視覺SLAM漫談(二):圖優化理論與g2o的使用
1 前言以及回顧
各位朋友,自從上一篇《視覺SLAM漫談》寫成以來已經有一段時間了。我收到幾位熱心讀者的郵件。有的希望我介紹一下當前視覺SLAM程式的實用程度,更多的人希望瞭解一下前文提到的g2o優化庫。因此我另寫一篇小文章來專門介紹這個新玩意。
在開始本篇文章正文以前,我們先來回顧一下圖優化SLAM問題的提法。至於SLAM更基礎的內容,例如SLAM是什麼東西等等,請參見上一篇文章。我們直接進入較深層次的討論。首先,關於我們要做的事情,你可以這樣想:
l 已知的東西:感測器資料(影象,點雲,慣性測量裝置等)。我們的感測器主要是一個Kinect,因此資料就是一個視訊序列,說的再詳細點就是一個RGB點陣圖序列與一個深度圖序列。至於慣性測量裝置,可以有也可以沒有。
l 待求的東西:機器人的運動軌跡,地圖的描述。運動軌跡,畫出來應該就像是一條路徑。而地圖的描述,通常是點雲的描述。但是點雲描述是否可用於導航、規劃等後續問題,還有待研究。
這兩個點之間還是有挺長的路要走的。如果我們使用圖優化,往往會在整個視訊序列中,定義若干個關鍵幀:
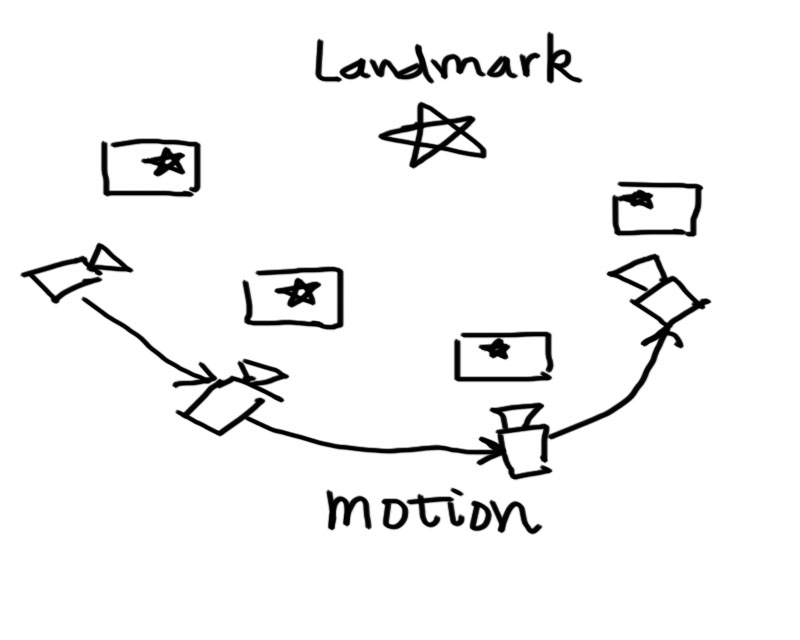
這個圖著實畫的有點醜,請大家不要吐槽……不管怎麼說,它表達出我想表達的意思。在這張圖中,我們有一個路標點(五角星),並在各個關鍵幀中都看到了這個點。於是,我們就能用PnP或ICP求解相鄰關鍵點的運動方向。這些在上篇文章都介紹過了,包括特徵選擇,匹配及計算等等。那麼,這個過程中有什麼問題呢?
2 為什麼要用全域性優化
你一定已經注意到,理想的計算總和實際有差距的。好比說理想的科研就是“看論文——產生想法——做實驗——發文章”,那麼現實的科研就是“看論文——產生想法——做實驗——發現該想法在二十年前就有人做過了”,這樣一個過程。實際當中,僅通過幀間運動(ego-motion)來計算機器人軌跡是遠遠不夠的。如下圖所示:

如果你只用幀間匹配,那麼每一幀的誤差將對後面所有的運動軌跡都要產生影響。例如第二幀往右偏了0.1,那麼後面第三、四、五幀都要往右偏0.1,還要加上它們自己的估算誤差。所以結果就是:當程式跑上十幾秒之後早就不知道飛到哪兒去了。這是經典的SLAM現象,在EKF實現中,也會發現,當機器人不斷運動時,不確定性會不斷增長。當然不是我們所希望的結果。
那麼怎麼辦才好呢?想象你到了一個陌生的城市,安全地走出了火車站,並在附近遊蕩了一會兒。當你走的越遠,看到許多未知的建築。你就越搞不清楚自己在什麼地方。如果是你,你會怎麼辦?
通常的做法是認準一個標誌性建築物,在它周圍轉上幾圈,弄清楚附近的環境。然後再一點點兒擴大我們走過的範圍。在這個過程中,我們會時常回到之前已經見過的場景,因此對它周圍的景象就會很熟悉。
機器人的情形也差不多,除了大多數時候是人在遙控它行走。因而我們希望,機器人不要僅和它上一個幀進行比較,而是和更多先前的幀比較,找出其中的相似之處。這就是所謂的迴環檢測(Loop closure detection)。用下面的示意圖來說明:

沒有迴環時,由於誤差對後續幀產生影響,機器人路徑估計很不穩定。加上一些區域性迴環,幾個相鄰幀就多了一些約束,因而誤差就減少了。你可以把它看成一個由彈簧連起來的鏈條(質點-彈簧模型)。當機器人經過若干時間,回到最初地方時,檢測出了大回環時,整個環內的結構都會變得穩定很多。我們就可以籍此知道一個房間是方的還是圓的,面前這堵牆對應著以前哪一堵牆,等等。
相信講到這裡,大家對迴環檢測都有了一個感性的認識。那麼,這件事情具體是怎麼建模,怎麼計算,怎麼程式設計呢?下面我們就一步步來介紹。
3 圖優化的數學模型
SLAM問題的優化模型可以有幾種不同的建模方式。我們挑選其中較簡單的一種進行介紹,即FrameSLAM,在2008年提出。它的特點是隻用位姿約束而不用特徵約束,減少了很多計算量,表達起來也比較直觀。下面我們給出一種6自由度的3D SLAM建模方法。
符號:


注意到這裡的建模與前文有所不同,是一個簡化版的模型。因為我們假設幀間匹配時得到了相鄰幀的變換矩陣,而不是把所有特徵也放到優化問題裡面來。所以這個模型看上去相對簡單。但是它很實用,因為不用引入特徵,所以結點和邊的數量大大減少,要知道在影象裡提特徵動輒成百上千的。
4 g2o是什麼
g2o,就是對上述問題的一個求解器。它原理上是一個通用的求解器,並不限定於某些SLAM問題。你可以用它來求SLAM,也可以用ICP, PnP以及其他你能想到的可以用圖來表達的優化問題。它的程式碼很規範,就是有一個缺點:文件太少。唯一的說明文件還有點太裝叉(個人感覺)了,有點擺弄作者數學水平的意思,反正那篇文件很難懂就是了。話說程式文件不應該是告訴我怎麼用才對麼……
言歸正傳。如果你想用g2o,請去它的github上面下載:https://github.com/RainerKuemmerle/g2o
它的API在:http://www.rock-robotics.org/stable/api/slam/g2o/classg2o_1_1HyperGraph.html
4.1 安裝
g2o是一個用cmake管理的C++工程,我是用Linux編譯的,所以不要問我怎麼在win下面用g2o,因為我也不會……不管怎麼說,你下載了它的zip包或者用git拷下來之後,裡面有一個README檔案。告訴你它的依賴項。在ubuntu下,直接鍵入命令:
sudo apt-get install cmake libeigen3-dev libsuitesparse-dev libqt4-dev qt4-qmake libqglviewer-qt4-dev
我個人感覺還要 libcsparse-dev和freeglut3這兩個庫,反正多裝了也無所謂。注意libqglviewer-qt4-dev只在ubuntu 12.04庫裡有,14.04 裡換成另一個庫了。g2o的視覺化工具g2o_viewer是依賴這個庫的,所以,如果你在14.04下面編,要麼是去把12.04那個deb(以及它的依賴項)找出來裝好,要麼用ccmake,把build apps一項給去掉,這樣就不編譯這個工具了。否則編譯過不去。
解開zip後,新建一個build資料夾,然後就是:
cmake ..
make
sudo make install
這樣g2o就裝到了你的/usr/local/lib和/usr/local/include下面。你可以到這兩個地方去看它的庫檔案與標頭檔案。
4.2 學習g2o的使用
因為g2o的文件真的很裝叉(不能忍),所以建議你直接看它的原始碼,耐心看,應該比文件好懂些。它的example文件夾下有一些示例程式碼,其中有一個tutorial_slam2d資料夾下有2d slam模擬的一個程式。值得仔細閱讀。
使用g2o來實現圖優化還是比較容易的。它幫你把節點和邊的型別都定義好了,基本上只需使用它內建的型別而不需自己重新定義。要構造一個圖,要做以下幾件事:
l 定義一個SparseOptimizer. 編寫方式參見tutorial_slam2d的宣告方式。你還要寫明它使用的演算法。通常是Gauss-Newton或LM演算法。個人覺得後者更好一些。
l 定義你要用到的邊、節點的型別。例如我們實現一個3D SLAM。那麼就要看它的g2o/types/slam3d下面的標頭檔案。節點標頭檔案都以vertex_開頭,而邊則以edge_開頭。在我們上面的模型中,可以選擇vertex_se3作為節點,edge_se3作為邊。這兩個型別的節點和邊的資料都可以直接來自於Eigen::Isometry,即上面講到過的變換矩陣T。
l 編寫一個幀間匹配程式,通過兩張影象算出變換矩陣。這個用opencv, pcl都可以做。
l 把你得到的關鍵幀作為節點,變換矩陣作為邊,加入到optimizer中。同時設定節點的估計值(如果沒有慣性測量就設成零)與邊的約束(變換矩陣)。此外,每條邊還需設定一個資訊矩陣(協方差矩陣之逆)作為不確定性的度量。例如你覺得幀間匹配精度在0.1m,那麼把資訊矩陣設成100的對角陣即可。
l 在程式執行過程中不斷作幀間檢測,維護你的圖。
l 程式結束時呼叫optimizer.optimize( steps )進行優化。優化完畢後讀取每個節點的估計值,此時就是優化後的機器人軌跡。
程式碼這種東西展開來說會變得像字典一樣枯燥,所以具體的東西需要大家自己去看,自己去體會。這裡有我自己寫的一個程式,可以供大家參考。不過這個程式需要帶著資料集才能跑,學習g2o的同學只需參考裡面程式碼的寫法即可:https://github.com/gaoxiang12/slam3d_gx
5 效果
最近我跑了幾個公開資料集(http://vision.in.tum.de/data/datasets/rgbd-dataset)上的例子(fr1_desk, fr2_slam)(,感覺效果還不錯。有些資料集還是挺難的。最後一張圖是g2o_viewer,可以看到那些關鍵路徑點與邊的樣子。



以上,如有什麼問題,歡迎與我交流:gaoxiang12@mails.tsinghua.edu.cn