1.概述
Apache Kylin是一個開源的分散式分析引擎,提供SQL介面並且用於OLAP業務於Hadoop的大資料集上,該專案由eBay貢獻於Apache。
2.What is Kylin
在使用一種模型,我們得知道她是幹什麼的,那麼首先來看看Kylin的特性,其內容如下所示:
- 可擴充套件超快的OLAP引擎:Kylin是為減少在Hadoop上百億級別資料查詢延遲而設計的。
- Hadoop ANSI SQL介面:Kylin為Hadoop提供標準的SQL,其支援大部分查詢功能。
- 出色的互動式查詢能力:通過Kylin,使用者可以於Hadoop資料進行亞秒級互動,在同樣的資料集上提供比Hive更好的效能。
- 多維度Cube:使用者能夠在Kylin裡為百億以上的資料集定義資料模型並構建Cube。
- 和BI工具無縫整合:Kylin提供與BI工具,如商業化的Tableau。另外,根據官方提供的資訊也在後續逐步提供對其他工具的支援。
- 其他特性:
- 對Job的管理和監控
- 壓縮和編碼的支援
- 增量更新Cube
- 利用HBase Coprocessor去查詢
- 基於HyperLogLog的Distinct Count近似演算法
- 友好的Web介面用於管理、監控和使用Cube
- 專案及Cube級別的訪問控制安全
- 支援LDAP
3.ECOSYSTEM
Kylin有其自己的生態圈,如下圖所示:
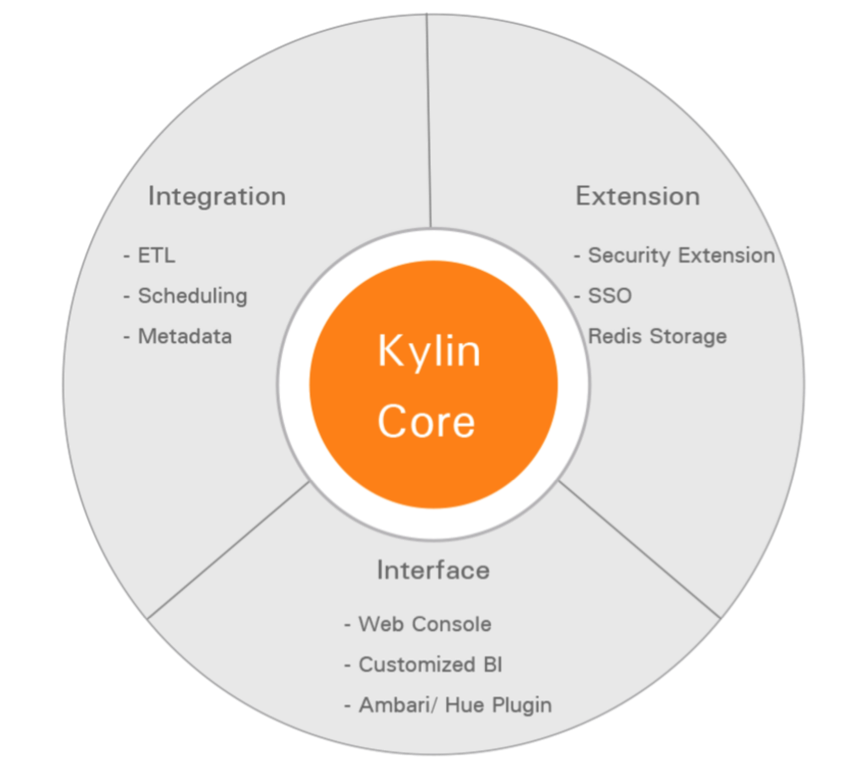
從上圖中,我們可以看到,Kylin的核心包含:Kylin OLAP引擎基礎框架,Metadata引擎,查詢引擎,Job引擎以及儲存引擎等等,同時還包括REST伺服器以響應客戶端請求。另外,還擴充套件支援額外功能和特性的外掛,同時整合與排程系統、ETL、監控等生命週期管理系統。在Kylin核心之上擴充套件的第三方使用者介面,ODBC和JDBC驅動用以支援不同的工具和產品,如:Tableau。
4.Architecture
Kylin的架構概述圖如下所示:
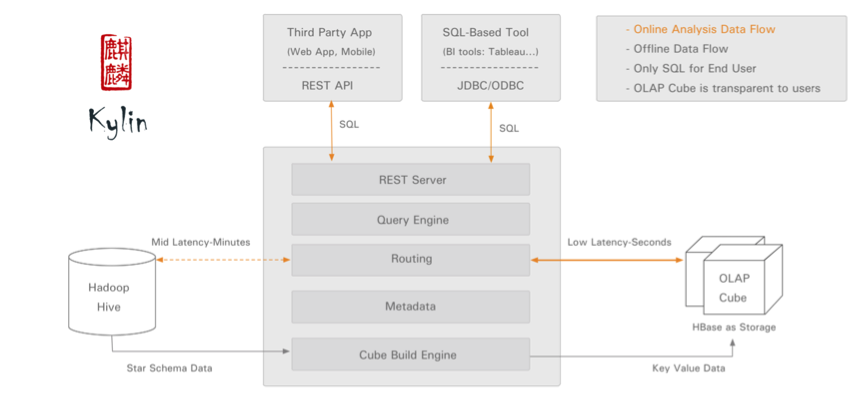
圖中的執行流程很清楚,客戶端(REST API或JDBC/ODBC)傳送SQL請求,將其交給Kylin的執行引擎去處理,Kylin去拉去對應的資料來做處理,並返回處理結果,這裡Kylin需要依賴HBase。複雜的事情,Kylin的引擎都給我們處理了,我們只需要負責去編寫我們的業務SQL。
5.How TO Works
在Kylin中,我們可以處理三維的業務查詢,如下圖所示:
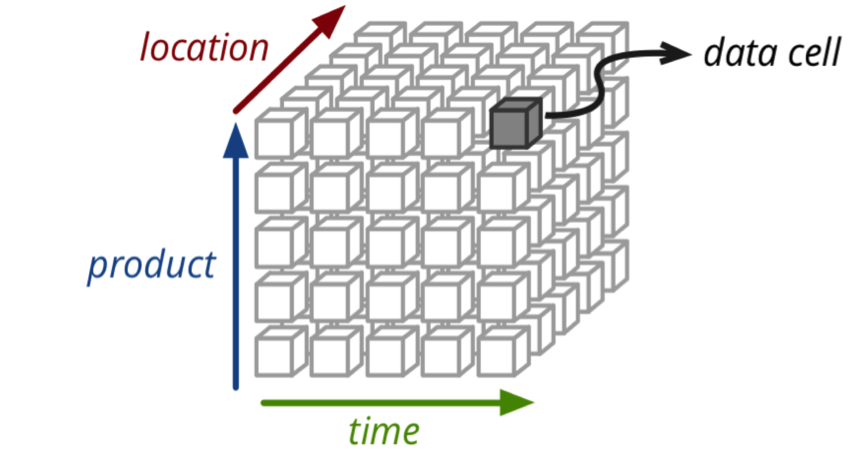
在明白了業務處理方向,其生態群和架構。我們要如何去整合該系統到Hadoop叢集?關於Kylin的整合過程是比較方便的,Kylin需要Hadoop、Hive、HBase、JDK,另外,對版本也是有要求的。本版要求如下:
- Hadoop:2.4 - 2.7
- Hive:0.13 - 0.14
- HBase:0.98(這裡若是選擇Kylin-1.2,需要用到HBase-1.1+以上)
- JDK1.7+
另外,安裝Kylin步驟也是比較簡單的,步驟如下所示:
- 下載最新的安裝包,地址如下:[Kylin.tar.gz]
- 設定KYLIN_HOME環境變數
- 確保使用者有許可權去訪問Hadoop、Hive和HBase,如果不確定的話,我們可以在安裝包的bin目錄下執行check-env.sh指令碼,如果我們有問題的話,她會列印詳細的資訊。
- 最後,我們可以通過kylin.sh start去啟動Kylin,或者使用kylin.sh stop去停止Kylin
在Kylin啟動之後,我們可以通過輸入http://node_hostname:7070/kylin去訪問Kylin,登入預設使用者名稱和密碼為:ADMIN/KYLIN
預覽截圖如下所示:
另外,我們可以通過JDBC去操作,程式碼片段如下所示:
Driver driver = (Driver) Class.forName("org.apache.kylin.jdbc.Driver").newInstance();
Properties info = new Properties();
info.put("user", "ADMIN");
info.put("password", "KYLIN");
Connection conn = driver.connect("jdbc:kylin://dn1:7070/kylin_project_name", info);
Statement state = conn.createStatement();
ResultSet resultSet = state.executeQuery("select * from test_table");
while (resultSet.next()) {
assertEquals("foo", resultSet.getString(1));
assertEquals("bar", resultSet.getString(2));
assertEquals("tool", resultSet.getString(3));
}
6.總結
在使用Kylin時,我們有必要去首先熟悉其架構,這能讓我們更加熟悉其應用場景和業務場景。在整合和使用的過程當中會遇到一些問題,我們可以分析其異常日誌,然後利用搜尋引擎得到解決。關於Kylin的詳細使用,大家可以參考官方撰寫的文件。
7.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行討論或傳送郵件給我,我會盡我所能為您解答,與君共勉!