1.概述
前面給大家介紹了整個Kafka專案的開發流程,今天給大家分享Kafka如何獲取資料來源,即Kafka生產資料。下面是今天要分享的目錄:
- 資料來源
- Flume到Kafka
- 資料來源載入
- 預覽
下面開始今天的分享內容。
2.資料來源
Kafka生產的資料,是由Flume的Sink提供的,這裡我們需要用到Flume叢集,通過Flume叢集將Agent的日誌收集分發到Kafka(供實時計算處理)和HDFS(離線計算處理)。關於Flume叢集的Agent部署,這裡就不多做贅述了,不清楚的同學可以參考《高可用Hadoop平臺-Flume NG實戰圖解篇》一文中的介紹,下面給大家介紹資料來源的流程圖,如下圖所示:

這裡,我們使用Flume作為日誌收集系統,將收集到的資料輸送到Kafka中介軟體,以供Storm去實時消費計算,整個流程從各個Web節點上,通過Flume的Agent代理收集日誌,然後彙總到Flume叢集,在由Flume的Sink將日誌輸送到Kafka叢集,完成資料的生產流程。
3.Flume到Kafka
從圖,我們已經清楚了資料生產的流程,下面我們來看看如何實現Flume到Kafka的輸送過程,下面我用一個簡要的圖來說明,如下圖所示:

這個表達了從Flume到Kafka的輸送工程,下面我們來看看如何實現這部分。
首先,在我們完成這部分流程時,需要我們將Flume叢集和Kafka叢集都部署完成,在完成部署相關叢集后,我們來配置Flume的Sink資料流向,配置資訊如下所示:
- 首先是配置spooldir方式,內容如下所示:
producer.sources.s.type = spooldir producer.sources.s.spoolDir = /home/hadoop/dir/logdfs
- 當然,Flume的資料傳送方型別也是多種型別的,有:Console、Text、HDFS、RPC等,這裡我們系統所使用的是Kafka中介軟體來接收,配置內容如下所示:
producer.sinks.r.type = org.apache.flume.plugins.KafkaSink producer.sinks.r.metadata.broker.list=dn1:9092,dn2:9092,dn3:9092 producer.sinks.r.partition.key=0 producer.sinks.r.partitioner.class=org.apache.flume.plugins.SinglePartition producer.sinks.r.serializer.class=kafka.serializer.StringEncoder producer.sinks.r.request.required.acks=0 producer.sinks.r.max.message.size=1000000 producer.sinks.r.producer.type=sync producer.sinks.r.custom.encoding=UTF-8 producer.sinks.r.custom.topic.name=test
這樣,我們就在Flume的Sink端配置好了資料流向接受方。
4.資料載入
在完成配置後,接下來我們開始載入資料,首先我們在Flume的spooldir端生產日誌,以供Flume去收集這些日誌。然後,我們通過Kafka的KafkaOffsetMonitor監控工具,去監控資料生產的情況,下面我們開始載入。
- 啟動ZK叢集,內容如下所示:
zkServer.sh start
注意:分別在ZK的節點上啟動。
- 啟動Kafka叢集
kafka-server-start.sh config/server.properties &
在其他的Kafka節點輸入同樣的命令,完成啟動。
- 啟動Kafka監控工具
java -cp KafkaOffsetMonitor-assembly-0.2.0.jar \ com.quantifind.kafka.offsetapp.OffsetGetterWeb \ --zk dn1:2181,dn2:2181,dn3:2181 \ --port 8089 \ --refresh 10.seconds \ --retain 1.days
- 啟動Flume叢集
flume-ng agent -n producer -c conf -f flume-kafka-sink.properties -Dflume.root.logger=ERROR,console
然後,我在/home/hadoop/dir/logdfs目錄下上傳log日誌,這裡我只抽取了一少部分日誌進行上傳,如下圖所示,表示日誌上傳成功。

5.預覽
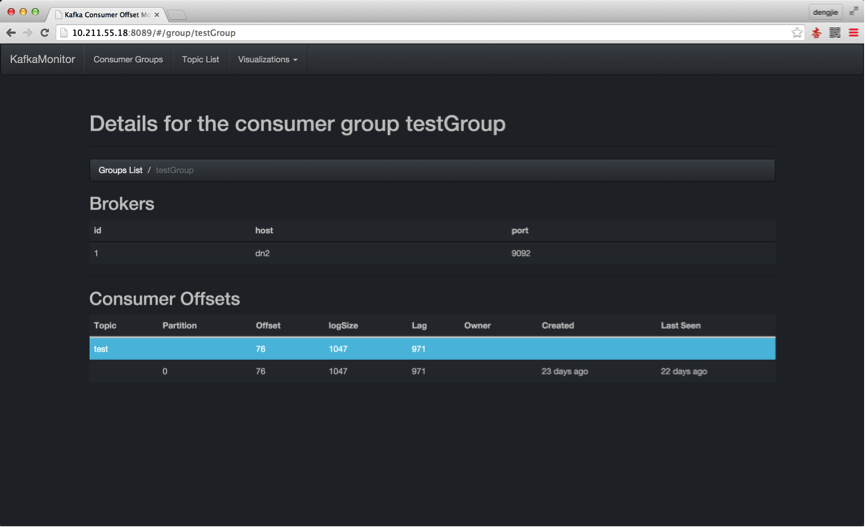
下面,我們通過Kafka的監控工具,來預覽我們上傳的日誌記錄,有沒有在Kafka中產生訊息資料,如下所示:
- 啟動Kafka叢集,為生產訊息截圖預覽

- 通過Flume上傳日誌,在Kafka中產生訊息資料
6.總結
本篇文章給大家講述了Kafka的訊息產生流程,後續會在Kafka實戰系列中為大家講述Kafka的訊息消費流程等一整套流程,這裡只是為後續的Kafka實戰編碼打下一個基礎,讓大家先對Kafka的訊息生產有個整體的認識。
7.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行討論或傳送郵件給我,我會盡我所能為您解答,與君共勉!