Apriori演算法 java程式碼
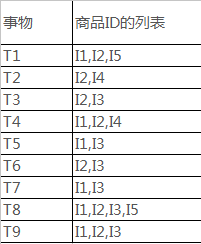
訓練集:
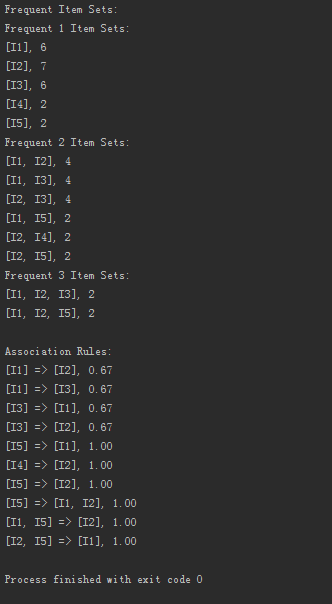
結果:
程式碼:
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import java.util.TreeMap;
import java.util.TreeSet;
public class Apriori {
public static void main(String[] args) throws Exception {
// 初始化事務集
List<Set<String>> trans = new LinkedList<Set<String>>();
trans.add(new ItemSet(new String[] { "I1", "I2", "I5" }));
trans.add(new ItemSet(new String[] { "I2", "I4" }));
trans.add(new ItemSet(new String[] { "I2", "I3" }));
trans.add(new ItemSet(new String[] { "I1", "I2", "I4" }));
trans.add(new ItemSet(new String[] { "I1", "I3" }));
trans.add(new ItemSet(new String[] { "I2", "I3" }));
trans.add(new ItemSet(new String[] { "I1", "I3" }));
trans.add(new ItemSet(new String[] { "I1", "I2", "I3", "I5" }));
trans.add(new ItemSet(new String[] { "I1", "I2", "I3" }));
int MSF = 2; // 設定最小支援頻次為2
Map<Integer, Set<ItemSet>> rst = findFrequentItemSets(trans, MSF);
// 輸出頻繁項集
System.out.println("Frequent Item Sets:");
for (Entry<Integer, Set<ItemSet>> entry : rst.entrySet()) {
Integer itemSetSize = entry.getKey();
System.out.printf("Frequent %d Item Sets:\n", itemSetSize);
for (ItemSet set : entry.getValue())
System.out.printf("%s, %d\n", set, set.frequence);
}
double MCONF = 0.6; // 設定最小置信度為60%
Map<ItemSet, ItemSet> directMap = new HashMap<ItemSet, ItemSet>();
for (Entry<Integer, Set<ItemSet>> entry : rst.entrySet()) {
for (ItemSet set : entry.getValue())
directMap.put(set, set);
}
// 根據頻繁項集構造關聯規則
System.out.println();
System.out.println("Association Rules:");
for (Entry<Integer, Set<ItemSet>> entry : rst.entrySet()) {
for (ItemSet set : entry.getValue()) {
double cnt1 = directMap.get(set).frequence;
List<ItemSet> subSets = set.listNotEmptySubItemSets();
for (ItemSet subSet : subSets) {
int cnt2 = directMap.get(subSet).frequence;
double conf = cnt1 / cnt2;
if (cnt1 / cnt2 >= MCONF) {
ItemSet remainSet = new ItemSet();
remainSet.addAll(set);
remainSet.removeAll(subSet);
System.out.printf("%s => %s, %.2f\n", subSet,
remainSet, conf);
}
}
}
}
}
/**
* 查詢事務集中的所有頻繁項集,返回Map為:L -> 所有頻繁L項集的列表
*/
static Map<Integer, Set<ItemSet>> findFrequentItemSets(
Iterable<Set<String>> transIterable, int MSF) {
Map<Integer, Set<ItemSet>> ret = new TreeMap<Integer, Set<ItemSet>>();
// 首先確定頻繁1項集
Iterator<Set<String>> it = transIterable.iterator();
Set<ItemSet> oneItemSets = findFrequentOneItemSets(it, MSF);
ret.put(1, oneItemSets);
int preItemSetSize = 1;
Set<ItemSet> preItemSets = oneItemSets;
// 基於獲得的所有頻繁L-1項集迭代查詢所有頻繁L項集,直到不存在頻繁L-1項集
while (!preItemSets.isEmpty()) {
int curItemSetSize = preItemSetSize + 1;
// 獲取頻繁L項集的所有候選L項集
List<ItemSet> candidates = aprioriGenCandidates(preItemSets);
// 掃描事務集以確定所有候選L項集出現的頻次
it = transIterable.iterator();
while (it.hasNext()) {
Set<String> tran = it.next();
for (ItemSet candidate : candidates)
if (tran.containsAll(candidate))
candidate.frequence++;
}
// 將出現頻次不小於最小支援頻次的候選L項集選為頻繁L項集
Set<ItemSet> curItemSets = new HashSet<ItemSet>();
for (ItemSet candidate : candidates)
if (candidate.frequence >= MSF)
curItemSets.add(candidate);
if (!curItemSets.isEmpty())
ret.put(curItemSetSize, curItemSets);
preItemSetSize = curItemSetSize;
preItemSets = curItemSets;
}
return ret;
}
/**
* 掃描事務集以確定頻繁1項集
*/
static Set<ItemSet> findFrequentOneItemSets(Iterator<Set<String>> trans,
int MSF) {
// 掃描事務集以確定各個項出現的頻次
Map<String, Integer> frequences = new HashMap<String, Integer>();
while (trans.hasNext()) {
Set<String> tran = trans.next();
for (String item : tran) {
Integer frequence = frequences.get(item);
frequence = frequence == null ? 1 : frequence + 1;
frequences.put(item, frequence);
}
}
// 用每個出現頻次不小於最小支援頻次的項構造一個頻繁1項集
Set<ItemSet> ret = new HashSet<ItemSet>();
for (Entry<String, Integer> entry : frequences.entrySet()) {
String item = entry.getKey();
Integer frequence = entry.getValue();
if (frequence >= MSF) {
ItemSet set = new ItemSet(new String[] { item });
set.frequence = frequence;
ret.add(set);
}
}
return ret;
}
/**
* 根據所有頻繁L-1項集獲得所有頻繁L項集的候選L項集
*/
static List<ItemSet> aprioriGenCandidates(Set<ItemSet> preItemSets) {
List<ItemSet> ret = new LinkedList<ItemSet>();
// 嘗試將所有頻繁L-1項集兩兩連線然後作剪枝處理以獲得候選L項集
for (ItemSet set1 : preItemSets) {
for (ItemSet set2 : preItemSets) {
if (set1 != set2 && set1.canMakeJoin(set2)) {
// 連線
ItemSet union = new ItemSet();
union.addAll(set1);
union.add(set2.last());
// 剪枝
boolean missSubSet = false;
List<ItemSet> subItemSets = union.listDirectSubItemSets();
for (ItemSet itemSet : subItemSets) {
if (!preItemSets.contains(itemSet)) {
missSubSet = true;
break;
}
}
if (!missSubSet)
ret.add(union);
}
}
}
return ret;
}
/**
* 由多個項組成的項集,每個項是一個字串。使用TreeSet使項集中的項有序,以輔助演算法實現
*/
static class ItemSet extends TreeSet<String> {
private static final long serialVersionUID = 23883315835136949L;
int frequence; // 項集出現的頻次
public ItemSet() {
this(new String[0]);
}
public ItemSet(String[] items) {
for (String item : items)
add(item);
}
/**
* 測試本項集(假定階為L-1)能否與別一個項集連線以生成L階項集
*/
public boolean canMakeJoin(ItemSet other) {
// 若兩個項集的階不同,則不能連線生成L階項集
if (other.size() != this.size())
return false;
// 假定項集的階為L-1,在項有序的前提下,當且僅當兩個項集的前L-2個項相同
// 而本項集的第L-1個項小於另一個項集的第L-1個項時,可以連線生成L階項集
Iterator<String> it1 = this.iterator();
Iterator<String> it2 = other.iterator();
while (it1.hasNext()) {
String item1 = it1.next();
String item2 = it2.next();
int result = item1.compareTo(item2);
if (result != 0) {
if (it1.hasNext())
return false;
return result < 0 ? true : false;
}
}
return false;
}
/**
* 假定本項集的階為L,列舉本項集的所有階為L-1的子項集
*/
public List<ItemSet> listDirectSubItemSets() {
List<ItemSet> ret = new LinkedList<ItemSet>();
// 只有本項集的階大於1,才可能存在非空子項集
if (size() > 1) {
for (String rmItem : this) {
ItemSet subSet = new ItemSet();
subSet.addAll(this);
subSet.remove(rmItem);
ret.add(subSet);
}
}
return ret;
}
/**
* 列出本項集除自身外的所有非空子項集
*/
public List<ItemSet> listNotEmptySubItemSets() {
List<ItemSet> ret = new LinkedList<ItemSet>();
int size = size();
if (size > 0) {
char[] mapping = new char[size()];
initMapping(mapping);
while (nextMapping(mapping)) {
ItemSet set = new ItemSet();
Iterator<String> it = this.iterator();
for (int i = 0; i < size; i++) {
String item = it.next();
if (mapping[i] == '1')
set.add(item);
}
if (set.size() < size)
ret.add(set);
}
}
return ret;
}
private void initMapping(char[] mapping) {
for (int i = 0; i < mapping.length; i++)
mapping[i] = '0';
}
private boolean nextMapping(char[] mapping) {
int pos = 0;
while (pos < mapping.length && mapping[pos] == '1') {
mapping[pos] = '0';
pos++;
}
if (pos < mapping.length) {
mapping[pos] = '1';
return true;
}
return false;
}
}
} 相關文章
- Apriori演算法演算法
- Apriori演算法原理總結演算法
- Apriori演算法的介紹演算法
- 第十四篇:Apriori 關聯分析演算法原理分析與程式碼實現演算法
- 關聯分析(二)--Apriori演算法演算法
- 機器學習系列文章:Apriori關聯規則分析演算法原理分析與程式碼實現機器學習演算法
- 關聯規則方法之apriori演算法演算法
- 使用apriori演算法進行關聯分析演算法
- 關聯規則挖掘(二)-- Apriori 演算法演算法
- 關聯規則挖掘之apriori演算法演算法
- 模式識別中的Apriori演算法和FPGrowth演算法模式演算法
- 關聯分析Apriori演算法和FP-growth演算法初探演算法
- Apriori 演算法-如何進行關聯規則挖掘演算法
- 關聯規則挖掘:Apriori演算法的深度探討演算法
- 資料探勘十大演算法之Apriori詳解演算法
- 關聯規則apriori演算法的python實現演算法Python
- 關聯規則分析 Apriori 演算法 簡介與入門演算法
- 25道經典Java演算法題(含程式碼)Java演算法
- 基於Apriori關聯規則的電影推薦系統(附python程式碼)Python
- K-Means演算法的程式碼實現(Java)演算法Java
- 負載均衡的幾種演算法Java實現程式碼負載演算法Java
- 多種負載均衡演算法及其Java程式碼實現負載演算法Java
- 多種負載均衡演算法及其 Java 程式碼實現負載演算法Java
- 菜市場價格分析 python pandas Apriori演算法 資料預處理Python演算法
- JNI:Java程式碼呼叫原生程式碼Java
- 演算法案例2-求冰雹數 java程式碼實現演算法Java
- java 程式碼塊Java
- 從 Java 程式碼到 Java 堆Java
- Java學習之7種排序演算法的完整例項程式碼Java排序演算法
- JAVA的六大經典演算法,程式碼案例簡化分析Java演算法
- Java NIO 程式碼示例Java
- Java程式碼建議Java
- java 程式碼格式(轉)Java
- Java程式碼優化Java優化
- Java - 26 程式碼塊Java
- java SPI 程式碼示例Java
- 十大經典排序演算法動畫解析和 Java 程式碼實現排序演算法動畫Java
- 幾種簡單的負載均衡演算法及其Java程式碼實現負載演算法Java