1.概述
在開發工作當中,提交 Hadoop 任務,任務的執行詳情,這是我們所關心的,當業務並不複雜的時候,我們可以使用 Hadoop 提供的命令工具去管理 YARN 中的任務。在編寫 Hive SQL 的時候,需要在 Hive 終端,編寫 SQL 語句,來觀察 MapReduce 的執行情況,長此以往,感覺非常的不便。另外隨著業務的複雜化,任務的數量增加,此時我們在使用這套流程,已預感到力不從心,這時候 Hive 的監控系統此刻便尤為顯得重要,我們需要觀察 Hive SQL 的 MapReduce 執行詳情以及在 YARN 中的相關狀態。
因此,我們經過調研,從網際網路公司的一些需求出發,從各位 DEVS 的使用經驗和反饋出發,結合業界的一些大的開源的 Hadoop SQL 訊息監控,用監控的一些思考出發,設計開發了現在這樣的監控系統:Hive Falcon。
Hive Falcon 用於監控 Hadoop 叢集中被提交的任務,以及其執行的狀態詳情。其中 Yarn 中任務詳情包含任務 ID,提交者,任務型別,完成狀態等資訊。另外,還可以編寫 Hive SQL,並運 SQL,檢視 SQL 執行詳情。也可以檢視 Hive 倉庫中所存在的表及其表結構等資訊。下載地址,如下所示:
2.內容
Hive Falcon 涉及以下內容:
- Dashboard
- Query
- Tables
- Tasks
- Clients & Nodes
2.1 Dashboard
我們通過在瀏覽器中輸入 http://host:port/hf,訪問 Hive Falcon 的 Dashboard 頁面。該頁面包含以下內容:
- Hive Clients
- Hive Tables
- Hadoop DataNodes
- YARN Tasks
- Hive Clients Graph
如下圖所示:

2.2 Query
Query 模組下,提供一個執行 Hive SQL 的介面,該介面可以用來檢視觀察 SQL 執行的 MapReduce 詳情。包含 SQL 編輯區,日誌輸出,以及結果展示。如下圖所示:

提示:在 SQL 編輯區可以通過 Alt+/ 快捷鍵,快速調出 SQL 關鍵字。
2.3 Tables
Tables 展示 Hive 中所有的表資訊,包含以下內容:
- 表名
- 表型別(如:內部表,外部表等)
- 所屬者
- 存放路徑
- 建立時間
如下圖所示:

每一個表名都附帶一個超連結,可以通過該超連結檢視該表的表結構,如下圖所示:

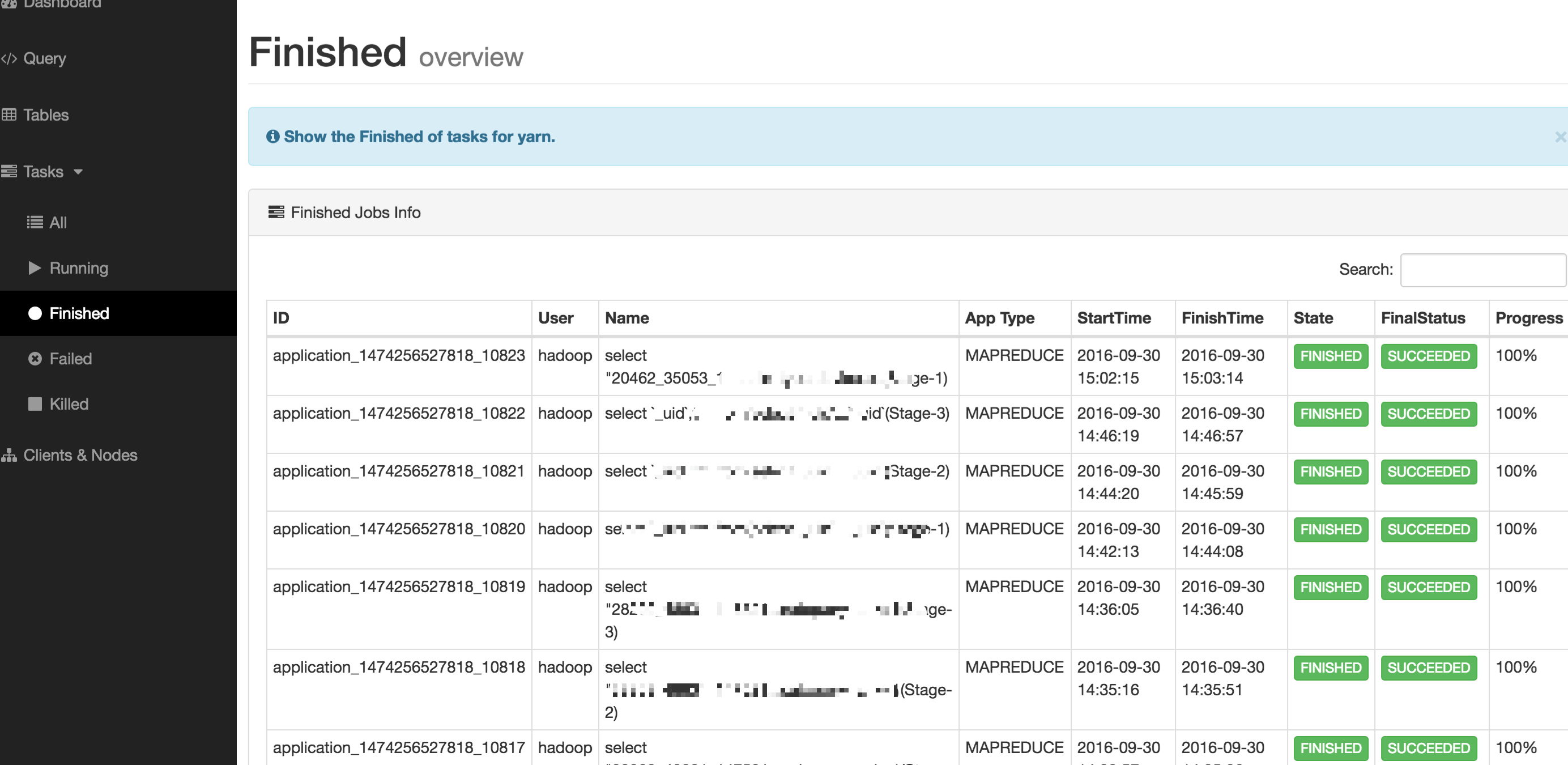
2.4 Tasks
Tasks 模組下所涉及的內容是 YARN 上的任務詳情,包含的內容如下所示:
- All(所有任務)
- Running(正在執行的任務)
- Finished(已完成的任務)
- Failed(以失敗的任務)
- Killed(已失敗的任務)
如下圖所示:
2.5 Clients & Nodes
該模組展示 Hive Client 詳情,以及 Hadoop DataNode 的詳情,如下圖所示:

2.6 指令碼命令
| 命令 | 描述 |
| hf.sh start | 啟動 Hive Falcon |
| hf.sh status | 檢視 Hive Falcon |
| hf.sh stop | 停止 Hive Falcon |
| hf.sh restart | 重啟 Hive Falcon |
| hf.sh stats | 檢視 Hive Falcon 在 Linux 系統中所佔用的控制程式碼數量 |
3.資料採集
Hive Falcon 系統的各個模組的資料來源,所包含的內容,如下圖所示:

4.總結
Hive Falcon 的安裝使用比較簡單,下載安裝,安裝文件的描述進行安裝配置即可,安裝部署文件地址,如下所示:
5.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行討論或傳送郵件給我,我會盡我所能為您解答,與君共勉!