魅族C++協程框架(Kiev)技術內幕
Kiev框架簡介
kiev是魅族科技推送平臺目前使用的Linux-C++後臺開發框架。從2012年立項起,先後由多位魅族資深架構師、資深C++工程師傾力打造,到本文寫就的時間為止,已經在推送平臺這個千萬使用者級的大型分散式系統上經歷了近5年的考驗。如今Kiev在魅族推送平臺中,每天為上百個服務完成數百億次RPC呼叫。
kiev作為一套完整的開發框架,是專為大型分散式系統後臺打造的C++開發框架,由以下幾個元件組成:
- RPC框架(TCP/UDP)
- FastCGI框架
- redis客戶端(基於hiredis封裝)
- mysql客戶端(基於mysqlclient封裝)
- mongodb客戶端
- 配置中心客戶端(Http協議, 基於curl實現)
- 基於zookeeper的分散式元件(服務發現、負載均衡)
- 日誌模組
- 狀態監控模組
- 核心模組是一個開源的`CSP併發模型`協程庫(libgo)
併發模型
Kiev採用了很先進的CSP開發模型的一個變種(golang就是這種模型),這一模型是繼承自libgo的。 選擇這種模型的主要原因是這種模型的開發效率遠高於非同步回撥模型,同時不需要在效能上做出任何妥協,在文中會對常見的幾種模型做詳細的對比。
CSP模型
CSP(Communicating Sequential Process)模型是一種目前非常流行的併發模型,golang語言所採用的併發模型就是CSP模型。 在CSP模型中,協程與協程間不直接通訊,也不像Actor模型那樣直接向目標協程投遞資訊,而是通過一個Channel來交換資料。
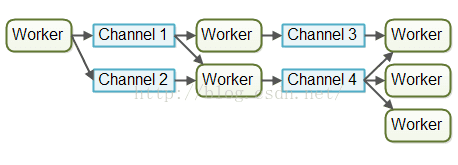
這樣設計的好處是通過Channel這個中間層減少協程間互動的耦合性,同時又保證了靈活性,非常適合開發併發程式。
RPC框架
RPC(Remote Procedure Call)是一種遠端呼叫協議,簡單地說就是能使應用像呼叫本地方法一樣的呼叫遠端的過程或服務,可以應用在分散式服務、分散式計算、遠端服務呼叫等許多場景。說起 RPC 大家並不陌生,業界有很多開源的優秀 RPC 框架,例如 Dubbo、Thrift、gRPC、Hprose 等等。 RPC框架的出現是為了簡化後臺內部各服務間的網路通訊,讓開發人員可以專注於業務邏輯,而不必與複雜的網路通訊打交道。 在我們看來,RPC框架絕不僅僅是封裝一下網路通訊就可以了的,要想應對數以百計的不同服務、數千萬使用者、百億級PV的業務量挑戰,RPC框架還必須在高可用、負載均衡、過載保護、通訊協議向後相容、優雅降級、超時處理、無序啟動幾個維度都做到足夠完善才行。
服務發現
Kiev使用zookeeper做服務發現,每個kiev服務開放時會在zookeeper上註冊一個節點,包含地址和協議資訊。水平擴充套件時,同質化服務會註冊到同一個路徑下,產生多個節點。 依賴的服務呼叫時,從zookeeper上查詢當前有哪些節點可以使用,依照負載均衡的策略擇一連線並呼叫。
負載均衡
內建兩種負載均衡策略:robin和conhash,並且根據實際業務場景可以定製。
過載保護
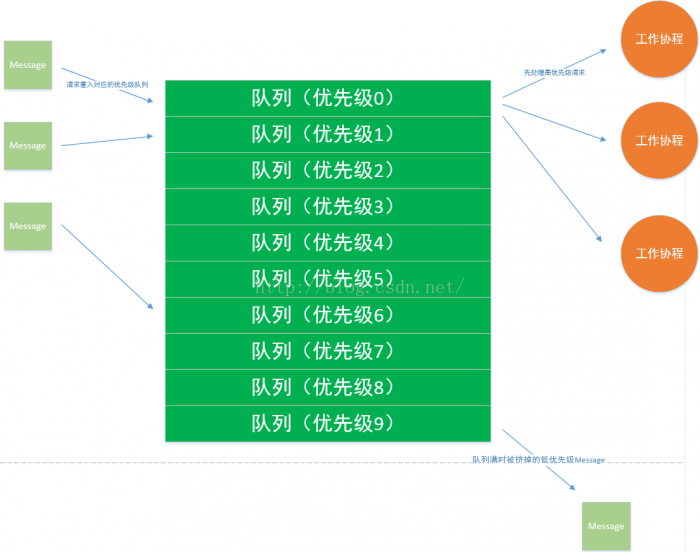
Kiev內建了一個過載保護佇列,分為10個優先順序。每個請求到達時先進入過載保護佇列,而後由工作協程(work-coroutine)取出請求進行處理。 如果工作協程的處理速度低於請求到達的速度,過載保護佇列就會堆積、甚至堆積滿。 當過載保護佇列堆滿時,新請求到達後會在佇列中刪除一個更低優先順序的請求,騰出一個空位,塞入新請求。 同時,佇列中的請求也是有時效性的,過長時間未能被處理的請求會被丟棄掉,以此避免處理已超時的請求。 這種機制保證了當系統過載時儘量將有限的資源提供給關鍵業務使用。
通訊協議向後相容
由於微服務架構經常需要部分發布,所以選擇一個支援向後相容的通訊協議是很必要的一個特性。 Kiev選取protobuf作為通訊協議。
與第三方庫協同工作
最早期的Kiev是基於非同步回撥模型的,但是很多第三方庫只提供了同步模型的版本,很難搭配使用。 當前的Kiev是CSP併發模型,配合libgo提供的Hook機制,可以將同步模型的第三方庫中阻塞等待的CPU時間充分利用起來執行其他邏輯,自動轉化成了CSP併發模型;非同步回撥模型的第三方庫也可以使用CSP模型中的Channel來等待回撥觸發;從而完美地與第三方庫協同工作。
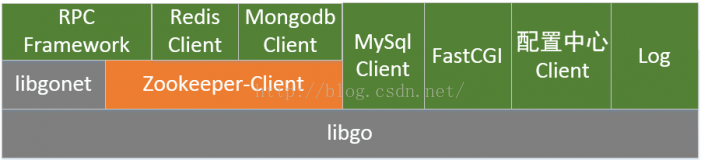
kiev功能元件結構圖
Kiev發展史與技術選型
2012年,魅族的推送業務剛剛有一點從傳統架構向微服務架構轉型的意識萌芽,為了在拆分系統的同時提高開發效率,我們決定做一個C++開發框架,這就是最早期Kiev的由來.
第一個版本的Kiev使用了多執行緒同步模型,業務邏輯順序編寫,非常簡單。 但是由於os對執行緒數的支援有限,隨著執行緒數量的增長,排程消耗的增長是非線性的,因此不能支援過高的請求併發。
隨著使用者量的增長,我們需要支援更高的併發請求,由於當年協程還不像現在這樣流行,所以我們決定使用非同步回撥模型編寫Kiev。早期的業務形態非常簡單,使用非同步回撥模型也勉強可以應付開發任務。
在其後幾年中,我們使用非同步回撥模型的Kiev開發了大量的服務,在使用中我們慢慢發現邏輯碎片化的問題越來越多,更可怕的是,有些時候長長的回撥鏈還要和有限狀態機糾纏在一起,程式碼越來越難以維護。常常出現類似於下面這樣的程式碼片段:

針對這樣的問題,我們引入了騰訊開源的協程庫libco,在協程中執行同步的程式碼邏輯;同時使用Hook技術,將阻塞式IO請求中等待的時間片利用起來,切換cpu執行其他協程,等到IO事件觸發再切換回來繼續執行邏輯。類似於上述的碎片化程式碼就變成了連續性的業務邏輯,也不再需要手動維護上下文資料,臨時資料直接置於棧上即可,程式碼變成如下的樣子:

然而,libco僅僅提供了協程和HOOK兩個功能,協程切換需要我們自己做,為了實現簡單,RPC框架進化成了連線池的模式,每次發起RPC呼叫時從連線池中取一條連線來傳送請求,等待回覆,然後釋放回連線池。 每條連線同一時刻只能跑一個請求,rpc協議退化成了半雙工模式。此時為保證效能,不得不在每兩個有依賴關係的服務之間建立數以百計的TCP連線,這樣在依賴了水平擴充套件為很多程式的服務上,就會與這些程式分別建立數百連線,TCP連線高達數千,甚至上萬,對伺服器造成了很大的壓力。連線請求如下圖所示,其中每條連線線都代表數以百計的TCP連線。

相應地,我們也更新了kiev中的redis、mysql、fastcgi模組,都改為了協程模型的。
在最初的幾個月中,這種方式很好地幫我們提升了開發效率,同時也有著還算不錯的效能(Rpc請求差不多有20K左右的QPS)。隨著時間的流逝,我們的使用者越來越多,請求量也越來越大,終於在某次新品釋出後,我們的一個非關鍵性業務出現了故障。
出現故障的這個業務是一個接受手機端訂閱請求的業務,手機端在訂閱請求超時後(大概30s),會重新嘗試發起請求。由於當時系統過載,處理速度慢於請求速度,大量請求積壓在佇列中,隨著時間的推移,服務處理請求的響應速度越來越慢,最終導致很多請求還沒處理完手機端就認為超時了,重新發起了第二次請求,形成雪崩效應。當時緊急增加了一些伺服器,恢復了故障,事後總結下來發現,事件的主因還是因為我們沒有做好過載保護機制。於是我們決定在Kiev中內建過載保護功能,增加一個分為10個優先順序的過載保護佇列。每個請求到達時先進入過載保護佇列,而後由工作協程(work-coroutine)取出請求進行處理。當過載保護佇列堆滿時,佇列中刪除一個最低優先順序的請求,騰出一個空位。同時,佇列中的請求也是有時效性的,過長時間未能被處理的請求會被丟棄掉,以此避免處理已超時的請求。如下圖所示:
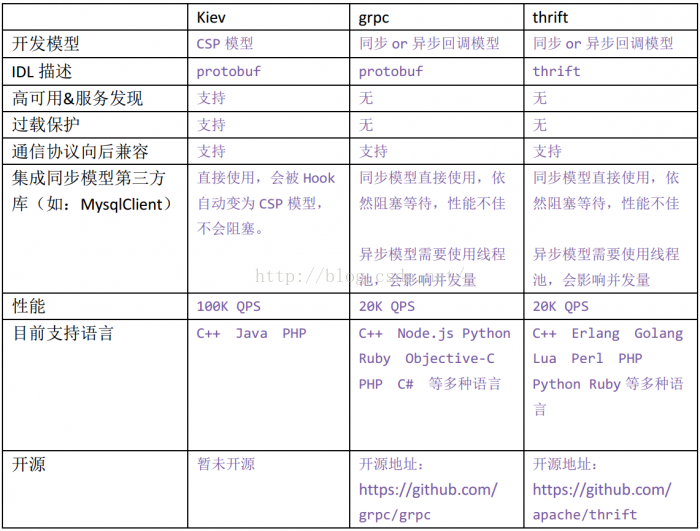
隨著機器越來越多,以及後續出現了一些超長鏈路請求的業務形態(這裡解釋一下長鏈路請求的問題,長鏈路請求是指一個請求要流經很多服務處理,在處理流程中,前面的服務一定要等到後面的服務全部處理完成或超時,才會釋放其佔用的TCP連線,這樣的模式會極大地影響整個系統的請求併發數),TCP連線數方面的壓力越來越大,最終不得不考慮改為單連線上使用全雙工模式。然而當時使用的libco功能過於簡單,很難基於此開發全雙工模式的RPC框架,恰好當時有一位同事在github上做了一個叫libgo的開源專案,是一個和golang語言一樣的CSP併發模型的協程庫,於是我們做了一段時間的技術預研,看看能否替換掉現有的libco. 下面的表格是兩個專案在我們比較關心的一些維度上的對比:
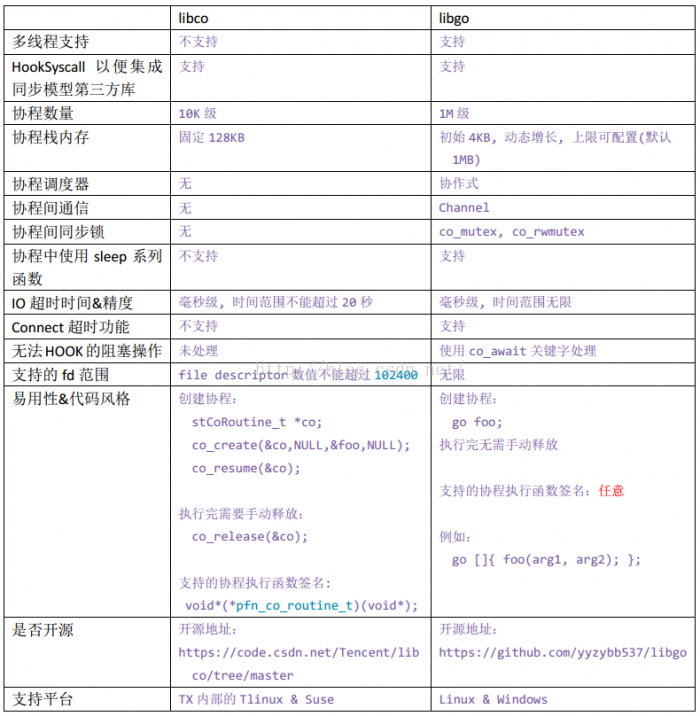
通過調研,最終我們決定使用libgo替換掉libco。
基於CSP模型實現全雙工通訊RPC非常容易,客戶端只需在每個request發出後儲存id和channel並阻塞地等待相應的channel,收到response時根據id找到對應的channel並寫入資料即可。這樣只需一條TCP連線,就可以併發無數個request,分散式水平擴充套件帶來的TCP連線管理方面的壓力就不再是問題了。同時由於每次RPC所需的資源更少,效能也有了很大提升,Rpc請求的QPS輕鬆提升到了100K以上。這一效能指標目前已經超越了絕大多數開源的RPC框架。
與流行開源框架對比
相關文章
- TiDB 技術內幕 - 談排程TiDB
- WebKit技術內幕WebKit
- 魅族16和魅族15區別對比 魅族15和魅族16哪個更好?
- ShowMeBug 核心技術內幕
- 讀《etcd 技術內幕》
- 揭祕《Arduino技術內幕》UI
- 魅族16與魅族16 Plus全面評測 魅族16值得買嗎?
- 魅族Flyme6內測體驗評測 魅族Flyme6怎麼樣
- 【魅族大賽技術公開課】移動應用開發技術精選
- 簡述Spring技術內幕Spring
- MFC技術內幕簡結 (轉)
- 三篇文章瞭解 TiDB 技術內幕 —— 談排程TiDB
- 【魅族大賽技術公開課】移動應用開發技術精選-CSDN公開課-專題視訊課程
- 「NGW」前端新技術賽場:Serverless SSR 技術內幕前端Server
- Mybatis技術內幕(2.3.3):反射模組-InvokerMyBatis反射
- Mybatis技術內幕(2.3.4):反射模組-ObjectFactoryMyBatis反射Object
- Mybatis技術內幕(2.3.1):反射模組-ReflectorMyBatis反射
- Mybatis技術內幕(1):Mybatis簡介MyBatis
- [Mysql技術內幕]Innodb儲存引擎MySql儲存引擎
- PostgreSQL技術內幕(七)索引掃描SQL索引
- Mysql技術內幕之InnoDB鎖探究MySql
- TiDB 技術內幕 - 說儲存TiDB
- [React技術內幕] setState的祕密React
- 深入分析java web技術內幕JavaWeb
- MySQL技術內幕:InnoDB儲存引擎MySql儲存引擎
- 魅族PRO 6評測 魅族PRO 6值得買嗎?
- 併發技術2:多協程
- 魅族Gravity懸浮音響跳票 只因設計超前技術難實現
- Mybatis技術內幕(2.3.6):反射模組-WrapperMyBatis反射APP
- Mybatis技術內幕(2.3.7):反射模組-TypeParameterResolverMyBatis反射
- MySQL技術內幕之“日誌檔案”MySql
- 深入剖析全鏈路灰度技術內幕
- “聲討”高雲的《jQuery技術內幕》jQuery
- 魅族智慧手錶何時釋出?魅族智慧手錶面世?
- 魅族MX6和魅族MX5的區別在哪?
- 《Storm技術內幕與大資料實踐》一1.2其他流式處理框架ORM大資料框架
- 魅族小米之爭 魅族緊隨小米進入智慧家居市場!
- 魅族智慧手錶值得期待!魅族智慧手錶何時釋出?