1.概述
今天補充一篇關於Flume的部落格,前面在講解高可用的Hadoop平臺的時候遺漏了這篇,本篇部落格為大家講述以下內容:
- Flume NG簡述
- 單點Flume NG搭建、執行
- 高可用Flume NG搭建
- Failover測試
- 截圖預覽
下面開始今天的部落格介紹。
2.Flume NG簡述
Flume NG是一個分散式,高可用,可靠的系統,它能將不同的海量資料收集,移動並儲存到一個資料儲存系統中。輕量,配置簡單,適用於各種日誌收集,並支援Failover和負載均衡。並且它擁有非常豐富的元件。Flume NG採用的是三層架構:Agent層,Collector層和Store層,每一層均可水平擴充。其中Agent包含Source,Channel和Sink,三者組建了一個Agent。三者的職責如下所示:
- Source:用來消費(收集)資料來源到Channel元件中
- Channel:中轉臨時儲存,儲存所有Source元件資訊
- Sink:從Channel中讀取,讀取成功後會刪除Channel中的資訊
下圖是Flume NG的架構圖,如下所示:

圖中描述了,從外部系統(Web Server)中收集產生的日誌,然後通過Flume的Agent的Source元件將資料傳送到臨時儲存Channel元件,最後傳遞給Sink元件,Sink元件直接把資料儲存到HDFS檔案系統中。
3.單點Flume NG搭建、執行
我們在熟悉了Flume NG的架構後,我們先搭建一個單點Flume收集資訊到HDFS叢集中,由於資源有限,本次直接在之前的高可用Hadoop叢集上搭建Flume。
場景如下:在NNA節點上搭建一個Flume NG,將本地日誌收集到HDFS叢集。
3.1基礎軟體
在搭建Flume NG之前,我們需要準備必要的軟體,具體下載地址如下所示:
- Flume 《下載地址》
JDK由於之前在安裝Hadoop叢集時已經配置過,這裡就不贅述了,若需要配置的同學,可參考《配置高可用的Hadoop平臺》。
3.2安裝與配置
- 安裝
首先,我們解壓flume安裝包,命令如下所示:
[hadoop@nna ~]$ tar -zxvf apache-flume-1.5.2-bin.tar.gz
- 配置
環境變數配置內容如下所示:
export FLUME_HOME=/home/hadoop/flume-1.5.2 export PATH=$PATH:$FLUME_HOME/bin
flume-conf.properties
#agent1 name agent1.sources=source1 agent1.sinks=sink1 agent1.channels=channel1 #Spooling Directory #set source1 agent1.sources.source1.type=spooldir agent1.sources.source1.spoolDir=/home/hadoop/dir/logdfs agent1.sources.source1.channels=channel1 agent1.sources.source1.fileHeader = false agent1.sources.source1.interceptors = i1 agent1.sources.source1.interceptors.i1.type = timestamp #set sink1 agent1.sinks.sink1.type=hdfs agent1.sinks.sink1.hdfs.path=/home/hdfs/flume/logdfs agent1.sinks.sink1.hdfs.fileType=DataStream agent1.sinks.sink1.hdfs.writeFormat=TEXT agent1.sinks.sink1.hdfs.rollInterval=1 agent1.sinks.sink1.channel=channel1 agent1.sinks.sink1.hdfs.filePrefix=%Y-%m-%d #set channel1 agent1.channels.channel1.type=file agent1.channels.channel1.checkpointDir=/home/hadoop/dir/logdfstmp/point agent1.channels.channel1.dataDirs=/home/hadoop/dir/logdfstmp
flume-env.sh
JAVA_HOME=/usr/java/jdk1.7
注:配置中的目錄若不存在,需提前建立。
3.3啟動
啟動命令如下所示:
flume-ng agent -n agent1 -c conf -f flume-conf.properties -Dflume.root.logger=DEBUG,console
注:命令中的agent1表示配置檔案中的Agent的Name,如配置檔案中的agent1。flume-conf.properties表示配置檔案所在配置,需填寫準確的配置檔案路徑。
3.4效果預覽
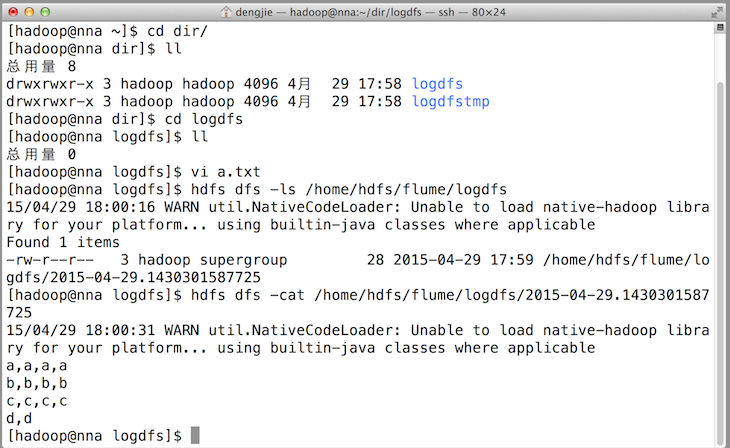
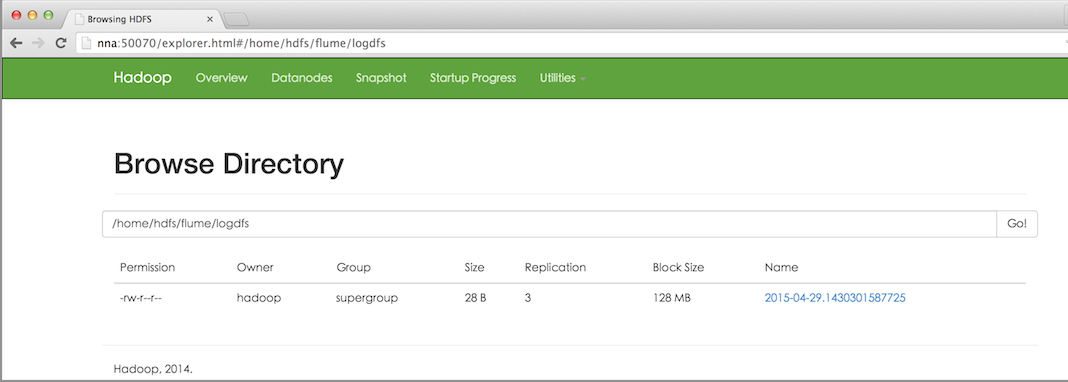
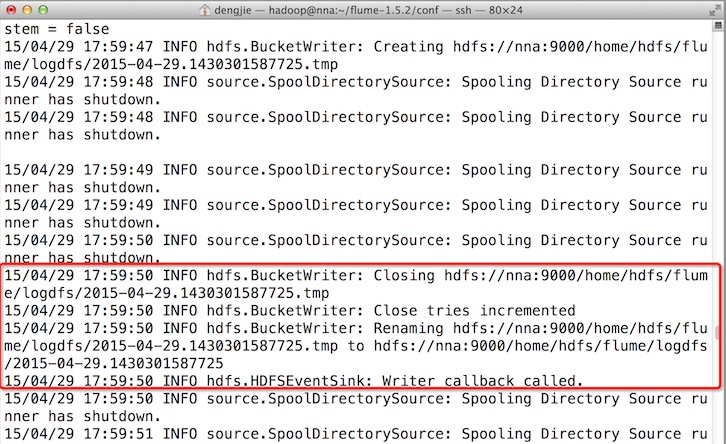
之後,成功上傳後本地目的會被標記完成。如下圖所示:

4.高可用Flume NG搭建
在完成單點的Flume NG搭建後,下面我們搭建一個高可用的Flume NG叢集,架構圖如下所示:
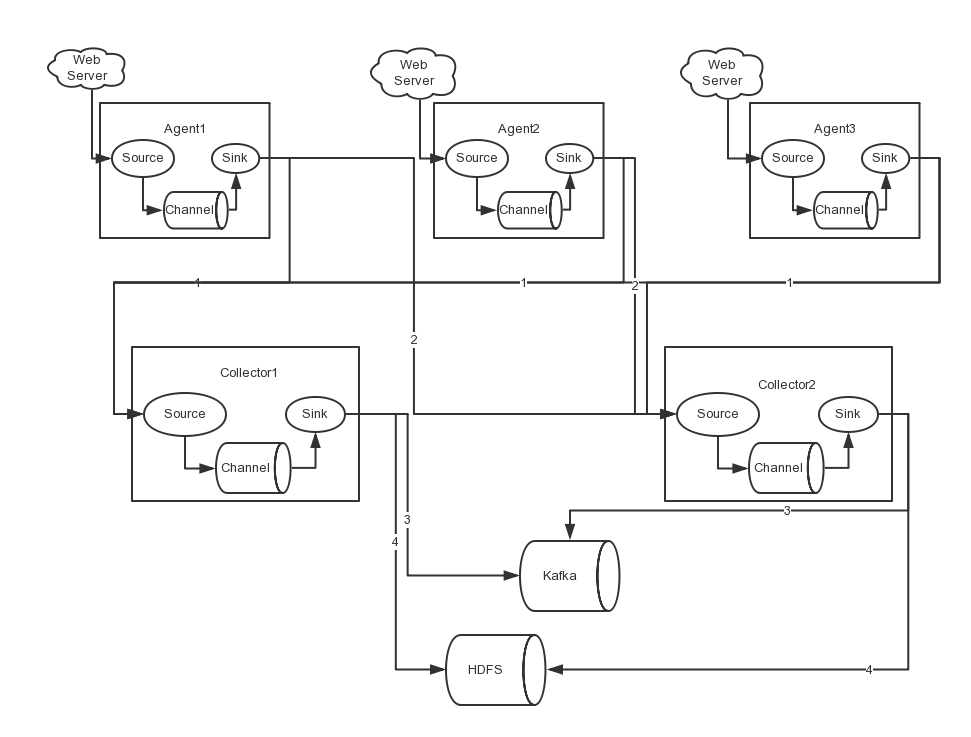
圖中,我們可以看出,Flume的儲存可以支援多種,這裡只列舉了HDFS和Kafka(如:儲存最新的一週日誌,並給Storm系統提供實時日誌流)。
4.1節點分配
Flume的Agent和Collector分佈如下表所示:
| 名稱 | HOST | 角色 |
| Agent1 | 10.211.55.14 | Web Server |
| Agent2 | 10.211.55.15 | Web Server |
| Agent3 | 10.211.55.16 | Web Server |
| Collector1 | 10.211.55.18 | AgentMstr1 |
| Collector2 | 10.211.55.19 | AgentMstr2 |
圖中所示,Agent1,Agent2,Agent3資料分別流入到Collector1和Collector2,Flume NG本身提供了Failover機制,可以自動切換和恢復。在上圖中,有3個產生日誌伺服器分佈在不同的機房,要把所有的日誌都收集到一個叢集中儲存。下面我們開發配置Flume NG叢集
4.2配置
在下面單點Flume中,基本配置都完成了,我們只需要新新增兩個配置檔案,它們是flume-client.properties和flume-server.properties,其配置內容如下所示:
- flume-client.properties
#agent1 name agent1.channels = c1 agent1.sources = r1 agent1.sinks = k1 k2 #set gruop agent1.sinkgroups = g1 #set channel agent1.channels.c1.type = memory agent1.channels.c1.capacity = 1000 agent1.channels.c1.transactionCapacity = 100 agent1.sources.r1.channels = c1 agent1.sources.r1.type = exec agent1.sources.r1.command = tail -F /home/hadoop/dir/logdfs/test.log agent1.sources.r1.interceptors = i1 i2 agent1.sources.r1.interceptors.i1.type = static agent1.sources.r1.interceptors.i1.key = Type agent1.sources.r1.interceptors.i1.value = LOGIN agent1.sources.r1.interceptors.i2.type = timestamp # set sink1 agent1.sinks.k1.channel = c1 agent1.sinks.k1.type = avro agent1.sinks.k1.hostname = nna agent1.sinks.k1.port = 52020 # set sink2 agent1.sinks.k2.channel = c1 agent1.sinks.k2.type = avro agent1.sinks.k2.hostname = nns agent1.sinks.k2.port = 52020 #set sink group agent1.sinkgroups.g1.sinks = k1 k2 #set failover agent1.sinkgroups.g1.processor.type = failover agent1.sinkgroups.g1.processor.priority.k1 = 10 agent1.sinkgroups.g1.processor.priority.k2 = 1 agent1.sinkgroups.g1.processor.maxpenalty = 10000
注:指定Collector的IP和Port。
- flume-server.properties
#set Agent name a1.sources = r1 a1.channels = c1 a1.sinks = k1 #set channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # other node,nna to nns a1.sources.r1.type = avro a1.sources.r1.bind = nna a1.sources.r1.port = 52020 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = Collector a1.sources.r1.interceptors.i1.value = NNA a1.sources.r1.channels = c1 #set sink to hdfs a1.sinks.k1.type=hdfs a1.sinks.k1.hdfs.path=/home/hdfs/flume/logdfs a1.sinks.k1.hdfs.fileType=DataStream a1.sinks.k1.hdfs.writeFormat=TEXT a1.sinks.k1.hdfs.rollInterval=1 a1.sinks.k1.channel=c1 a1.sinks.k1.hdfs.filePrefix=%Y-%m-%d
注:在另一臺Collector節點上修改IP,如在NNS節點將繫結的物件有nna修改為nns。
4.3啟動
在Agent節點上啟動命令如下所示:
flume-ng agent -n agent1 -c conf -f flume-client.properties -Dflume.root.logger=DEBUG,console
注:命令中的agent1表示配置檔案中的Agent的Name,如配置檔案中的agent1。flume-client.properties表示配置檔案所在配置,需填寫準確的配置檔案路徑。
在Collector節點上啟動命令如下所示:
flume-ng agent -n a1 -c conf -f flume-server.properties -Dflume.root.logger=DEBUG,console
注:命令中的a1表示配置檔案中的Agent的Name,如配置檔案中的a1。flume-server.properties表示配置檔案所在配置,需填寫準確的配置檔案路徑。
5.Failover測試
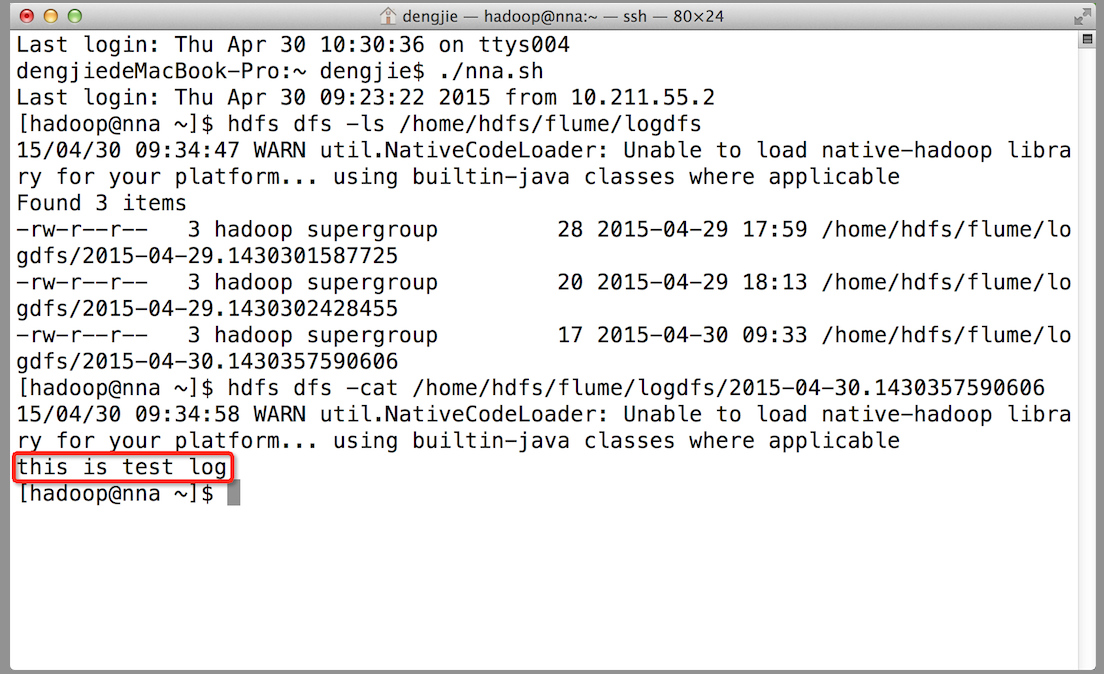
下面我們來測試下Flume NG叢集的高可用(故障轉移)。場景如下:我們在Agent1節點上傳檔案,由於我們配置Collector1的權重比Collector2大,所以Collector1優先採集並上傳到儲存系統。然後我們kill掉Collector1,此時有Collector2負責日誌的採集上傳工作,之後,我們手動恢復Collector1節點的Flume服務,再次在Agent1上次檔案,發現Collector1恢復優先順序別的採集工作。具體截圖如下所示:
- Collector1優先上傳

- HDFS叢集中上傳的log內容預覽
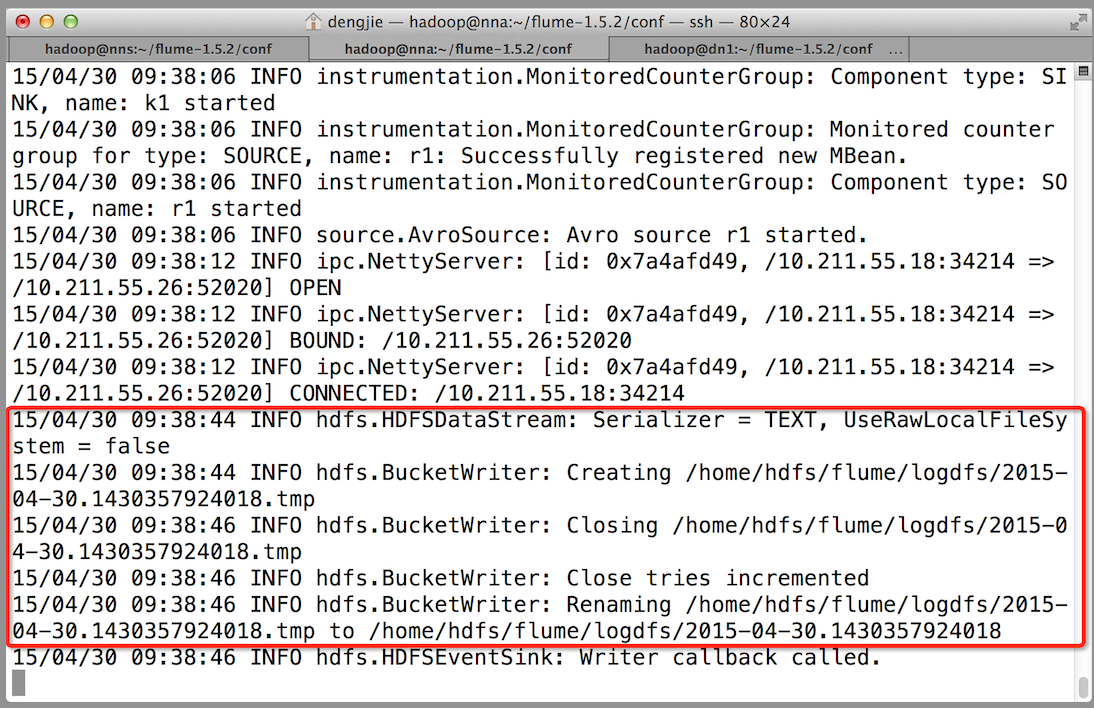
- Collector1當機,Collector2獲取優先上傳許可權

- 重啟Collector1服務,Collector1重新獲得優先上傳的許可權
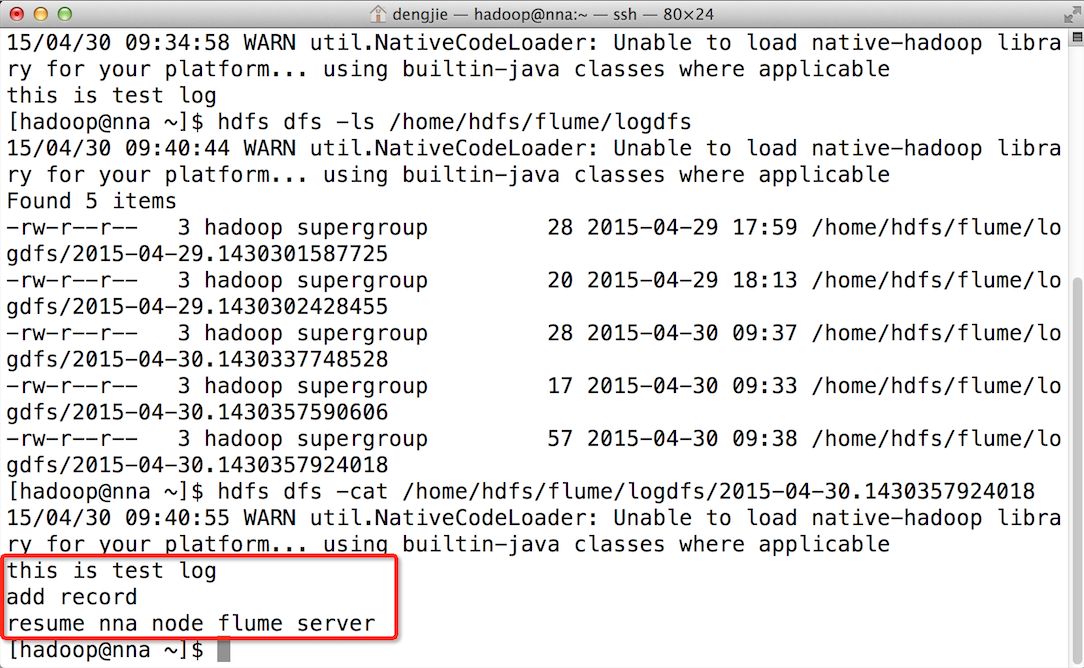
6.截圖預覽
下面為大家附上HDFS檔案系統中的截圖預覽,如下圖所示:
- HDFS檔案系統中的檔案預覽

- 上傳的檔案內容預覽
7.總結
在配置高可用的Flume NG時,需要注意一些事項。在Agent中需要繫結對應的Collector1和Collector2的IP和Port,另外,在配置Collector節點時,需要修改當前Flume節點的配置檔案,Bind的IP(或HostName)為當前節點的IP(或HostName),最後,在啟動的時候,指定配置檔案中的Agent的Name和配置檔案的路徑,否則會出錯。
8.結束語
這篇部落格就和大家分享到這裡,如果大家在研究學習的過程當中有什麼問題,可以加群進行討論或傳送郵件給我,我會盡我所能為您解答,與君共勉!