1.概述
在編寫 Flink,Spark,Hive 等相關作業時,要是能快速的將我們所編寫的作業能視覺化在我們面前,是件讓人興奮的時,如果能帶上趨勢功能就更好了。今天,給大家介紹這麼一款工具。它就能滿足上述要求,在使用了一段時間之後,這裡給大家分享以下使用心得。
2.How to do
首先,我們來了解一下這款工具的背景及用途。Zeppelin 目前已託管於 Apache 基金會,但並未列為頂級專案,可以在其公佈的 官網訪問。它提供了一個非常友好的 WebUI 介面,操作相關指令。它可以用於做資料分析和視覺化。其後面可以接入不同的資料處理引擎。包括 Flink,Spark,Hive 等。支援原生的 Scala,Shell,Markdown 等。
2.1 Install
對於 Zeppelin 而言,並不依賴 Hadoop 叢集環境,我們可以部署到單獨的節點上進行使用。首先我們使用以下地址獲取安裝包:
這裡,有2種選擇,其一,可以下載原檔案,自行編譯安裝。其二,直接下載二進位制檔案進行安裝。這裡,為了方便,筆者直接使用二進位制檔案進行安裝使用。這裡有些引數需要進行配置,為了保證系統正常啟動,確保的 zeppelin.server.port 屬性的埠不被佔用,預設是8080,其他屬性大家可按需配置即可。[配置連結]
2.2 Start/Stop
在完成上述步驟後,啟動對應的程式。定位到 Zeppelin 安裝目錄的bin資料夾下,使用以下命令啟動程式:
./zeppelin-daemon.sh start
若需要停止,可以使用以下命令停止程式:
./zeppelin-daemon.sh stop
另外,通過閱讀 zeppelin-daemon.sh 指令碼的內容,可以發現,我們還可以使用相關重啟,檢視狀態等命令。內容如下:
case "${1}" in start) start ;; stop) stop ;; reload) stop start ;; restart) stop start ;; status) find_zeppelin_process ;; *) echo ${USAGE}
3.How to use
在啟動相關程式後,可以使用以下地址在瀏覽器中訪問:
http://<Your_<IP/Host>:Port>
啟動之後的介面如下所示:

該介面羅列出外掛繫結項。如圖中的 spark,md,sh 等。那我如何使用這些來完成一些工作。在使用一些資料引擎時,如 Flink,Spark,Hive 等,是需要配置對應的連線資訊的。在 Interpreter 欄處進行配置。這裡給大家列舉一些配置示例:
3.1 Flink
可以找到 Flink 的配置項,如下圖所示:

然後指定對應的 IP 和地址即可。
3.2 Hive
這裡 Hive 配置需要指向其 Thrift 服務地址,如下圖所示:

另外,其他的外掛,如 Spark,Kylin,phoenix等配置類似,配置完成後,記得點選 “restart” 按鈕。
3.3 Use md and sh
下面,我們可以建立一個 Notebook 來使用,我們拿最簡單的 Shell 和 Markdown 來演示,如下圖所示:
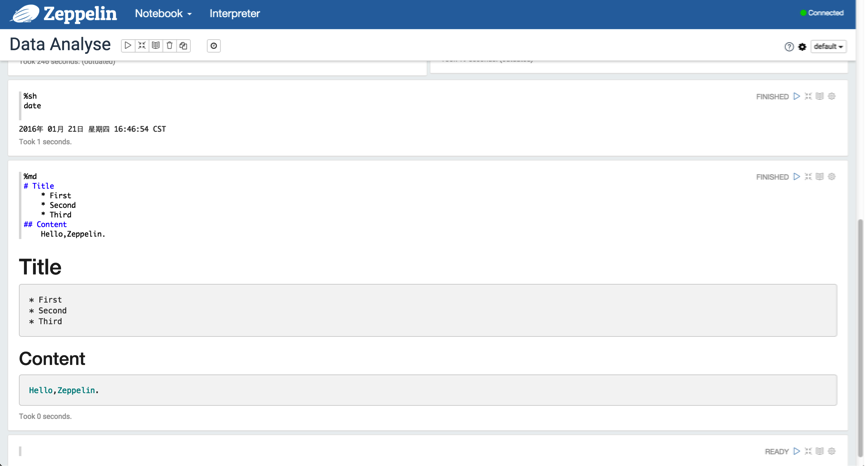
3.4 SQL
當然,我們的目的並不是僅僅使用 Shell 和 Markdown,我們需要能夠使用 SQL 來獲取我們想要的結果。
3.4.1 Spark SQL
下面,我們使用 Spark SQL 去獲取想要的結果。如下圖所示:

這裡,可以將結果以不同的形式來視覺化,量化,趨勢,一目瞭然。
3.4.2 Hive SQL
另外,可以使用動態格式來查詢分割槽資料,以"${partition_col=20160101,20160102|20160103|20160104|20160105|20160106}"的格式進行表示。如下圖所示:
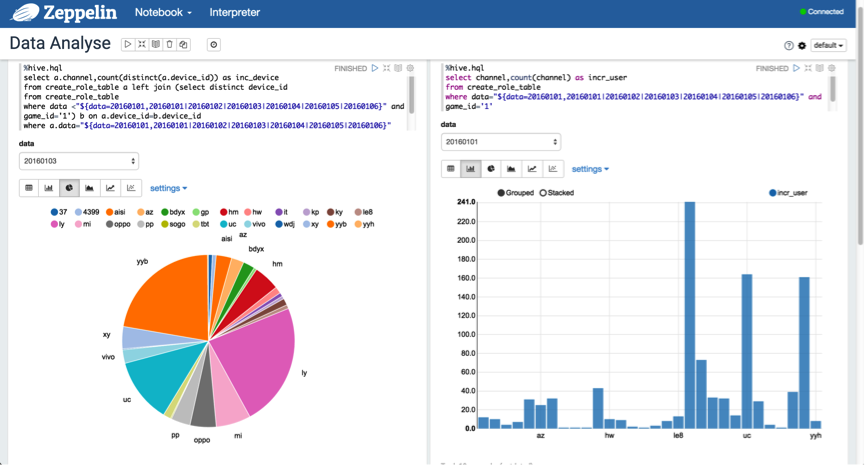
3.5 Video Guide
另外,官方也給出了一個快速指導的入門視訊,觀看地址:[入口]
4.總結
在使用的過程當中,有些地方需要注意,必須在編寫 Hive SQL 時,%hql 需要替換為 %hive.sql 的格式;另外,在執行 Scala 程式碼時,如果出現以下異常,如下圖所示:

解決方案,在 zeppelin-env.sh 檔案中新增以下內容:
export ZEPPELIN_MEM=-Xmx4g
該 BUG 在 0.5.6 版本得到修復,參考碼:[ZEPPELIN-305]
5.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行討論或傳送郵件給我,我會盡我所能為您解答,與君共勉!