Producer API
org.apache.kafka.clients.producer.KafkaProducer
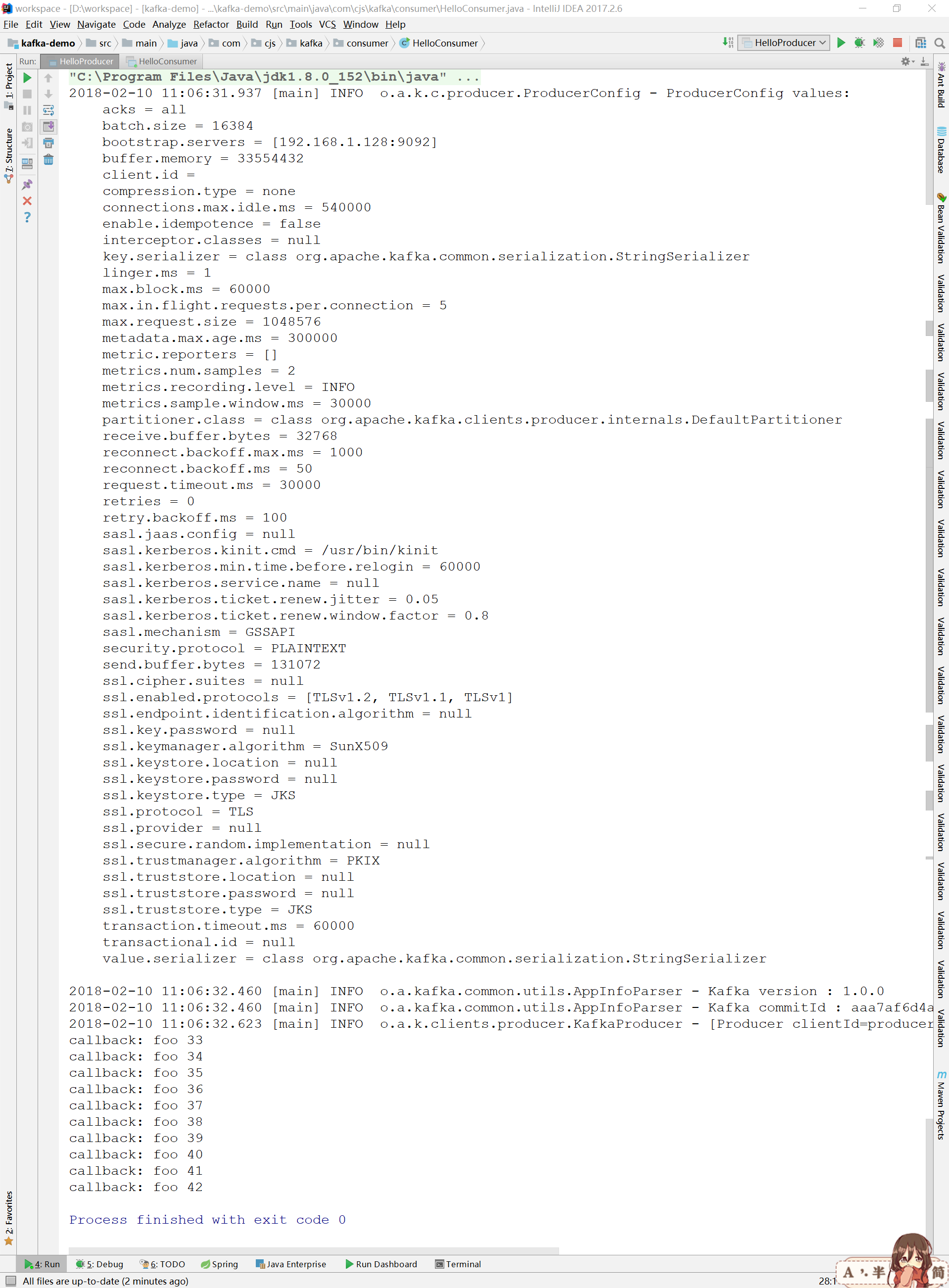
1 props.put("bootstrap.servers", "192.168.1.128:9092"); 2 props.put("acks", "all"); 3 props.put("retries", 0); 4 props.put("batch.size", 16384); 5 props.put("linger.ms", 1); 6 props.put("buffer.memory", 33554432); 7 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); 8 props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); 9 10 Producer<String, String> producer = new KafkaProducer<String, String>(props); 11 for (int i = 0; i < 10; i++) { 12 producer.send(new ProducerRecord<String, String>("foo", Integer.toString(i), Integer.toString(i)), new Callback() { 13 @Override 14 public void onCompletion(RecordMetadata recordMetadata, Exception e) { 15 if (null != e) { 16 e.printStackTrace(); 17 }else { 18 System.out.println("callback: " + recordMetadata.topic() + " " + recordMetadata.offset()); 19 } 20 } 21 }); 22 } 23 producer.close();
producer由一個緩衝池組成,這個緩衝池中維護著那些還沒有被傳送到伺服器上的記錄,而且有一個後臺的I/O執行緒負責將這些記錄轉換為請求並將其傳送到叢集上去。
send()方法是非同步的。當呼叫它以後就把記錄放到buffer中並立即返回。這就允許生產者批量的傳送記錄。
acks配置項控制的是完成的標準,即什麼樣的請求被認為是完成了的。本例中其值設定的是"all"表示客戶端會等待直到所有記錄完全被提交,這是最慢的一種方式也是持久化最好的一種方式。
如果請求失敗了,生產者可以自動重試。因為這裡我們設定retries為0,所以它不重試。
生產者對每個分割槽都維護了一個buffers,其中放的是未被髮送的記錄。這些buffers的大小是通過batch.size配置項來控制的。
預設情況下,即使一個buffer還有未使用的空間(PS:buffer沒滿)也會立即傳送。如果你想要減少請求的次數,你可以設定linger.ms為一個大於0的數。這個指令將告訴生產者在傳送請求之前先等待多少毫秒,以希望能有更多的記錄到達好填滿buffer。在本例中,我們設定的是1毫秒,表示我們的請求將會延遲1毫秒傳送,這樣做是為了等待更多的記錄到達,1毫秒之後即使buffer沒有被填滿,請求也會傳送。(PS:稍微解釋一下這段話,producer呼叫send()方法只是將記錄放到buffer中,然後由一個後臺執行緒將buffer中的記錄傳送到伺服器上。這裡所說的請求指的是從buffer到伺服器。預設情況下記錄被放到buffer以後立即被髮送到伺服器,為了減少請求伺服器的次數,可以通過設定linger.ms,這個配置項表示等多少毫秒以後再傳送,這樣做是希望每次請求可以傳送更多的記錄,以此減少請求次數)
buffer.memory控制的是總的buffer記憶體數量
key.serializer 和 value.serializer表示怎樣將key和value物件轉成位元組
從kafka 0.11開始,KafkaProducer支援兩種模型:the idempotent producer and the transactional producer(冪等producer和事務producer)。冪等producer強調的是至少一次精確的投遞。事務producer允許應用程式原子的傳送訊息到多個分割槽或者主題。
為了啟用冪等性,必須將enable.idempotence這個配置的值設為true。如果你這樣設定了,那麼retries預設是Integer.MAX_VALUE,並且acks預設是all。為了利用冪等producer的優勢,請避免應用程式級別的重新傳送。
為了使用事務producer,你必須配置transactional.id。如果transactional.id被設定,冪等性自動被啟用。
1 Properties props = new Properties(); 2 props.put("bootstrap.servers", "192.168.1.128:9092"); 3 props.put("transactional.id", "my-transactional-id"); 4 5 Producer<String, String> producer = new KafkaProducer<String, String>(props, new StringSerializer(), new StringSerializer()); 6 7 producer.initTransactions(); 8 9 try { 10 producer.beginTransaction(); 11 12 for (int i = 11; i < 20; i++) { 13 producer.send(new ProducerRecord<String, String>("bar", Integer.toString(i), Integer.toString(i))); 14 } 15 // This method will flush any unsent records before actually committing the transaction 16 producer.commitTransaction(); 17 } catch (ProducerFencedException | OutOfOrderSequenceException | AuthorizationException e) { 18 producer.close(); 19 } catch (KafkaException e) { 20 // By calling producer.abortTransaction() upon receiving a KafkaException we can ensure 21 // that any successful writes are marked as aborted, hence keeping the transactional guarantees. 22 producer.abortTransaction(); 23 } 24 25 producer.close();
Consumer API
org.apache.kafka.clients.consumer.KafkaConsumer
Offsets and Consumer Position
對於分割槽中的每條記錄,kafka維護一個數值偏移量。這個偏移量是分割槽中一條記錄的唯一標識,同時也是消費者在分割槽中的位置。例如,一個消費者在分割槽中的位置是5,表示它已經消費了偏移量從0到4的記錄,並且接下來它將消費偏移量為5的記錄。相對於消費者使用者來說,這裡實際上有兩個位置的概念。
消費者的position表示下一條將要消費的記錄的offset。每次消費者通過呼叫poll(long)接收訊息的時候這個position會自動增加。
committed position表示已經被儲存的最後一個偏移量。消費者可以自動的週期性提交offsets,也可以通過呼叫提交API(e.g. commitSync and commitAsync)手動的提交position。
Consumer Groups and Topic Subscriptions
Kafka用"consumer groups"(消費者組)的概念來允許一組程式分開處理和消費記錄。這些處理在同一個機器上進行,也可以在不同的機器上。同一個消費者組中的消費者例項有相同的group.id
組中的每個消費者可以動態設定它們想要訂閱的主題列表。Kafka給每個訂閱的消費者組都投遞一份訊息。這歸功於消費者組中所有成員之間的均衡分割槽,以至於每個分割槽都可以被指定到組中精確的一個消費者。假設一個主題有4個分割槽,一個組中有2個消費者,那麼每個消費者將處理2個分割槽。
消費者組中的成員是動態維護的:如果一個消費者處理失敗了,那麼分配給它的分割槽將會被重新分給組中其它消費者。
在概念上,你可以把一個消費者組想象成一個單個的邏輯訂閱者,並且每個邏輯訂閱者由多個程式組成。作為一個多訂閱系統,Kafka天生就支援對於給定的主題可以有任意數量的消費者組。
Automatic Offset Committing
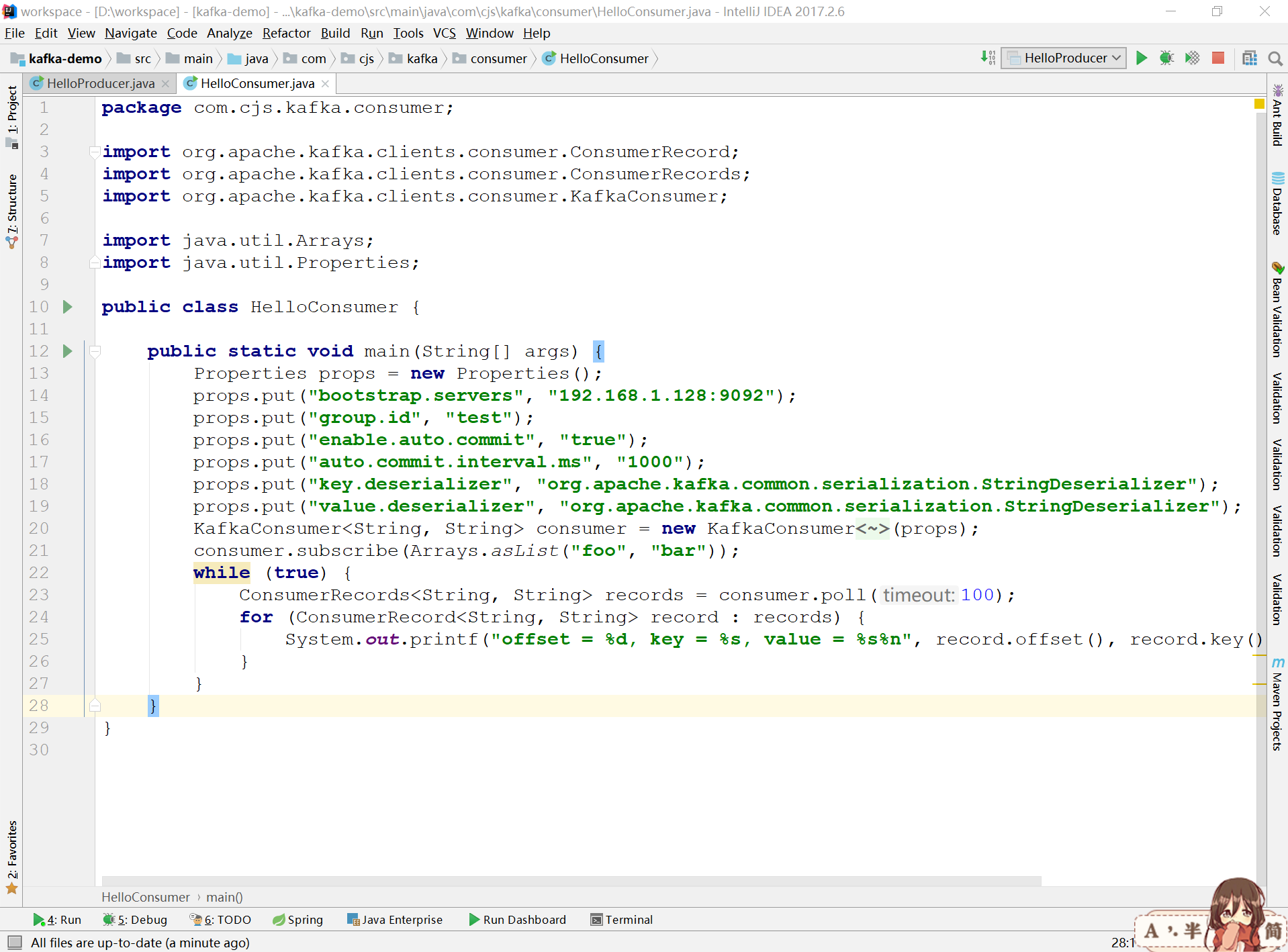
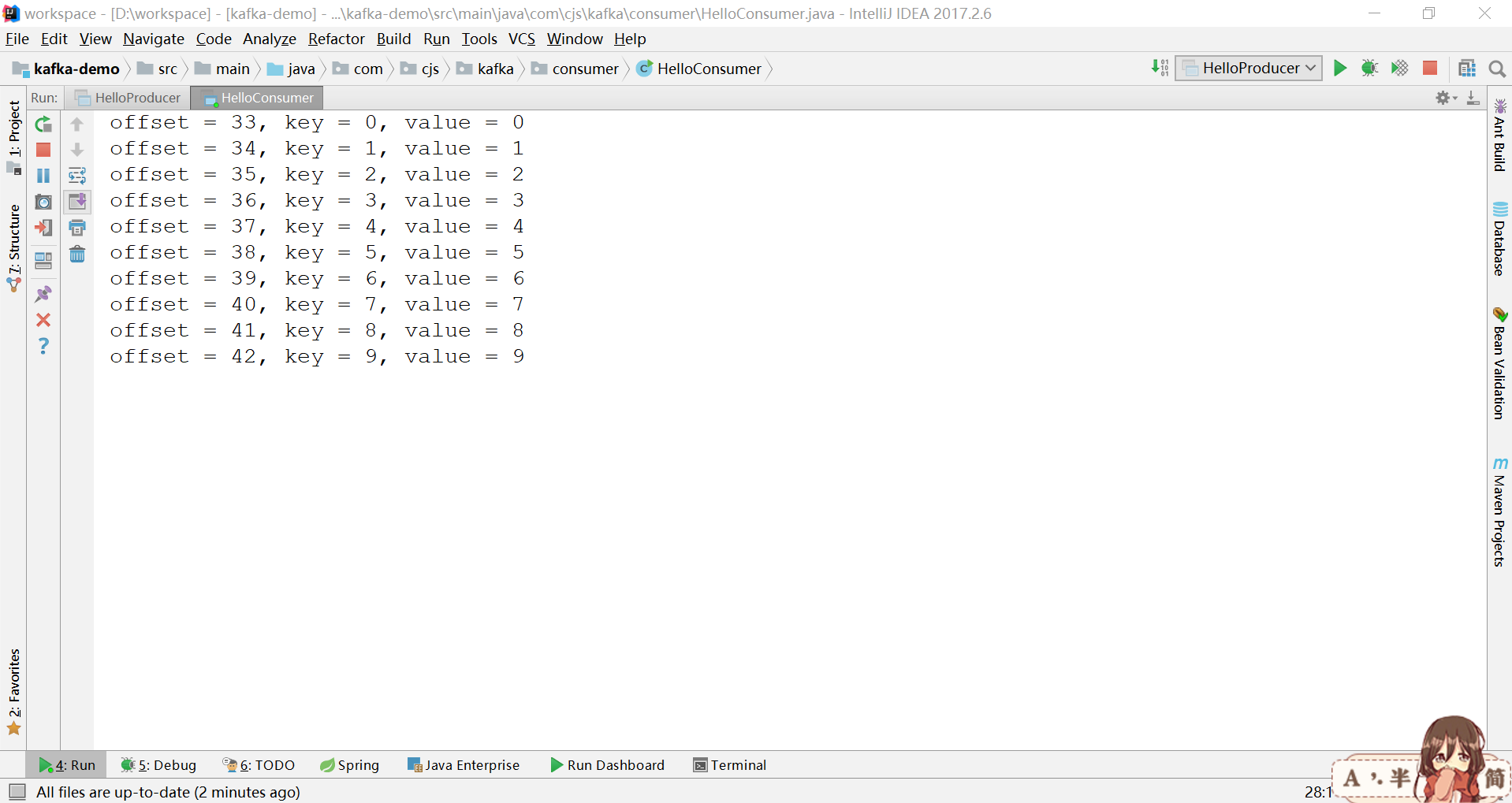
1 Properties props = new Properties(); 2 props.put("bootstrap.servers", "192.168.1.128:9092"); 3 props.put("group.id", "test"); 4 props.put("enable.auto.commit", "true"); 5 props.put("auto.commit.interval.ms", "1000"); 6 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); 7 props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); 8 KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props); 9 consumer.subscribe(Arrays.asList("foo", "bar")); 10 while (true) { 11 ConsumerRecords<String, String> records = consumer.poll(100); 12 for (ConsumerRecord<String, String> record : records) { 13 System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); 14 } 15 }
設定enable.auto.commit意味著自動提交已消費的記錄的offset
Manual Offset Control
代替消費者週期性的提交已消費的offsets,使用者可以控制什麼時候記錄被認為是已經消費並提交它們的offsets。
1 Properties props = new Properties(); 2 props.put("bootstrap.servers", "localhost:9092"); 3 props.put("group.id", "test"); 4 props.put("enable.auto.commit", "false"); 5 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); 6 props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); 7 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); 8 consumer.subscribe(Arrays.asList("foo", "bar")); 9 final int minBatchSize = 200; 10 List<ConsumerRecord<String, String>> buffer = new ArrayList<>(); 11 while (true) { 12 ConsumerRecords<String, String> records = consumer.poll(100); 13 for (ConsumerRecord<String, String> record : records) { 14 buffer.add(record); 15 } 16 if (buffer.size() >= minBatchSize) { 17 insertIntoDb(buffer); 18 consumer.commitSync(); 19 buffer.clear(); 20 } 21 }
程式碼演示
伺服器端
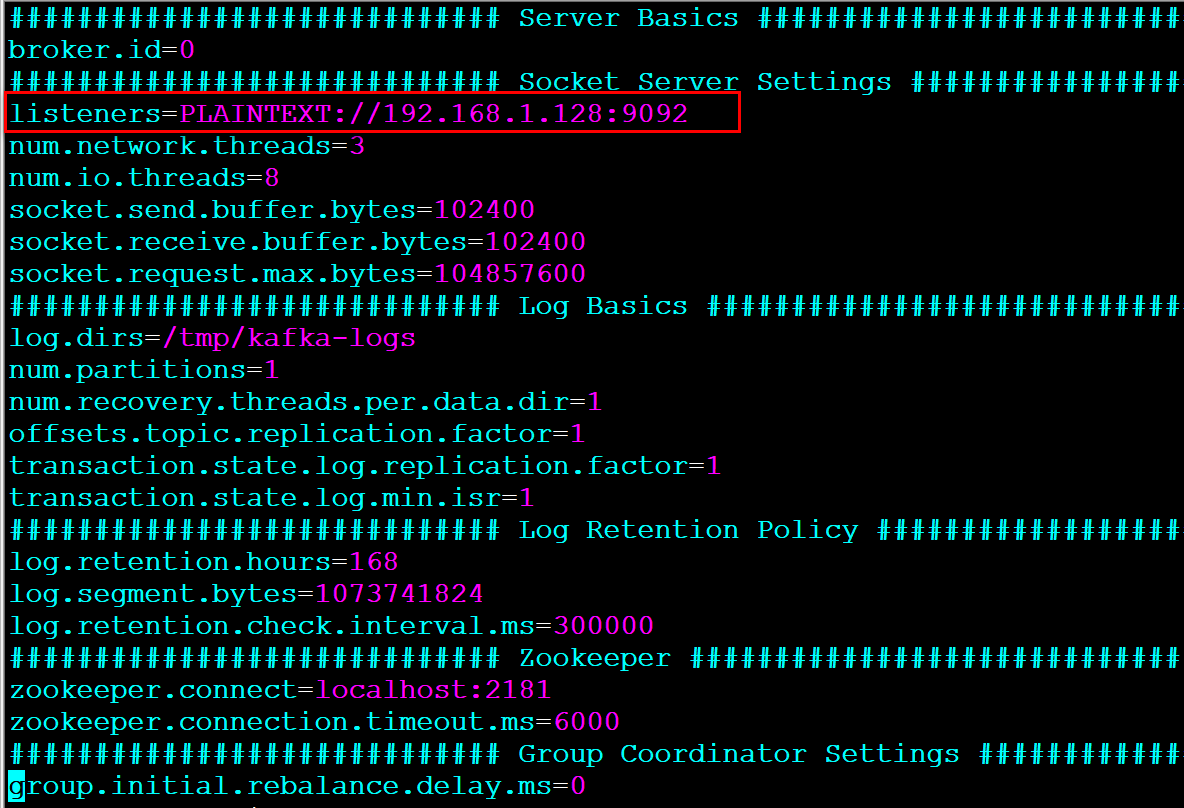
客戶端


參考
http://kafka.apache.org/10/javadoc/index.html?org/apache/kafka/clients/producer/KafkaProducer.html
http://kafka.apache.org/10/javadoc/index.html?org/apache/kafka/clients/consumer/KafkaConsumer.html