
在MapReduce整個過程可以概括為以下過程:
輸入 --> map --> shuffle --> reduce -->輸出
輸入檔案會被切分成多個塊,每一塊都有一個map task
map階段的輸出結果會先寫到記憶體緩衝區,然後由緩衝區寫到磁碟上。預設的緩衝區大小是100M,溢位的百分比是0.8,也就是說當緩衝區中達到80M的時候就會往磁碟上寫。如果map計算完成後的中間結果沒有達到80M,最終也是要寫到磁碟上的,因為它最終還是要形成檔案。那麼,在往磁碟上寫的時候會進行分割槽和排序。一個map的輸出可能有多個這個的檔案,這些檔案最終會合併成一個,這就是這個map的輸出檔案。
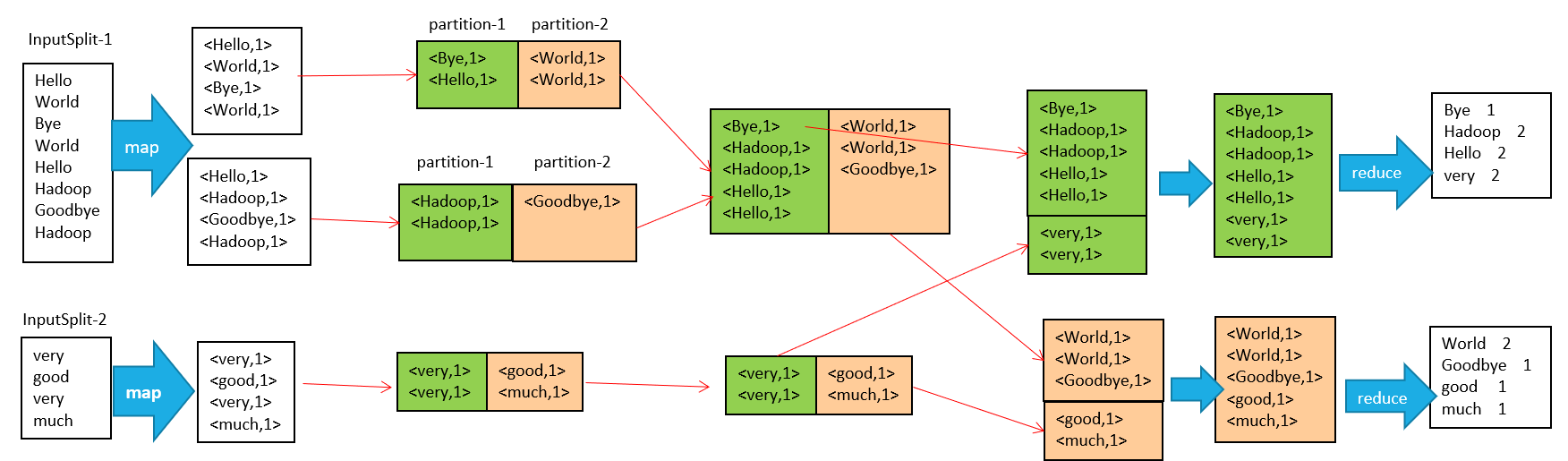
流程說明如下:
1、輸入檔案分片,每一片都由一個MapTask來處理
2、Map輸出的中間結果會先放在記憶體緩衝區中,這個緩衝區的大小預設是100M,當緩衝區中的內容達到80%時(80M)會將緩衝區的內容寫到磁碟上。也就是說,一個map會輸出一個或者多個這樣的檔案,如果一個map輸出的全部內容沒有超過限制,那麼最終也會發生這個寫磁碟的操作,只不過是寫幾次的問題。
3、從緩衝區寫到磁碟的時候,會進行分割槽並排序,分割槽指的是某個key應該進入到哪個分割槽,同一分割槽中的key會進行排序,如果定義了Combiner的話,也會進行combine操作
4、如果一個map產生的中間結果存放到多個檔案,那麼這些檔案最終會合併成一個檔案,這個合併過程不會改變分割槽數量,只會減少檔案數量。例如,假設分了3個區,4個檔案,那麼最終會合併成1個檔案,3個區
5、以上只是一個map的輸出,接下來進入reduce階段
6、每個reducer對應一個ReduceTask,在真正開始reduce之前,先要從分割槽中抓取資料
7、相同的分割槽的資料會進入同一個reduce。這一步中會從所有map輸出中抓取某一分割槽的資料,在抓取的過程中伴隨著排序、合併。
8、reduce輸出