Springboot與Selenium合體變蜘蛛爬企查查
最近工作上需要一些企業的詳細的資料,工商資訊啦,基本資訊啦,還有一些關係圖(投資關係、人物圖譜)之類的,然後我來負責從企查查上弄些資料。
強調:下面只是快速實現資料抓取的思路,沒有詳細的程式碼,同時也拒絕伸手黨。
現實中,一些工商資訊網站會被無數的爬蟲“騷擾”,所以網站的反爬蟲策略也是越來越高,就拿企查查來說,基本的資訊是直接可訪問的,但是像人物圖譜和企業圖譜這些內容還是需要登入的,
特別是人物圖譜,非VIP會員,一天也只能看兩次
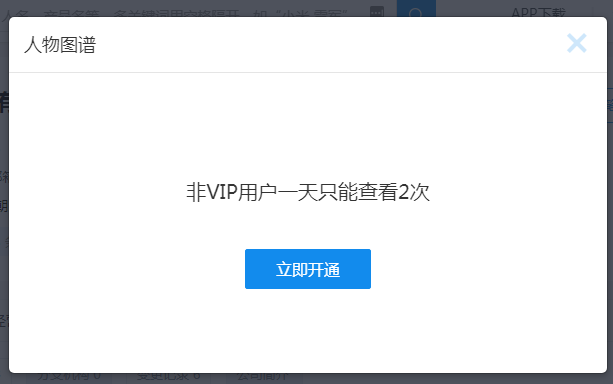
企查查的登入也是做了很多限制
比如圖片驗證碼啊,數字驗證碼啊,還有驗證碼異常出現重新整理按鈕啊等等(之前在做的過程中發現的沒有及時截圖)
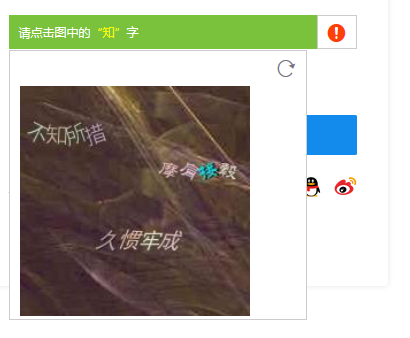
但是有了selenium這些都不是問題~接下來按照如下思維導圖做一個抓取的分析(程式碼想了許久還是不貼出來了)
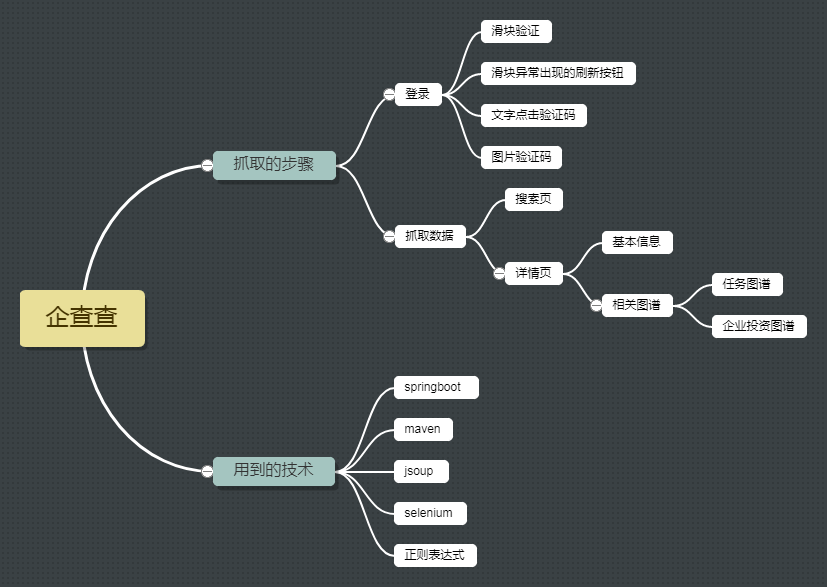
登入
滑塊驗證
首先出場的是滑塊驗證,這個可以使用Selenium中的Actions.clickAndHold()來破防,開啟瀏覽器Element皮膚,邊滑動滑塊邊觀察Html
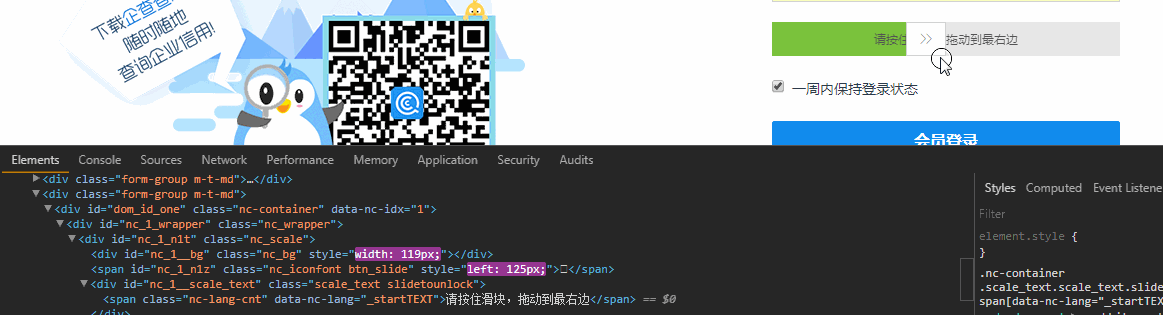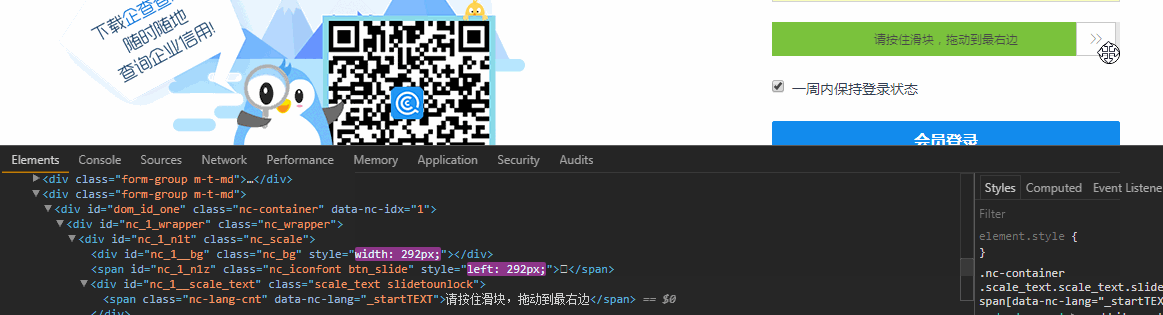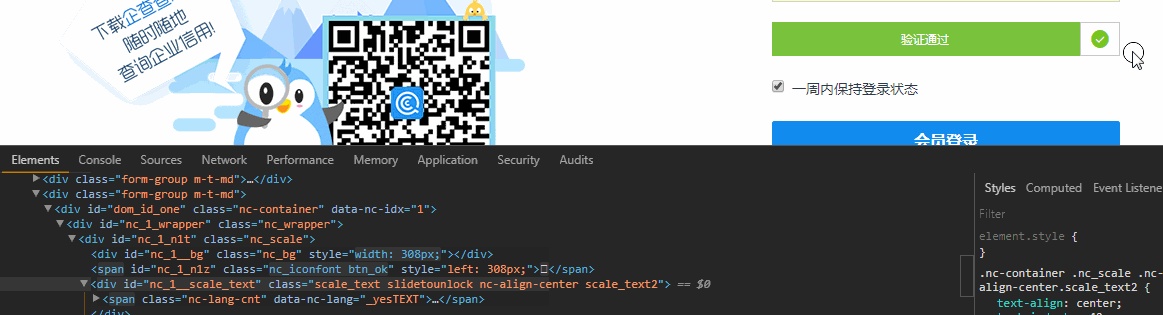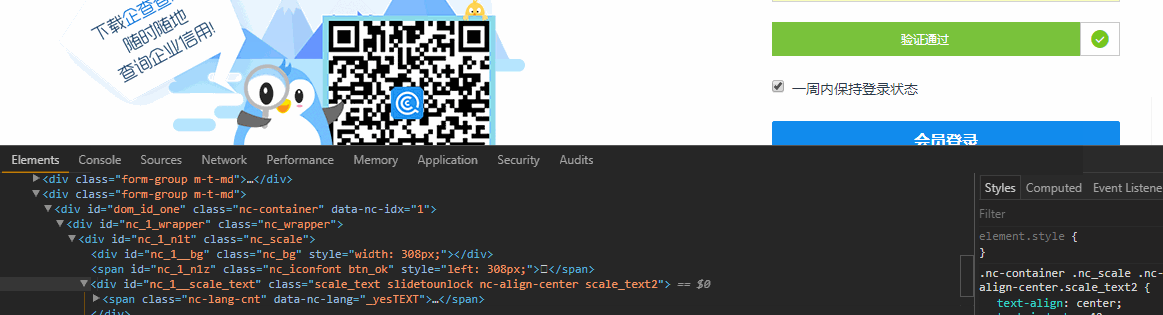 這說明滑塊不只是單純的移動到右側,還導致其他樣式改變,這也說明你不能直接通過修改Html的方式改變滑塊的位置來驗證 ,Ps:有的網站只要滑塊在最終的位置,就認為驗證通過了。
這說明滑塊不只是單純的移動到右側,還導致其他樣式改變,這也說明你不能直接通過修改Html的方式改變滑塊的位置來驗證 ,Ps:有的網站只要滑塊在最終的位置,就認為驗證通過了。
使用java和selenium模擬滑動滑塊
WebElement dragger = driver.findElement(By.cssSelector("#nc_1_n1z"));
Actions action = new Actions(driver);
action.clickAndHold(dragger).build().perform();
for (int i = 0; i < target; i++) {
try {
action.moveByOffset(offset, 0).perform();
} catch (Exception e) {
e.printStackTrace();
}
}target 和 offset 的值自己去口算一下~
圖片型驗證碼
不知為何,我每次用程式碼模擬滑塊的時候頁面都會彈出圖片型驗證碼,而人工滑動卻不要,這讓我很費解。
一般像圖片型驗證碼和數字型驗證碼有的人可能會自己去研究演算法來解決,什麼機器學習啦,深度學習啦等等。這裡不要這麼高深的,統統用打碼平臺,用法和價格自行百度,可以這樣理解:你通過Http的方式提交圖片和要求,平臺會返回給你相應的結果。如數字啦、文字的座標啦、多個文字的座標等等。
仔細分析下面的截圖所對應的的Element
我們可以看出驗證要求在青色橫條中,而目標文字在下面的方塊中,這是兩個不同的Element,而打碼平臺的要求是給他一張完整的圖片,這個當時我想都沒想,立即決定使用selenium截圖的方式將橫條和方塊分別儲存下來,然後通過程式碼將其拼接為一張圖片,最後將一整張圖提交給打碼平臺。如下
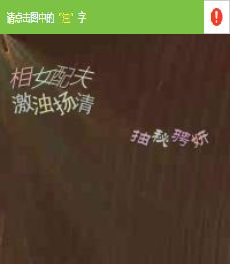
然後平臺會返回給你一個座標如(x,y),剛剛提到了方塊圖他是單獨的一個Element,所以目標y還要減去橫條的高度即(x,y-34),這個時候你以為搞定了?NoNoNo!通過瀏覽器的定位元素,可以看到
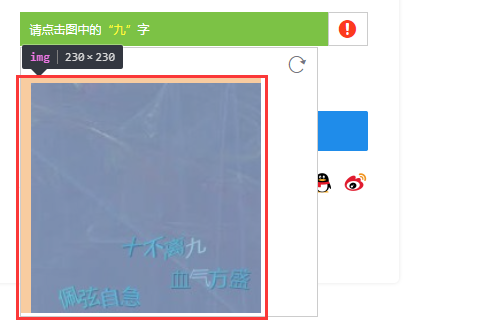
方塊所在的Elemnt 有個樣式margin-left,所以我們還要減去這個值,即最終的最標為(x + 2, y - 34)為什麼是2而不是10,這個是因為我嘗試了很多次,發現2才可以。。。
好了接下來就是根據座標去點選,要用到這個方法:
Actions action = new Actions(driver);
action.moveToElement(bodyImgEle, x + 2, y - 34).click().perform();這裡注意下,moveToElement是以element的左上角為原點,往右是X,往下是Y
數字驗證碼
(沒有截圖,只有程式碼截的圖)
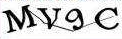
這樣的就很普通了,我們依然交給打碼平臺,通過使用返回的“MV9C”來通過此驗證。
異常重新整理
(這個也沒有截圖)出現這種情況我猜測是企查查檢測到你這邊頻繁的登入或驗證,形式就是滑動條上出現了“重新整理”超連結,這個只要定為到“重新整理”Element,點選一下就ok,如下
WebElement err = reloadElement.findElement(By.cssSelector("#dom_id_one > div > span > a"));
err.click();注意:登入的過程中每一個驗證都可能有失敗的情況,所以每個處理最好加上一個迴圈,直到驗證通過再跳出迴圈進入下一步操作
抓取資料
這裡重點講企業詳情頁
對於企查查來說只要登入這塊搞定了,其他資料不是問題,就是簡單的分析下每個資料的請求地址,然後用selenium模擬請求就行了。
人物圖譜

URL:http://www.qichacha.com/company_opercorview?name=馬化騰&personId=p03cf330a686332cfe9cb8f36a8f3ab8&keyno=f1c5372005e04ba99175d5fd3db7b8fc投資圖譜
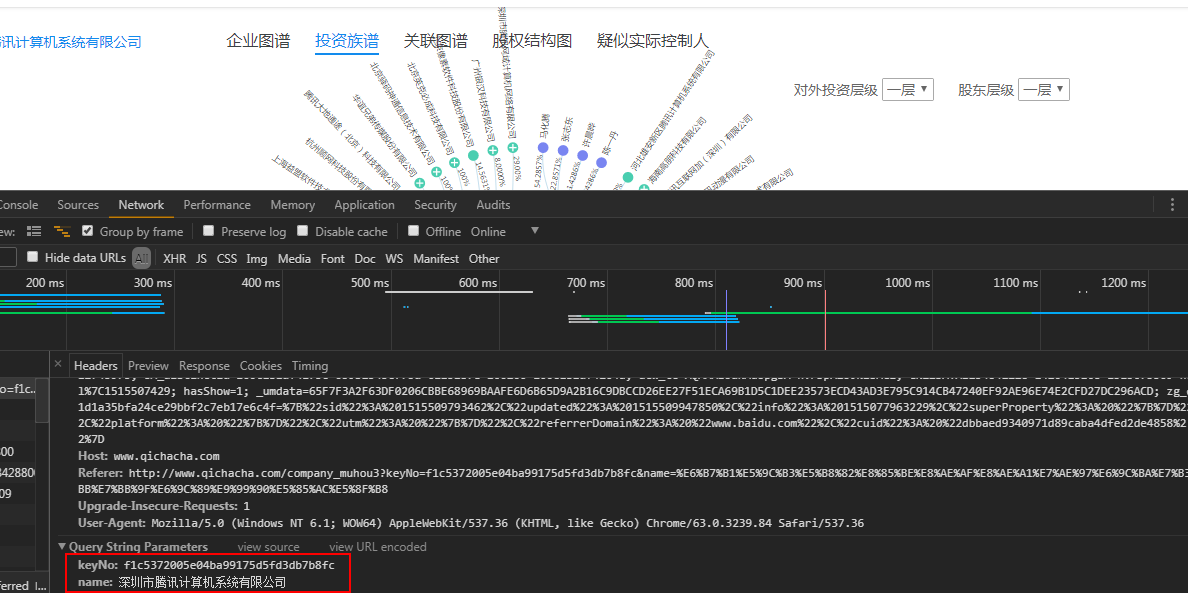
URL:http://www.qichacha.com/company_relation?keyNo=f1c5372005e04ba99175d5fd3db7b8fc&name=深圳市騰訊計算機系統有限公司很直觀的就能看到請求地址,然後將返回的JSON字串處理一下,就得到了你想要的資料
這裡不做太多的贅述。
貼個控制檯的圖

總結
總的來講企查查的網站相對於天眼查還是比較容易突破的,只要把登入這塊完美處理好,其他就是解析上的問題了。
話說企查查並沒有對訪問IP做限制處理,只是如果用一個賬號訪問次數太多之後,中間也會出現滑塊認證,但是不要擔心,你可以把登入那塊的驗證邏輯直接搬過來即可,你敢信?
爬蟲不是我的主要工作,我只是對資料抓取這塊比較感興趣,還有在工作中有些資料需要抓取,所以我也就擔當了半個爬蟲的角色,最近自己在使用jsoup寫一個簡易爬蟲框架(參照webmagic),有興趣得可持續關注我,如果有必要的話,我會寫一些爬蟲教程,讓小白變大白(●—●)綽綽有餘
CSDN:http://blog.csdn.net/qqhjqs?viewmode=list
部落格:http://vector4wang.tk/
簡書:https://www.jianshu.com/u/223a1314e818
Github:https://github.com/vector4wang
相關文章
- Nebula Graph 在企查查的應用
- PHP蜘蛛爬蟲開發文件PHP爬蟲
- seo-mask -- 為單頁應用建立一個適合蜘蛛爬取的seo網站網站
- SpringBoot:結合 SpringBoot 與 Grails 3Spring BootAI
- 搜尋引擎爬蟲蜘蛛的User-Agent收集爬蟲
- 爬蟲-selenium的使用爬蟲
- SQL執行速度慢?查查中介軟體SQL
- SpringBoot與mongodb的結合Spring BootMongoDB
- selenium爬蟲學習1爬蟲
- 隱私保護軟體——蜘蛛密友
- 企查查:我國在業/存續“大資料”相關企業共有18.65萬家大資料
- Python爬蟲之路-selenium在爬蟲中的使用Python爬蟲
- 呼叫瀏覽器的爬蟲——selenium瀏覽器爬蟲
- Python爬蟲基礎之seleniumPython爬蟲
- 【爬蟲】專案篇-使用selenium爬取大魚潮汐網爬蟲
- Web網站如何檢視搜尋引擎蜘蛛爬蟲的行為Web網站爬蟲
- 結合“xPlus”探討軟體架構的創新與變革架構
- 企業級SpringBoot與Dubbo的並用Spring Boot
- 使用Selenium從IEEE與谷歌學術批量爬取BibTex文獻引用谷歌
- Python爬蟲教程-27-Selenium Chrome版本與chromedriver相容版本對照表Python爬蟲Chrome
- 智慧穿戴裝置:穿上就變蜘蛛俠的褲子
- 爬蟲實戰(二):Selenium 模擬登入並爬取資訊爬蟲
- python實現selenium網路爬蟲Python爬蟲
- Selenium + Scrapy爬取某商標資料
- 如何利用 Selenium 爬取評論資料?
- JAVA爬蟲使用Selenium自動翻頁Java爬蟲
- SpringBoot與單元測試JUnit的結合Spring Boot
- SpringBoot基礎教程(十六)——與docker的結合Spring BootDocker
- [python爬蟲] BeautifulSoup和Selenium簡單爬取知網資訊測試Python爬蟲
- [譯]不變性之道 —— 組合軟體系列
- 禁止蜘蛛/爬蟲:如何配置Robots.txt和網站地圖(Sitemap.xml)爬蟲網站地圖XML
- Datawhale-爬蟲-Task5(selenium學習)爬蟲
- [Python3]selenium爬取淘寶商品資訊Python
- Python爬蟲之Selenium庫的基本使用Python爬蟲
- python利用selenium+phantomJS爬淘寶PythonJS
- Python爬蟲學習(9):Selenium的使用Python爬蟲
- Python爬蟲之selenium庫使用詳解Python爬蟲
- 企業IT基礎發展趁向與企業業務管理貼合