1.概述
最近在和人交流時談到資料相似度和資料共性問題,而剛好在業務層面有類似的需求,今天和大家分享這類問題的解決思路,分享目錄如下所示:
- 業務背景
- 編碼實踐
- 預覽截圖
下面開始今天的內容分享。
2.業務背景
目前有這樣一個背景,在一大堆資料中,裡面存放著圖片的相關資訊,如下圖所示:
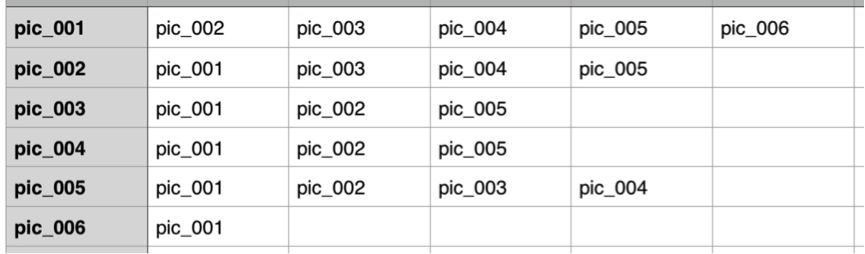
上圖只是給大家列舉的一個示例資料格式,第一列表示自身圖片,第二、第三......等列表示與第一列相關聯的圖片資訊。那麼我們從這堆資料中如何找出他們擁有相同圖片資訊的圖片。
2.1 實現思路
那麼,我們在明確了上述需求後,下面我們來分析它的實現思路。首先,我們通過上圖所要實現的目標結果,其最終計算結果如下所示:
pic_001pic_002 pic_003,pic_004,pic_005
pic_001pic_003 pic_002,pic_005
pic_001pic_004 pic_002,pic_005
pic_001pic_005 pic_002,pic_003,pic_004
......
結果如上所示,找出兩兩圖片之間的共性圖片,結果未列完整,只是列舉了部分,具體結果大家可以參考截圖預覽的相關資訊。
下面給大家介紹解決思路,通過觀察資料,我們可以發現在上述資料當中,我們要計算圖片兩兩的共性圖片,可以從關聯圖片入手,在關聯圖片中我們可以找到共性圖片的關聯資訊,比如:我們要計算pic001pic002圖片的共性圖片,我們可以在關聯圖片中找到兩者(pic001pic002組合)後對應的自身圖片(key),最後在將所有的key求並集即為兩者的共性圖片資訊,具體資訊如下圖所示:
通過上圖,我們可以知道具體的實現思路,步驟如下所示:
- 第一步:拆分資料,關聯資料兩兩組合作為Key輸出。
- 第二步:將相同Key分組,然後求並集得到計算結果。
這裡使用一個MR來完成此項工作,在明白了實現思路後,我們接下來去實現對應的編碼。
3.編碼實踐
- 拆分資料,兩兩組合。
public static class PictureMap extends Mapper<LongWritable, Text, Text, Text> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { StringTokenizer strToken = new StringTokenizer(value.toString()); Text owner = new Text(); Set<String> set = new TreeSet<String>(); owner.set(strToken.nextToken()); while (strToken.hasMoreTokens()) { set.add(strToken.nextToken()); } String[] relations = new String[set.size()]; relations = set.toArray(relations); for (int i = 0; i < relations.length; i++) { for (int j = i + 1; j < relations.length; j++) { String outPutKey = relations[i] + relations[j]; context.write(new Text(outPutKey), owner); } } } }
- 按Key分組,求並集
public static class PictureReduce extends Reducer<Text, Text, Text, Text> { @Override protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { String common = ""; for (Text val : values) { if (common == "") { common = val.toString(); } else { common = common + "," + val.toString(); } } context.write(key, new Text(common)); } }
- 完整示例
package cn.hadoop.hdfs.example; import java.io.IOException; import java.util.Set; import java.util.StringTokenizer; import java.util.TreeSet; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import cn.hadoop.hdfs.util.HDFSUtils; import cn.hadoop.hdfs.util.SystemConfig; /** * @Date Aug 31, 2015 * * @Author dengjie * * @Note Find picture relations */ public class PictureRelations extends Configured implements Tool { private static Logger log = LoggerFactory.getLogger(PictureRelations.class); private static Configuration conf; static { String tag = SystemConfig.getProperty("dev.tag"); String[] hosts = SystemConfig.getPropertyArray(tag + ".hdfs.host", ","); conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://cluster1"); conf.set("dfs.nameservices", "cluster1"); conf.set("dfs.ha.namenodes.cluster1", "nna,nns"); conf.set("dfs.namenode.rpc-address.cluster1.nna", hosts[0]); conf.set("dfs.namenode.rpc-address.cluster1.nns", hosts[1]); conf.set("dfs.client.failover.proxy.provider.cluster1", "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"); conf.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName()); conf.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName()); } public static class PictureMap extends Mapper<LongWritable, Text, Text, Text> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { StringTokenizer strToken = new StringTokenizer(value.toString()); Text owner = new Text(); Set<String> set = new TreeSet<String>(); owner.set(strToken.nextToken()); while (strToken.hasMoreTokens()) { set.add(strToken.nextToken()); } String[] relations = new String[set.size()]; relations = set.toArray(relations); for (int i = 0; i < relations.length; i++) { for (int j = i + 1; j < relations.length; j++) { String outPutKey = relations[i] + relations[j]; context.write(new Text(outPutKey), owner); } } } } public static class PictureReduce extends Reducer<Text, Text, Text, Text> { @Override protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { String common = ""; for (Text val : values) { if (common == "") { common = val.toString(); } else { common = common + "," + val.toString(); } } context.write(key, new Text(common)); } } public int run(String[] args) throws Exception { final Job job = Job.getInstance(conf); job.setJarByClass(PictureMap.class); job.setMapperClass(PictureMap.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setReducerClass(PictureReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job, args[0]); FileOutputFormat.setOutputPath(job, new Path(args[1])); int status = job.waitForCompletion(true) ? 0 : 1; return status; } public static void main(String[] args) { try { if (args.length != 1) { log.warn("args length must be 1 and as date param"); return; } String tmpIn = SystemConfig.getProperty("hdfs.input.path.v2"); String tmpOut = SystemConfig.getProperty("hdfs.output.path.v2"); String inPath = String.format(tmpIn, "t_pic_20150801.log"); String outPath = String.format(tmpOut, "meta/" + args[0]); // bak dfs file to old HDFSUtils.bak(tmpOut, outPath, "meta/" + args[0] + "-old", conf); args = new String[] { inPath, outPath }; int res = ToolRunner.run(new Configuration(), new PictureRelations(), args); System.exit(res); } catch (Exception ex) { ex.printStackTrace(); log.error("Picture relations task has error,msg is" + ex.getMessage()); } } }
4.截圖預覽
關於計算結果,如下圖所示:

5.總結
本篇部落格只是從思路上實現了圖片關聯計算,在資料量大的情況下,是有待優化的,這裡就不多做贅述了,後續有時間在為大家分析其中的細節。
6.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行討論或傳送郵件給我,我會盡我所能為您解答,與君共勉!