1.概述
JStorm 是一個類似於 Hadoop 的MapReduce的計算系統,它是由Alibaba開源的實時計算模型,它使用Java重寫了原生的Storm模型(Clojure和Java混合編寫的),並且再原來的基礎上做了許多改進。使用者只需按照指定的介面實現一個任務,然後將這個任務提交給JStorm系統,JStorm在接受了任務指令後,會無間斷執行任務,一旦出現異常導致某個Worker傳送故障,排程器立刻會分配一個新的Worker去頂替異常的Worker。下面是本次分享的目錄結構:
- 應用場景
- 基本術語
- JStorm比較
- JStorm架構
- 總結
下面開始今天的內容分享。
2.應用場景
從應用的角度來說,JStorm它是一種分散式的應用;從系統層面來說,它又類似於MapReduce這樣的排程系統;而從資料方面來說,它又是一種基於流水資料的實時處理解決方案。如今,DT時代的當下,使用者和企業也不僅僅只滿足於離線資料,對於資料的實時性要求也越來越高了。
在早期,Storm和JStorm未問世之前,業界有很多實時計算系統,可謂百家爭鳴,自Storm和JStorm出世之後,基本這兩者佔據主要地位,原因如下:
- 易開發:介面簡單,上手容易,只需要按照Spout,Bolt以及Topology的程式設計規範即可開發一個擴充套件性良好的應用,底層的細節我們可以不用去深究其原因。
- 擴充套件性:可線性擴充套件效能。
- 容錯:當Worker異常或掛起,會自動分配新的Worker去工作。
- 資料精準:其包含Ack機制,規避了資料丟失的風險。使用事物機制,提高資料精度。
JStorm處理資料的方式流程是基於流式處理,因此,我們會用它做以下處理:
- 日誌分析:從收集的日誌當中,統計出特定的資料結果,並將統計後的結果持久化到外界儲存介質中,如:DB。當下,實時統計主流使用JStorm和Storm。
- 訊息轉移:將接受的訊息進行Filter後,定向的儲存到另外的訊息中介軟體中。
3.基本術語
3.1 Stream
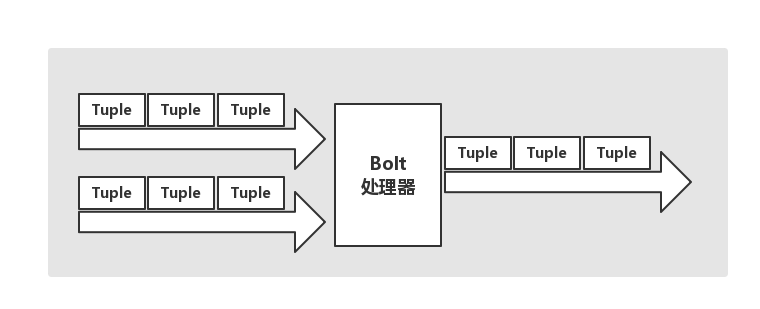
在JStorm當中,有對Stream的抽象,它是一個不間斷的無界的連續Tuple,而JStorm在建模事件流時,把流中的事件抽象未Tuple,流程如下圖所示:
3.2 Spout和Bolt
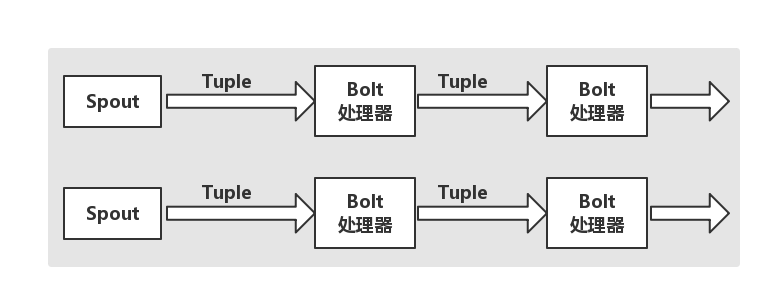
在JStorm中,它認為每個Stream都有一個Stream的來源,即Tuple的源頭,所以它將這個源頭抽象為Spout,而Spout可能是一個訊息中介軟體,如:MQ,Kafka等。並不斷的發出訊息,也可能是從某個佇列中不斷讀取佇列的後設資料。
在有了Spout後,接下來如何去處理相關內容,以類似的思想,將JStorm的處理過程抽象為Bolt,Bolt可以消費任意數量的輸入流,只要將流方向導到該Bolt即可,同時,它也可以傳送新的流給其他的Bolt使用,因而,我們只需要開啟特定的Spout,將Spout流出的Tuple導向特定的Bolt,然後Bolt對匯入的流做處理後再導向其它的Bolt等。
那麼,通過上述描述,其實,我們可以用一個形象的比喻來理解這個流程。我們可以認為Spout就是一個個的水龍頭,並且每個水龍頭中的水是不同的,我們想要消費那種水就去開啟對應的水龍頭,然後使用管道將水龍頭中的水導向一個水處理器,即Bolt,水處理器處理完後會再使用管道導向到另外的處理器或者落地到儲存介質。流程如下圖所示:
3.3 Topology
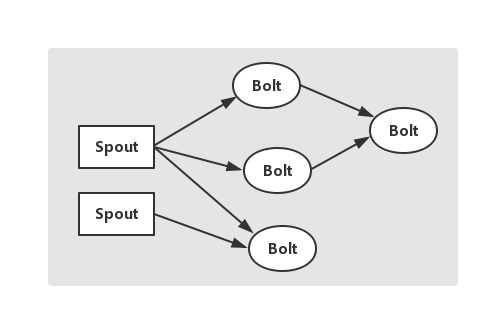
如圖所示,這是一個有向無環圖,JStorm將這個圖抽象為Topology,它是JStorm中最高層次的一個抽象概念,它可以處理程式碼層面當中直接於JStorm打交道的,可以被提交到JStorm叢集執行對應的任務,一個Topology即為一個資料流轉換圖,圖中的每個節點是一個Spout或者Bolt,當Spout或Bolt傳送Tuple到流時,它就傳送Tuple到每個訂閱了該流的Bolt上。
3.4 Tuple
JStorm當中將Stream中資料抽象為了Tuple,一個Tuple就是一個Value List,List值的每個Value都有一個Name,並且該Value可以是基本型別,字元型別,位元組陣列等,當然也可以是其它可序列化的型別。Topology的每個節點都要說明它所發射出的Tuple的欄位的Name,其它節點只需要訂閱該Name就可以接收處理相應的內容。
3.5 Worker和Task
Work和Task在JStorm中的職責是一個執行單元,一個Worker表示一個程式,一個Task表示一個執行緒,一個Worker可以執行多個Task。而Worker可以通過setNumWorkers(int workers)方法來設定對應的數目,表示這個Topology執行在多個JVM(PS:一個JVM為一個程式,即一個Worker);另外setSpout(String id, IRichSpout spout, Number parallelism_hint)和setBolt(String id, IRichBolt bolt,Number parallelism_hint)方法中的引數parallelism_hint代表這樣一個Spout或Bolt有多少個例項,即對應多少個執行緒,一個例項對應一個執行緒。
3.6 Slot
在JStorm當中,Slot的型別分為四種,他們分別是:CPU,Memory,Disk,Port;與Storm有所區別(Storm侷限於Port)。一個Supervisor可以提供的物件有:CPU Slot、Memory Slot、Disk Slot以及Port Slot。
- 在JStorm中,一個Worker消耗一個Port Slot,預設一個Task會消耗一個CPU Slot和一個Memory Slot
- 在Task執行較多的任務時,可以申請更多的CPU Slot
- 在Task需要更多的記憶體時,可以申請更多的額Memory Slot
- 在Task磁碟IO較多時,可以申請Disk Slot
4.JStorm比較
當前JStorm已經更新到2.x版本了,較於Storm而言,JStorm在一個Nimbus當機後,會自動的熱切到備份的Nimbus,實現了HA特性。對比與其它的資料產品而言,如下所示:
- Flume:一個成熟的產品,目前很多企業的日誌收集系統均基於此套件開發,可以將資料收集後做一些計算與分析。
- S4:它是一個通用的,可擴充套件的,分散式的,容錯,可插拔的平臺,使程式設計師可以很容易地開發用於處理無界的連續資料流應用。資料準確性較差,資料丟失的風險無法規避,導致其發展不是很迅速,社群活躍度不夠高。
- AKKA:一個Actor模型,系統模型強大,可以做任何你想做的時,當時很多工作都需要自己親自動手去實現,如序列化、Topology的生成等。
- Spark:基於記憶體計算的MapReduce模型,偏重於資料批量處理。
5.JStorm架構
從設計層面來說,JStorm是一個典型的排程系統。在這個系統中,有以下內容:
| 角色 | 作用 |
| Nimbus | 排程器 |
| Supervisor | Worker的代理角色,負責Kill掉Worker和執行Worker |
| Worker | Task的容器 |
| Task | 任務的執行者 |
| ZooKeeper | 系統的協調者 |
其整體架構圖,如下所示:

6.總結
本篇部落格給大家分享了JStorm的相關內容,其中包含一些基本概念,與Storm的區別,它的架構圖等內容,後續會大家介紹如何去部署JStorm的相關內容,以及它的程式設計方式,API的用法等內容會用一些案例給大家去一一的贅述。
7.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行討論或傳送郵件給我,我會盡我所能為您解答,與君共勉!