C語言深度剖析——讀書筆記
1、 什麼是定義,什麼是宣告?
定義:編譯器建立一個物件,併為這個物件分配一塊記憶體,給它取上一個名字。
宣告:1>告訴編譯器這個名字已經已經分配到一塊記憶體上了
2>告訴編譯器這個名字已經被預定了,別的地方不能再用它來作為變數名或物件名。
2、 auto:
在預設的情況下,編譯器預設所有的變數都是auto的,
3、 register:
register變數必須是單個的值,並且其長度應該小於或等於整形的長度,而且register變數可能不存放在記憶體中,所以不能用&—-取地址符來獲取register變數的地址。
4、 static:在C語言中有兩個作用
1> 修飾變數:變數又分為區域性變數和全域性變數但都存在記憶體的靜態區。
靜態全域性變數:作用域僅限於變數被定義的檔案中,其他檔案即使用extern宣告也沒法使用它。或者說它的作用域從定義之處開始到檔案結尾處結束。
靜態區域性變數:在函 數體中定義,只能在這個函式中使用,由於是存在靜態區,所以函式執行結束該變數也不會被銷燬,下次使用仍能用到這個值。
2> 修飾函式:此處static不是指儲存方式,而是指函式的作用域僅限於本檔案。
所以又稱內部函式。
5、 不同型別的資料之間的運算要注意精度擴充套件問題,一般低精度資料向高精度資料擴充套件。
6、 柔型陣列:
結構體中的最後一個元素允許是未知大小的陣列,這就叫做柔型陣列的成員。
但結構中的柔性陣列成員前面必須至少包含一個其他成員。
柔型陣列成員允許結構體中包含一個大小可變的陣列,
柔型陣列成員只作為一個符號地址存在,而且必須是結構體最後一個成員。
Sizeof返回的這種結構體大小不包括柔性陣列的記憶體,
柔型陣列成員不僅可以用於字元陣列,還可以是元素為其他型別形的陣列。
包含柔型陣列成員的結構用malloc()函式進行記憶體的動態分配。並且分配的記憶體應大於結構的大小,以適應柔型陣列的預期大小。
7、 signed char 範圍-128~127
unsigned char 範圍 0~255
-1 補碼 1111 1111
-2 補碼 1111 1110
-3 補碼 1111 1101
.
.
.
-127 補碼 1000 0001
-127絕對值為127:0111 1111 取反加一 1000 0001
-128 補碼 1000 0000
-128絕對值為128:1000 0000 取反加一 0111 1111+1=1000 0000
-129補碼 0111 1111
-129絕對值為129:1000 0001 取反加一 0111 1110+1=0111 1111
.
.
.
-255補碼0000 0001
-255絕對值為255:1111 1111 取反加一 0000 0000 +1=0000 0001
-256補碼0000 0000
-256絕對值為256:1 0000 0000取反加一
0 1111 1111 +1=1 0000 0000
-257 補碼
-257絕對值257:1 0000 0001取反加一
0 1111 1110+1=0 1111 1111
8、
int main()
{
int j = -20;//11111111 11111111 11111111 11101100
unsigned int i = 10;//00000000 00000000 00000000 00001010
unsigned k=i + j;//11111111 11111111 11111111 11110110(但是這是一個無符號數)=4292967286
system("pause");
return 0;
}9、+0和-0在記憶體裡怎麼儲存?
-0 原碼:1000 0000
反碼:1111 1111
補碼:1 0000 0000
+0 原碼:0000 0000
反碼:1111 1111
補碼:1 0000 0000
10、case後面只能是整形或者字元型的常量,或者常量表示式。
11、for語句的控制表示式不能包含任何浮點型別的物件
舍入誤差和擷取誤差會通過迴圈的迭代過程傳播,導致迴圈變數的顯著誤差
12、在C語言中,凡不加返回值型別限定的函式,就會被編譯器作為返回整型值處理
13、在C++中,引數為void的意思是這個函式不接受任何引數。
14、不能對void指標進行演算法操作。
15、return語句不可以返回指向“棧記憶體”的“指標”,因為該記憶體在函式結束時自動銷燬。
16、const在C和C++中的區別:
在C語言中:
1》 const修飾的是隻讀的變數,並不是一個常量(因此不可以做陣列下標)
2》 節省空間,避免不必要的記憶體分配,同時提高效率
編譯器通常不為普通const只讀變數分配記憶體空間,而是將它們儲存在符號表中,這使得它成為一個編譯期間的值,沒有了儲存與讀記憶體的操作,使得它的效率也很高。
3》 修飾一般變數,可以用在型別說明符前,也可以在型別說明符後面。
4》 修飾陣列,用法同上
5》 修飾指標。離哪個近就修飾誰
6》 修飾函式的引數。不希望這個引數在函式體內被意外改變時用
7》 修飾函式的返回值,表示返回值不能改變。
Const和#define的比較:
1》 Const定義的只讀變數從彙編的角度來講,只給出了對應的記憶體地址,而不像是#define給出了立即數,所以const定義的只讀變數在程式執行過程中只有一份備份(因為它是全域性的只讀變數,存放在靜態區),而#define定義的巨集常量在記憶體中有若干個備份。#define巨集是在預編譯階段進行替換,而const修飾的只讀變數是在編譯時確定其值的。
2》 #define巨集沒有型別,而const修飾的只讀變數有特定的型別。
在C++語言中:
1》 const修飾形參,一般和引用同時使用
2》 const修飾返回值
3》 const修飾類資料成員,必須在建構函式的初始化列表中初始化
4》 const修飾類成員函式,實際修飾隱含的this,表示在類中不可以對類的任何成員進行修改(將const加在函式後面)
5》 在const修飾的成員函式中要對類的某個資料成員進行修改,該資料成員定義宣告時必須加mutable
問題:
1》 const物件可以呼叫非const成員函式(不可以)和成員函式(可以)嗎?
2》 非const物件可以呼叫非const成員函式(y)和成員函式(y)嗎?
3》 Const成員函式內可以呼叫它的const成員函式(y)和非const成員函式(n)嗎?
4》 非Const成員函式內可以呼叫它的const成員函式(y)和非const成員函式(y)嗎?
Const在C和C++中最大的不同:
在C中const預設具有外部連結,而C++中則是內部連結。
內連線:也就是說它只能在定義它的檔案中使用,連線時其他編譯單元看不見他。
外連結:就可能導致同一個變數在不同的CPP檔案中都分配了地址
17、volatie—是易變不穩定的意思。
用它修飾的變數表示可以被某些編譯器未知的因素修改,可以保證對特殊地址的穩定訪問。
18、記憶體地址的最小單元為1個位元組,空結構體的大小為1個位元組。
19、在C++裡struct的成員預設是public,而class成員預設是private
20、在C++裡union的成員預設為public,union主要用來壓縮空間,如果一些資料不可能在同一時間同時被用到,則可以使用union。
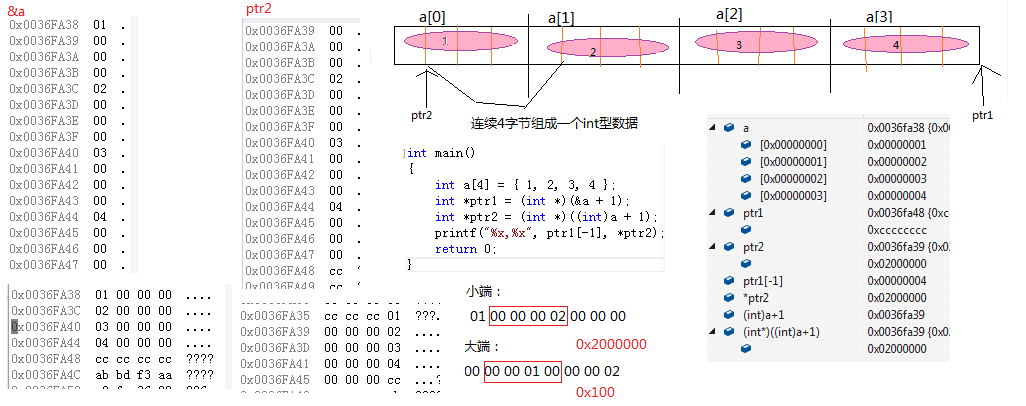
21、大小端:對於一個由2位元組組成的16位整數,在記憶體中儲存這兩個位元組有兩種方法:一種是將底序位元組儲存在起始地址,稱為小端模式;另一種方法是將高序位元組儲存在起始位置,稱為大端模式。(一般先讀取高地址儲存的資料)
大端模式(Big-endian):字資料的高位元組儲存在低地址中,而字資料的低位元組儲存在高地址中。
小端模式(Little-endian) : 字資料的高位元組儲存在高地址中,而字資料的低位元組儲存在低地址中。
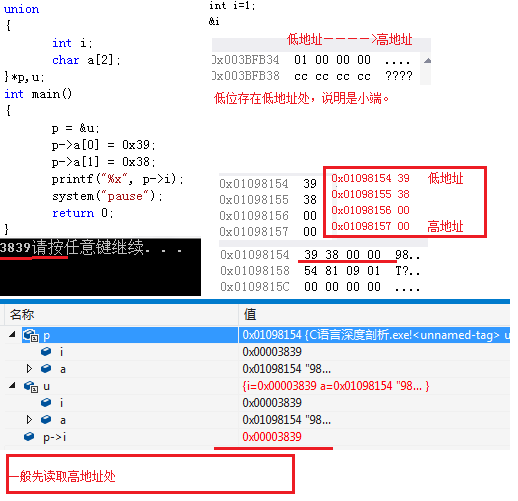
22、判斷當前系統的大小端:
int CheckSystem()
{
union check
{
int i;
char ch;
}c;
c.i = 1;
return c.ch == 1;
}
int main()
{
int ret = CheckSystem();
return 0;
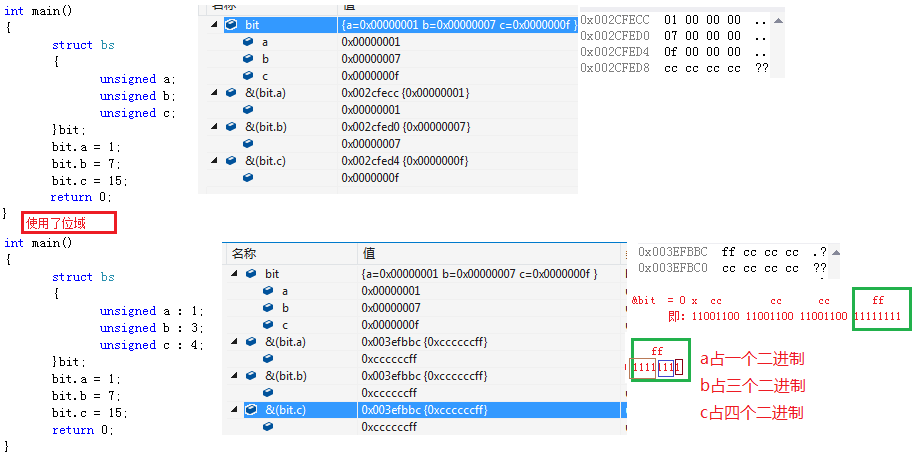
}23、位域:
1》位域是指資訊在儲存時,並不需要佔用一個完整的位元組,而只需佔用幾個或者一個二進位制位。
2》所謂“位域”是把一個位元組中的二進位劃分為幾個不同區域,並說明每個區域的位數。每個區域有一個位名,允許在程式中按照域名進行操作。這樣就可以把幾個不同的物件用一個位元組的二進位制與來表示。
24、列舉與#define巨集的區別:
1》#define巨集是在預編譯階段進行簡單題替換的;列舉常量編譯的時候確定其值的。
2》一般在偵錯程式裡,可以除錯列舉常量,但是不能除錯巨集常量。
3》,列舉可以一次性定義大量相關的常量,而#define巨集一次只能定義一個。
25、typedef:是給一個已經存在的型別取一個別名。
——再把typedef和const放在一起看看:
typedef struct strudent
{
int a;
}Stu_st,* Stu_pst; 這裡1》const Stu_pst stu3;
2》Stu_pst const stu3;
以前說過const int i 和 int const i 完全一樣。const 放在型別前型別後都可以
但是const int* p 和 int* const p則完全不一樣(一個修飾指標指向的內容;一個修飾指標)
26、
27、單引號、雙引號
1》雙引號引起來的都是字串常量;單引號引起來的都是字元常量。
2》’a’ 和 “a”則完全不一樣,在記憶體裡前者佔1個位元組,後者佔2個位元組(還有一個\0)。
3》再看看這個例子:1,‘1’,“1”
1》第一個1是個整形,32位系統下佔4個位元組。
2》第二個1是字元常量,佔1個位元組。
3》第三個1是字串常量,佔2個位元組。
28、邏輯運算子:“||” 和 “&&”
1》“||”只要有一個條件為真,結果就為真
2》“&&”只要有一個條件為假,結果就為假。
3》例如:
int i=0; int j=0;
if(++i>0 || ++j>0)
{
//列印出i和j的值(i=1;j=0),,因為先計算++i>0,發現結果為真,後面的就不再計算。
}29、位運算子:“|”,“&”,“^”,”~”,”>>”,”<<”
1》位操作需要用巨集定義好後再使用。
2》如果位操作符“~”和“<<”應用於基本型別無符號字元型或無符號短整形的運算元,結果會立即轉換成運算元的基本型別。
3》位運算子不能用於基本型別是有符號的運算元上。
4》一元減運算子不能用在計本型別無符號的表示式上,除非在使用之前對兩個運算元進行大小判斷,且被減數必須大於減數。
30、左移、右移
1》0x01<<2+3;//+優先順序高於<<,所以結果是32
2》0x01<<2+30 或者 0x01<<2-3
3》上述兩個操作均會報錯,因為一個整數長度為32位,左移32位發生溢位,右移-1位也會溢位。
4》所以左移和右移的位數,不能大於和等於資料的長度,不能小於0.
31、++、–
1》++、–作為字首,先自加或者自減,再做其他運算。
2》逗號表示式,i在遇到每一個分號後,認為本計算單元已經結束,i這個時候自加。
int main()
{
int i = 2;
int j = 0;
j = (i++, i++, i++);
return 0;
}最後:i=2+1+1+1=5;j=2+1+1=4.
3》也就是說字尾運算是在本單元計算結束後再自加自減的。
int main()
{
int i = 2;
int j = 0;
j = (i++)+(i++)+(i++);
return 0;
}最後:j=2+2+2=6;i=2+1+1+1=5;
32、

33、貪心演算法:
C語言有這樣一個規則,每個符號應該包含儘可能多的字元。也就是說,編譯器將程式分解成符號的方法是:從左到右一個一個讀入,如果該字元可能組成一個符號,那麼再讀入下一個時,判斷已經讀入的兩個字元組成的字串是否可能是一個符號的組成部分;如果可能,繼續讀入下一個字元,重複上述判斷,知道讀入的字元組成的字串已經不再可能組成一個有意義的符號。
需要注意的是:除了字串和字元常量,符號的中間不能嵌有空白(空格、製表符、換行符等)。
34、
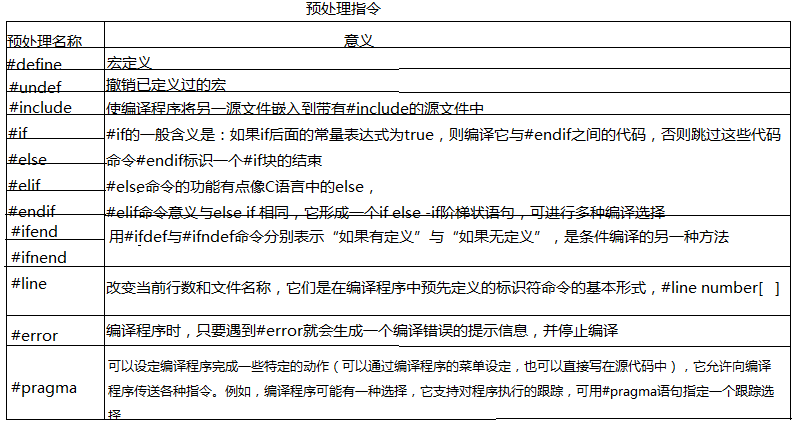
35、預處理指令:
36、用define巨集定義註釋符號
看下這個例子:
#define BSC //
#define BMC /*
#define BMC */
1>BSC my single-line comment
2>BMC my multi-line comment EMC
1和2都錯了,為什麼呢?因為註釋先於預處理指令被處理,當這兩行被展開成“//…” 或者 “/* ……/”時,註釋已經處理完畢,此時再出現“//…” 或者 “/ ……*/”時自然錯誤。因此,試圖用巨集開始或者結束一段註釋是不行的。
37、注意:函式巨集被呼叫時是以實參代換形參,而不是“值傳送”。
38、#undef
#undef是用來撤銷巨集定義的,也就是說巨集的生命週期從#define 到 #undef結束。
39、檔案包含:
1》它實際上是巨集替換的延伸。有兩種格式:#include 和 #include ” filename”
2》第一種,表示預處理到系統規定的路徑中去獲得這個檔案 ,找到檔案後,用檔案內容替換該語句。
3》第二種,雙引號表示預處理應該在當前目錄中查詢檔名為filename的檔案;如沒有找到,則按系統指定的路徑資訊搜尋其他目錄。找到檔案後,用檔案的內容替換該語句。
4》需要注意:#include是將已存在檔案的內容嵌入到當前檔案中,
5》另外,include支援相對路徑
40、#error預處理
1》#error預處理指令的作用是:編譯程式時,只要遇到#error就會生成一個編譯錯誤提示資訊,並停止編譯
2》其語法格式: #error error-message 注意 error-message 不用雙引號包圍
41、#line預處理
1》#line的作用是改變當前行數和檔名稱,他們是在編譯程式中預先定義的識別符號
2》命令的基本形式:#line number[“fliename”] ,例如 #line 30 a.h,其中檔名 a.h可以省略不寫。
42、#pragma預處理:設定編譯器的狀態,或者指定編譯器完成一些特定的動作
1》#pragma message :能夠在編譯資訊輸出視窗中輸出相應的資訊,他的用法:#pragma message(“訊息文字”)
例如:
#ifdef _X86
#pragma message(“_X86 macro activated”)
#endif
當我們定義了這個巨集後,編譯器就會在視窗提示這個資訊,就不用再但心是否定義過這個巨集了沒
2》#pragma code_seg:能夠設定程式中函式程式碼存放的程式碼段,開發驅動程式的時候會使用到
例如:
#pragma code_seg( [“section-name”[,”section-class”] ] )
3》#pragma once:在標頭檔案的最開始加入,可以保證標頭檔案只被編譯一次
4》#pragma hdrstop:表示預編譯標頭檔案到此為止,後面的標頭檔案不進行預編譯。
有時單元之間有依賴關係,比如單元A依賴單元B,所以單元B要先於單元A進行編譯,你可以用#pragma startup指定編譯優先順序,
5》#pragma resource:#pragma resource “. dfm”表示把.dfm檔案中的資源加入工程。 .dfm包括窗體外觀的定義。
6》#pragma warning
例如:#pragma warning (disable:4507 34; once: 4385;error:164)
等價於:#pragma warning(disable; 4507 34) //不顯示4507 和34號警告資訊
#pragma warning(once : 4385) //4385號警告資訊只顯示一次
#pragma warning(errror:164) //吧164號警告資訊作為一個錯誤
7》#pragma comment:該指令將一個註釋記錄放入一個物件檔案或可執行檔案中。
例如:#pragma comment( lib . “user32.lib”),該指令用來將user32.lib庫檔案加入到本工程中。
8》#pragma pack(n):設定記憶體對齊數
43、“#”運算子:
例如: #defien SQR(x) printf(“The square of x is %d\n”, ((x)*(x)) )
輸入:SQR(8)
輸出: The square of x is 64
這裡的x並沒有被替換,要修改這種情況,可以加上#
例如: #defien SQR(x) printf(“The square of “#x” is %d\n”, ((x)*(x)) )
輸入:SQR(8)
輸出: The square of 8 is 64
44、“##”運算子:可以用於函式巨集的替換部分,可以把兩個語言符號組合成單個語言符號。
例如;#define XNAME(n) x##n
如果這樣使用巨集:XNAME(8)
則展開就會是: x8
45、注意:在單一的巨集定義中,最多可以出現一次“#”或者“##”,但“##”不能隨意粘合任意字元,必須是合法的C語言識別符號
46、指標和陣列的定義雨宣告:
注意:定義和宣告的區別:定義分配記憶體、而宣告沒有;定義只能定義一次,可以宣告多次
1》定義為陣列,宣告為指標:
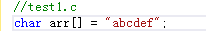


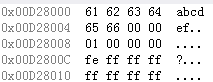
extern char* arr;——編譯器認為a是一個指標變數,佔4個位元組。
1》0x00D28000這個地址並沒有用到,而是編譯器按照int型別的取值方法一次性取出前4個位元組的值,得到0x64636261
2》地址0x64636261上的內容,按照char型別讀/寫。但是這個地址並非是一個有效地址。退一步即使是一個有效地址那也不是我們想要的。
3》應該用 (char*)&arr 取出“abcdef\0”的值
2》定義為陣列,宣告為指標
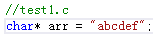

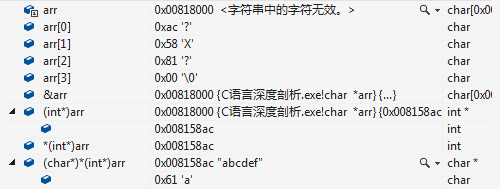
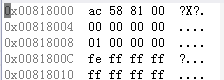
在檔案1中,編譯器分配4位元組空間,並命名為arr;同時arr裡儲存了字串常量“abcdef”的首字元的首地址,這個字元創常量本身儲存在記憶體的靜態區,其內容不可以更改。
在檔案2中,編譯器認為arr是一個陣列,其大小為4個位元組,陣列裡儲存的是char型別的資料。
1》指標arr裡儲存的是字串常量的地址,0xac588100,而arr本身的地址(0x00818000)並沒有用到。
2》編譯器把指標便令arr當做一個包含4個char型別資料的陣列來使用,按char型別取出arr[0],arr[1],arr[2],arr[3]的值為0xac,0x58,0x81,0x00
但這個並非我們所要的某塊記憶體的地址。如果給arr[i]賦值會把原來arr中保持的真正地址覆蓋,導致再也無法找出其原來指向的記憶體。
3》應該用 (char*)(int)arr 取出“abcdef\0”的值。
注意:以後一定要確認你的程式碼在一個地方定義為指標,在另一個地方只能宣告為指標;在一個地方定義為陣列,在另一個地方只能宣告為陣列。
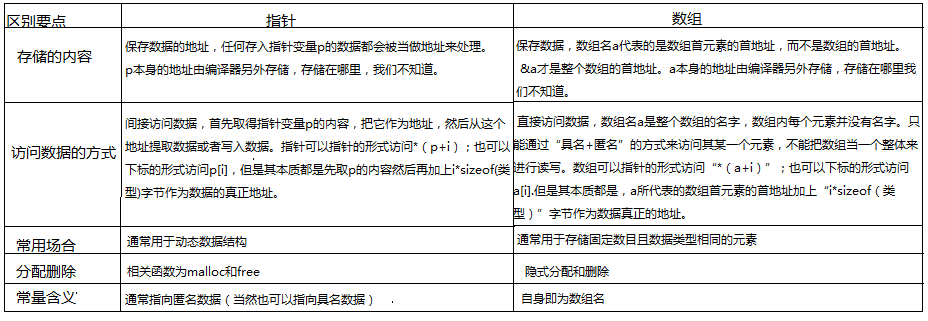
47、指標和陣列的特性
48、指標陣列和陣列指標
1》指標陣列:( int *p1[10]; )首先它是一個陣列,陣列的元素都是指標,陣列佔多少位元組由陣列本身決定。它是“儲存指標的陣列”的簡稱
2》陣列指標:( int (*p2)[10]; )首先它是一個指標,它指向一個陣列。在32位系統下永遠佔4位元組,至於它指向的陣列佔多少位元組並不知道。它是
“指向指標的陣列”的簡稱。
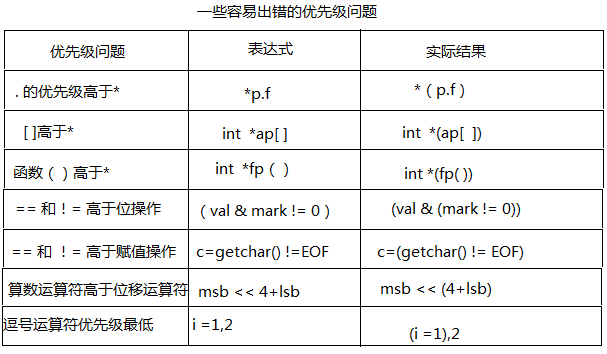
注意:這裡需要明白一個符號之間的優先順序問題,
“[ ]”的優先順序比“”的優先順序高,p1先於[ ]結合,構成陣列的定義,陣列名為p1,int修飾的是陣列的內容,即陣列的每一個元素。即p1是一個陣列其包含10個指向int型別資料的指標,即指標陣列。
至於p2 *和p2構成一個指標的定義,指標變數名為p2,int修飾的是陣列的內容,即陣列的每一個元素。即p2是一個指標,它指向一個包含10個int型別資料的陣列,即陣列指標。
49、
struct Test
{
int Num;
char *pcName;
short sDate;
char cha[2];
short sba[4];
}*p;
int main()
{
printf( "%x\n", p + 0x1);
printf( "%x\n", (unsigned long)p + 0x1);
printf( "%x\n", (unsigned int*)p + 0x1);
return 0;
}假設p的值為0x100000,sizeof(Test)=20
1》p+0x1:即為0x100000+0x1*sizeof(Test)=0x100014
2》(unsigned long)p+0x1:這裡涉及強制型別轉換,將指標變數p儲存的值強制轉換成無符號的長整型數。所以這個表示式就是一個無符號的長整形數加上另一個整數,其值為0x100001
3》(unsigned int )p+0x1:這裡p被強制轉換為指向無符號整型的指標,所以其值為0x10000+sizeof(unsigned int)*0x1
等於0x100004;
50、
51、二維陣列
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p = NULL ;
p = a[0];
printf( "%d", p[0]);
return 0;
}注意:這裡花括號裡巢狀的是小括號,而不是花括號。這裡是花括號裡巢狀了逗號表示式,其實就相當於 int a[3][2]={1,3,5};
52、
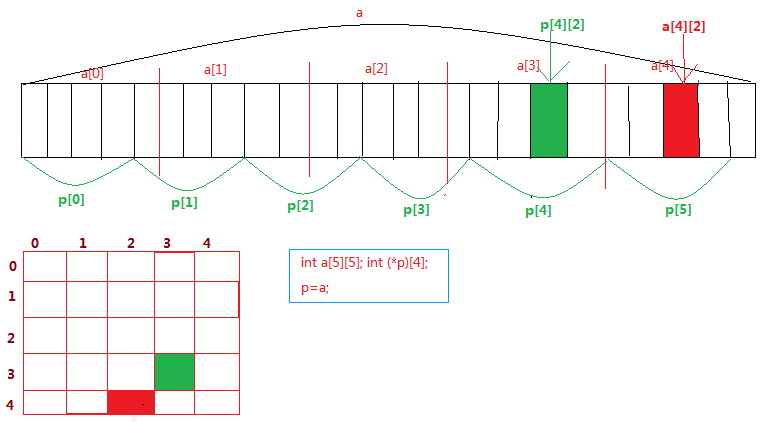
53、二級指標
一級指標儲存的是資料的地址;二級指標儲存的是一級指標的地址。
54、陣列引數和指標引數
——在C語言中,當一維陣列作為函式引數的時候,編譯器總是把它解析成一個指向其首元素地址的指標。
55、一級指標引數
1》能否把指標變數本身傳遞給一個函式
void fun(char *p)
{
char c = p [3];
}
int main()
{
char *p2 = "abcdefg" ;
fun(p2);
return 0;
}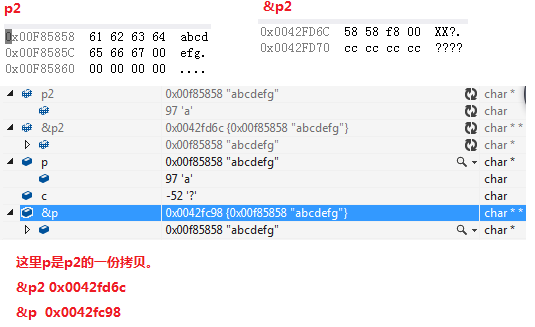
1>在這裡p2只是main函式裡的區域性變數,它只在main函式裡面有效。
2>注意:main函式裡面的變數不是全域性變數,而是區域性變數,只不過他的生命週期和全域性變數一樣長。全域性變數一定是定義在函式外部的。
3>既然是區域性變數,fun函式肯定無法使用p2的真身,函式呼叫的時候,對實參做一份拷貝並傳遞給被呼叫的函式。
2》無法把指標變數本身傳遞給一個函式
void GetMemory(char *p, int num)
{
p = (char *)malloc(num*sizeof( char));
}
int main()
{
char* str = NULL ;
GetMemory(str, 10);
strcpy(str, "hello");
free(str);
return 0;
}在執行strcpy(str,”hello”)語句的時候發生錯誤。這時候str的值任然為NULL。也就是說str本身並沒有改變,函式malloc的記憶體地址並沒有賦給str,而是賦給了_str.而這個_str是系統自動分配收回的,我們根本無法使用。所以free(str)並沒有起作用,發生了記憶體洩漏。
這裡有兩個方法可以獲取函式中分配的記憶體:
1>用return
#include <string.h>
char* GetMemory(char *p, int num)
{
p = (char *)malloc(num*sizeof( char));
return p ;
}
int main()
{
char* str = NULL ;
str=GetMemory(str, 10);
strcpy(str, "hello");
free(str);
return 0;
} 注意:1>函式返回值型別為char* 2>主函式裡需要接受函式的返回值
2>用二級指標
#include <string.h>
void GetMemory(char * * p, int num)
{
* p = (char *)malloc(num*sizeof( char));
}
int main()
{
char* str = NULL ;
GetMemory(&str, 10);
strcpy(str, "hello");
free(str);
return 0;
}注意:這裡的引數是&str而不是str。這樣的話傳遞過去的是str的地址,是一個值。在函式內部用 “”來開鎖:(&str),其值就是str。所以malloc分配的記憶體地址是真正賦給了str本身。
56、函式指標
1》定義一個函式指標:
char* (*fun)(char* p1,char* p2);2》使用一個函式指標
char* fun(char* p1, char* p2)
{
int i = 0;
i = _strcmp(p1, p2);
if (0 == i)
{
return p1;
}
else
{
return p2;
}
}
int main()
{
char* (*pf)(char* p1, char* p2);//定義一個函式指標
char *ret = NULL;
pf = &fun;
ret=(*pf)("aa", "bb");
return 0;
}注意:使用指標時,需要通過鑰匙“*”來取其指向的記憶體裡面的值,函式指標也是如此。通過用(*pf)取出存在這個地址上的函式,然後呼叫它。
57、(int)&p——這是什麼?
void FunTest()
{
printf( "Call FunTest" );
}
int main()
{
void (*p)();
*( int *)&p = (int )FunTest;
(*p)();
return 0;
} 1> void (*p)();
——這行程式碼定義了一個指標變數p,p指向一個函式,這個函式的引數和返回值都是void。
2>&p
——&p是求指標變數p本身的地址,這是一個32位的二進位制常數。
3>(int*)&p
——表示將地址強制轉換成指向int型別資料的指標。
4>(int)FunTest
——表示將函式的入口地址強制轉換成int型別的資料。
5>*(int*)&p=(int)FunTest;
——表示將函式的入口地址賦值給變數p。
6>(*p)()
——表示對函式的呼叫。
58、(*(void(*)())0)()——這是什麼?
1>void(*)(); (void(*)())0;
——這是一個函式指標型別,這個函式沒有引數,沒有返回值
2> ((void()())0)
——這是將0強制轉換為函式指標型別,0是一個地址,也就是說這個函式儲存在首地址為0的一段區域內的函式。
3> ((void()())0)()`
——這是取0地址開始的一段記憶體裡面的內容,其實就是儲存在首地址為0的一段區域內的函式
4>
——這是函式的呼叫
59、函式指標陣列
int *p1[10];//指標陣列char* (*pf[3])(char* p);這是定義一個函式指標陣列,它是一個陣列,陣列名為pf,陣列記憶體儲了3個指向函式的指標。這些指標指向一些返回值為指向字元的指標,引數為一個指向字元的指標,的函式。
60、函式指標陣列指標
int (*p1)[10];//陣列指標char* (*(*pf)[3])(char* p);這裡的pf是一個指標。這個指標指向一個包含了3三個元素的陣列,這個陣列裡面存的是指向函式的指標;這些指標指向一些返回值型別為(char*)指向字元的指標,引數為(char*)一個指向字元的指標,的函式。
61、堆、棧和靜態區
1. 堆:由maollc系列函式或new操作符分配的記憶體。其生命週期由free或者delete決定。在沒有釋放之前一直存在,直到程式結束。其特點是使用靈活,空間比較大,但是容易出錯。
2. 棧:儲存區域性變數。棧上的內容只在函式的範圍記憶體在當函式執行結束時,這些內容也會自動銷燬。其特點是效率高,但空間大小有限。
3. 靜態區:儲存自動全域性變數和static變數(包括static全域性和區域性變數)。靜態區的內容在整個程式的生命週期都存在,由編譯器在編譯的時候分配。
62、函式的入口校驗
1. 一般在函式入口處使用assert(NULL!=p)對引數進行校驗,在非引數的地方使用if(NULL!=p)來校驗。但是這都有要求,即p在定義的時候被初始化為NULL。
2. assert是一個巨集,而不是函式。包含在assert.h的標頭檔案中。如果其後括號裡的值為假,則程式終止執行,並提示錯誤;如果為真,則繼續執行後續程式碼。這個巨集只是在Debug版本里起作用,而在Relese版本里被編譯器完全優化掉,這樣就不會影響程式碼的效能
63、memset(a,0,sizeof(a))
memset有3個引數:第一個引數是要被設定的記憶體起始地址;第二個引數要被設定的值;第三個引數是要被設定的記憶體大小,單位為位元組。
64、malloc函式
先看一下malloc函式的原型:
(void*)malloc(int size);
malloc函式的返回值是一個void型別的指標,引數為int型別的資料,即申請分配的記憶體大小,單位是位元組。記憶體分配成功之後,malloc函式返回這塊記憶體的首地址,你需要一個指標來接收這個地址。但由於函式的返回值是void*型別的,所以必須要強制轉換成你所要接收的型別。
比如:
char* p=(char*)malloc(100);在堆上分配了100位元組的記憶體,返回這苦啊記憶體的首地址,把地址強制轉換為(char*)型別後賦給(char*)型別的指標變數p;同時告訴我們這塊記憶體將用來儲存char型別的資料。也就是說只能通過指標變數p來操作這塊記憶體。這塊記憶體本身並沒有名字,對它的訪問是匿名的。
但是,並不是每一次記憶體分配都是成功的,所以在我們使用只想這塊記憶體的指標時,必須用if(NULL != p)語句來驗證記憶體確實分配成功了。
65、用malloc函式申請0位元組記憶體
申請0位元組記憶體並,函式不會返回NULL,而是返回一個正常地址,但是你卻無法使用這塊大小為0的記憶體。
對於這一點要小心,因為這個時候if(NULL != p)語句檢驗將不起作用。
相關文章
- 【C語言深度剖析】讀書筆記之 signed ,unsignedC語言筆記
- C語言深度剖析-筆記C語言筆記
- C語言程式設計讀書筆記:結構C語言程式設計筆記
- 《深度探索C++物件模型》讀書筆記C++物件模型筆記
- 【記】《.net之美》之讀書筆記(一) C#語言基礎筆記C#
- 讀書寫筆記-王爽《組合語言》筆記組合語言
- 好語言,就該善用它——《C++語言的設計與演化》讀書筆記C++筆記
- 《深度探索c++記憶體模型》讀書筆記 (二)C++記憶體模型筆記
- c語言筆記C語言筆記
- 《深入剖析Tomcat》讀書筆記(一)Tomcat筆記
- 《深入剖析Tomcat》讀書筆記(二)Tomcat筆記
- 《論語》讀書筆記筆記
- 《Go 語言程式設計》讀書筆記(四)介面Go程式設計筆記
- 《Go 語言程式設計》 讀書筆記 (八) 包Go程式設計筆記
- 《Go 語言程式設計》讀書筆記(十)反射Go程式設計筆記反射
- 《Go 語言程式設計》讀書筆記 (三) 方法Go程式設計筆記
- 讀書筆記:組合語言(王爽)實驗七筆記組合語言
- C程式設計語言讀書筆記:型別運算子與表示式C程式程式設計筆記型別
- swift語法-讀書筆記Swift筆記
- 《Go 語言程式設計》讀書筆記 (二)函式Go程式設計筆記函式
- C++讀書筆記:字串C++筆記字串
- 《Effective C#》讀書筆記C#筆記
- 《Effective C++》讀書筆記C++筆記
- 深度學習讀書筆記之RBM深度學習筆記
- C 語言學習筆記筆記
- C語言學習筆記C語言筆記
- C語言指標筆記C語言指標筆記
- 《Go 語言程式設計》讀書筆記 (九) 命令工具集Go程式設計筆記
- 《C缺陷與陷阱》讀書筆記筆記
- C陷阱與缺陷--讀書筆記筆記
- 《More Effective C#》讀書筆記C#筆記
- 《C與指標》讀書筆記指標筆記
- 《Go 語言程式設計》讀書筆記 (五) 協程與通道Go程式設計筆記
- C語言學習筆記--C運算子C語言筆記
- 《Go 語言程式設計》讀書筆記(十一)底層程式設計Go程式設計筆記
- 《Java8函數語言程式設計》讀書筆記---類庫Java函數程式設計筆記
- c語言-記錄閱讀《c缺陷與陷阱》C語言
- 讀書筆記...筆記