【BAT(百度,阿里,騰迅)面試題】
轉載的 有時間好好看下
【常見面試問題總結目錄>>>】
114、java中實現多型的機制是什麼
答:重寫,過載。方法的重寫Overriding和過載Overloading是Java多型性的不同表現。
重寫Overriding是父類與子類之間多型性的一種表現,過載Overloading是一個類中多型性的一種表現。如果在子類中定義某方法與其父類有相同的名稱和引數,我們說該方法被重寫 (Overriding)。子類的物件使用這個方法時,將呼叫子類中的定義,對它而言,父類中的定義如同被”遮蔽”了。
如果在一個類中定義了多個同名的方法,它們或有不同的引數個數或有不同的引數型別,則稱為方法的過載(Overloading)。Overloaded的方法是可以改變返回值的型別。
115、靜態的多型和動態的多型的區別
答:靜態的多型: 即為過載 ;方法名相同,引數個數或型別不相同。(overloading)。動態的多型: 即為重寫;子類覆蓋父類的方法,將子類的例項傳與父類的引用呼叫的是子類的方法 實現介面的例項傳與介面的引用呼叫的實現類的方法。
116、extends和implement的不同
答:extends是繼承父類,只要那個類不是宣告為final或者那個類定義為abstract的就能繼承,JAVA中不支援多重繼承,但是可以用介面來實現,這樣就要用到implements,繼承只能繼承一個類,但implements可以實現多個介面,用逗號分開就行了,比如 class A extends B implements C,D,E。
117、介面卡模式與橋樑模式的區別
答:介面卡模式把一個類的介面變換成客戶端所期待的另一種介面,從而使原本因介面不匹配而無法在一起工作的兩個類能夠在一起工作。又稱為轉換器模式、變壓器模式、包裝模式(把已有的一些類包裝起來,使之能有滿足需要的介面)。介面卡模式的用意是將介面不同而功能相同或者相近的兩個介面加以轉換,包括介面卡角色補充一些源角色沒有但目標介面需要的方法。就像生活中電器插頭是三相的,而電源插座是兩相的,這時需要一個三相變兩相的轉換器來滿足。
比如,在Java I/O庫中使用了介面卡模式,象FileInputStream是一個介面卡類,其繼承了InputStrem型別,同時持有一個對FileDiscriptor的引用。這是將一個FileDiscriptor物件適配成InputStrem型別的物件形式的介面卡模式。StringReader是一個介面卡類,其繼承了Reader型別,持有一個對String物件的引用。它將String的介面適配成Reader型別的介面。等等。
橋樑模式的用意是要把實現和它的介面分開,以便它們可以獨立地變化。橋樑模式並不是用來把一個已有的物件接到不相匹配的介面上的。當一個客戶端只知道一個特定的介面,但是又必須與具有不同介面的類打交道時,就應該使用橋樑模式。
比如,JDBC驅動器就是一個橋樑模式的應用,使用驅動程式的應用系統就是抽象化角色,而驅動器本身扮演實現化角色。應用系統和JDBC驅動器是相對獨立的。應用系統動態地選擇一個合適的驅動器,然後通過驅動器向資料庫引擎發出指令就可以訪問資料庫中的資料。
118、抽象類能否被例項化 ?抽象類的作用是什麼?
答:抽象類不能被例項化;抽象類通常不是由程式設計師定義的,而是由專案經理或模組設計人設計抽象類的原因通常是為了規範方法名 抽象類必須要繼承,不然沒法用,作為模組設計者,可以把讓底層程式設計師直接用得方法直接呼叫,而一些需要讓程式設計師覆蓋後自己做得方法則定義稱抽象方法。
120、String,StringBuffer, StringBuilder 的區別是什麼?String為什麼是不可變的?
答:
1、String是字串常量,StringBuffer和StringBuilder都是字串變數。後兩者的字元內容可變,而前者建立後內容不可變。
2、String不可變是因為在JDK中String類被宣告為一個final類。
3、StringBuffer是執行緒安全的,而StringBuilder是非執行緒安全的。
ps:執行緒安全會帶來額外的系統開銷,所以StringBuilder的效率比StringBuffer高。如果對系統中的執行緒是否安全很掌握,可用StringBuffer,線上程不安全處加上關鍵字Synchronize。
121、Vector,ArrayList, LinkedList的區別是什麼?
答:
1、Vector、ArrayList都是以類似陣列的形式儲存在記憶體中,LinkedList則以連結串列的形式進行儲存。
2、List中的元素有序、允許有重複的元素,Set中的元素無序、不允許有重複元素。(TreeSet 是二差樹實現的,Treeset中的資料是自動排好序的,不允許放入null值,HashSet 是雜湊表實現的,HashSet中的資料是無序的,可以放入null,但只能放入一個null,兩者中的值都不能重複)
3、Vector執行緒同步,ArrayList、LinkedList執行緒不同步。
4、LinkedList適合指定位置插入、刪除操作,不適合查詢;ArrayList、Vector適合查詢,不適合指定位置的插入、刪除操作。
5、ArrayList在元素填滿容器時會自動擴充容器大小的0.5n+1,而Vector則是2n,因此ArrayList更節省空間。
122、HashTable, HashMap,TreeMap區別?
答:
1、HashTable執行緒同步,HashMap非執行緒同步。
2、HashTable不允許<鍵,值>有空值,HashMap允許<鍵,值>有空值。
3、HashTable使用Enumeration,HashMap使用Iterator。
4、HashTable中hash陣列的預設大小是11,增加方式的old*2+1,HashMap中hash陣列的預設大小是16,增長方式一定是2的指數倍。
5、TreeMap能夠把它儲存的記錄根據鍵排序,預設是按升序排序。
123、Tomcat,Apache,JBoss,Weblogic的區別?
答:
Apache:全球應用最廣泛的http伺服器,免費,出自apache基金組織
Tomcat:應用也算非常廣泛的web伺服器,支援部分j2ee,免費,出自apache基金組織
JBoss:開源的應用伺服器,比較受人喜愛,免費(文件要收費)
Weblogic:應該說算是業界第一的app server,全部支援j2ee1.4,對於開發者,有免費使用一年的許可證。
124、GET,POST區別?
答:基礎知識:Http的請求格式如下。
- 1
- 2
- 3
- 4
區別:
1、Get是從伺服器端獲取資料,Post則是向伺服器端傳送資料。
2、在客戶端,Get方式通過URL提交資料,在URL位址列可以看到請求訊息,該訊息被編碼過;Post資料則是放在Html header內提交。
3、對於Get方式,伺服器端用Request.QueryString獲取變數的值;對用Post方式,伺服器端用Request.Form獲取提交的資料值。
4、Get方式提交的資料最多1024位元組,而Post則沒有限制。
5、Get方式提交的引數及引數值會在位址列顯示,不安全,而Post不會,比較安全。
125、Session, Cookie區別
答:
1、Session由應用伺服器維護的一個伺服器端的儲存空間;Cookie是客戶端的儲存空間,由瀏覽器維護。
2、使用者可以通過瀏覽器設定決定是否儲存Cookie,而不能決定是否儲存Session,因為Session是由伺服器端維護的。
3、Session中儲存的是物件,Cookie中儲存的是字串。
4、Session和Cookie不能跨視窗使用,每開啟一個瀏覽器系統會賦予一個SessionID,此時的SessionID不同,若要完成跨瀏覽器訪問資料,可以使用Application。
5、Session、Cookie都有失效時間,過期後會自動刪除,減少系統開銷。
126、Servlet的生命週期
答:大致分為4部:Servlet類載入–>例項化–>服務–>銷燬
1、Web Client向Servlet容器(Tomcat)發出Http請求。
2、Servlet容器接收Client端的請求。
3、Servlet容器建立一個HttpRequest物件,將Client的請求資訊封裝到這個物件中。
4、Servlet建立一個HttpResponse物件。
5、Servlet呼叫HttpServlet物件的service方法,把HttpRequest物件和HttpResponse物件作為引數傳遞給HttpServlet物件中。
6、HttpServlet呼叫HttpRequest物件的方法,獲取Http請求,並進行相應處理。
7、處理完成HttpServlet呼叫HttpResponse物件的方法,返回響應資料。
8、Servlet容器把HttpServlet的響應結果傳回客戶端。
其中的3個方法說明了Servlet的生命週期:
1、init():負責初始化Servlet物件。
2、service():負責響應客戶端請求。
3、destroy():當Servlet物件推出時,負責釋放佔用資源。
127、HTTP 報文包含內容
答:主要包含四部分:
1、request line
2、header line
3、blank line
4、request body
128、Statement與PreparedStatement的區別,什麼是SQL隱碼攻擊,如何防止SQL隱碼攻擊
答:
1、PreparedStatement支援動態設定引數,Statement不支援。
2、PreparedStatement可避免如類似 單引號 的編碼麻煩,Statement不可以。
3、PreparedStatement支援預編譯,Statement不支援。
4、在sql語句出錯時PreparedStatement不易檢查,而Statement則更便於查錯。
5、PreparedStatement可防止Sql注入,更加安全,而Statement不行。
什麼是SQL隱碼攻擊:
通過sql語句的拼接達到無引數查詢資料庫資料目的的方法。
如將要執行的sql語句為 select * from table where name = “+appName+”,利用appName引數值的輸入,來生成惡意的sql語句,如將[‘or’1’=’1’] 傳入可在資料庫中執行。
因此可以採用PrepareStatement來避免Sql注入,在伺服器端接收引數資料後,進行驗證,此時PrepareStatement會自動檢測,而Statement不 行,需要手工檢測。
129、sendRedirect, foward區別
答:轉發是伺服器行為,重定向是客戶端行為。
轉發過程:客戶瀏覽器傳送http請求->web伺服器接受此請求->呼叫內部的一個方法在容器內部完成請求處理和轉發動作->將目標資源 傳送給客戶;在這裡,轉發的路徑必須是同一個web容器下的url,其不能轉向到其他的web路徑上去,中間傳遞的是自己的容器內的request。在客戶瀏覽器路徑欄顯示的仍然是其第一次訪問的路徑,也就是說客戶是感覺不到伺服器做了轉發的。轉發行為是瀏覽器只做了一次訪問請求。
重定向過程:客戶瀏覽器傳送http請求->web伺服器接受後傳送302狀態碼響應及對應新的location給客戶瀏覽器->客戶瀏覽器發現 是302響應,則自動再傳送一個新的http請求,請求url是新的location地址->伺服器根據此請求尋找資源併傳送給客戶。在這裡location可以重定向到任意URL,既然是瀏覽器重新發出了請求,則就沒有什麼request傳遞的概念了。在客戶瀏覽器路徑欄顯示的是其重定向的 路徑,客戶可以觀察到地址的變化的。重定向行為是瀏覽器做了至少兩次的訪問請求的。
130、反射講一講,主要是概念,都在哪需要反射機制,反射的效能,如何優化
答:反射機制的定義:是在執行狀態中,對於任意的一個類,都能夠知道這個類的所有屬性和方法,對任意一個物件都能夠通過反射機制呼叫一個類的任意方法,這種動態獲取類資訊及動態呼叫類物件方法的功能稱為java的反射機制。
反射的作用:
1、動態地建立類的例項,將類繫結到現有的物件中,或從現有的物件中獲取型別。
2、應用程式需要在執行時從某個特定的程式集中載入一個特定的類
131、關於Cache(Ehcache,Memcached)
http://xuezhongfeicn.blog.163.com/blog/static/2246014120106144143737/
133、畫出最熟悉的三個設計模式的類圖
134、寫程式碼分別使得JVM的堆、棧和持久代發生記憶體溢位(棧溢位)
一個死迴圈 遞迴呼叫就 可以棧溢位。建好多物件例項放入ArrayList裡可以堆溢位。持久代溢位可以新建很多 ClassLoader 來裝載同一個類檔案。
因為方法區是儲存類的相關資訊的,所以當我們載入過多的類時就會導致方法區溢位。CGLIB同樣會快取代理類的Class物件,但是我們可以通過配置讓它不快取Class物件,這樣就可以通過反覆建立代理類達到使方法區溢位的目的。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
堆溢位比較簡單,只需通過建立一個大陣列物件來申請一塊比較大的記憶體,就可以使堆發生溢位。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
棧溢位也比較常見,有時我們編寫的遞迴呼叫沒有正確的終止條件時,就會使方法不斷遞迴,棧的深度不斷增大,最終發生棧溢位。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
135、hashmap的內部實現機制,hash是怎樣實現的,什麼時候rehash
136、java的記憶體管理
137、分散式快取的記憶體管理,如何管理和釋放不斷膨脹的session,memcache是否熟悉
138、oralce的底層管理(怎樣讓查詢快,插入慢)
139、java底層是怎樣對檔案操作的
140、研究了哪些框架的原始碼
141、併發問題,鎖,怎麼處理死鎖,髒資料處理
141、效能問題
142、equals和hashcode這些方法怎麼使用的
143、java的NIO
http://lvwenwen.iteye.com/blog/1706221
144、先從專案模組入手,詳細問專案模組是怎麼實現的,遇到的問題怎麼解決(一定要說自己做過的,真實的情況)
145、sql語句優化怎麼做的,建索引的時候要考慮什麼
146、spring ioc你的理解,ioc容器啟動的過程是什麼樣的,什麼是ioc,aop 你個人的理解是什麼
147、jms 你個人的理解,就是訊息接收完怎麼處理,介質處理(為什麼重啟mq就能恢復)
解答:http://setting.iteye.com/blog/1097767
148、sychronized 機制 加了static 方法的同步異同,A 呼叫 B,A執行完了,B沒執行完,怎麼解決這個同步問題
149、servlet 預設是執行緒安全的嗎,為什麼不是執行緒安全的
解答:不是 :url:http://westlifesz.iteye.com/blog/49511
http://jsjxqjy.iteye.com/blog/1563249
http://developer.51cto.com/art/200907/133827.htm
150、spring裡面的action 預設是單列的,怎麼配置成多列?
socpe =proptype?
151、socket 是用的什麼協議,tcp協議連線(握手)的過程是什麼樣的,socket使用要注意哪些問題
解答:tcp協議,
152、資料庫連線池設定幾個連線,是怎麼處理的,說說你的理解
153、自定義異常要怎麼考慮呢,checked的異常跟 unchecked 的異常的區別
154、執行緒池是怎麼配置的,怎麼用的,要注意哪些,說下個人的理解
155、tomact 裡session共享是怎麼做到的,
解答:http://zhli986-yahoo-cn.iteye.com/blog/1344694
156、伺服器叢集有搭建過嗎
解答:http://www.iteye.com/topic/1119823
157、阿里B2B北京專場java開發面試題(2011.10.29)
http://yueyemaitian.iteye.com/blog/1387901
jvm的體系結構,畫了之後說各個部分的職責,並扯到執行期優化。
158、檔案拷貝,把一個檔案的內容拷貝到另外一個檔案裡
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
159、HashMap遍歷的幾種方法
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
160、寫一個類,連線資料庫並執行一條sql
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
161、JVM效能調優,都做了什麼?
答:
1).控制GC的行為。GC是一個後臺處理,但是它也是會消耗系統效能的,因此經常會根據系統執行的程式的特性來更改GC行為
2).控制JVM堆疊大小。一般來說,JVM在記憶體分配上不需要你修改,(舉例)但是當你的程式新生代物件在某個時間段產生的比較多的時候,就需要控制新生代的堆大小.同時,還要需要控制總的JVM大小避免記憶體溢位。
3).控制JVM執行緒的記憶體分配。如果是多執行緒程式,產生執行緒和執行緒執行所消耗的記憶體也是可以控制的,需要通過一定時間的觀測後,配置最優結果。
162、TCP頭部都什麼內容
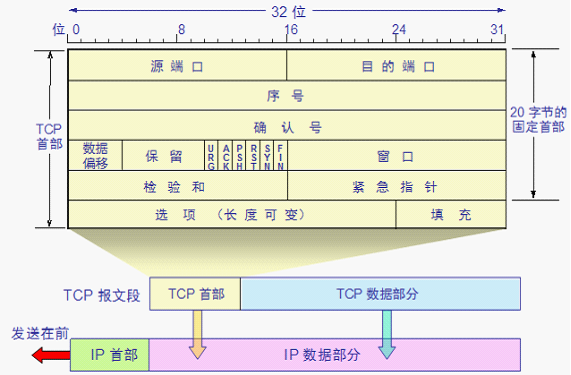
源埠和目的埠:各佔2位元組.埠是傳輸層與應用層的服務介面.傳輸層的複用和分用功能都要通過埠才能實現。
序號:佔4位元組.TCP 連線中傳送的資料流中的每一個位元組都編上一個序號.序號欄位的值則指的是本報文段所傳送的資料的第一個位元組的序號
確認號:佔 4 位元組,是期望收到對方的下一個報文段的資料的第一個位元組的序號
資料偏移/首部長度:佔4位,它指出 TCP 報文段的資料起始處距離 TCP 報文段的起始處有多遠.“資料偏移”的單位是32位字(以 4 位元組為計算單位)
保留:佔6位,保留為今後使用,但目前應置為0
緊急URG:當 URG=1 時,表明緊急指標欄位有效.它告訴系統此報文段中有緊急資料,應儘快傳送(相當於高優先順序的資料)
確認ACK:只有當 ACK=1 時確認號欄位才有效.當 ACK=0 時,確認號無效
PSH(PuSH):接收 TCP 收到 PSH = 1 的報文段,就儘快地交付接收應用程式,而不再等到整個快取都填滿了後再向上交付。
RST (ReSeT):當 RST=1 時,表明 TCP 連線中出現嚴重差錯(如由於主機崩潰或其他原因),必須釋放連線,然後再重新建立運輸連線。
同步 SYN:同步 SYN = 1 表示這是一個連線請求或連線接受報文
終止 FIN:用來釋放一個連線.FIN=1 表明此報文段的傳送端的資料已傳送完畢,並要求釋放運輸連線
檢驗和:佔 2 位元組.檢驗和欄位檢驗的範圍包括首部和資料這兩部分.在計算檢驗和時,要在 TCP 報文段的前面加上 12 位元組的偽首部
緊急指標:佔 16 位,指出在本報文段中緊急資料共有多少個位元組(緊急資料放在本報文段資料的最前面)
選項:長度可變.TCP 最初只規定了一種選項,即最大報文段長度 MSS.MSS 告訴對方 TCP:“我的快取所能接收的報文段的資料欄位的最大長度是 MSS 個位元組.” [MSS(Maximum Segment Size)是 TCP 報文段中的資料欄位的最大長度.資料欄位加上 TCP 首部才等於整個的 TCP 報文段]
填充:這是為了使整個首部長度是4 位元組的整數倍
其他選項:
視窗擴大:佔3位元組,其中有一個位元組表示移位值 S.新的視窗值等於TCP 首部中的視窗位數增大到(16 + S),相當於把視窗值向左移動 S 位後獲得實際的視窗大小
時間戳:佔10 位元組,其中最主要的欄位時間戳值欄位(4位元組)和時間戳回送回答欄位(4位元組)
選擇確認:接收方收到了和前面的位元組流不連續的兩2位元組.如果這些位元組的序號都在接收視窗之內,那麼接收方就先收下這些資料,但要把這些資訊準確地告訴傳送方,使傳送方不要再重複傳送這些已收到的資料
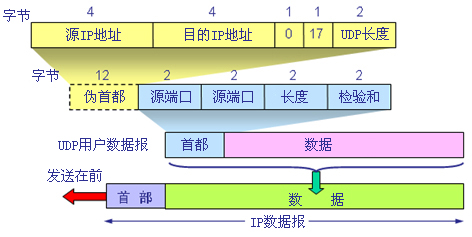
163、DUP報文結構
164、HTTP報文結構
HTTP請求報文:一個HTTP請求報文由請求行(request line)、請求頭部(header)、空行和請求資料4個部分組成。
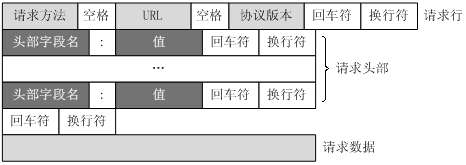
or
- 1
- 2
- 3
- 4
請求行:請求行由請求方法欄位、URL欄位和HTTP協議版本欄位3個欄位組成,它們用空格分隔。
請求頭部:請求頭部由關鍵字/值對組成,每行一對,關鍵字和值用英文冒號“:”分隔。請求頭部通知伺服器有關於客戶端請求的資訊,典型的請求頭有:
- User-Agent:產生請求的瀏覽器型別。
- Accept:客戶端可識別的內容型別列表。
- Host:請求的主機名,允許多個域名同處一個IP地址,即虛擬主機。
- 空行:最後一個請求頭之後是一個空行,傳送回車符和換行符,通知伺服器以下不再有請求頭。
請求資料:請求資料不在GET方法中使用,而是在POST方法中使用。POST方法適用於需要客戶填寫表單的場合。與請求資料相關的最常使用的請求頭是Content-Type和Content-Length。
HTTP響應報文:HTTP響應由四個部分組成,分別是:狀態行、訊息報頭、空行和響應正文。
- 1
- 2
- 3
- 4
狀態行格式如下:HTTP-Version Status-Code Reason-Phrase CRLF
HTTP-Version表示伺服器HTTP協議的版本;
Status-Code表示伺服器發回的響應狀態程式碼;
Reason-Phrase表示狀態程式碼的文字描述。
CRLF表示換行
狀態程式碼由三位數字組成,第一個數字定義了響應的類別,且有五種可能取值。
1xx:指示資訊–表示請求已接收,繼續處理。
2xx:成功–表示請求已被成功接收、理解、接受。
3xx:重定向–要完成請求必須進行更進一步的操作。
4xx:客戶端錯誤–請求有語法錯誤或請求無法實現。
5xx:伺服器端錯誤–伺服器未能實現合法的請求。
常見狀態程式碼、狀態描述的說明如下。
200 OK:客戶端請求成功。
400 Bad Request:客戶端請求有語法錯誤,不能被伺服器所理解。
401 Unauthorized:請求未經授權,這個狀態程式碼必須和WWW-Authenticate報頭域一起使用。
403 Forbidden:伺服器收到請求,但是拒絕提供服務。
404 Not Found:請求資源不存在,舉個例子:輸入了錯誤的URL。
500 Internal Server Error:伺服器發生不可預期的錯誤。
503 Server Unavailable:伺服器當前不能處理客戶端的請求,一段時間後可能恢復正常,舉個例子:HTTP/1.1 200 OK(CRLF)。
165、TCP協議和UDP協議的區別
1,TCP協議面向連線,UDP協議面向非連線
2,TCP協議傳輸速度慢,UDP協議傳輸速度快
3,TCP協議保證資料順序,UDP協議不保證
4,TCP協議保證資料正確性,UDP協議可能丟包
5,TCP協議對系統資源要求多,UDP協議要求少
166、java物件在虛擬機器中怎樣例項化。
首先判斷物件例項化的型別資訊是否已經在JVM,如果不存在就對型別資訊進行裝載、連線和初始化,之後就可以使用了,可以訪問型別的靜態欄位和方法,最後再建立型別例項,為例項物件分配記憶體空間。物件的建立分為顯示建立和隱式建立兩種。
顯示建立分為:
1、通過new建立;
2、通過java.lang.Class的newInstance方法建立;
3、通過clone方法建立;
4、通過java.io.ObjectInputStream的readObject方法建立。
隱式建立分為:
1、啟動類的main方法的string陣列引數;
2、常量池的CONSTANT_String_info表項被解析的時候會建立一個String物件;
3、每個載入的類都會建立一個java.lang.Class物件;
4、字串+操作的時候,建立StringBuffer/StringBuilder物件。
物件在記憶體中的儲存
非嚴格意義來說,物件都儲存在堆上,由垃圾收集器負責回收不再被引用的物件。但是隨著jvm執行期編譯技術的不斷進步,棧上分配物件和標量替換技術使得非逃逸物件可以分配在棧上。當然絕大多數物件都是分配在堆上的,此處我們主要討論物件在堆中的儲存。
物件的內容有:
1、例項資料;
2、指向堆中型別資訊的指標;
3、物件鎖相關的資料;
4、多執行緒協調完成同一件事情的時候wait set相關的佇列;
5、垃圾收集相關的內容,如存活時間、finalize方法是否執行過。
物件在記憶體中儲存主要有兩種方式:
1、堆劃分為控制程式碼池和物件池,建立物件後的得到的引用是指向控制程式碼池的指標,控制程式碼池指標則指向物件池裡的物件;
2、堆只分為物件池,引用直接指向物件池中的物件。
167、java連線池中連線如何收縮?
Java連線池中一般都有設定最大、最小連線數,當連線池中的連線達到最大連線數時,就不會再建立新的連線。一般來說定時檢測連線池中空閒連線數,當超過一定時間沒有使用的話,先判斷現有連線池中的連線是否大於最小連線數,如果大於的話,就好回收這個空閒連線,否則的話,就不會進行回收。
如何確保連線池中的最小連線數呢?有動態和靜態兩種策略。動態即每隔一定時間就對連線池進行檢測,如果發現連線數量小於最小連線數,則補充相應數量的新連線,以保證連線池的正常運轉。靜態是發現空閒連線不夠時再去檢查。

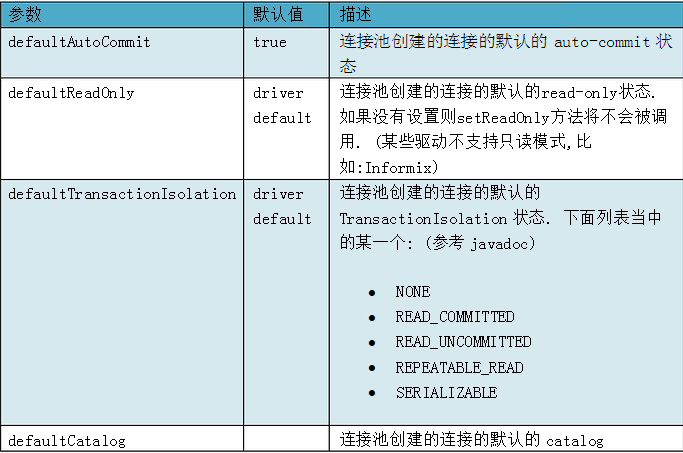
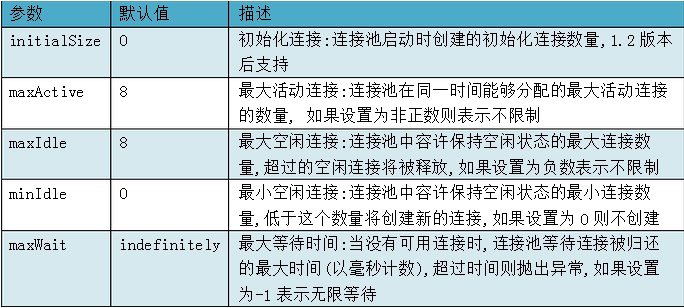
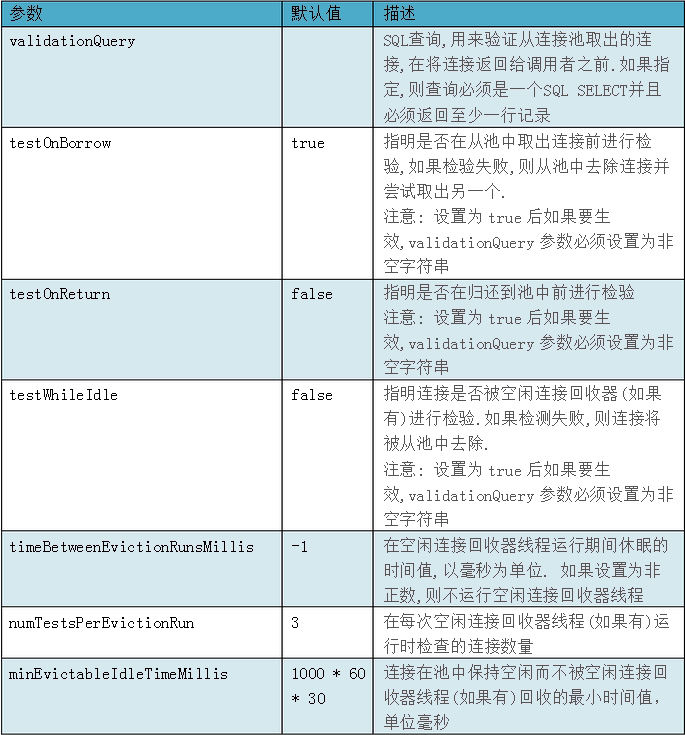
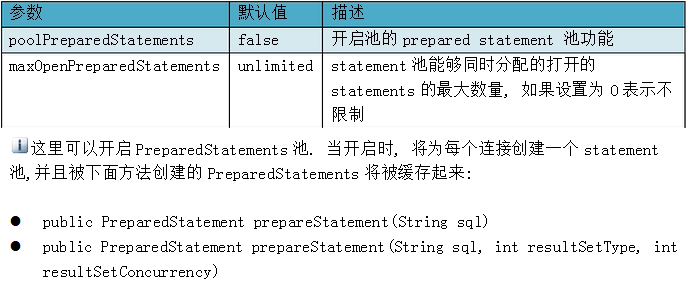

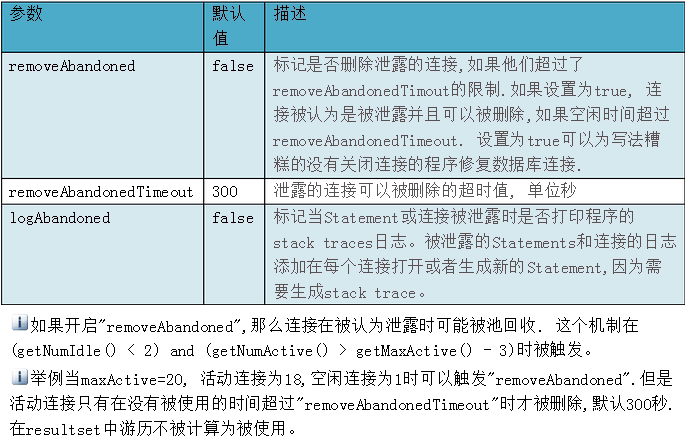
上面就是連線池的配置資訊
168、Java多執行緒問題
有如下一個類:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
問題: 這段程式碼大多數情況下執行正常,但是某些情況下會出問題。什麼時候會出現什麼問題?如何修正?
程式碼分析:
從整體上,在併發狀態下,push和pop都使用了synchronized的鎖,來實現同步,同步的資料物件是基於List的資料;大部分情況下是可以正常工作的。
問題描述:
狀況1:
1. 假設有三個執行緒: A,B,C. A 負責放入資料到list,就是呼叫push操作, B,C分別執行Pop操作,移除資料。
2. 首先B先執行,於pop中的wait()方法處,進入waiting狀態,進入等待佇列,釋放鎖。
3. A首先執行放入資料push操作到List,在呼叫notify()之前; 同時C執行pop(),由於synchronized,被阻塞,進入Blocked狀態,放入基於鎖的等待佇列。注意,這裡的佇列和2中的waiting等待佇列是兩個不同的佇列。
4. A執行緒呼叫notify(),喚醒等待中的執行緒A。
5. 如果此時, C獲取到基於物件的鎖,則優先執行,執行pop方法,獲取資料,從list移除一個元素。
6. 然後,A獲取到競爭鎖,A中呼叫list.remove(list.size() - 1),則會報資料越界exception。
狀況2:
1. 相同於狀況1
2. B、C都處於等待waiting狀態,釋放鎖。等待notify()、notifyAll()操作的喚醒。
3. 存在被虛假喚醒的可能。
何為虛假喚醒?
虛假喚醒就是一些obj.wait()會在除了obj.notify()和obj.notifyAll()的其他情況被喚醒,而此時是不應該喚醒的。
解決的辦法是基於while來反覆判斷進入正常操作的臨界條件是否滿足:
- 1
- 2
- 3
- 4
- 5
如何修復問題?
1. 使用可同步的資料結構來存放資料,比如LinkedBlockingQueue之類。由這些同步的資料結構來完成繁瑣的同步操作。
2. 雙層的synchronized使用沒有意義,保留外層即可。
3. 將if替換為while,解決虛假喚醒的問題。
168、super.getClass方法呼叫
先看一下程式的程式碼,看看最後的輸出結果是多少?
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
如果不瞭解,很可能得出錯誤的答案,其實答案是Test,是不是很奇怪,結果竟然是Test。
這道題就屬於腦筋急轉彎的題目,很簡單的,也很容易落入陷阱中。我想大部分人之所以落入陷阱中可能是因為這個類繼承了。
如果在test方法中,直接呼叫getClass().getName()方法的化,相當於呼叫this.getClass().getName(),這樣返回的就是Test類名,getClass()返回物件執行時的位元組碼物件,當前物件是Test的例項,所以其位元組碼物件就是Test
由於getClass()在Object類中定義成了final,子類不能覆蓋該方法,所以,Date類也是沒有這個方法的,在test方法中呼叫getClass().getName()方法,其實就是在呼叫從父類繼承的getClass()方法,等效於呼叫super.getClass().getName()方法,所以,super.getClass().getName()方法返回的也應該是Test。
如果想得到父類的名稱,應該用如下程式碼:
getClass().getSuperClass().getName();
169、B樹,B+樹,B*樹
170、知道哪些鎖機制?(不限JAVA)什麼是可重入性? synchronized的可重入性?顯式鎖跟synchronized對比?semaphore機制怎麼實現?一個執行緒從wait()狀態醒來是不是一定被notify()了?
171、什麼情景下應用過TreeMap?TreeMap內部怎麼實現的?
TreeMap 是一個有序的key-value集合,它是通過紅黑樹實現的。
TreeMap 繼承於AbstractMap,所以它是一個Map,即一個key-value集合。
TreeMap 實現了NavigableMap介面,意味著它支援一系列的導航方法。比如返回有序的key集合。
TreeMap 實現了Cloneable介面,意味著它能被克隆。
TreeMap 實現了java.io.Serializable介面,意味著它支援序列化。
TreeMap基於紅黑樹(Red-Black tree)實現。該對映根據其鍵的自然順序進行排序,或者根據建立對映時提供的 Comparator 進行排序,具體取決於使用的構造方法。
TreeMap的基本操作 containsKey、get、put 和 remove 的時間複雜度是 log(n) 。
另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fast的。
178、Java網路程式設計,socket描述什麼的?同一埠可否同時被兩個應用監聽?
Socket通常也稱作”套接字”,用於描述IP地址和埠,是一個通訊鏈的控制程式碼。網路上的兩個程式通過一個雙向的通訊連線實現資料的交換,這個雙向鏈路的一端稱為一個Socket,一個Socket由一個IP地址和一個埠號唯一確定。應用程式通常通過”套接字”向網路發出請求或者應答網路請求。 Socket是TCP/IP協議的一個十分流行的程式設計介面,但是,Socket所支援的協議種類也不光TCP/IP一種,因此兩者之間是沒有必然聯絡的。在Java環境下,Socket程式設計主要是指基於TCP/IP協議的網路程式設計。
Socket通訊過程:服務端監聽某個埠是否有連線請求,客戶端向服務端傳送連線請求,服務端收到連線請求向客戶端發出接收訊息,這樣一個連線就建立起來了。客戶端和服務端都可以相互傳送訊息與對方進行通訊。
Socket的基本工作過程包含以下四個步驟:
1、建立Socket;
2、開啟連線到Socket的輸入輸出流;
3、按照一定的協議對Socket進行讀寫操作;
4、關閉Socket。
在java.net包下有兩個類:Socket和ServerSocket。ServerSocket用於伺服器端,Socket是建立網路連線時使用的。在連線成功時,應用程式兩端都會產生一個Socket例項,操作這個例項,完成所需的會話。對於一個網路連線來說,套接字是平等的,並沒有差別,不因為在伺服器端或在客戶端而產生不同級別。不管是Socket還是ServerSocket它們的工作都是通過SocketImpl類及其子類完成的。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
179、在多執行緒裡面如何實現一個變數被多執行緒獨立的訪問。
1,線上程內部建立變數
2,使用threadlocal物件
180、concurrentHashMap的實現
ConcurrentHashMap允許多個修改操作併發進行,其關鍵在於使用了鎖分離技術。它使用了多個鎖來控制對hash表的不同部分進行的修改。ConcurrentHashMap內部使用段(Segment)來表示這些不同的部分,每個段其實就是一個小的hash table,它們有自己的鎖。只要多個修改操作發生在不同的段上,它們就可以併發進行。
有些方法需要跨段,比如size()和containsValue(),它們可能需要鎖定整個表而而不僅僅是某個段,這需要按順序鎖定所有段,操作完畢後,又按順序釋放所有段的鎖。這裡“按順序”是很重要的,否則極有可能出現死鎖,在ConcurrentHashMap內部,段陣列是final的,並且其成員變數實際上也是final的,但是,僅僅是將陣列宣告為final的並不保證陣列成員也是final的,這需要實現上的保證。這可以確保不會出現死鎖,因為獲得鎖的順序是固定的。
ConcurrentHashMap 類中包含兩個靜態內部類 HashEntry 和 Segment。HashEntry 用來封裝對映表的鍵 / 值對;Segment 用來充當鎖的角色,每個 Segment 物件守護整個雜湊對映表的若干個桶。每個桶是由若干個 HashEntry 物件連結起來的連結串列。一個 ConcurrentHashMap 例項中包含由若干個 Segment 物件組成的陣列。
HashEntry 用來封裝雜湊對映表中的鍵值對。在 HashEntry 類中,key,hash 和 next 域都被宣告為 final 型,value 域被宣告為 volatile 型。同時,HashEntry 類的 value 域被宣告為 Volatile 型,Java 的記憶體模型可以保證:某個寫執行緒對 value 域的寫入馬上可以被後續的某個讀執行緒“看”到。在 ConcurrentHashMap 中,不允許用 unll 作為鍵和值,當讀執行緒讀到某個 HashEntry 的 value 域的值為 null
時,便知道產生了衝突——發生了重排序現象,需要加鎖後重新讀入這個 value 值。這些特性互相配合,使得讀執行緒即使在不加鎖狀態下,也能正確訪問 ConcurrentHashMap。
在 ConcurrentHashMap 中,在雜湊時如果產生“碰撞”,將採用“分離連結法”來處理“碰撞”:把“碰撞”的 HashEntry 物件連結成一個連結串列。由於 HashEntry 的 next 域為 final 型,所以新節點只能在連結串列的表頭處插入。
Segment 類繼承於 ReentrantLock 類,從而使得 Segment 物件能充當鎖的角色。每個 Segment 物件用來守護其(成員物件 table 中)包含的若干個桶。
避免熱點域:在 ConcurrentHashMap中,每一個 Segment 物件都有一個 count 物件來表示本 Segment 中包含的 HashEntry 物件的個數。這樣當需要更新計數器時,不用鎖定整個 ConcurrentHashMap。
ConcurrentHashMap 在預設併發級別會建立包含 16 個 Segment 物件的陣列。每個 Segment 的成員物件 table 包含若干個雜湊表的桶。每個桶是由 HashEntry 連結起來的一個連結串列。如果鍵能均勻雜湊,每個 Segment 大約守護整個雜湊表中桶總數的 1/16。
在 ConcurrentHashMap 中,執行緒對對映表做讀操作時,一般情況下不需要加鎖就可以完成,對容器做結構性修改的操作才需要加鎖。
用 Volatile 變數協調讀寫執行緒間的記憶體可見性。
ConcurrentHashMap 實現高併發的總結
基於通常情形而優化
在實際的應用中,雜湊表一般的應用場景是:除了少數插入操作和刪除操作外,絕大多數都是讀取操作,而且讀操作在大多數時候都是成功的。正是基於這個前提,ConcurrentHashMap 針對讀操作做了大量的優化。通過 HashEntry 物件的不變性和用 volatile 型變數協調執行緒間的記憶體可見性,使得大多數時候,讀操作不需要加鎖就可以正確獲得值。這個特性使得 ConcurrentHashMap 的併發效能在分離鎖的基礎上又有了近一步的提高。
總結
ConcurrentHashMap 是一個併發雜湊對映表的實現,它允許完全併發的讀取,並且支援給定數量的併發更新。相比於 HashTable 和用同步包裝器包裝的 HashMap(Collections.synchronizedMap(new HashMap())),ConcurrentHashMap 擁有更高的併發性。在 HashTable 和由同步包裝器包裝的 HashMap 中,使用一個全域性的鎖來同步不同執行緒間的併發訪問。同一時間點,只能有一個執行緒持有鎖,也就是說在同一時間點,只能有一個執行緒能訪問容器。這雖然保證多執行緒間的安全併發訪問,但同時也導致對容器的訪問變成序列化的了。
在使用鎖來協調多執行緒間併發訪問的模式下,減小對鎖的競爭可以有效提高併發性。有兩種方式可以減小對鎖的競爭:
1. 減小請求 同一個鎖的 頻率。
2. 減少持有鎖的 時間。
ConcurrentHashMap 的高併發性主要來自於三個方面:
1. 用分離鎖實現多個執行緒間的更深層次的共享訪問。
2. 用 HashEntery 物件的不變性來降低執行讀操作的執行緒在遍歷連結串列期間對加鎖的需求。
3. 通過對同一個 Volatile 變數的寫 / 讀訪問,協調不同執行緒間讀 / 寫操作的記憶體可見性。
使用分離鎖,減小了請求 同一個鎖的頻率。
通過 HashEntery 物件的不變性及對同一個 Volatile 變數的讀 / 寫來協調記憶體可見性,使得 讀操作大多數時候不需要加鎖就能成功獲取到需要的值。由於雜湊對映表在實際應用中大多數操作都是成功的 讀操作,所以 2 和 3 既可以減少請求同一個鎖的頻率,也可以有效減少持有鎖的時間。
通過減小請求同一個鎖的頻率和儘量減少持有鎖的時間 ,使得 ConcurrentHashMap 的併發性相對於 HashTable 和用同步包裝器包裝的 HashMap有了質的提高。
181、TCP長連線和短連線
當網路通訊時採用TCP協議時,在真正的讀寫操作之前,server與client之間必須建立一個連線,當讀寫操作完成後,雙方不再需要這個連線時它們可以釋放這個連線,連線的建立是需要三次握手的,而釋放則需要4次握手,所以說每個連線的建立都是需要資源消耗和時間消耗的。
TCP短連線
我們模擬一下TCP短連線的情況,client向server發起連線請求,server接到請求,然後雙方建立連線。client向server傳送訊息,server迴應client,然後一次讀寫就完成了,這時候雙方任何一個都可以發起close操作,不過一般都是client先發起close操作。為什麼呢,一般的server不會回覆完client後立即關閉連線的,當然不排除有特殊的情況。從上面的描述看,短連線一般只會在client/server間傳遞一次讀寫操作
短連線的優點是:管理起來比較簡單,存在的連線都是有用的連線,不需要額外的控制手段。
TCP長連線
接下來我們再模擬一下長連線的情況,client向server發起連線,server接受client連線,雙方建立連線。Client與server完成一次讀寫之後,它們之間的連線並不會主動關閉,後續的讀寫操作會繼續使用這個連線。
首先說一下TCP/IP詳解上講到的TCP保活功能,保活功能主要為伺服器應用提供,伺服器應用希望知道客戶主機是否崩潰,從而可以代表客戶使用資源。如果客戶已經消失,使得伺服器上保留一個半開放的連線,而伺服器又在等待來自客戶端的資料,則伺服器將永遠等待客戶端的資料,保活功能就是試圖在伺服器端檢測到這種半開放的連線。
如果一個給定的連線在兩小時內沒有任何的動作,則伺服器就向客戶發一個探測報文段,客戶主機必須處於
以下4個狀態之一:
客戶主機依然正常執行,並從伺服器可達。客戶的TCP響應正常,而伺服器也知道對方是正常的,伺服器在兩小時後將保活定時器復位。
客戶主機已經崩潰,並且關閉或者正在重新啟動。在任何一種情況下,客戶的TCP都沒有響應。服務端將不能收到對探測的響應,並在75秒後超時。伺服器總共傳送10個這樣的探測 ,每個間隔75秒。如果伺服器沒有收到一個響應,它就認為客戶主機已經關閉並終止連線。
客戶主機崩潰並已經重新啟動。伺服器將收到一個對其保活探測的響應,這個響應是一個復位,使得伺服器終止這個連線。
客戶機正常執行,但是伺服器不可達,這種情況與2類似,TCP能發現的就是沒有收到探查的響應。
從上面可以看出,TCP保活功能主要為探測長連線的存活狀況,不過這裡存在一個問題,存活功能的探測週期太長,還有就是它只是探測TCP連線的存活,屬於比較斯文的做法,遇到惡意的連線時,保活功能就不夠使了。
在長連線的應用場景下,client端一般不會主動關閉它們之間的連線,Client與server之間的連線如果一直不關閉的話,會存在一個問題,隨著客戶端連線越來越多,server早晚有扛不住的時候,這時候server端需要採取一些策略,如關閉一些長時間沒有讀寫事件發生的連線,這樣可以避免一些惡意連線導致server端服務受損;如果條件再允許就可以以客戶端機器為顆粒度,限制每個客戶端的最大長連線數,這樣可以完全避免某個蛋疼的客戶端連累後端服務。
長連線和短連線的產生在於client和server採取的關閉策略,具體的應用場景採用具體的策略,沒有十全十美的選擇,只有合適的選擇。
182、Java實現Socket長連線和短連線.
概念
Socket:socket實際上是對TCP/IP進行的封裝,我們可以使用socket套接字通過socket來傳輸。首先我們需要明白的一個概念就是通道,簡單地說通道就是兩個對端可以隨時傳輸資料的通道。我麼常說的所謂建立socket連線,也就是建立了客戶端與伺服器端的通道。
長短連線:顯而易見,長連線也就是這個socket連線一直保持連線,也就是通道一直保持通暢,兩個對端可以隨時傳送和接收資料;短連線就是我們傳送一次或有限的幾次,socket通道就被關閉了。首先,我們必須明白的是socket連線後,如果沒有任何一方關閉,這個通道是一直保持著的,換句話說,如果任何一方都不關閉連線,這個socket連線就是長連線,因此Java中的socket本身就是支援長連線的(如一個簡單的實驗:伺服器端不關閉連線,伺服器端每隔10秒傳送一次資料,伺服器端每次都能正確接受資料,這個實驗就可以證明)。
那麼既然socket本身是支援長連線的,那麼為什麼我們還要提短連線的概念呢?試想一箇中國移動的簡訊閘道器(即通過釋出socket通訊介面)每時每分都有N多個連線傳送簡訊請求,加入伺服器不加任何限制地直接和客戶端使用長連線那麼可想而知伺服器需要承受多麼大的壓力。所以一般的socket伺服器端都是會設定超時時間的,也就是timeout,如果超過timeout伺服器沒有接收到任何資料,那麼該伺服器就會關閉該連線,從而使得伺服器資源得到有效地使用。
如何實現長短連線
有了長短連線的概念,伺服器如果超過timeout時間接收不到客戶端的通訊就會斷開連線,那麼假如客戶端在timeout時間前一秒(或者更短的時間)傳送一條啟用資料來使伺服器端重新計時,如此重複就能保證伺服器一直不能進入timeout時間,從而一直保持連線,這就是長連線的實現原理。下面我們通過一張圖說明:
由上圖可見,是否是長連線完全取決於客戶端是否會在timeout時間傳送心跳訊息,因此長短連線是和客戶端相關的,伺服器端沒有任何區別(只不過伺服器端需要設定timeout而已)。
183、介面卡模式,裝飾模式,代理模式異同(介面卡模式和代理模式的區別答案在其中)。
介面卡模式,一個適配允許通常因為介面不相容而不能在一起工作的類工作在一起,做法是將類自己的介面包裹在一個已存在的類中。
裝飾器模式,原有的不能滿足現有的需求,對原有的進行增強。
代理模式,同一個類而去呼叫另一個類的方法,不對這個方法進行直接操作。
介面卡的特點在於相容,從程式碼上的特點來說,適配類與原有的類具有相同的介面,並且持有新的目標物件。就如同一個三孔轉2孔的介面卡一樣,他有三孔的插頭,可以插到三孔插座裡,又有兩孔的插座可以被2孔插頭插入。介面卡模式是在於對原有3孔的改造。在使用介面卡模式的時候,我們必須同時持有原物件,適配物件,目標物件。
裝飾器模式特點在於增強,他的特點是被裝飾類和所有的裝飾類必須實現同一個介面,而且必須持有被裝飾的物件,可以無限裝飾。
代理模式的特點在於隔離,隔離呼叫類和被呼叫類的關係,通過一個代理類去呼叫。
總的來說就是如下三句話:
1) 介面卡模式是將一個類(a)通過某種方式轉換成另一個類(b).
2) 裝飾模式是在一個原有類(a)的基礎之上增加了某些新的功能變成另一個類(b).
3) 代理模式是將一個類(a)轉換成具體的操作類(b).
184、什麼是可重入鎖
見文章
185、volatile變數的兩種特性。
可見性:volatile變數則是通過主記憶體完成交換,但是兩者區別在於volatile變數能立即同步到主記憶體中,當一個執行緒修改變數的變數的時候,立刻會被其他執行緒感知到。
阻止重排序:普通變數僅僅會保證在該方法的執行過程中所依賴複製結果的地方都能獲取到正確的結果,而不能保證變數複製操作的
順序與程式程式碼中的執行順序一致。
186、volatile變數詳解
Volatile 變數具有 synchronized 的可見性特性,但是不具備原子特性。這就是說執行緒能夠自動發現 volatile 變數的最新值。Volatile 變數可用於提供執行緒安全,但是隻能應用於非常有限的一組用例:多個變數之間或者某個變數的當前值與修改後值之間沒有約束。因此,單獨使用 volatile 還不足以實現計數器、互斥鎖或任何具有與多個變數相關的不變式(Invariants)的類(例如 “start <=end”)。此外,volatile 變數不會像鎖那樣造成執行緒阻塞,因此也很少造成可伸縮性問題。在某些情況下,如果讀操作遠遠大於寫操作,volatile 變數還可以提供優於鎖的效能優勢。
正確使用 volatile 變數的條件:
要使 volatile 變數提供理想的執行緒安全,必須同時滿足下面兩個條件:
對變數的寫操作不依賴於當前值。
該變數沒有包含在具有其他變數的不變式中。
這些條件表明,可以被寫入 volatile 變數的這些有效值獨立於任何程式的狀態,包括變數的當前狀態。
第一個條件的限制使 volatile 變數不能用作執行緒安全計數器。雖然增量操作(x++)看上去類似一個單獨操作,實際上它是一個由讀取-修改-寫入操作序列組成的組合操作,必須以原子方式執行,而 volatile 不能提供必須的原子特性。實現正確的操作需要使 x 的值在操作期間保持不變,而 volatile 變數無法實現這點。(然而,如果將值調整為只從單個執行緒寫入,那麼可以忽略第一個條件。)
使用 volatile 變數的主要原因是其簡易性:在某些情形下,使用 volatile 變數要比使用相應的鎖簡單得多。使用 volatile 變數次要原因是其效能:某些情況下,volatile 變數同步機制的效能要優於鎖。
很難做出準確、全面的評價,例如 “X 總是比 Y 快”,尤其是對 JVM 內在的操作而言。(例如,某些情況下 VM 也許能夠完全刪除鎖機制,這使得我們難以抽象地比較 volatile 和 synchronized 的開銷。)就是說,在目前大多數的處理器架構上,volatile 讀操作開銷非常低 —— 幾乎和非 volatile 讀操作一樣。而 volatile 寫操作的開銷要比非 volatile 寫操作多很多,因為要保證可見性需要實現記憶體界定(Memory Fence),即便如此,volatile 的總開銷仍然要比鎖獲取低。
volatile 操作不會像鎖一樣造成阻塞,因此,在能夠安全使用 volatile 的情況下,volatile 可以提供一些優於鎖的可伸縮特性。如果讀操作的次數要遠遠超過寫操作,與鎖相比,volatile 變數通常能夠減少同步的效能開銷。
很多併發性專家事實上往往引導使用者遠離 volatile 變數,因為使用它們要比使用鎖更加容易出錯。然而,如果謹慎地遵循一些良好定義的模式,就能夠在很多場合內安全地使用 volatile 變數。要始終牢記使用 volatile 的限制 —— 只有在狀態真正獨立於程式內其他內容時才能使用 volatile —— 這條規則能夠避免將這些模式擴充套件到不安全的用例。
187、Sesson怎麼建立和銷燬。
當客戶端發出第一個請求時(不管是被訪問網站的任何頁面)就會在此站點的服務其中開闢一塊記憶體空間,這塊記憶體就是session,session的銷燬有兩種方式,一種是session過期時間已到,會自動銷燬(注意這裡不是馬上就會銷燬,具體銷燬時間由Tomcat容器所決定)。在我們專案中的web.xml中就可以配置:
- 1
- 2
- 3
表示設定session過期時間為30分鐘。值得注意的就是上面說的即使30分鐘到了session不一定會馬上銷燬,可以通過session監聽器測試得到每次session銷燬的時間都不一樣。如果要想安全的話就用下面第二種方法。在Tomcat的conf資料夾中的web.xml中可以找到Tomcat預設的session過期時間為30分鐘。如果我們在我們的站點中配置了session過期時間Tomcat容器會以站點配置為主,如果我們沒有在站點中配置session過期時間,將會以Tomcat下conf資料夾下的web.xml檔案中配置的session過期時間為準。
第二種銷燬方式通過手工方式銷燬,這種銷燬方式會立刻釋放伺服器端session的資源,我們手動銷燬可以通過session().invalidate();實現。
188、“static”關鍵字是什麼意思?Java中是否可以覆蓋(override)一個private或者是static的方法?
“static”關鍵字表明一個成員變數或者是成員方法可以在沒有所屬的類的例項變數的情況下被訪問。Java中static方法不能被覆蓋,因為方法覆蓋是基於執行時動態繫結的,而static方法是編譯時靜態繫結的。static方法跟類的任何例項都不相關,所以概念上不適用。
189、介面和抽象類的區別是什麼?
Java提供和支援建立抽象類和介面。它們的實現有共同點,不同點在於:
1. 介面中所有的方法隱含的都是抽象的。而抽象類則可以同時包含抽象和非抽象的方法。
2. 類可以實現很多個介面,但是隻能繼承一個抽象類
3. 類如果要實現一個介面,它必須要實現介面宣告的所有方法。但是,類可以不實現抽象類宣告的所有方法,當然,在這種情況下,類也必須得宣告成是抽象的。
4. 抽象類可以在不提供介面方法實現的情況下實現介面。
5. Java介面中宣告的變數預設都是final的。抽象類可以包含非final的變數。
6. Java介面中的成員函式預設是public的。抽象類的成員函式可以是private,protected或者是public。
7. 介面是絕對抽象的,不可以被例項化。抽象類也不可以被例項化,但是,如果它包含main方法的話是可以被呼叫的。
190、在監視器(Monitor)內部,是如何做執行緒同步的?程式應該做哪種級別的同步?
監視器和鎖在Java虛擬機器中是一塊使用的。監視器監視一塊同步程式碼塊,確保一次只有一個執行緒執行同步程式碼塊。每一個監視器都和一個物件引用相關聯。執行緒在獲取鎖之前不允許執行同步程式碼。
191、如何確保N個執行緒可以訪問N個資源同時又不導致死鎖?
使用多執行緒的時候,一種非常簡單的避免死鎖的方式就是:指定獲取鎖的順序,並強制執行緒按照指定的順序獲取鎖。因此,如果所有的執行緒都是以同樣的順序加鎖和釋放鎖,就不會出現死鎖了。
192、Java集合類框架的基本介面有哪些?
Java集合類提供了一套設計良好的支援對一組物件進行操作的介面和類。Java集合類裡面最基本的介面有:
Collection:代表一組物件,每一個物件都是它的子元素。
Set:不包含重複元素的Collection。
List:有順序的collection,並且可以包含重複元素。
Map:可以把鍵(key)對映到值(value)的物件,鍵不能重複
193、為什麼集合類沒有實現Cloneable和Serializable介面?
集合類介面指定了一組叫做元素的物件。集合類介面的每一種具體的實現類都可以選擇以它自己的方式對元素進行儲存和排序。有的集合類允許重複的鍵,有些不允許。克隆(cloning)或者是序列化(serialization)的語義和含義是跟具體的實現相關的。因此,應該由集合類的具體實現來決定如何被克隆或者是序列化。
193、Iterator和ListIterator的區別是什麼?
下面列出了他們的區別:
Iterator可用來遍歷Set和List集合,但是ListIterator只能用來遍歷List。
Iterator對集合只能是前向遍歷,ListIterator既可以前向也可以後向。
ListIterator實現了Iterator介面,幷包含其他的功能,比如:增加元素,替換元素,獲取前一個和後一個元素的索引,等等
194、快速失敗(fail-fast)和安全失敗(fail-safe)的區別是什麼?
Iterator的安全失敗是基於對底層集合做拷貝,因此,它不受源集合上修改的影響。java.util包下面的所有的集合類都是快速失敗的,而java.util.concurrent包下面的所有的類都是安全失敗的。快速失敗的迭代器會丟擲ConcurrentModificationException異常,而安全失敗的迭代器永遠不會丟擲這樣的異常。
195、Java中的HashMap的工作原理是什麼?
Java中的HashMap是以鍵值對(key-value)的形式儲存元素的。HashMap需要一個hash函式,它使用hashCode()和equals()方法來向集合/從集合新增和檢索元素。當呼叫put()方法的時候,HashMap會計算key的hash值,然後把鍵值對儲存在集合中合適的索引上。如果key已經存在了,value會被更新成新值。HashMap的一些重要的特性是它的容量(capacity),負載因子(load factor)和擴容極限(threshold resizing)。
196、hashCode()和equals()方法的重要性體現在什麼地方?
Java中的HashMap使用hashCode()和equals()方法來確定鍵值對的索引,當根據鍵獲取值的時候也會用到這兩個方法。如果沒有正確的實現這兩個方法,兩個不同的鍵可能會有相同的hash值,因此,可能會被集合認為是相等的。而且,這兩個方法也用來發現重複元素。所以這兩個方法的實現對HashMap的精確性和正確性是至關重要的。當equals()方法返回true時,兩個物件必須返回相同的hashCode值,否則在HashMap中就會出錯。
197、HashMap和Hashtable有什麼區別?
HashMap和Hashtable都實現了Map介面,因此很多特性非常相似。但是,他們有以下不同點:
HashMap允許鍵和值是null,而Hashtable不允許鍵或者值是null。
Hashtable是同步的,而HashMap不是。因此,HashMap更適合於單執行緒環境,而Hashtable適合於多執行緒環境。
HashMap提供了可供應用迭代的鍵的集合,因此,HashMap是快速失敗的。另一方面,Hashtable提供了對鍵的列舉(Enumeration)。
一般認為Hashtable是一個遺留的類。
198、陣列(Array)和列表(ArrayList)有什麼區別?什麼時候應該使用Array而不是ArrayList?
下面列出了Array和ArrayList的不同點:
Array可以包含基本型別和物件型別,ArrayList只能包含物件型別。
Array大小是固定的,ArrayList的大小是動態變化的。
ArrayList提供了更多的方法和特性,比如:addAll(),removeAll(),iterator()等等。
對於基本型別資料,集合使用自動裝箱來減少編碼工作量。但是,當處理固定大小的基本資料型別的時候,這種方式相對比較慢。
199、ArrayList和LinkedList有什麼區別?
ArrayList和LinkedList都實現了List介面,他們有以下的不同點:
ArrayList是基於索引的資料介面,它的底層是陣列。它可以以O(1)時間複雜度對元素進行隨機訪問。與此對應,LinkedList是以元素列表的形式儲存它的資料,每一個元素都和它的前一個和後一個元素連結在一起,在這種情況下,查詢某個元素的時間複雜度是O(n)。
相對於ArrayList,LinkedList的插入,新增,刪除操作速度更快,因為當元素被新增到集合任意位置的時候,不需要像陣列那樣重新計算大小或者是更新索引。
LinkedList比ArrayList更佔記憶體,因為LinkedList為每一個節點儲存了兩個引用,一個指向前一個元素,一個指向下一個元素。
200、Comparable和Comparator介面是幹什麼的?列出它們的區別。
Java提供了只包含一個compareTo()方法的Comparable介面。這個方法可以個給兩個物件排序。具體來說,它返回負數,0,正數來表明輸入物件小於,等於,大於已經存在的物件。
Java提供了包含compare()和equals()兩個方法的Comparator介面。compare()方法用來給兩個輸入引數排序,返回負數,0,正數表明第一個引數是小於,等於,大於第二個引數。equals()方法需要一個物件作為引數,它用來決定輸入引數是否和comparator相等。只有當輸入引數也是一個comparator並且輸入引數和當前comparator的排序結果是相同的時候,這個方法才返回true。
201、什麼是Java優先順序佇列(Priority Queue)?
PriorityQueue是一個基於優先順序堆的無界佇列,它的元素是按照自然順序(natural order)排序的。在建立的時候,我們可以給它提供一個負責給元素排序的比較器。PriorityQueue不允許null值,因為他們沒有自然順序,或者說他們沒有任何的相關聯的比較器。最後,PriorityQueue不是執行緒安全的,入隊和出隊的時間複雜度是O(log(n))。
.
202、Java集合類框架的最佳實踐有哪些?
根據應用的需要正確選擇要使用的集合的型別對效能非常重要,比如:假如元素的大小是固定的,而且能事先知道,我們就應該用Array而不是ArrayList。
有些集合類允許指定初始容量。因此,如果我們能估計出儲存的元素的數目,我們可以設定初始容量來避免重新計算hash值或者是擴容。
為了型別安全,可讀性和健壯性的原因總是要使用泛型。同時,使用泛型還可以避免執行時的ClassCastException。
使用JDK提供的不變類(immutable class)作為Map的鍵可以避免為我們自己的類實現hashCode()和equals()方法。
程式設計的時候介面優於實現。
底層的集合實際上是空的情況下,返回長度是0的集合或者是陣列,不要返回null。
203、Enumeration介面和Iterator介面的區別有哪些?
Enumeration速度是Iterator的2倍,同時佔用更少的記憶體。但是,Iterator遠遠比Enumeration安全,因為其他執行緒不能夠修改正在被iterator遍歷的集合裡面的物件。同時,Iterator允許呼叫者刪除底層集合裡面的元素,這對Enumeration來說是不可能的。
204、HashSet和TreeSet有什麼區別?
- HashSet是通過HashMap實現的,TreeSet是通過TreeMap實現的,只不過Set用的只是Map的key
- Map的key和Set都有一個共同的特性就是集合的唯一性.TreeMap更是多了一個排序的功能.
- hashCode和equal()是HashMap用的, 因為無需排序所以只需要關注定位和唯一性即可.
- a. hashCode是用來計算hash值的,hash值是用來確定hash表索引的.
- b. hash表中的一個索引處存放的是一張連結串列, 所以還要通過equal方法迴圈比較鏈上的每一個物件
才可以真正定位到鍵值對應的Entry. - c. put時,如果hash表中沒定位到,就在連結串列前加一個Entry,如果定位到了,則更換Entry中的value,並返回舊value
- 由於TreeMap需要排序,所以需要一個Comparator為鍵值進行大小比較.當然也是用Comparator定位的.
- a. Comparator可以在建立TreeMap時指定
- b. 如果建立時沒有確定,那麼就會使用key.compareTo()方法,這就要求key必須實現Comparable介面.
- c. TreeMap是使用Tree資料結構實現的,所以使用compare介面就可以完成定位了.
HashSet是由一個hash表來實現的,因此,它的元素是無序的。add(),remove(),contains()方法的時間複雜度是O(1)。
另一方面,TreeSet是由一個樹形的結構來實現的,它裡面的元素是有序的。因此,add(),remove(),contains()方法的時間複雜度是O(logn)。
205、stop() 和 suspend() 方 法為何不推薦使用?
反對使用stop(),是因為它不安全。它會解除由執行緒獲取的所有鎖定,而且如果物件處於一種不連貫狀態,那麼其他執行緒能在那種狀態下檢查和修改它們。結果 很難檢查出真正的問題所在。suspend()方法容易發生死鎖。呼叫suspend()的時候,目標執行緒會停下來,但卻仍然持有在這之前獲得的鎖定。此 時,其他任何執行緒都不能訪問鎖定的資源,除非被”掛起”的執行緒恢復執行。對任何執行緒來說,如果它們想恢復目標執行緒,同時又試圖使用任何一個鎖定的資源,就 會造成死鎖。所以不應該使用suspend(),而應在自己的Thread類中置入一個標誌,指出執行緒應該活動還是掛起。若標誌指出執行緒應該掛起,便用wait()命其進入等待狀態。若標誌指出執行緒應當恢復,則用一個notify()重新啟動執行緒。
206、當一個執行緒進入一個物件的一個 synchronized 方法後,其它執行緒是否可進入此物件的其它方法 ?
答:情況一:當一個執行緒進入一個物件的一個synchronized方法後,其它執行緒可以訪問該物件的非同步方法。
情況二:當一個執行緒進入一個物件的一個synchronized方法後,其它執行緒不能訪問該同步方法。
情況三:當一個執行緒進入一個物件的一個synchronized方法後,其它執行緒不能同時訪問該物件的另一個同步方法。
207、介面:Collection
所有集合類的根型別,主要的一個介面方法:boolean add(Ojbect c)
雖返回的是boolean,但不是表示新增成功與否,因為Collection規定:一個集合拒絕新增這個元素,無論什麼原因,都必須丟擲異常,這個返回值表示的意義是add()執行後,集合的內容是否改了(就是元素有無數量、位置等變化)。類似的addAll,remove,removeAll,remainAll也是一樣的。
用Iterator模式實現遍歷集合
Collection有一個重要的方法:iterator(),返回一個Iterator(迭代子),用於遍歷集合的所有元素。Iterator模式可以把訪問邏輯從不同類的集合類中抽象出來,從而避免向客戶端暴露集合的內部結構。
for(Iterator it = c.iterator(); it.hasNext();) {…}
不需要維護遍歷集合的“指標”,所有的內部狀態都有Iterator來維護,而這個Iterator由集合類通過工廠方法生成。
每一種集合類返回的Iterator具體型別可能不同,但它們都實現了Iterator介面,因此,我們不需要關心到底是哪種Iterator,它只需要獲得這個Iterator介面即可,這就是介面的好處,物件導向的威力。
要確保遍歷過程順利完成,必須保證遍歷過程中不更改集合的內容(Iterator的remove()方法除外),所以,確保遍歷可靠的原則是:只在一個執行緒中使用這個集合,或者在多執行緒中對遍歷程式碼進行同步。
208、JDBC:如何控制事務?
A: conn.setAutoCommit(false);
當值為false時,表示禁止自動提交。 在預設情況下,JDBC驅動程式會在每一個更新操作語句之後自動新增commit語句,如果呼叫了setAutoCommit(false),則驅動程式不再新增commit語句了。
B: conn.commit();
提交事務。即驅動程式會向資料庫傳送一個commit語句。
C: conn.rollback();
回滾事務。即驅動程式會向資料庫傳送一個rollback語句。
209、ArrayList總結:
-
ArrayList是基於陣列實現的,是一個動態陣列,其容量能自動增長,類似於C語言中的動態申請記憶體,動態增長記憶體。
-
ArrayList不是執行緒安全的,只能用在單執行緒環境下,多執行緒環境下可以考慮用Collections.synchronizedList(List l)函式返回一個執行緒安全的ArrayList類,也可以使用concurrent併發包下的CopyOnWriteArrayList類。
-
ArrayList實現了Serializable介面,因此它支援序列化,能夠通過序列化傳輸,實現了RandomAccess介面,支援快速隨機訪問,實際上就是通過下標序號進行快速訪問,實現了Cloneable介面,能被克隆。
-
無參構造方法構造的ArrayList的容量預設為10,帶有Collection引數的構造方法,將Collection轉化為陣列賦給ArrayList的實現陣列elementData。
-
ArrayList在每次增加元素(可能是1個,也可能是一組)時,都要呼叫該方法來確保足夠的容量。當容量不足以容納當前的元素個數時,就設定新的容量為舊的容量的1.5倍加1,如果設定後的新容量還不夠,則直接新容量設定為傳入的引數(也就是所需的容量),而後用Arrays.copyof()方法將元素拷貝到新的陣列。
-
ArrayList基於陣列實現,可以通過下標索引直接查詢到指定位置的元素,因此查詢效率高,但每次插入或刪除元素,就要大量地移動元素,插入刪除元素的效率低。
-
在查詢給定元素索引值等的方法中,原始碼都將該元素的值分為null和不為null兩種情況處理,ArrayList中允許元素為null。
210、CopyOnWriteArrayList
-
和ArrayList繼承於AbstractList不同,CopyOnWriteArrayList沒有繼承於AbstractList,它僅僅只是實現了List介面。
-
ArrayList的iterator()函式返回的Iterator是在AbstractList中實現的;而CopyOnWriteArrayList是自己實現Iterator。
-
ArrayList的Iterator實現類中呼叫next()時,會“呼叫checkForComodification()比較‘expectedModCount’和‘modCount’的大小”;但是,CopyOnWriteArrayList的Iterator實現類中,沒有所謂的checkForComodification(),更不會丟擲ConcurrentModificationException異常!
-
CopyOnWriteArrayList不會拋ConcurrentModificationException,是因為所有改變其內容的操作(add、remove、clear等),都會copy一份現有資料,在現有資料上修改好,在把原有資料的引用改成指向修改後的資料。而不是在讀的時候copy。
211、LinkedList總結
-
LinkedList是基於雙向迴圈連結串列實現的,且頭結點中不存放資料。除了可以當做連結串列來操作外,它還可以當做棧、佇列和雙端佇列來使用。
-
LinkedList同樣是非執行緒安全的,只在單執行緒下適合使用。
-
LinkedList實現了Serializable介面,因此它支援序列化,能夠通過序列化傳輸,實現了Cloneable介面,能被克隆。
-
無參構造方法直接建立一個僅包含head節點的空連結串列,包含Collection的構造方法,先呼叫無參構造方法建立一個空連結串列,而後將Collection中的資料加入到連結串列的尾部後面。
-
在查詢和刪除某元素時,原始碼中都劃分為該元素為null和不為null兩種情況來處理,LinkedList中允許元素為null。
-
LinkedList是基於連結串列實現的,因此不存在容量不足的問題,所以這裡沒有擴容的方法。
-
找指定位置的元素時,先將index與長度size的一半比較,如果index
212、Vector總結
-
Vector也是基於陣列實現的,是一個動態陣列,其容量能自動增長。
-
Vector是JDK1.0引入了,它的很多實現方法都加入了同步語句,因此是執行緒安全的(其實也只是相對安全,有些時候還是要加入同步語句來保證執行緒的安全),可以用於多執行緒環境。
-
Vector沒有實現Serializable介面,因此它不支援序列化,實現了Cloneable介面,能被克隆,實現了RandomAccess介面,支援快速隨機訪問。
-
Vector有四個不同的構造方法。無參構造方法的容量為預設值10,僅包含容量的構造方法則將容量增長量明置為0。
-
Vector在每次增加元素(可能是1個,也可能是一組)時,都要呼叫該方法來確保足夠的容量。當容量不足以容納當前的元素個數時,就先看構造方法中傳入的容量增長量引數CapacityIncrement是否為0,如果不為0,就設定新的容量為就容量加上容量增長量,如果為0,就設定新的容量為舊的容量的2倍,如果設定後的新容量還不夠,則直接新容量設定為傳入的引數(也就是所需的容量),而後同樣用Arrays.copyof()方法將元素拷貝到新的陣列。
-
很多方法都加入了synchronized同步語句,來保證執行緒安全。
-
同樣在查詢給定元素索引值等的方法中,原始碼都將該元素的值分為null和不為null兩種情況處理,Vector中也允許元素為null。
-
其他很多地方都與ArrayList實現大同小異,Vector現在已經基本不再使用。
HashMap總結 -
HashMap是基於雜湊表實現的,每一個元素是一個key-value對,其內部通過單連結串列解決衝突問題,容量不足(超過了閥值)時,同樣會自動增長。
-
HashMap是非執行緒安全的,只是用於單執行緒環境下,多執行緒環境下可以採用concurrent併發包下的concurrentHashMap。
-
HashMap 實現了Serializable介面,因此它支援序列化,實現了Cloneable介面,能被克隆。
-
HashMap共有四個構造方法。構造方法中提到了兩個很重要的引數:初始容量和載入因子。這兩個引數是影響HashMap效能的重要引數,其中容量表示雜湊表中槽的數量(即雜湊陣列的長度),初始容量是建立雜湊表時的容量(如果不指明,則預設為16),載入因子是雜湊表在其容量自動增加之前可以達到多滿的一種尺度,當雜湊表中的條目數超出了載入因子與當前容量的乘積時,則要對該雜湊表進行 resize 操作(即擴容)。如果載入因子越大,對空間的利用更充分,但是查詢效率會降低(連結串列長度會越來越長);如果載入因子太小,那麼表中的資料將過於稀疏(很多空間還沒用,就開始擴容了),對空間造成嚴重浪費。如果我們在構造方法中不指定,則系統預設載入因子為0.75,這是一個比較理想的值,一般情況下我們是無需修改的。另外,無論指定的容量為多少,構造方法都會將實際容量設為不小於指定容量的2的次方的一個數,且最大值不能超過2的30次方。每次擴容也是擴大兩倍,也就是容量總是2的冪次方。
-
HashMap中key和value都允許為null。
-
key為null的鍵值對永遠都放在以table[0]為頭結點的連結串列中,當然不一定是存放在頭結點table[0]中。如果key不為null,則先求的key的hash值,根據hash值找到在table中的索引,在該索引對應的單連結串列中查詢是否有鍵值對的key與目標key相等,有就返回對應的value,沒有則返回null。
213、Hashtable總結
-
Hashtable同樣是基於雜湊表實現的,同樣每個元素是一個key-value對,其內部也是通過單連結串列解決衝突問題,容量不足(超過了閥值)時,同樣會自動增長。
-
Hashtable也是JDK1.0引入的類,是執行緒安全的,能用於多執行緒環境中。
-
Hashtable同樣實現了Serializable介面,它支援序列化,實現了Cloneable介面,能被克隆。
-
HashTable在不指定容量的情況下的預設容量為11,而HashMap為16,Hashtable不要求底層陣列的容量一定要為2的整數次冪,而HashMap則要求一定為2的整數次冪。
-
Hashtable中key和value都不允許為null,而HashMap中key和value都允許為null(key只能有一個為null,而value則可以有多個為null)。但是如果在Hashtable中有類似put(null,null)的操作,編譯同樣可以通過,因為key和value都是Object型別,但執行時會丟擲NullPointerException異常,這是JDK的規範規定的。
-
Hashtable擴容時,將容量變為原來的2倍加1,而HashMap擴容時,將容量變為原來的2倍。
-
Hashtable計算hash值,直接用key的hashCode(),而HashMap重新計算了key的hash值,Hashtable在求hash值對應的位置索引時,用取模運算,而HashMap在求位置索引時,則用與運算,且這裡一般先用hash&0x7FFFFFFF後,再對length取模,&0x7FFFFFFF的目的是為了將負的hash值轉化為正值,因為hash值有可能為負數,而&0x7FFFFFFF後,只有符號外改變,而後面的位都不變。
214、TreeMap總結
-
TreeMap是基於紅黑樹實現的。
-
TreeMap是根據key進行排序的,它的排序和定位需要依賴比較器或覆寫Comparable介面,也因此不需要key覆寫hashCode方法和equals方法,就可以排除掉重複的key,而HashMap的key則需要通過覆寫hashCode方法和equals方法來確保沒有重複的key。
-
TreeMap的查詢、插入、刪除效率均沒有HashMap高,一般只有要對key排序時才使用TreeMap。
-
TreeMap的key不能為null,而HashMap的key可以為null。
215、LinkedHashMap總結
-
LinkedHashMap是HashMap的子類,與HashMap有著同樣的儲存結構,但它加入了一個雙向連結串列的頭結點,將所有put到LinkedHashmap的節點一一串成了一個雙向迴圈連結串列,因此它保留了節點插入的順序,可以使節點的輸出順序與輸入順序相同。
-
LinkedHashMap可以用來實現LRU演算法。
-
LinkedHashMap同樣是非執行緒安全的,只在單執行緒環境下使用。
-
LinkedHashMap中加入了一個head頭結點,將所有插入到該LinkedHashMap中的Entry按照插入的先後順序依次加入到以head為頭結點的雙向迴圈連結串列的尾部。
-
LinkedHashMap由於繼承自HashMap,因此它具有HashMap的所有特性,同樣允許key和value為null。
-
原始碼中的accessOrder標誌位,當它false時,表示雙向連結串列中的元素按照Entry插入LinkedHashMap到中的先後順序排序,即每次put到LinkedHashMap中的Entry都放在雙向連結串列的尾部,這樣遍歷雙向連結串列時,Entry的輸出順序便和插入的順序一致,這也是預設的雙向連結串列的儲存順序;當它為true時,表示雙向連結串列中的元素按照訪問的先後順序排列,可以看到,雖然Entry插入連結串列的順序依然是按照其put到LinkedHashMap中的順序,但put和get方法均有呼叫recordAccess方法(put方法在key相同,覆蓋原有的Entry的情況下呼叫recordAccess方法),該方法判斷accessOrder是否為true,如果是,則將當前訪問的Entry(put進來的Entry或get出來的Entry)移到雙向連結串列的尾部(key不相同時,put新Entry時,會呼叫addEntry,它會呼叫creatEntry,該方法同樣將新插入的元素放入到雙向連結串列的尾部,既符合插入的先後順序,又符合訪問的先後順序,因為這時該Entry也被訪問了),否則,什麼也不做。
-
構造方法,前四個構造方法都將accessOrder設為false,說明預設是按照插入順序排序的,而第五個構造方法可以自定義傳入的accessOrder的值,因此可以指定雙向迴圈連結串列中元素的排序規則,一般要用LinkedHashMap實現LRU演算法,就要用該構造方法,將accessOrder置為true。
-
LinkedHashMap是如何實現LRU的。首先,當accessOrder為true時,才會開啟按訪問順序排序的模式,才能用來實現LRU演算法。我們可以看到,無論是put方法還是get方法,都會導致目標Entry成為最近訪問的Entry,因此便把該Entry加入到了雙向連結串列的末尾(get方法通過呼叫recordAccess方法來實現,put方法在覆蓋已有key的情況下,也是通過呼叫recordAccess方法來實現,在插入新的Entry時,則是通過createEntry中的addBefore方法來實現),這樣便把最近使用了的Entry放入到了雙向連結串列的後面,多次操作後,雙向連結串列前面的Entry便是最近沒有使用的,這樣當節點個數滿的時候,刪除的最前面的Entry(head後面的那個Entry)便是最近最少使用的Entry。
216、ThreadLocal原理
首先,ThreadLocal 不是用來解決共享物件的多執行緒訪問問題的,一般情況下,通過ThreadLocal.set() 到執行緒中的物件是該執行緒自己使用的物件,其他執行緒是不需要訪問的,也訪問不到的。各個執行緒中訪問的是不同的物件。
另外,說ThreadLocal使得各執行緒能夠保持各自獨立的一個物件,並不是通過ThreadLocal.set()來實現的,而是通過每個執行緒中的new 物件 的操作來建立的物件,每個執行緒建立一個,不是什麼物件的拷貝或副本。通過ThreadLocal.set()將這個新建立的物件的引用儲存到各執行緒的自己的一個map中,每個執行緒都有這樣一個map,執行ThreadLocal.get()時,各執行緒從自己的map中取出放進去的物件,因此取出來的是各自自己執行緒中的物件,ThreadLocal例項是作為map的key來使用的。
如果ThreadLocal.set()進去的東西本來就是多個執行緒共享的同一個物件,那麼多個執行緒的ThreadLocal.get()取得的還是這個共享物件本身,還是有併發訪問問題。
ThreadLocal不是用來解決物件共享訪問問題的,而主要是提供了保持物件的方法和避免引數傳遞的方便的物件訪問方式。歸納了兩點:
-
每個執行緒中都有一個自己的ThreadLocalMap類物件,可以將執行緒自己的物件保持到其中,各管各的,執行緒可以正確的訪問到自己的物件。
-
將一個共用的ThreadLocal靜態例項作為key,將不同物件的引用儲存到不同執行緒的ThreadLocalMap中,然後線上程執行的各處通過這個靜態ThreadLocal例項的get()方法取得自己執行緒儲存的那個物件,避免了將這個物件作為引數傳遞的麻煩。
如果要把本來執行緒共享的物件通過ThreadLocal.set()放到執行緒中也可以,可以實現避免引數傳遞的訪問方式,但是要注意get()到的是那同一個共享物件,併發訪問問題要靠其他手段來解決。但一般來說執行緒共享的物件通過設定為某類的靜態變數就可以實現方便的訪問了,似乎沒必要放到執行緒中。
ThreadLocal的應用場合,我覺得最適合的是按執行緒多例項(每個執行緒對應一個例項)的物件的訪問,並且這個物件很多地方都要用到。
ThreadLocal類中的變數只有這3個int型:
- 1
- 2
- 3
而作為ThreadLocal例項的變數只有threadLocalHashCode 這一個,nextHashCode 和HASH_INCREMENT 是ThreadLocal類的靜態變數,實際上HASH_INCREMENT是一個常量,表示了連續分配的兩個ThreadLocal例項的threadLocalHashCode值的增量,而nextHashCode 的表示了即將分配的下一個ThreadLocal例項的threadLocalHashCode 的值。
建立一個ThreadLocal例項即new ThreadLocal()時做了哪些操作,從建構函式ThreadLocal()裡看什麼操作都沒有,唯一的操作是這句:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
就是將ThreadLocal類的下一個hashCode值即nextHashCode的值賦給例項的threadLocalHashCode,然後nextHashCode的值增加HASH_INCREMENT這個值。
因此ThreadLocal例項的變數只有這個threadLocalHashCode,而且是final的,用來區分不同的ThreadLocal例項,ThreadLocal類主要是作為工具類來使用,那麼ThreadLocal.set()進去的物件是放在哪兒的呢?
看一下上面的set()方法,兩句合併一下成為
- 1
這個ThreadLocalMap 類是ThreadLocal中定義的內部類,但是它的例項卻用在Thread類中:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
再看這句。
- 1
- 2
也就是將該ThreadLocal例項作為key,要保持的物件作為值,設定到當前執行緒的ThreadLocalMap 中,get()方法同樣類似。
217、Static Nested Class 和 Inner Class的不同?
1 建立一個static內部類的物件,不需要一個外部類物件。建立一個非static內部類必須要一個外部類物件
2 不能從一個static內部類的一個物件訪問一個外部類物件,可以從一個非static內部類訪問其外部類物件。如OutterClassName.this進行訪問。
218、當你在瀏覽器輸入一個網址,比如http://www.taobao.com,按回車之後發生了什麼?請從技術的角度描述,如瀏覽器、網路(UDP,TCP,HTTP等),以及伺服器等各種引數與物件上由此引發的一系列活動。請儘可能的涉及到所有的關鍵技術點。
答案:答題角度有以下幾個DNS域名查詢,負載均衡,HTTP協議格式,HTTP下一層的TCP協議,伺服器應該返回的各種網路的應答。
1、通過訪問的域名找出其IP地址。DNS查詢過程如下:
瀏覽器快取:瀏覽器會快取DNS記錄,並存放一段時間。
系統快取:如果瀏覽器快取中沒有找到需要的記錄,瀏覽器會做一個系統呼叫。
路由器快取:接著前面的查詢請求發向路由器,它一般會有自己的DNS快取。
ISP DNS快取:接下來要check的就是ISP快取的DNS伺服器,在這一般都能找到相應的快取記錄
遞迴搜尋:你的ISP的DNS伺服器從根域名伺服器開始進行遞迴搜尋,從.com頂級域名伺服器到葉節點伺服器。
2、上述這種域名解析的方式似乎只能解析出一個ip,我們知道一般的大型網站都有好幾個ip地址,這種問題如何解決?還好,有幾種方法可以消除這個瓶頸:
輪叫排程(round-robin DNS):是DNS查詢時返回多個IP時的解決方案。舉例來說,Facebook.com實際上就對應了四個IP地址。
負載均衡:是以一個特定IP地址進行偵聽並將網路請求轉發到叢集伺服器上的硬體裝置。一些大型的站點一般都會使用這種昂貴的高效能負載均衡
地理DNS:根據使用者所處的地理位置,通過把域名對映到多個不同的IP地址提高可擴充套件性。這樣不同的伺服器不能夠更新同步狀態,但對映靜態內容的話非常好。
Anycast:是一個IP地址對映多個物理主機的路由技術。美中不足,Anycast與TCP協議適應的不是很好,所以很少應用在那些方案中。大多數DNS伺服器使用Anycast來獲得高效低延遲的DNS查詢。
3、瀏覽器給Web伺服器傳送一個Http請求
這裡可以回答的更詳細一點:比如說http協議的格式,http請求的頭,比如說發起一個Get型別請求。
4、伺服器給瀏覽器響應一個301永久重定向響應
為什麼要有這一步,原因之一是為了便於搜尋引擎優化
5、瀏覽器跟中重定向地址
這個時候瀏覽器已經知道了正確的URL地址,於是重新傳送一個Get請求,請求頭中的URL為重定向之後的。
6、伺服器處理請求
Web伺服器軟體:web伺服器軟體(IIS和Apatch)介紹到Http請求,然後確定執行什麼請求處理來處理它。請求處理就是一個能夠讀懂請求並且能生成HTML來進行相應的程式
請求處理:請求處理閱讀請求及它的引數和cookies。它會讀取也可能更新一些資料,並將資料儲存在伺服器上。然後,需求處理會生成一個HTML響應。
7、伺服器發回一個HTML響應
8、瀏覽器開始渲染這個HTML
9、瀏覽器傳送獲取嵌入在HTML中的資源物件請求
一些嵌入在html中的資源,比如說圖片,js,css等等
10、瀏覽器傳送非同步(AJAX)請求
在web2.0時代,在頁面渲染成功之後,瀏覽器依然可以跟伺服器進行互動,方法就是通過這個非同步請求AJAX
下面這個答案說的儘管跟這道題目關係不大,但是很有意思。所以還是給出來:
你開啟了www.taobao.com,這時你的瀏覽器首先查詢DNS伺服器,將www.taobao.com轉換成ip地址。不過首先你會發現,你在不同的地區或者不同的網路(電信,聯通,移動)的情況下,轉換後的ip地址很可能是不一樣的,這首先涉及到負載均衡的第一步,通過DNS解析域名時將你的訪問分配到不同的入口,同時儘可能保證你所訪問的入口是所有入口中可能較快的一個。
你通過這個入口成功的訪問了www.taobao.com的實際的入口ip地址。這時你產生了一個PV,即Page View,頁面訪問。每日每個網站的總PV量是形容一個網站規模的重要指標。淘寶網全網在平日(非促銷期間)的PV大概是16-25億之間。同時作為一個獨立的使用者,你這次訪問淘寶網的所有頁面,均算作一個UV(Unique Visitor使用者訪問)。
因為同一時刻訪問www.taobao.com的人數過於巨大,所以即便是生成淘寶首頁頁面的伺服器,也不可能僅有一臺。僅用於生成www.taobao.com首頁的伺服器就有可能有成百上千臺,那麼你的一次訪問時生成頁面給你看的任務便會被分配給其中一臺伺服器完成。這個過程要保證公平公正(也就是說這成百上千臺伺服器每臺負擔的使用者數要差不多),這一很複雜的過程是由幾個系統配合完成,其中最關鍵的便是LVS,Linux Virtual Server,世界上最流行的負載均衡系統之一。
經過一系列複雜的邏輯運算和資料處理,用於這次給你看的淘寶網的首頁的HTML內容便生成成功了,對Web前端稍微有點常識的童鞋都應該知道,下一步瀏覽器會去載入頁面中用到的css,js,圖片等樣式,指令碼和資原始檔。但是可能相對較少的同學才會知道,你的瀏覽器在同一個域名下併發載入的資源數量是有限制的,例如ie6-7是兩個,ie8是6個,chrome個版本不大一樣,一般是4-6個。我剛剛看了一下,我訪問的淘寶網首頁需要載入126個資源,那麼如此小的併發連線數自然會載入很久。所以前端開發人員往往會將上述的這些資原始檔分佈在好多個域名下,變相的繞過瀏覽器的這個限制,同時也為下文的CDN工作做準備。
據不可靠訊息,在雙十一當天高峰,淘寶的訪問流量達到最巔峰達到871GB/S。這個數字意味著需要178萬個4mb頻寬的家庭頻寬才能負擔的起,也完全有能力拖垮一箇中小城市的全部網際網路頻寬。那麼顯然,這些訪問流量不可能集中在一起。並且大家都知道,不同地區不同網路(電信,聯通等)之間互訪會非常緩慢,但是你卻發現很少發現淘寶網訪問緩慢。這便是CDN,Content Delivery Network,即內容分發網路的作用。淘寶在全國各地建立了上百個CDN節點,利用一些手段保證你的訪問的(這裡主要指js、css、圖片等)地方是離你最近的CDN節點,這樣便保證了大流量分散已經在各地訪問的加速。
這便出現了一個問題,那就是假如一個賣家釋出了一個新寶貝,上傳了幾張新的寶貝圖片,那麼淘寶網如何保證全國各地的CDN節點中都會同步的存在這幾張圖片供使用者使用呢?這裡邊就涉及到大量的內容分發與同步的相關技術。淘寶開發了分散式檔案系統TFS來處理這類問題。
219、程式間通訊的方法主要有以下幾種:
-
管道(Pipe):管道可用於具有親緣關係程式間的通訊,允許一個程式和另一個與它有共同祖先的程式之間進行通訊。
-
命名管道(named pipe):命名管道克服了管道沒有名字的限制,因此,除具有管道所具有的功能外,它還允許無親緣關係程式間的通訊。命名管道在檔案系統中有對應的檔名。命名管道通過命令mkfifo或系統呼叫mkfifo來建立。
-
訊號(Signal):訊號是比較複雜的通訊方式,用於通知接受程式有某種事件發生,除了用於程式間通訊外,程式還可以傳送訊號給程式本身;linux除了支援Unix早期訊號語義函式sigal外,還支援語義符合Posix.1標準的訊號函式sigaction(實際上,該函式是基於BSD的,BSD為了實現可靠訊號機制,又能夠統一對外介面,用sigaction函式重新實現了signal函式)。
-
訊息(Message)佇列:訊息佇列是訊息的連結表,包括Posix訊息佇列system V訊息佇列。有足夠許可權的程式可以向佇列中新增訊息,被賦予讀許可權的程式則可以讀走佇列中的訊息。訊息佇列克服了訊號承載資訊量少,管道只能承載無格式位元組流以及緩衝區大小受限等缺
-
共享記憶體:使得多個程式可以訪問同一塊記憶體空間,是最快的可用IPC形式。是針對其他通訊機制執行效率較低而設計的。往往與其它通訊機制,如訊號量結合使用,來達到程式間的同步及互斥。
-
記憶體對映(mapped memory):記憶體對映允許任何多個程式間通訊,每一個使用該機制的程式通過把一個共享的檔案對映到自己的程式地址空間來實現它。
-
訊號量(semaphore):主要作為程式間以及同一程式不同執行緒之間的同步手段。
-
套接字(Socket):更為一般的程式間通訊機制,可用於不同機器之間的程式間通訊。起初是由Unix系統的BSD分支開發出來的,但現在一般可以移植到其它
類Unix系統上:Linux和System V的變種都支援套接字。而在java中我們實現多執行緒間通訊則主要採用”共享變數”和”管道流”這兩種方法
- 方法一 通過訪問共享變數的方式(注:需要處理同步問題)
- 方法二 通過管道流
其中方法一有兩種實現方法,即
- 通過內部類實現執行緒的共享變數
- 通過實現Runnable介面實現執行緒的共享變數
210、什麼是trie樹(單詞查詢樹、字典樹)?
1.Trie樹 (特例結構樹)
Trie樹,又稱單詞查詢樹、字典樹,是一種樹形結構,是一種雜湊樹的變種,是一種用於快速檢索的多叉樹結構。典型應用是用於統計和排序大量的字串(但不僅限於字串),所以經常被搜尋引擎系統用於文字詞頻統計。它的優點是:最大限度地減少無謂的字串比較,查詢效率比雜湊表高。
Trie的核心思想是空間換時間。利用字串的公共字首來降低查詢時間的開銷以達到提高效率的目的。
Trie樹也有它的缺點,Trie樹的記憶體消耗非常大.當然,或許用左兒子右兄弟的方法建樹的話,可能會好點.
2. 三個基本特性:
-
1)根節點不包含字元,除根節點外每一個節點都只包含一個字元。
-
2)從根節點到某一節點,路徑上經過的字元連線起來,為該節點對應的字串。
-
3)每個節點的所有子節點包含的字元都不相同。
3 .說明:和二叉查詢樹不同,在trie樹中,每個結點上並非儲存一個元素。trie樹把要查詢的關鍵詞看作一個字元序列。並根據構成關鍵詞字元的先後順序構造用於檢索的樹結構。在trie樹上進行檢索類似於查閱英語詞典。 一棵m度的trie樹或者為空,或者由m棵m度的trie樹構成。
查詢分析
在trie樹中查詢一個關鍵字的時間和樹中包含的結點數無關,而取決於組成關鍵字的字元數。而二叉查詢樹的查詢時間和樹中的結點數有關O(log2n)。
如果要查詢的關鍵字可以分解成字元序列且不是很長,利用trie樹查詢速度優於
二叉查詢樹。如:
若關鍵字長度最大是5,則利用trie樹,利用5次比較可以從26^5=11881376個可能的關鍵字中檢索出指定的關鍵字。而利用二叉查詢樹至少要進行 次比較。
trie樹的應用:
- 字串檢索,詞頻統計,搜尋引擎的熱門查詢。
- 字串最長公共字首。
- 排序。
- 作為其他資料結構和演算法的輔助結構。如字尾樹,AC自動機等。
221、在25匹馬中,挑出速度最快的3匹。每場比賽只能有5馬一起跑。所需要的最少比賽次數是多少
至少7次
先分為5組,每組5匹。
首先全部5組分別比賽;
其次,每組的第一名進行第六次比賽:這樣可淘汰最後兩名及其所在組的全部馬匹(共10匹),同時可淘汰第三名所在組排名靠後的其餘4匹馬,以及第二名所在組的排名最後的3匹,再加上第一名所在小組的最後2名,共計淘汰19名,同時產生25匹中的冠軍(即本輪的第一名)。
最後,剩餘的5匹進行第7次比賽,前兩名為25匹中的亞軍和季軍。
相關文章
- Android 面試題,百度,小米,阿里面試題Android面試題阿里
- iOS面試·一個iOS程式設計師的BAT面試全記錄(內含百度+網易+阿里面試真題)iOS面試程式設計師BAT阿里
- 直通BAT專場:百度+阿里+騰訊+網易(題目大合集)!BAT阿里
- 最全技術面試180題:阿里11面試+網易+百度+美團!面試阿里
- 180道Java技術面試題:阿里11面試+網易+百度+美團!Java面試題阿里
- BAT經典面試題彙總BAT面試題
- 百度面試題面試題
- 那我也來一波最近熱騰騰的面試題?面試題
- 最全的BAT大廠面試題整理BAT面試題
- 手撕面試官系列:BAT面試常問85題面試BAT
- 阿里面試題阿里面試題
- 阿里java面試題阿里Java面試題
- 阿里、騰訊、百度、華為、京東、搜狗和滴滴最新面試題彙集阿里面試題
- 百度js面試題JS面試題
- 阿里歷年經典Java面試題彙總,想進BAT你還不快收藏!阿里Java面試題BAT
- 最全的BAT大廠面試題(百度、小米、樂視、美團、58、獵豹、360)【 java基礎面試知識點】BAT面試題Java
- BAT機器學習面試1000題系列(二)BAT機器學習面試
- 百度、阿里、騰訊(BAT)三大巨頭的金融之局阿里BAT
- BAT遊戲無百度BAT遊戲
- 阿里面試題(一)阿里面試題
- (四) BAT面試的20道高頻資料庫面試題BAT資料庫面試題
- 阿里補貼20億、百度豪擲百億,BAT“巷戰”小程式阿里BAT
- BAT年度財報解讀 阿里彎道超車 百度投資未來BAT阿里
- 已整理,最新面試題彙集!阿里、騰訊、百度、華為、京東、搜狗和滴滴!面試題阿里
- 刷完500道BAT面試題,我能去面試大廠了嗎?BAT面試題
- 2017阿里,百度,京東java面試+筆試大合集,這些面試題你都會嗎?阿里Java筆試面試題
- LeetCode 74,直擊BAT經典面試題LeetCodeBAT面試題
- 2018最新《BAT Java必考面試題集》BATJava面試題
- 阿里+百度+CVTE的Java面試題曝光,巨頭的招聘你怕了麼?阿里Java面試題
- 最新阿里Java面試題,這些面試題你會嗎?阿里Java面試題
- 【答阿里寒冬面試題】呵呵,大神的面試題就是好!阿里面試題
- [演算法總結] 17 題搞定 BAT 面試——連結串列題演算法BAT面試
- 【BAT機器學習面試題】前100題彙總及勘誤(上)BAT機器學習面試題
- 百度的智慧化圖騰
- 2020年最新位元組、阿里、騰訊、愛奇藝等BAT Android社招高頻面試題,押題99.98%!阿里BATAndroid面試題
- 百度掉隊BAT 5年後阿里與騰訊的勝負已揭曉BAT阿里
- 阿里最全面試116題:阿里天貓、螞蟻金服、阿里巴巴面試題含答案阿里面試題
- 2018年前端大廠面試題(百度,阿里,滴滴,去哪兒網.....)前端面試題阿里