1.概述
本課程的視訊教程地址:《Kafka實戰專案之分析與設計》
本課程我通過一個使用者實時上報日誌案例作為基礎,帶著大家去分析Kafka這樣一個專案的各個環節,從而對專案的整體設計做比較合理的規劃,最終讓大家能夠通過本課程去掌握類似Kafka專案的分析與設計。下面,我給大家介紹本課程包含的課時內容,如下圖所示:

接下來,我們開始第一課時的學習:《專案整體概述》。
2.內容
2.1 專案整體設計
專案整體概述主要講解一個專案產生的背景,以及該專案背後的目的,從而讓大家更好的去把握專案的需求。
本課時所涉及的主要知識點,如下圖所示:

那麼,接下來,我就先從背景來給大家簡述一個專案,背景包含一下知識點,如下圖所示:

前面我已經給大家說明了,這是一個實時統計專案,我們可以實時的訪問記錄, 通過實時流式計算後,得到使用者實時的訪問行跡。這個和離線計算有所區別,離線計算任務,不能立馬得到我們想要的結果。
那麼,這樣一個專案我們能得到什麼好處,舉個例子:
業績部門的同事需要知道當天的使用者實時瀏覽行跡,而針對這一需求,我們可以通過實時計算後,將統計後的結果 通過圖表視覺化出來,讓業績部門的同事可以非常清晰的知道,公司的使用者對公司的那些業務模組趕興趣,需求量比較大, 那麼業績部門的同事,可以這一塊重點投入,對那些不是很趕興趣,需求量較小的模組,業績部門的同事可以投入的成本相對低一些。
以上便是我為大家介紹的專案背景,下面我給大家介紹專案的目的。
專案的目的所包含的內容,如下圖所示:

關於詳細的目的內容,這裡我就不多做贅述了。《觀看地址》
2.2 Producer 模組分析
Producer模組分析一課給大家介紹資料生產環節,我帶著大家去分析生產資料來源,讓大家掌握資料如何收集到 Kafka 的 Producer 模組。
其主要知識點包含以下內容,如下所示:

下面,我們先去分析資料來源。我們知道,在日誌記錄中一條日誌記錄代表使用者的一次活動形跡,下面我我從實時日誌記錄中抽取的一條使用者記錄,如下所示:
121.40.174.237 yx12345 [21/July/2015 13:25:45 +0000] chrome appid_5 "http://www.***.cn/sort/channel/2085.html"
那麼通過觀察分析這條記錄,我們可以從示例資料中得到那些資訊量,這裡我給大家總結到一張圖上了,如下圖所示:

在分析了日誌記錄的資訊量,我們接下來去看看是如何收集到這些資料的,整個收集資料的流程是怎麼樣的,下面我用一張圖來給大家,如下圖所示:

從圖中,我們可以看出,資料的產生的源頭是使用者,從圖的左邊開始看起,使用者通過自己手上的終端(有可能是: PC機,手機,pad等裝置去訪問公司的網站),而這裡訪問的記錄都會被實時的記錄到伺服器,我們在部署網站的的節點上新增 Flume的Agent代理,將這些實時記錄集中收集起來,然後我們在Flume的Sink元件處新增輸送的目標地址,這裡我們是要將這些 實時的記錄輸送到Kafka叢集的,所以在Sink元件處填寫指向Kafka叢集的資訊,這樣收集的實時記錄就被儲存在Kafka的 Producer端,然後,這部分資料我們就可以在下一個階段,也就是消費階段去消費這些資料。
以上就是整個實時資料的採集過程,由使用者產生,Flume收集並傳輸,最後存放與Kafka叢集的Producer端等待被消費。
關於具體細節,這裡就不贅述了。《觀看地址》
2.3 Consumer 模組分析
該課時我給大家介紹資料消費環節,帶著大家從消費的角度去分析消費的資料來源,讓大家掌握資料如何在Kafka中被消費。
其主要知識點包含以下內容,如下所示:

那麼,下面我先帶著大家去分析消費資料來源,關於消費資料來源的統計的KPI指標,如下圖所示:

從圖中,我們可以看出,由以下KPI指標:
- 業務模組的訪問量:這裡通過記錄中的App Id來統計相關指標。
- 頁面的訪問量:關於PV,這裡我們可以使用瀏覽記錄來完成這部分的指標統計。
- 當天時段模組的訪問量:而時間段的訪問量,可以通過使用者訪問的時間戳,來完成這部分的指標統計。
- 訪問者的客戶端型別:在每條訪問記錄中,都含有對應的訪問瀏覽裝置型別,我們提取這部分內容來完成相應的統計指標。
以上便是我給大家分析消費資料的相關資訊所設計的內容。
接下來,我帶著大家去看看本課時的另一個比較重要的知識點,那就是關於資料來源的消費流程。這裡,我用一張圖來給大家描述了整個消費過程,如下圖所示:
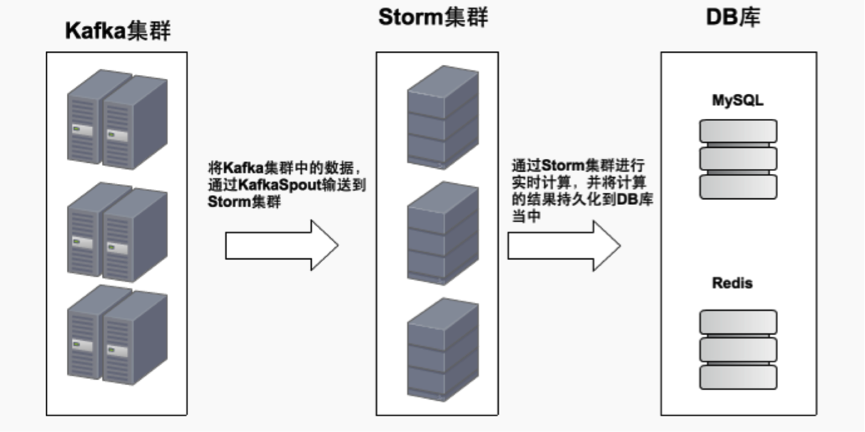
我們先從圖的最左邊看起,這個是Kafka的叢集,在這個叢集中,存放著我們即將要被消費的資料,這裡,我們通過KafkaSpout 將Kafka和Storm聯絡起來,將Kafka叢集中要消費的資料,通過KafkaSpout輸送到Storm叢集,然後資料進入到Storm叢集后, 通過Storm的實時計算模型,按照業務指標做對應的計算,並將計算之後的結果持久化到DB庫當中去,這裡同時採用MySQL和Redis 來做持久化。
以上,便是我給大家描述的如何去消費Kafka叢集中資料的流程。《觀看地址》
2.4 專案整體設計
該課時我給大家介紹設計一個專案的整體架構和流程開發,以及 KPI 的設計,讓大家能夠通過本課時去掌握一個專案的設計流程。
其主要知識點包含以下內容,如下所示:

下面,我先給大家去分析本專案的詳細設計流程,這裡我繪製了一張圖來描述整個專案設計流程的相關資訊,如下圖所示:

從圖的最左邊開始,依次是:
- 資料來源:這部分資料在使用者訪問公司網站的時候就會產生對應的記錄,我們只需要在各個網站節點新增對應的Flume的Agent代理即可。
- 資料收集:這裡我們使用Flume叢集去收集訪問的日誌記錄,在收集完資料後,進入到下一階段。
- 資料接入:在該模組下,使用Kafka來充當一個訊息資料的核心中介軟體,通過Flume的Sink元件,將資料 傳送到Kafka叢集,這樣在Kafka的生產端就有了資料,這些資料等待去被消費。那麼接下來,通過KafkaSpout 將Kafka叢集和Storm叢集關聯起來,將Kafka叢集中的資料,由KafkaSpout輸送到Storm叢集,這樣消費端的資料就流向了Storm叢集。
- 流式計算:在資料進入到Storm叢集后,通過Storm的實時計算模型,將資料按照業務需要完成對應的指標計算,並將統計的 結果持久化到DB庫當中。
- 持久化層:在持久化層,這裡選用MySQL和Redis來做持久化儲存,統計結果出來後,進入到下一階段。
- 資料介面層:這裡我們可以編寫一個RPC服務,統一的將統計結果共享出去,這裡RPC服務所採用的是Thrift,完成資料的共享。
- 視覺化層:這裡由前端統一查詢Thrift資料共享介面,將統計結果展示出來,完成資料的視覺化。
以上,便是我給大家介紹本專案的整個流程設計的相關內容。關於其他的細節內容,這裡就不多贅述了。《觀看地址》
3.總結
本課程我們對專案進行了整體分析,並指導大家去分析 Kafka 的 Producer 模組和 Consumer 模組,以及幫助大家去設計專案的開發流程等知識,我們應該掌握以下知識點,如下圖所示:

4.結束語
這就是本課程的主要內容,主要就對 Kafka 專案做前期準備,對後續學習 Kafka 專案實戰內容奠定良好的基礎。
如果本教程能幫助到您,希望您能點選進去觀看一下,謝謝您的支援!
轉載請註明出處,謝謝合作!
本課程的視訊教程地址:《Kafka實戰專案之分析與設計》