故意kill掉了1746個工作程式中的200個。底層的排程者會迅速在這些機器上重啟新的工作程式(因為只有程式被殺掉,機器本身執行正常)。
工作程式死掉會出現負的輸入速率,因為一些之前已經完成的map工作消失了(因為香港的map工作程式被kill掉了),並且需要重新執行。這個map任務會相當快的重新執行。整個計算過程在933秒後完成,包括了啟動開銷(僅僅比普通情況多花費了5%的時間)。
六、 經驗
我們在2003年2月完成了MapReduce庫的第一個版本,並在2003年8月做了重大的改進,包括位置優化、任務在工作機器上的動態負載均衡執行等。從那時起,我們驚喜的發現,MapReduce庫能夠廣泛的用於我們工作中的各種問題。它已經被用於Google內部廣泛的領域,包括:
- 大規模機器學習問題
- Google新聞和Froogle產品的叢集問題
- 抽取資料用於公眾查詢的產品報告
- 從大量新應用和新產品的網頁中抽取特性(如,從大量的位置查詢頁面中抽取地理位置資訊)
- 大規模圖形計算
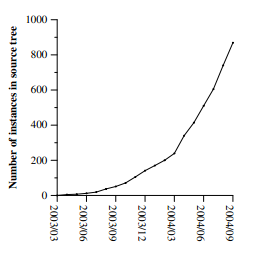
圖4:隨時間變化的MapReduce例項
圖4中顯示了在我們的原始碼管理系統中,隨著時間的推移,MapReduce程式的數量有明顯的增加,從2003年早期的0增加到2004年9月時的900個獨立的例項。MapReduce如此的成功,因為它使利用半個小時編寫的一個簡單程式能夠高效的執行在一千臺機器上成為可能,這極大的加快了開發和原型設計的週期。此外,它允許沒有分散式和/或並行系統經驗的開發者能夠利用這些資源開發出分散式應用。

表1: 2004年8月執行的MapReduce任務
在每個工作的最後,MapReduce庫統計了工作使用的計算資源。在表1中,我們看到一些2004年8月在Google內部執行的MapReduce工作的一些統計資料。
6.1 大規模索引
目前為止,MapReduce最重要的應用之一就是完成了對生產索引系統的重寫,它生成了用於Google網頁搜尋服務的資料結構。索引系統的輸入資料是通過我們的爬取系統檢索到的海量文件,儲存為就一個GFS檔案集合。這些檔案的原始內容還有超過20TB的資料。索引程式是一個包含了5-10個MapReduce操作的序列。使用MapReduce(代替了之前版本的索引系統中的adhoc分散式處理)有幾個優點:
- 索引程式程式碼是一個簡單、短小、易於理解的程式碼,因為容錯、分散式和並行處理都隱藏在了MapReduce庫中。比如,一個計算程式的大小由接近3800行的C++程式碼減少到使用MapReduce的大約700行的程式碼。
- MapReduce庫效能非常好,以至於能夠將概念上不相關的計算分開,來代替將這些計算混合在一起進行,避免額外的資料處理。這會使索引程式易於改變。比如,對之前的索引系統做一個改動大概需要幾個月時間,而對新的系統則只需要幾天時間。
- 索引程式變得更易於操作,因為大多數由於機器故障、機器處理速度慢和網路的瞬間阻塞等引起的問題都被MapReduce庫自動的處理掉,而無需人為的介入。
七、 相關工作
許多系統都提供了有限的程式模型,並且對自動的平行計算使用了限制。比如,一個結合函式可以在logN時間內在N個處理器上對一個包含N個元素的陣列使用並行字首計算,來獲取所有的字首[6,9,13]。MapReduce被認為是這些模型中基於我們對大規模工作計算的經驗的簡化和精華。更為重要的是,我們提供了一個在數千個處理器上的容錯實現。相反的,大多數並行處理系統只在較小規模下實現,並將機器故障的處理細節交給了程式開發者。
Bulk Synchronous Programming和一些MPI源於提供了更高層次的抽象使它更易於讓開發者編寫並行程式。這些系統和MapReduce的一個關鍵不同點是MapReduce開發了一個有限的程式模型來自動的並行執行使用者的程式,並提供了透明的容錯機制。
我們的位置優化機制的靈感來自於移動磁碟技術,計算用於處理靠近本地磁碟的資料,減少資料在I/O子系統或網路上傳輸的次數。我們的系統執行在掛載幾個磁碟的普通機器上,而不是在磁碟處理器上執行,但是一般方法是類似的。
我們的備用任務機制與Charlotte系統中採用的eager排程機制類似。簡單的Eager排程機制有一個缺點,如果一個給定的任務造成反覆的失敗,整個計算將以失敗告終。我們通過跳過損壞計算路的機制,解決了這個問題的一些情況。
MapReduce實現依賴了內部叢集管理系統,它負責在一個大規模的共享機器集合中分發和執行使用者的任務。儘管不是本篇文章的焦點,但是叢集管理系統在本質上與像Condor的其它系統類似。
排序功能是MapReduce庫的一部分,與NOW-Sort中的操作類似。源機器(map工作程式)將將要排序的資料分割槽,並將其傳送給R個Reduce工作程式中的一個。每個reduce工作程式在本地對這些資料進行排序(如果可能的話就在記憶體中進行)。當然NOW-Sort沒有使MapReduce庫能夠廣泛使用的使用者定義的Map和Reduce函式。
River提供了一個程式設計模型,處理程式通過在分散式佇列上傳送資料來進行通訊。像MapReduce一樣,即使在不均勻的硬體或系統顛簸的情況下,River系統依然試圖提供較好的平均效能。River系統通過小心的磁碟和網路傳輸排程來平衡完成時間。通過限制程式設計模型,MapReduce框架能夠將問題分解成很多細顆粒的任務,這些任務在可用的工作程式上動態的排程,以至於越快的工作程式處理越多的任務。這個受限制的程式設計模型也允許我們在工作將要結束時排程冗餘的任務進行處理,這樣可以減少不均勻情況下的完成時間。
BAD-FS與MapReduce有完全不同的程式設計模型,不像MapReduce,它是用於在廣域網下執行工作的。然而,它們有兩個基本相似點。(1)兩個系統都使用了重新執行的方式來處理因故障而丟失的資料。(2)兩個系統都本地有限排程原則來減少網路鏈路上傳送資料的次數。
TASCC是一個用於簡化結構的高可用性的網路服務。像MapReduce一樣,它依靠重新執行作為一個容錯機制。
八、 總結
MapReduce程式設計模型已經成功的應用在Google內部的許多不同的產品上。我們將這個成功歸功於幾個原因。第一,模型很易用,即使對那些沒有平行計算和分散式系統經驗的開發者,因為它隱藏了並行處理、容錯、本地優化和負載均衡這些處理過程。第二,各種各樣的問題都能用MapReduce計算簡單的表示出來,例如,MapReduce被Google網頁搜尋服務用於生成資料、排序、資料探勘、機器學習和許多其它系統。第三,我們已經實現了擴充套件到由數千臺機器組成的大規模叢集上使用的MapReduce。這個實現能夠有效的利用這些機器自由,因此適合在Google內部遇到的很多海量計算問題。
我們從這項工作中學到了幾樣東西。第一,限制程式模型使得平行計算和分散式計算變得容易,也容易實現這樣的計算容錯。第二,網路頻寬是一個稀有的資源,因此我們系統中的很多優化的目標都是為了減少資料在網路上的傳輸次數:位置優化允許我們從本地磁碟讀取資料,並將中間資料的一個拷貝寫入到本地磁碟,以此來節省網路頻寬的使用。第三,冗餘執行能夠用於減少允許速度慢的機器所造成的影響,並且能夠處理機器故障和資料丟失。