OpenCL之矩陣乘法實現
kernel
在opencl中,一般最優價值的就是kernel,前面寫的配置檔案基本沒有很大的差別,主要是kernel寫法上。其中矩陣運算又是最能體現opencl價值的地方。先上寫的kernel:
__kernel void matrix_mult(
const int Ndim,
const int Mdim,
const int Pdim,
__global const float* A,
__global const float* B,
__global float* C)
{
int i = get_global_id(0);
int j = get_global_id(1);
int k;
float tmp;
if ((i < Ndim) && (j < Mdim)) {
tmp = 0.0;
for (k = 0; k < Pdim; k++)
tmp += A[i*Pdim + k] * B[k*Mdim + j];
C[i*Mdim + j] = tmp;
}
}上面的配置檔案看起來簡單其實已經包含了兩方面的並行,首先是裡面的乘法,這裡是對所有的乘法可以進行並行。如果是M×P,P×N的矩陣,那麼最多可以進行:M×N×P次乘法,如果沒有超過GPU裡面流媒體的處理器個數的話那麼就可以同時執行,否者也只能滿負荷執行。接著計算完這個之後就是加法的並行操作。用if是防止越界。
配置
在這裡要特別說明的就是我們在傳資料給從機的時候我們是傳的一維陣列,再通過傳矩陣的維度來還原回二維陣列。
配置檔案的說明可以參考我之前的部落格:請點選!
直接貼程式碼:
#include <CL/cl.h>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <iostream>
#include <fstream>
using namespace std;
#define NWITEMS 6
#pragma comment (lib,"OpenCL.lib")
//把文字檔案讀入一個 string 中
int convertToString(const char *filename, std::string& s)
{
size_t size;
char* str;
std::fstream f(filename, (std::fstream::in | std::fstream::binary));
if (f.is_open())
{
size_t fileSize;
f.seekg(0, std::fstream::end);
size = fileSize = (size_t)f.tellg();
f.seekg(0, std::fstream::beg);
str = new char[size + 1];
if (!str)
{
f.close();
return NULL;
}
f.read(str, fileSize);
f.close();
str[size] = '\0';
s = str;
delete[] str;
return 0;
}
printf("Error: Failed to open file %s\n", filename);
return 1;
}
int main()
{
cl_uint status;
cl_platform_id platform;
//建立平臺物件
status = clGetPlatformIDs(1, &platform, NULL);
cl_device_id device;
//建立 GPU 裝置
clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU,
1,
&device,
NULL);
//建立context
cl_context context = clCreateContext(NULL,
1,
&device,
NULL, NULL, NULL);
//建立命令佇列
cl_command_queue commandQueue = clCreateCommandQueue(context,
device,
CL_QUEUE_PROFILING_ENABLE, NULL);
if (commandQueue == NULL)
perror("Failed to create commandQueue for device 0.");
//建立要傳入從機的資料
/******** 建立核心和記憶體物件 ********/
const int Ndim = 20;
const int Mdim = 20;
const int Pdim = 20;
int szA = Ndim * Pdim;
int szB = Pdim * Mdim;
int szC = Ndim * Mdim;
float *A;
float *B;
float *C;
A = (float *)malloc(szA * sizeof(float));
B = (float *)malloc(szB * sizeof(float));
C = (float *)malloc(szC * sizeof(float));
int i, j;
for (i = 0; i < szA; i++)
A[i] = (float)((float)i + 1.0);
for (i = 0; i < szB; i++)
B[i] = (float)((float)i + 1.0);
//建立三個 OpenCL 記憶體物件,並把buf1 的內容通過隱式拷貝的方式
//拷貝到clbuf1, buf2 的內容通過顯示拷貝的方式拷貝到clbuf2
cl_mem memObjects[3] = { 0, 0, 0 };
memObjects[0] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(float)* szA, A, NULL);
memObjects[1] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,
sizeof(float)* szB, B, NULL);
memObjects[2] = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR,
sizeof(float)* szC, C, NULL);
if (memObjects[0] == NULL || memObjects[1] == NULL ||memObjects[2] == NULL)
perror("Error in clCreateBuffer.\n");
const char * filename = "Vadd.cl";
std::string sourceStr;
status = convertToString(filename, sourceStr);
if (status)
cout << status << " !!!!!!!!" << endl;
const char * source = sourceStr.c_str();
size_t sourceSize[] = { strlen(source) };
//建立程式物件
cl_program program = clCreateProgramWithSource(
context,
1,
&source,
sourceSize,
NULL);
//編譯程式物件
status = clBuildProgram(program, 1, &device, NULL, NULL, NULL);
if (status)
cout << status << " !!!!!!!!" <<endl;
if (status != 0)
{
printf("clBuild failed:%d\n", status);
char tbuf[0x10000];
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, 0x10000, tbuf,
NULL);
printf("\n%s\n", tbuf);
//return −1;
}
//建立 Kernel 物件
cl_kernel kernel = clCreateKernel(program, "matrix_mult", NULL);
//設定 Kernel 引數
cl_int clnum = NWITEMS;
status = clSetKernelArg(kernel, 0, sizeof(int), &Ndim);
status = clSetKernelArg(kernel, 1, sizeof(int), &Mdim);
status = clSetKernelArg(kernel, 2, sizeof(int), &Pdim);
status = clSetKernelArg(kernel, 3, sizeof(cl_mem), &memObjects[0]);
status = clSetKernelArg(kernel, 4, sizeof(cl_mem), &memObjects[1]);
status = clSetKernelArg(kernel, 5, sizeof(cl_mem), &memObjects[2]);
if (status)
cout << "引數設定錯誤" << endl;
//執行 kernel
size_t global[2];
cl_event prof_event;
cl_ulong ev_start_time = (cl_ulong)0;
cl_ulong ev_end_time = (cl_ulong)0;
double rum_time;
global[0] = (size_t)Ndim;
global[1] = (size_t)Mdim;
status = clEnqueueNDRangeKernel(commandQueue, kernel, 2, NULL,
global, NULL, 0, NULL, &prof_event);
if (status)
cout << "執行核心時錯誤" << endl;
clFinish(commandQueue);
//讀取時間
status = clGetEventProfilingInfo(prof_event,CL_PROFILING_COMMAND_QUEUED,
sizeof(cl_ulong),&ev_start_time,NULL);
status = clGetEventProfilingInfo(prof_event,CL_PROFILING_COMMAND_END,
sizeof(cl_ulong),&ev_end_time,NULL);
if (status)
perror("讀取時間的時候發生錯誤\n");
rum_time = (double)(ev_end_time - ev_start_time);
cout << "執行時間為:" << rum_time << endl;
//資料拷回 host 記憶體
status = clEnqueueReadBuffer(commandQueue, memObjects[2],CL_TRUE, 0,
sizeof(float)* szC, C,0, NULL, NULL);
if (status)
perror("讀回資料的時候發生錯誤\n");
//結果顯示
printf("\nArray A:\n");
for (i = 0; i < Ndim; i++) {
for (j = 0; j < Pdim; j++)
printf("%.3f\t", A[i*Pdim + j]);
printf("\n");
}
printf("\nArray B:\n");
for (i = 0; i < Pdim; i++) {
for (j = 0; j < Mdim; j++)
printf("%.3f\t", B[i*Mdim + j]);
printf("\n");
}
printf("\nArray C:\n");
for (i = 0; i < Ndim; i++) {
for (j = 0; j < Mdim; j++)
printf("%.3f\t", C[i*Mdim + j]);
printf("\n");
}
cout << endl;
if (A)
free(A);
if (B)
free(B);
if (C)
free(C);
//刪除 OpenCL 資源物件
clReleaseMemObject(memObjects[2]);
clReleaseMemObject(memObjects[1]);
clReleaseMemObject(memObjects[0]);
clReleaseProgram(program);
clReleaseCommandQueue(commandQueue);
clReleaseContext(context);
system("pause");
return 0;
}效果
我演示一個4×5與5×6的矩陣的乘法:
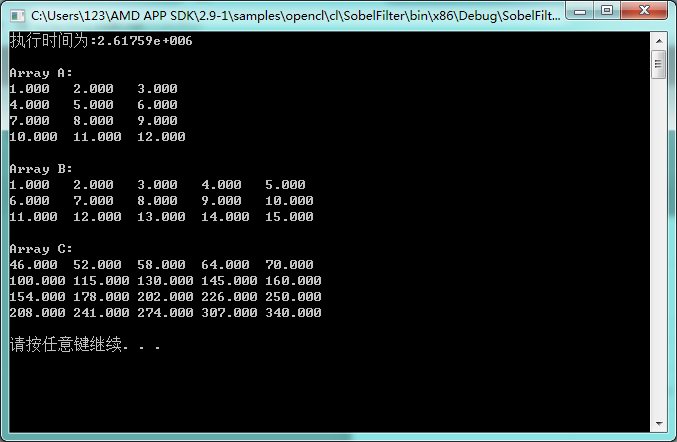
請點選:參考文件
另外可以免積分下載AMD OpenCL教程:點選進入下載
相關文章
- 矩陣乘法矩陣
- 理解矩陣乘法矩陣
- MKL庫矩陣乘法矩陣
- cuda 加速矩陣乘法矩陣
- 【矩陣乘法】Matrix Power Series矩陣
- #100. 矩陣乘法矩陣
- 【矩陣乘法】【快速冪】遞推矩陣
- POJ 3613 Cow Relays 矩陣乘法Floyd+矩陣快速冪矩陣
- CUDA 矩陣乘法終極優化指南矩陣優化
- 斐波那契數列Ⅳ【矩陣乘法】矩陣
- torch中向量、矩陣乘法大總結矩陣
- [轉]如何理解矩陣乘法的規則矩陣
- bzoj3240: [Noi2013]矩陣遊戲(矩陣乘法+快速冪)矩陣遊戲
- 怎樣用python計算矩陣乘法?Python矩陣
- 計算機演算法:Strassen矩陣乘法計算機演算法矩陣
- 讀取大型稀疏矩陣&KNN演算法的OpenCL加速版本矩陣KNN演算法
- 04 矩陣乘法與線性變換複合矩陣
- BASIC-17 / Tsinsen 1041 矩陣乘法(java)矩陣Java
- 矩陣乘法的運算量計算(華為OJ)矩陣
- C++實現蛇形矩陣C++矩陣
- Hadoop 2.6 使用Map Reduce實現矩陣相乘1 矩陣轉置Hadoop矩陣
- 想學人工智慧,先從理解矩陣乘法開始人工智慧矩陣
- bzoj4547: Hdu5171 小奇的集合(矩陣乘法)矩陣
- UOJ 241. 【UR #16】破壞發射臺 [矩陣乘法]矩陣
- MPI矩陣向量乘法程式碼《並行程式設計導論》矩陣並行行程程式設計
- 線性代數 - 矩陣形式下的最小二乘法矩陣
- bzoj4887: [Tjoi2017]可樂(矩陣乘法+快速冪)矩陣
- C語言實現矩陣螺旋輸出C語言矩陣
- 灰度共生矩陣GLCM及其matlab實現矩陣Matlab
- 矩陣的乘法運算與css的3d變換(transform)矩陣CSS3DORM
- POJ3070 Fibonacci[矩陣乘法]【學習筆記】矩陣筆記
- 【線性變換/矩陣及乘法】- 圖解線性代數 03矩陣圖解
- 脈動陣列在二維矩陣乘法及卷積運算中的應用陣列矩陣卷積
- 生成螺旋矩陣(方陣、矩陣)矩陣
- 資料結構之陣列和矩陣--矩陣&不規則二維陣列資料結構陣列矩陣
- verilog實現矩陣卷積運算矩陣卷積
- 【矩陣基礎與維度分析】【公式細節推導】矩陣非線性最小二乘法泰勒展開矩陣公式
- 資料結構實驗 二維矩陣的實現資料結構矩陣