深度學習演算法之YOLOv2
一. 久違的新版本
YOLO 問世已久,不過風頭被SSD蓋過不少,原作者自然不甘心,YOLO v2 的提出給我們帶來了什麼呢?
先看一下其在 v1的基礎上做了哪些改進,直接引用作者的實驗結果了:
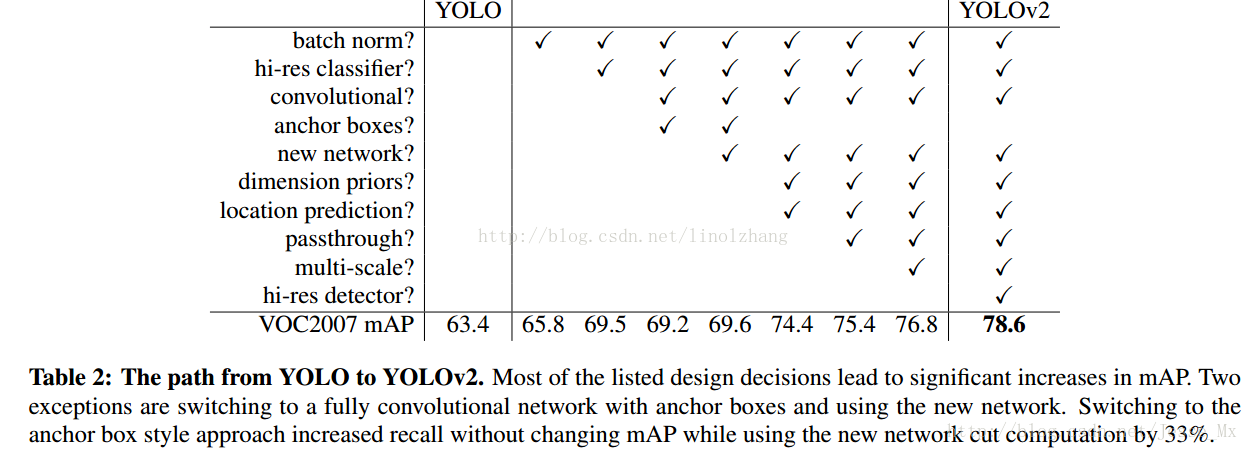
條目不少,好多Trick,我們一個一個來看:
A)Batch Normalization(批量規範化)
先建立這樣一個觀點: 對資料進行預處理(統一格式、均衡化、去噪等)能夠大大提高訓練速度,提升訓練效果。
批量規範化 正是基於這個假設的實踐,對每一層輸入的資料進行加工。示意圖:
Batch Normalization,簡稱 BN,由Google提出,是指對資料的 歸一化、規範化、正態化。BN 作為近幾年最火爆的Trick之一,主流的CNN都已整合。
該方法的提出基於以下背景:

1)神經網路每層輸入的分佈總是發生變化,通過標準化上層輸出,均衡輸入資料分佈,加快訓練速度;
可以設定較大的學習率和衰減,而不用去care初始引數,BN總能快速收斂,調參狗的福音。
2)通過規範化輸入,降低啟用函式在特定輸入區間達到飽和狀態的概率,避免 gradient vanishing 問題;
舉個例子:0.95^64 ≈ 0.0375 計算累積會產生資料偏離中心,導致誤差的放大或縮小。
3)輸入規範化對應樣本正則化,在一定程度上可以替代 Drop Out;
Drop Out的比例也可以被無視了,全自動的節奏。
BN 的做法是 在卷積池化之後,啟用函式之前,對每個資料輸出進行規範化(均值為 0,方差為 1)。
公式很簡單,第一部分是 Batch內資料歸一化(其中 E為Batch均值,Var為方差),Batch資料近似代表了整體訓練資料。
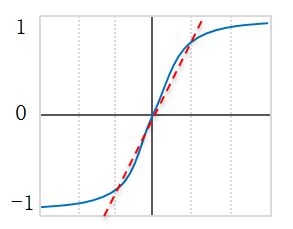
第二部分是亮點,即引入 附加引數 γ 和 β(Scale & Shift),Why? 因為簡單的歸一化 相當於只使用了啟用函式中近似線性的部分(如下圖紅色虛線),破壞了原始資料的特徵分佈,這會降低模型表達能力。
這兩個引數需要通過訓練得到:
關於這一層的函式定義、反向求導 等具體推理本章不再做進一步介紹,大家肯定可以搜到很多專門講 BN的文獻。
B)High Resolution Classifier
YOLO 對應訓練過程分為兩步,第一步是通過 ImageNet 訓練集 進行高解析度的預訓練,這一步訓練的是分類網路;第二步是訓練檢測網路,是在分類網路的基礎上進行 fine tune。
之前的 YOLO v1以解析度224*224訓練分類網路,YOLO v2 將分類網路的解析度提高到 448*448,高解析度樣本對於效果有一定的提升(文中mAp提高了約4%)。
高解析度對於精度的提高是顯而易見的,這點我們不去論證。
C)New Network(新網路)
為保證後續 Anchor Boxes 講解的連續性,這裡將New Network提前。
作者對網路進行了改進:
1)不同於SSD的VGG-16網路,作者採用的基礎網路是Googlenet,並且加入了自己的訂製,來看資料對比:
Googlenet vs VGG-16
前向傳播運算量(一次) 85.2億次 306.9億次
精度(224 * 224) 88% 90% single-crop,top-5 accuracy
整體來看,VGG-16整體精確度較高,但計算量過於複雜,價效比不高。
2)YOLO v2採用了常用的3 * 3卷積核,在每一次池化操作後把通道數翻倍。借鑑了network in network的思想,網路使用了全域性平均池化(global average pooling)做預測,把1 * 1的卷積核置於3 * 3的卷積核之間,用來壓縮特徵。
YOLO v2包含19個卷積層、5個最大值池化層(max pooling layers )。
D)Convolutional With Anchor Boxes
Faster的 Anchor 機制又一次得到印證,與SSD一樣,Anchor建立了和原始座標的對應關係:
定義了不同的Scale和寬高比,一箇中心對應K個不同尺度和寬高比的Boxes。
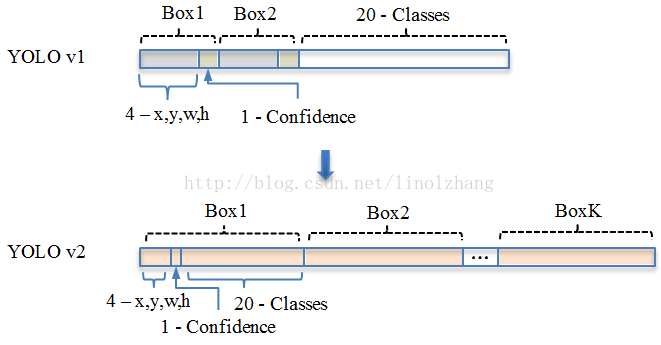
YOLO v1: S*S* (B*5 + C) => 7*7(2*5+20)
其中B對應Box數量,5對應 Rect 定位+置信度。
每個Grid只能預測對應兩個Box,這兩個Box共用一個分類結果(20 classes),
這是很不合理的臨時方案,看來作者為第二篇論文預留了改進,沒想被 SSD 搶了風頭。
YOLO v2: S*S*K* (5 + C) => 13*13*9(5+20)
解析度改成了13*13,更細的格子劃分對小目標適應更好,再加上與Faster一樣的K=9,計算量增加了不少。
通過Anchor Box改進,mAP由69.5下降到69.2,Recall由81%提升到了88%。
SSD(-): S*S*K*(4 + C) => 7*7*6*( 4+21 )
對應C=21,代表20種分類類別和一種 背景類。
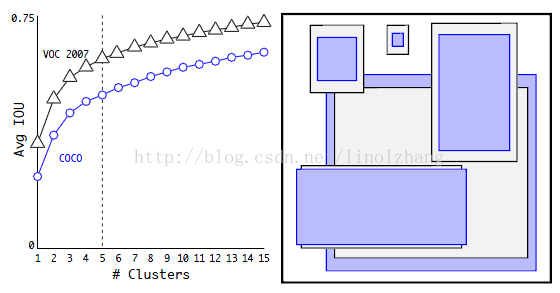
E)Dimension Clusters(維度聚類)
還是針對Anchors,Faster的Anchor對應 K=9,那麼為什麼等於9呢?寬高比為什麼定位成這樣(1:1,1:2,2:1)?
對於SSD選擇了K=6,那麼K到底等於幾合適?寬高比又該怎麼設計? 作者給出瞭解決方案,這個解決方案就是聚類。
作者在 VOC和COCO上通過Ground Truth進行聚類統計(採用K-means演算法),得到如下兩個有用資訊:
1)從K=1到K=5,IOU曲線上升較快(對應匹配度高),因此從效果和複雜度進行Trade Off, 選定了 Anchor Box個數為5;對應左圖
2)統計發現,瘦高的框比扁平的框要多一些(人比車多?),選定了5種不同 寬高比+Scale 的 Anchor Box;對應右圖
注:k-mans 採用的距離函式(度量標準) 描述為:
d(box,centroid) = 1 - IOU(box,centroid)
作者實驗發現,5種boxes的Avg IOU(61.0)就和Faster R-CNN的9種Avg IOU(60.9)相當。 說明K-means方法的生成的boxes更具有代表性。
F)Direct location prediction(直接位置預測)
直接Anchor Box迴歸導致模型不穩定,對應公式也可以參考 Faster-RCNN論文,該公式沒有任何約束,中心點可能會出現在影象任何位置,這就有可能導致迴歸過程震盪,甚至無法收斂:
針對這個問題,作者在預測位置引數時採用了強約束方法:
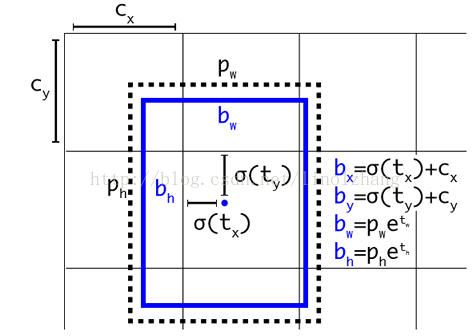
1)對應 Cell 距離左上角的邊距為(Cx,Cy),σ定義為sigmoid啟用函式,將函式值約束到[0,1],用來預測相對於該Cell 中心的偏移(不會偏離cell);
2)預定Anchor(文中描述為bounding box prior)對應的寬高為(Pw,Ph),預測 Location 是相對於Anchor的寬高 乘以係數得到;
如下圖所示:
作者通過使用 維度聚類 和 直接位置預測 這兩項Anchor Boxes改進方法,將 mAP 提高了5%。
G)Fine-Grained Features(細粒度特徵)
SSD通過不同Scale的Feature Map來預測Box來實現多尺度,而YOLO v2則採用了另一種思路:新增一個passthrough layer,來獲取上一層26x26的特徵,並將該特徵同最後輸出特徵(13*13)相結合,以此來提高對小目標的檢測能力。
通過Passthrough 把26 * 26 * 512的特徵圖疊加成13 * 13 * 2048的特徵圖,與原生的深層特徵圖相連線。
YOLO v2 使用擴充套件後的的特徵圖(add passthrough),將mAP提高了了1%。
PS:這裡實際上是有個Trick,網路最後一層是13*13,相對原來7*7的網路來講,細粒度的處理目標已經double了,再加上上一層26*26的Feature共同決策,這兩層的貢獻等價於SSD的4層以上,但計算量其實並沒有增加多少。
H)Multi-Scale Training(多尺度訓練)
為了讓 YOLOv2 適應不同Scale下的檢測任務,作者嘗試 通過不同解析度圖片的訓練來提高網路的適應性。
PS:網路只用到了卷積層和池化層,可以進行動態調整(檢測任意大小圖片)
具體做法是:
每經過10批訓練(10 batches)就會隨機選擇新的圖片尺寸,尺度定義為32的倍數,( 320,352,…,608 ),為了最後一層得到特徵圖尺度為13*13(416=13*32),YOLO v2 輸入圖片尺寸為416 * 416,降取樣引數為32。
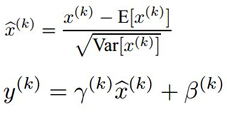

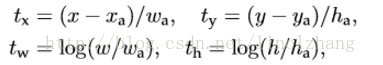
二. 訓練過程
作者採用的深度學習框架是Darknet,該框架作者使用很少,具體不作描述。
a)預訓練 - 訓練分類網路(Training for classification)
採用隨機梯度下降法SGD,在 ImageNet-1000分類資料集 上訓練了160個epochs,引數設定:
初始學習率 - starting learning rate:0.1
多項式速率衰減 - polynomial rate decay:4的冪次
權值衰減 - weight decay:0.0005
動量 - momentum:0.9
b)資料增廣方法(Data augmentation)
採用了常見的data augmentation,包括:
隨機裁剪、旋轉 - random crops、rotations
色調、飽和度、曝光偏移 - hue、saturation、exposure shifts
c)多解析度訓練
通過初始的224 * 224訓練後,把解析度上調到了448 * 448,同樣的引數又訓練了10個epochs,然後將學習率調整到了10^{-3}。
d)訓練檢測網路 - Training for detection
把分類網路改成檢測網路,去掉原網路最後一個卷積層,增加了三個 3 * 3 (1024 filters)的卷積層,並且在每一個卷積層後面跟一個1 * 1的卷積層,輸出個數是檢測所需要的數量。
初始學習率為10^{-3},訓練了160個epochs(劃分為60 | 10 | 90),權值衰減 與 momentum引數與前面一樣。
三. 交叉資料集訓練
大家都知道,不同的資料集有不同的作用,通常我們採用一個資料集進行訓練,而作者提出了新的思路:
通過ImageNet訓練分類,COCO和VOC資料集來訓練檢測,這是一個很有價值的思路,可以讓我們在公網上達到比較優的效果。 通過將兩個資料集混合訓練,如果遇到來自分類集的圖片則只計算分類的Loss,遇到來自檢測集的圖片則計算完整的Loss。
這裡面是有問題的,ImageNet對應分類有9000種,而COCO則只提供80種目標檢測,這中間如何Match?答案就是multi-label模型,即假定一張圖片可以有多個label,並且不要求label間獨立。
還是通過作者Paper裡的圖來說明,由於ImageNet的類別是從WordNet選取的,作者採用以下策略重建了一個樹形結構(稱為分層樹):
1)遍歷Imagenet的label,然後在WordNet中尋找該label到根節點(指向一個物理物件)的路徑;
2)如果路徑直有一條,那麼就將該路徑直接加入到分層樹結構中;
3)否則,從剩餘的路徑中選擇一條最短路徑,加入到分層樹。
這個分層樹我們稱之為 Word Tree,作用就在於將兩種資料集按照層級進行結合。
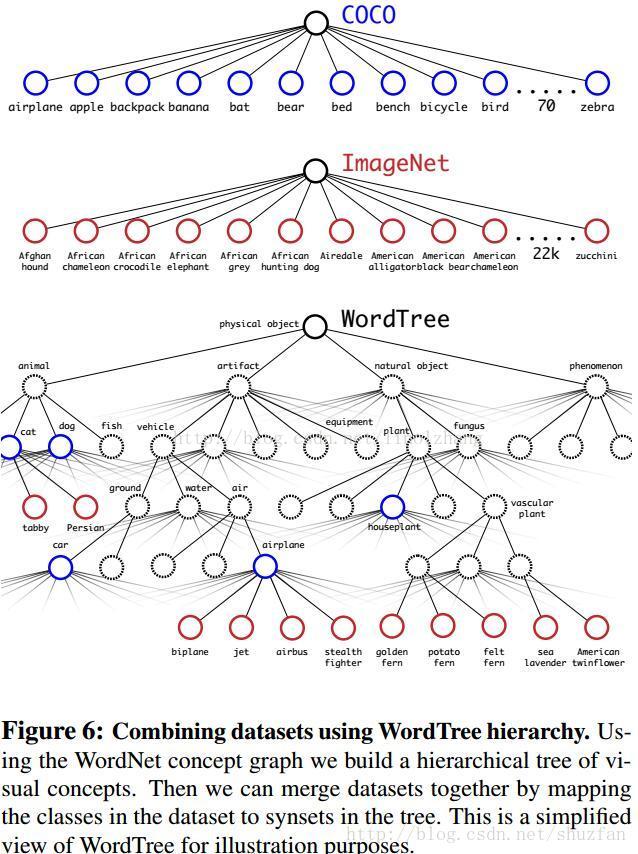
分類時的概率計算借用了決策樹思想,某個節點的概率值等於 該節點到根節點的所有條件概率之積。
另外,softmax操作也同時應該採用分組操作,下圖上半部分為ImageNet對應的原生Softmax,下半部分對應基於Word Tree的Softmax:
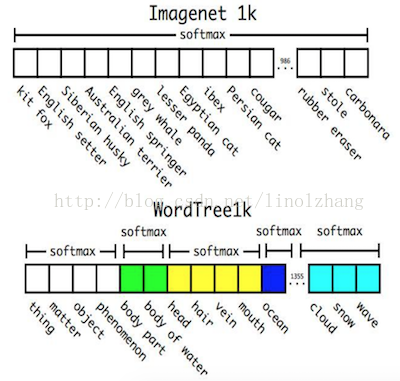
通過上述方案構造WordTree,得到對應9418個分類,通過重取樣保證Imagenet和COCO的樣本資料比例為4:1(這個沒有太明顯的意義,你也可以改成6:1試試效果)。
四. 效果如何?
YOLO v2 在大尺寸圖片上能夠實現高精度,在小尺寸圖片上執行更快,可以說在速度和精度上達到了平衡。總結下不同解析度下的震撼的效果:
1)低解析度 - 228 * 228,幀率達到90FPS,mAP幾乎與Faster媲美;
2)高解析度,在VOC2007 上mAP達到78.6%,同時FPS=40;
看圖說話:
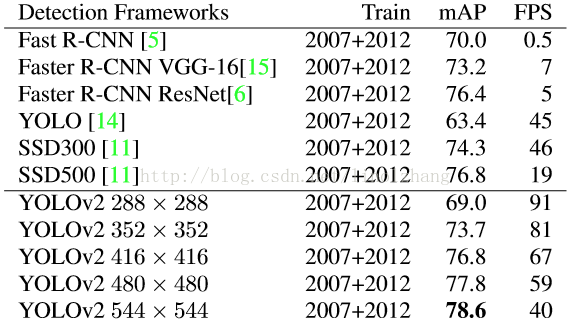
相比SSD,YOLOv2新增了諸多工程Trick,雖然在演算法理論上並沒有明確的突破,但效果著實提升不少,相信實用性仍是我們的第一齣發點,為作者點贊!
相關文章
- 基於yolov2深度學習網路模型的魚眼鏡頭中人員檢測演算法matlab模擬YOLO深度學習模型演算法Matlab
- 如何學習和利用深度學習演算法框架深度學習演算法框架
- 深度學習word2vec筆記之演算法篇深度學習筆記演算法
- yolov2演算法淺見YOLO演算法
- 深度學習基礎之 Dropout深度學習
- 《深度學習之TensorFlow》pdf深度學習
- 深度學習之Tensorflow框架深度學習框架
- 深度學習 - 常用優化演算法深度學習優化演算法
- 深度學習(一)深度學習學習資料深度學習
- 深度學習|基於MobileNet的多目標跟蹤深度學習演算法深度學習演算法
- 深度學習之遷移學習介紹與使用深度學習遷移學習
- 深度學習優化演算法總結深度學習優化演算法
- 深度學習之目標檢測深度學習
- 深度學習之瑕疵缺陷檢測深度學習
- 深度學習(五)之原型網路深度學習原型
- 深度學習之Transformer網路深度學習ORM
- 深度學習之殘差網路深度學習
- 深度學習(三)之LSTM寫詩深度學習
- 深度學習(二)之貓狗分類深度學習
- 深度學習之PyTorch實戰(4)——遷移學習深度學習PyTorch遷移學習
- RSA演算法之學習演算法
- 深度學習+深度強化學習+遷移學習【研修】深度學習強化學習遷移學習
- 深度學習演算法簡要綜述(下)深度學習演算法
- 深度學習演算法:從模仿到創造深度學習演算法
- 深度學習及深度強化學習研修深度學習強化學習
- 深度學習之卷積模型應用深度學習卷積模型
- 深度學習利器之自動微分(1)深度學習
- 深度學習利器之自動微分(2)深度學習
- 深度學習tensorflow 之 distorted_inputs深度學習
- AI之(神經網路+深度學習)AI神經網路深度學習
- 深度學習讀書筆記之RBM深度學習筆記
- 深度學習學習框架深度學習框架
- m基於yolov2深度學習的車輛檢測系統matlab模擬,帶GUI操作介面YOLO深度學習MatlabGUI
- m基於yolov2深度學習的細胞檢測系統matlab模擬,帶GUI操作介面YOLO深度學習MatlabGUI
- 深度學習深度學習
- ####深度學習深度學習
- 深度 學習
- Deep Learning(深度學習)學習筆記整理系列之(一)深度學習筆記