損失函式改進方法之Focal Loss
深度學習交流QQ群:116270156
論文:Focal Loss for Dense Object Detection
論文連結:https://arxiv.org/abs/1708.02002
RBG和Kaiming大神的新作。
我們知道object detection的演算法主要可以分為兩大類:two-stage detector和one-stage detector。前者是指類似Faster RCNN,RFCN這樣需要region proposal的檢測演算法,這類演算法可以達到很高的準確率,但是速度較慢。雖然可以通過減少proposal的數量或降低輸入影象的解析度等方式達到提速,但是速度並沒有質的提升。後者是指類似YOLO,SSD這樣不需要region proposal,直接回歸的檢測演算法,這類演算法速度很快,但是準確率不如前者。作者提出focal
loss的出發點也是希望one-stage detector可以達到two-stage detector的準確率,同時不影響原有的速度。
既然有了出發點,那麼就要找one-stage detector的準確率不如two-stage detector的原因,作者認為原因是:樣本的類別不均衡導致的。我們知道在object detection領域,一張影象可能生成成千上萬的candidate locations,但是其中只有很少一部分是包含object的,這就帶來了類別不均衡。那麼類別不均衡會帶來什麼後果呢?引用原文講的兩個後果:(1) training is inefficient as most locations are easy negatives that contribute no useful learning signal; (2) en masse, the easy negatives can overwhelm training and lead to degenerate models. 什麼意思呢?負樣本數量太大,佔總的loss的大部分,而且多是容易分類的,因此使得模型的優化方向並不是我們所希望的那樣。其實先前也有一些演算法來處理類別不均衡的問題,比如OHEM(online hard example mining),OHEM的主要思想可以用原文的一句話概括:In OHEM each example is scored by its loss, non-maximum suppression (nms) is then applied, and a minibatch is constructed with the highest-loss examples。OHEM演算法雖然增加了錯分類樣本的權重,但是OHEM演算法忽略了容易分類的樣本。
因此針對類別不均衡問題,作者提出一種新的損失函式:focal loss,這個損失函式是在標準交叉熵損失基礎上修改得到的。這個函式可以通過減少易分類樣本的權重,使得模型在訓練時更專注於難分類的樣本。為了證明focal loss的有效性,作者設計了一個dense detector:RetinaNet,並且在訓練時採用focal loss訓練。實驗證明RetinaNet不僅可以達到one-stage detector的速度,也能有two-stage detector的準確率。
focal loss的含義可以看如下Figure1,橫座標是pt,縱座標是loss。CE(pt)表示標準的交叉熵公式,FL(pt)表示focal loss中用到的改進的交叉熵,可以看出和原來的交叉熵對比多了一個調製係數(modulating factor)。為什麼要加上這個調製係數呢?目的是通過減少易分類樣本的權重,從而使得模型在訓練時更專注於難分類的樣本。首先pt的範圍是0到1,所以不管γ是多少,這個調製係數都是大於等於0的。易分類的樣本再多,你的權重很小,那麼對於total loss的共享也就不會太大。那麼怎麼控制樣本權重呢?舉個例子,假設一個二分類,樣本x1屬於類別1的pt=0.9,樣本x2屬於類別1的pt=0.6,顯然前者更可能是類別1,假設γ=1,那麼對於pt=0.9,調製係數則為0.1;對於pt=0.6,調製係數則為0.4,這個調製係數就是這個樣本對loss的貢獻程度,也就是權重,所以難分的樣本(pt=0.6)的權重更大。Figure1中γ=0的藍色曲線就是標準的交叉熵損失。
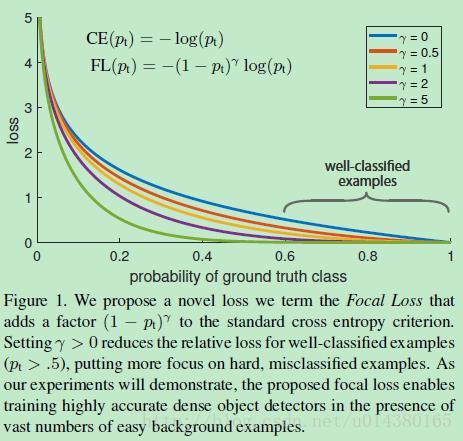
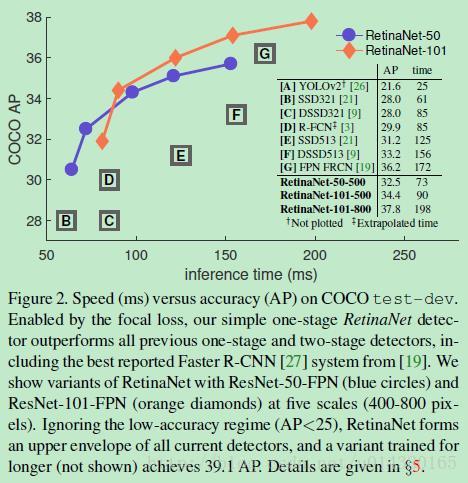
Figure2是在COCO資料集上幾個模型的實驗對比結果。可以看看再AP和time的對比下,本文演算法和其他one-stage和two-stage檢測演算法的差別。
看完實驗結果和提出演算法的出發點,接下來就要介紹focal loss了。在介紹focal loss之前,先來看看交叉熵損失,這裡以二分類為例,p表示概率,公式如下:
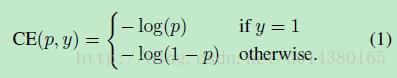
因為是二分類,所以y的值是正1或負1,p的範圍為0到1。當真實label是1,也就是y=1時,假如某個樣本x預測為1這個類的概率p=0.6,那麼損失就是-log(0.6),注意這個損失是大於等於0的。如果p=0.9,那麼損失就是-log(0.9),所以p=0.6的損失要大於p=0.9的損失,這很容易理解。
為了方便,用pt代替p,如下公式2:。這裡的pt就是前面Figure1中的橫座標。
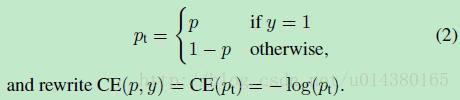
接下來介紹一個最基本的對交叉熵的改進,也將作為本文實驗的baseline,如下公式3。什麼意思呢?增加了一個係數at,跟pt的定義類似,當label=1的時候,at=a;當label=-1的時候,at=1-a,a的範圍也是0到1。因此可以通過設定a的值(一般而言假如1這個類的樣本數比-1這個類的樣本數多很多,那麼a會取0到0.5來增加-1這個類的樣本的權重)來控制正負樣本對總的loss的共享權重。
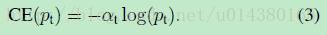
顯然前面的公式3雖然可以控制正負樣本的權重,但是沒法控制容易分類和難分類樣本的權重,於是就有了focal loss:
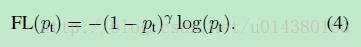
這裡的γ稱作focusing parameter,γ>=0。
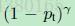
稱為調製係數(modulating factor)
這裡介紹下focal loss的兩個重要性質:1、當一個樣本被分錯的時候,pt是很小的(請結合公式2,比如當y=1時,p要小於0.5才是錯分類,此時pt就比較小,反之亦然),因此調製係數就趨於1,也就是說相比原來的loss是沒有什麼大的改變的。當pt趨於1的時候(此時分類正確而且是易分類樣本),調製係數趨於0,也就是對於總的loss的貢獻很小。2、當γ=0的時候,focal loss就是傳統的交叉熵損失,當γ增加的時候,調製係數也會增加。
focal loss的兩個性質算是核心,其實就是用一個合適的函式去度量難分類和易分類樣本對總的損失的貢獻。
作者在實驗中採用的是公式5的focal loss(結合了公式3和公式4,這樣既能調整正負樣本的權重,又能控制難易分類樣本的權重):
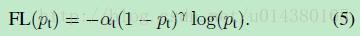
在實驗中a的選擇範圍也很廣,一般而言當γ增加的時候,a需要減小一點(實驗中γ=2,a=0.25的效果最好)
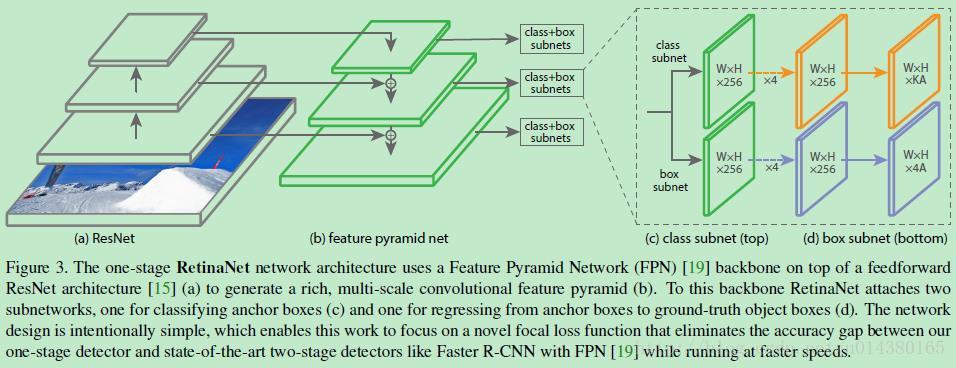
貼一下RetinaNet的結構圖:Figure3。因為網路結構不是本文的重點,所以這裡就不詳細介紹了,感興趣的可以看論文的第4部分。
實驗結果:
Table1是關於RetinaNet和Focal Loss的一些實驗結果。(a)是在交叉熵的基礎上加上引數a,a=0.5就表示傳統的交叉熵,可以看出當a=0.75的時候效果最好,AP值提升了0.9。(b)是對比不同的引數γ和a的實驗結果,可以看出隨著γ的增加,AP提升比較明顯。(d)通過和OHEM的對比可以看出最好的Focal Loss比最好的OHEM提高了3.2AP。這裡OHEM1:3表示在通過OHEM得到的minibatch上強制positive和negative樣本的比例為1:3,通過對比可以看出這種強制的操作並沒有提升AP。(e)加入了運算時間的對比,可以和前面的Figure2結合起來看,速度方面也有優勢!注意這裡RetinaNet-101-800的AP是37.8,當把訓練時間擴大1.5倍同時採用scale
jitter,AP可以提高到39.1,這就是全文和table2中的最高的39.1AP的由來。
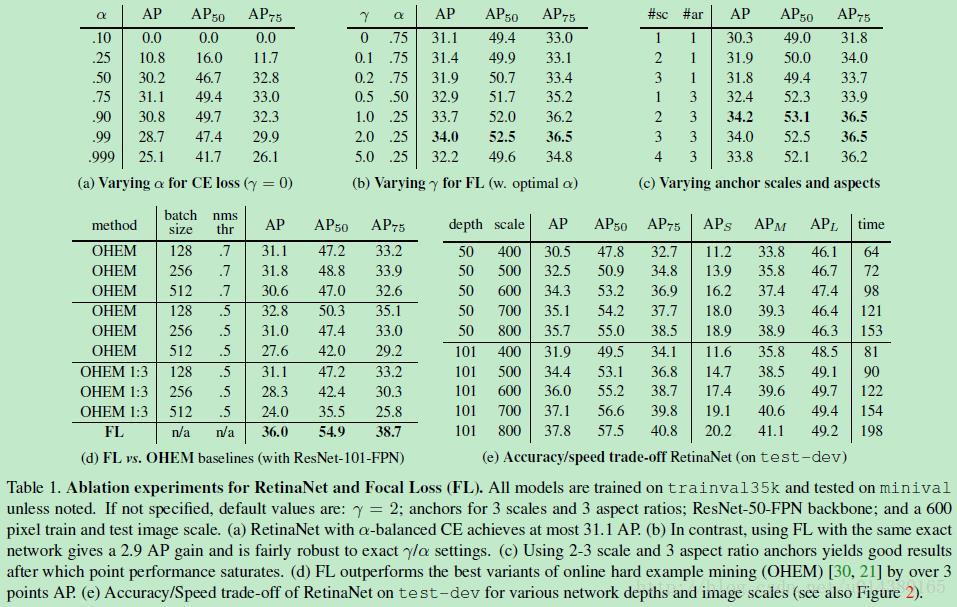
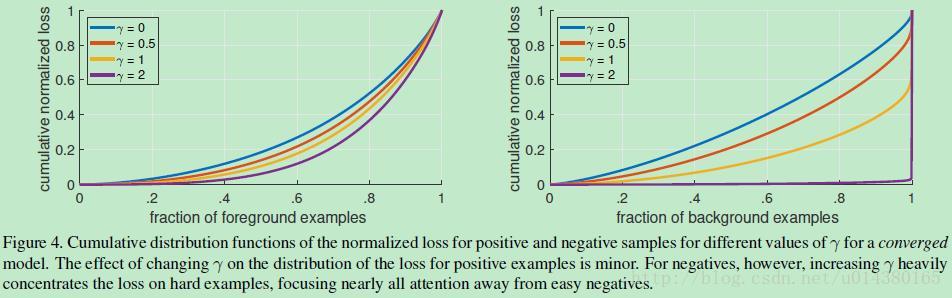
Figure4是對比forground和background樣本在不同γ情況下的累積誤差。縱座標是歸一化後的損失,橫座標是總的foreground或background樣本數的百分比。可以看出γ的變化對正(forground)樣本的累積誤差的影響並不大,但是對於負(background)樣本的累積誤差的影響還是很大的(γ=2時,將近99%的background樣本的損失都非常小)。
總結:
原文的這段話概括得很好:In this work, we identify class imbalance as the primary obstacle preventing one-stage object detectors from surpassing top-performing, two-stage methods, such as Faster R-CNN variants. To address this, we propose the focal loss which applies
a modulating term to the cross entropy loss in order to focus learning on hard examples and down-weight the numerous easy negatives.
相關文章
- 焦點損失函式 Focal Loss 與 GHM函式
- Triplet Loss 損失函式函式
- PyTorch:損失函式loss functionPyTorch函式Function
- 何愷明Focal Loss改進版!GFocal Loss:良心技術,無cost漲點
- Focal loss論文解析
- 損失函式函式
- 損失函式+啟用函式函式
- 3D高斯損失函式(1)單純損失函式3D函式
- 損失函式綜述函式
- Pytorch 常用損失函式PyTorch函式
- DDMP中的損失函式函式
- 【機器學習】【base】 之 目標函式 損失函式 優化演算法機器學習函式優化演算法
- 例項解釋NLLLoss損失函式與CrossEntropyLoss損失函式的關係函式ROS
- TensorFlow損失函式專題函式
- 談談交叉熵損失函式熵函式
- Pytorch中的損失函式PyTorch函式
- SSD的損失函式設計函式
- 邏輯迴歸 損失函式邏輯迴歸函式
- 聊聊損失函式1. 噪聲魯棒損失函式簡析 & 程式碼實現函式
- 詳解常見的損失函式函式
- 2.3邏輯迴歸損失函式邏輯迴歸函式
- TensorFlow筆記-06-神經網路優化-損失函式,自定義損失函式,交叉熵筆記神經網路優化函式熵
- 技術乾貨 | 基於MindSpore更好的理解Focal Loss
- 圖示Softmax及交叉熵損失函式熵函式
- 邏輯迴歸損失函式(cost function)邏輯迴歸函式Function
- 人臉識別損失函式疏理與分析函式
- 理解神經網路的不同損失函式神經網路函式
- 【機器學習基礎】常見損失函式總結機器學習函式
- 邏輯迴歸:損失函式與梯度下降邏輯迴歸函式梯度
- 3D高斯損失函式(2)新增BA最佳化和結構損失3D函式
- 換個角度看GAN:另一種損失函式函式
- 神經網路基礎部件-損失函式詳解神經網路函式
- 深度神經網路(DNN)損失函式和啟用函式的選擇神經網路DNN函式
- Java開發者的神經網路進階指南:深入探討交叉熵損失函式Java神經網路熵函式
- 深度學習基礎5:交叉熵損失函式、MSE、CTC損失適用於字識別語音等序列問題、Balanced L1 Loss適用於目標檢測深度學習熵函式
- 梯度提升二三事:怎麼來自定義損失函式?梯度函式
- 機器學習者都應該知道的五種損失函式!機器學習函式
- JavaScript進階之函式JavaScript函式