20145227《資訊保安系統設計基礎》第十三週學習總結
第十一章 網路程式設計
客戶端-伺服器程式設計模型
1.每個網路應用都是基於客戶端-伺服器模型的。採用這個模型,一個應用是由一個伺服器程式和一個或者多個客戶端程式組成。伺服器管理某種資源,並且通過操作這種資源來為它的客戶端提供某種服務。
eg:一個Web伺服器管理了一組磁碟檔案,它為客戶端進行它會為客戶端進行儲存和檢索。一個FTP管理了一組磁碟檔案。相似地一個電子郵件伺服器管理了一些檔案,它為客戶端進行讀和更新。
2.客戶端-伺服器模型中的基本操作是事務。
3.一個客戶端-伺服器事務由四步組成
- (1)當一個客戶端需要服務時,它向伺服器傳送一個請求,發起一個事務。例如,當Web覽器需要一個檔案時,它就傳送一個請求給Web伺服器
- (2)伺服器收到請求後,解釋它,並以適當的方式操作它的資源。例如,當Web伺服器收到瀏覽器發出的請求後,它就讀一個磁碟檔案
- (3)伺服器給客戶端傳送一響應,並等待下一個請求。例如,Web伺服器將檔案傳送回客戶端;
- (4)客戶端收到響應並處理它。例如,當Web瀏覽器收到來自伺服器的一頁後,它就在螢幕上顯示此頁。
網路
- 客戶端和伺服器通常執行在不同的主機上,並且通過計算機網路的硬體和軟體資源來通訊。
- 對於一個主機而言,網路只是又一種I/O裝置,作為資料來源和資料接收方。
- 一個插到I/O匯流排擴充套件槽的介面卡提供了到網路的物理介面。從網路上接收到的資料從介面卡經過I/O和儲存器匯流排拷貝到儲存器,典型地是通過DMA(譯者注:直接儲存器存取方式)傳送。相似地,資料也能從儲存器拷貝到網路。
1.一個乙太網段,包括電纜和集線器。
- 每根電纜都有相同的最大位頻寬,集線器不加分辯地將一個埠上收到的每個位複製到其他所有的埠上。因此,每臺主機都能看到每個位。
2.每個乙太網介面卡都有一個全球唯一的48位地址。
- 它儲存在這個介面卡的非易失性儲存器上。每個主機介面卡都能看到這個幀,但是隻有目的主機實際讀取它。
3.橋接乙太網
- 它由電纜和網橋將多個乙太網段連線起來,形成的較大的區域網。連線網橋的電纜傳輸速率可以不同(例:網橋與網橋之間1GB/S, 網橋與集線器之間100MB/S)。
4.網橋作用:連線不同網段。
- 同一網段內A向B傳輸資料時,幀到達網橋輸入埠,網橋將其丟棄,不予轉發。A向另一網段內C傳輸資料時,網橋才將幀拷貝到與相應網段連線的埠上。從而節省了網段的頻寬
5.協議軟體的基本能力:
- 命名機制 為每臺主機至少分配一個網際網路地址,從而消除不同主機地址格式的差異,這個地址唯一地標識了這臺主機。
- 傳送機制 不同格式的資料進行封裝,使其具有相同的格式。
全球ip因特網
ip地址
- 一個IP地址就是一個32位無符號整數。網路程式將IP地址存放在下圖所示的IP地址結構中。
因特網域名
- 1.因特網客戶端和伺服器互相通訊時使用的是IP地址。為了方便記憶,因特網也定義了一組更加人性化的域名,以及一種將域名對映到IP地址的機制。域名是一串用句點分隔的單詞(字母、數字和破折號)。
- 2.域名集合形成了一個層次結構,每個域名編碼了它在這個層次中的位置。通過一個示例你將很容易理解這點。下展示了域名層次結構的一部分。層次結構可以表示為一棵樹。樹的節點表示城名,反向到根的路徑形成了域名。子樹稱為子域。層次結構中的第一層是個未命名的根節點。下一層是一組一級域名由非贏利組織(因特網分酒名字數字協會)定義。常見的第一層域名包括com、edu、gov、org、net,這些域名是由ICANN的各個授權代理按照先到先服務的基礎分配的的。一旦一個組織得到了一個二級域名,那麼它就可以在這個子域中建立任何新的域名了。
因特網連線
- 因特網客戶端和伺服器通過在連線上傳送和接收位元組流來通訊。從連線一對程式的意義上而言,連線是點對點的。從資料可以同時雙向流動的角度來說,它是全雙工的。並且從(除了一些如粗心的耕鋤機操作員切斷了電纜引起災對性的失敗以外)由源程式發出的位元組流最終被目的程式以它發出的順序收到它的角度來說,它也是可靠的。
web伺服器
- Web客戶端和伺服器之間的互動用的是一個基於文字的應用級協議,叫做HTTP。
- HTTP是一個簡單的協議。一個web客戶端(即瀏覽器)開啟一個到伺服器的因特網連線。瀏覽器讀取這些內容,並請求某些內容。伺服器響應所請求的內容,然後關閉連線。瀏覽器讀取並把它顯示在螢幕內。
- 主要的區別是Web內容可以用HTML來編寫。一個HTML程式(頁)包含指令(標記)它們告訴瀏覽器如何顯示這頁中的各種文字和圖形物件。
- Web伺服器以兩種不同的方式向客戶端提供內容:
(1)取一個磁碟檔案,並將它的內容返回給客戶端。
(2)執行一個可執行檔案,並將它的輸出返回給客戶端。
服務動態內容
- 1.客戶端如何將程式引數傳遞給伺服器
- 2.伺服器如何將引數傳遞給子程式
- 3.伺服器如何將其他資訊傳遞給子程式
- 4.子程式將它的輸出傳送到哪裡
第十二章 併發程式設計
三種基本的構造併發程式的方法:
程式
- 每個邏輯控制流是一個程式,由核心進行排程,程式有獨立的虛擬地址空間
I/O多路複用
- 邏輯流被模型化為狀態機,所有流共享同一個地址空間
執行緒
- 執行在單一程式上下文中的邏輯流,由核心進行排程,共享同一個虛擬地址空間
基於程式的併發程式設計
- 構造併發程式最簡單的方法——用程式
- 構造併發伺服器:在父程式中接受客戶端連線請求,然後建立一個新的子程式來為每個新客戶端提供服務。
- 注意:
(1)父程式需要關閉它的已連線描述符的拷貝(子程式也需要關閉)
(2)必須要包括一個SIGCHLD處理程式來回收僵死子程式的資源
(3)父子程式之間共享檔案表,但是不共享使用者地址空間,這個在以前的學習過程中提到過 - 關於獨立地址空間
(1)優點:防止虛擬儲存器被錯誤覆蓋
(2)缺點:開銷高,共享狀態資訊才需要IPC機制
基於I/O多路複用的併發程式設計
- 就是使用select函式要求核心掛起程式,只有在一個或多個I/O事件發生後,才將控制返回給應用程式。
select函式處理型別為fd_set的集合,即描述符集合,並在邏輯上描述為一個大小為n的位向量,每一位b[k]對應描述符k,但當且僅當b[k]=1,描述符k才表明是描述符集合的一個元素。
描述符能做的三件事:
(1)分配他們
(2)將一個此種型別的變數賦值給另一個變數
(3)用FD_ZERO、FD_SET、FD_CLR和FD_ISSET巨集指令來修改和檢查它們
基於I/O多路複用的併發事件驅動伺服器
事件驅動程式:將邏輯流模型化為狀態機。
狀態機:
- 狀態
- 輸入事件
- 轉移
整體的流程是:
select函式檢測到輸入事件
add_client函式建立新狀態機
check_clients函式執行狀態轉移(在課本的例題中是回送輸入行),並且完成時刪除該狀態機。
幾個需要注意的函式:
init_pool:初始化客戶端池
add_client:新增一個新的客戶端到活動客戶端池中
check_clients:回送來自每個準備好的已連線描述符的一個文字行
I/O多路複用技術的優劣
優點
(1)相較基於程式的設計,給了程式設計師更多的對程式程式的控制
(2)執行在單一程式上下文中,所以每個邏輯流都可以訪問該程式的全部地址空間,共享資料容易實現
(3)可以使用GDB除錯
(4)高效缺點
(1)編碼複雜
(2)不能充分利用多核處理器
基於執行緒的併發程式設計
執行緒執行模型
1.主執行緒
- 在每個程式開始生命週期時都是單一執行緒——主執行緒,與其他程式的區別僅有:它總是程式中第一個執行的執行緒。
2.對等執行緒
- 某時刻主執行緒建立,之後兩個執行緒併發執行。
- 每個對等執行緒都能讀寫相同的共享資料。
3.主執行緒切換到對等執行緒的原因:
- 主執行緒執行一個慢速系統呼叫,如read或sleep
- 被系統的間隔計時器中斷
4.執行緒和程式的區別
- 執行緒的上下文切換比程式快得多
- 組織形式:
- 程式:嚴格的父子層次
- 執行緒:一個程式相關執行緒組成對等(執行緒)池,和其他程式的執行緒獨立開來。一個執行緒可以殺死它的任意對等執行緒,或者等待他的任意對等執行緒終止。
Posix執行緒
Posix執行緒是C程式中處理執行緒的一個標準介面。基本用法是:
- 執行緒的程式碼和本地資料被封裝在一個執行緒例程中
- 每個執行緒例程都以一個通用指標為輸入,並返回一個通用指標。
建立執行緒
1.建立執行緒:pthread_create函式
#include <pthread.h>
typedef void *(func)(void *);
int pthread_create(pthread_t *tid, pthread_attr_t *attr, func *f, void *arg);
- 成功返回0,出錯返回非0
- 建立一個新的執行緒,帶著一個輸入變數arg,在新執行緒的上下文執行執行緒例程f。
- attr預設為NULL
- 引數tid中包含新建立執行緒的ID
2.檢視執行緒ID——pthread_self函式
#include <pthread.h>
pthread_t pthread_self(void);
返回撥用者的執行緒ID(TID)
終止執行緒
1.終止執行緒的幾個方式:
- 隱式終止:頂層的執行緒例程返回
- 顯示終止:呼叫pthread_exit函式
- 如果主執行緒呼叫,會先等待所有其他對等執行緒終止,再終止主執行緒和整個程式,返回值為pthread_return
- 某個對等執行緒呼叫Unix的exit函式,會終止程式與其相關執行緒
- 另一個對等執行緒通過以當前執行緒ID作為引數呼叫pthread_cancle來終止當前執行緒
2.pthread_exit函式
#include <pthread.h>
void pthread_exit(void *thread_return);
- 若成功返回0,出錯為非0
3.pthread_cancle函式
#include <pthread.h>
void pthread_cancle(pthread_t tid);
若成功返回0,出錯為非0
回收已終止執行緒的資源
用pthread_join函式:
#include <pthread.h>
int pthread_join(pthread_t tid,void **thrad_return);
- 這個函式會阻塞,知道執行緒tid終止,將執行緒例程返回的(void*)指標賦值為thread_return指向的位置,然後回收已終止執行緒佔用的所有儲存器資源
分離執行緒
1.可結合的執行緒
- 能夠被其他執行緒收回其資源和殺死
- 被收回前,它的儲存器資源沒有被釋放
- 每個可結合執行緒要麼被其他執行緒顯式的收回,要麼通過呼叫pthread_detach函式被分離
2.分離的執行緒
- 不能被其他執行緒回收或殺死
- 儲存器資源在它終止時由系統自動釋放
3.pthread_detach函式
#include <pthread.h>
void pthread_detach(pthread_t tid);
- 若成功返回0,出錯為非0
- 這個函式可以分離可結合執行緒tid。
- 執行緒能夠通過以pthread_self()為引數的pthread_detach呼叫來分離他們自己。
- 每個對等執行緒都應該在他開始處理請求之前分離他自身,以使得系統能在它終止後回收它的儲存器資源。
初始化執行緒:pthread_once函式
#include <pthread.h>
pthread_once_t once_control = PTHREAD_ONCE_INIT;
int pthread_once(pthread_once_t *once_control, void (*init_routine)(void));
- 總是返回0
多執行緒程式中的共享變數
執行緒儲存器模型
- 每個執行緒都有自己獨立的執行緒上下文,包括一個唯一的整數執行緒ID,棧、棧指標、程式計數器、通用目的暫存器和條件碼。
- 暫存器是從不共享的,而虛擬儲存器總是共享的。
- 各自獨立的執行緒棧被儲存在虛擬地址空間的棧區域中,並且通常是被相應的執行緒獨立地訪問的。
將變數對映到儲存器
- 全域性變數:定義在函式之外的變數
- 本地自動變數:定義在函式內部但是沒有static屬性的變數。
- 本地靜態變數:定義在函式內部並有static屬性的變數。
共享變數
- 一個變數V是共享的,當且僅當它的一個例項被一個以上的執行緒引用。例如,示例程式中的變數cnt就是共享的,因為它只有一個執行時例項,並且這個例項被兩個對等執行緒引用在- 另一方面,myid不是共享的,因為它的兩個例項中每一個都只被一個執行緒引用。然而,認識到像msgs這樣的本地自動變數也能被共享是很重要的。
用訊號量同步執行緒
- 共享變數的同時引入了同步錯誤,即沒有辦法預測作業系統是否為執行緒選擇一個正確的順序。
進度圖
- 進度圖是將n個併發執行緒的執行模型化為一條n維笛卡爾空間中的軌跡線,原點對應於沒有任何執行緒完成一條指令的初始狀態。
- 當n=2時,狀態比較簡單,是比較熟悉的二維座標圖,橫縱座標各代表一個執行緒,而轉換被表示為有向邊
轉換規則:
- 合法的轉換是向右或者向上,即某一個執行緒中的一條指令完成
- 兩條指令不能在同一時刻完成,即不允許出現對角線
- 程式不能反向執行,即不能出現向下或向左
訊號量
- P(s):如果s是非零的,那麼P將s減一,並且立即返回。如果s為零,那麼就掛起這個執行緒,直到s變為非零。
- V(s):將s加一,如果有任何執行緒阻塞在P操作等待s變為非零,那麼V操作會重啟執行緒中的一個,然後該執行緒將s減一,完成他的P操作。
- 訊號量不變性:一個正確初始化了的訊號量有一個負值。
- 訊號量操作函式:
int sem_init(sem_t *sem,0,unsigned int value);//將訊號量初始化為value
int sem_wait(sem_t *s);//P(s)
int sem_post(sem_t *s);//V(s)
使用訊號量來實現互斥
- 訊號量提供了一種很方便的方法來確保對共享變數的互斥訪問。基本思想是將每個共享變數(或者一組相關的共享變數)與一個訊號量聯絡起來 。以這種方式來保護共享變數的訊號量叫做二元訊號量,因為它的值總是0或者1。以提供互斥為目的的二元訊號量常常也稱為互斥鎖。在一個互斥鎖上執行P操作稱為對互斥鎖加鎖。類似地,執行V操作稱為對互斥鎖解鎖。對一個互斥鎖加了鎖但是還沒有解鎖的執行緒稱為佔用這個互斥鎖。一個被用作一組可用資源的計數器的訊號量稱為計數訊號量。關鍵思想是這種P和V操作的結合建立了一組狀態,叫做禁止區。因為訊號量的不變性,沒有實際可行的軌跡線能夠包含禁止區中的狀態。而且,因為禁止區完全包括了不安全區,所以沒有實際可行的軌跡線能夠接觸不安全區的任何部分。因此,每條實際可行的軌跡線都是安全的,而且不管執行時指令順序是怎樣的,程式都會正確地增加計數器的值。
利用訊號量來排程共享資源
訊號量有兩個作用:
- 實現互斥
- 排程共享資源
綜合:基於預執行緒化的併發伺服器
- 在如圖所示的併發伺服器中,我們為每一個新客戶端建立了一個新執行緒這種方法的缺點是我們為每一個新客戶端建立一個新執行緒,導致不小的代價。一個基於預執行緒化的伺服器試圖通過使用如圖所示的生產者-消費者模型來降低這種開銷。伺服器是由一個主執行緒和一組工作者執行緒構成的。主執行緒不斷地接受來自客戶端的連線請求,並將得到的連線描述符放在一個不限緩衝區中。每一個工作者執行緒反覆地從共享緩衝區中取出描述符,為客戶端服務,然後等待下一個描述符。

使用執行緒提高並行性
- 到目前為止,在對併發的研究中,我們都假設併發執行緒是在單處許多現代機器具有多核處理器。併發程式通常在這樣的機器上運理器系統上執行的。然而,在多個核上並行地排程這些併發執行緒,而不是在單個核順序地排程,在像繁忙的Web伺服器、資料庫伺服器和大型科學計算程式碼這樣的應用中利用這種並行性是至關重要的。
其他併發問題
1.執行緒安全
定義四個(不相交的)執行緒不安全函式類:
- 不保護共享變數的函式。
- 保持跨越多個呼叫狀態的函式。
- 返回指向靜態變數指標的函式。
- 呼叫執行緒不安全函式的函式。
2.可重入性
- 當它們被多個執行緒呼叫時,不會引用任何共享資料。
(1)顯式可重入的: - 所有函式引數都是傳值傳遞,沒有指標,並且所有的資料引用都是本地的自動棧變數,沒有引用靜態或全劇變數。
(2)隱式可重入的: - 呼叫執行緒小心的傳遞指向非共享資料的指標。
3.競爭
(1)競爭發生的原因:
- 一個程式的正確性依賴於一個執行緒要在另一個執行緒到達y點之前到達它的控制流中的x點。也就是說,程式設計師假定執行緒會按照某種特殊的軌跡穿過執行狀態空間,忘了一條準則規定:執行緒化的程式必須對任何可行的軌跡線都正確工作。
(2)消除方法: - 動態的為每個整數ID分配一個獨立的塊,並且傳遞給執行緒例程一個指向這個塊的指標
4.死鎖
(1)一組執行緒被阻塞了,等待一個永遠也不會為真的條件。
- 程式設計師使用P和V操作順序不當,以至於兩個訊號量的禁止區域重疊。
- 重疊的禁止區域引起了一組稱為死鎖區域的狀態。
- 死鎖是一個相當難的問題,因為它是不可預測的。
(2)互斥鎖加鎖順序規則:如果對於程式中每對互斥鎖(s,t),給所有的鎖分配一個全序,每個執行緒按照這個順序來請求鎖,並且按照逆序來釋放,這個程式就是無死鎖的。
(3)解決死鎖的方法
a、不讓死鎖發生: - 靜態策略:設計合適的資源分配演算法,不讓死鎖發生---死鎖預防;
- 動態策略:程式在申請資源時,系統審查是否會產生死鎖,若會產生死鎖則不分配---死鎖避免。
b、讓死鎖發生:
- 程式申請資源時不進行限制,系統定期或者不定期檢測是否有死鎖發生,當檢測到時解決死鎖----死鎖檢測與解除。
遇到的問題和解決過程
一開始編譯程式碼時按照之前的方法編譯,報錯。根據錯誤提示,發現pthread庫不是linux系統預設的庫,因此pthread_creat建立執行緒時,在編譯中要加上-lpthread引數。修正後順利編譯。
實踐
condvar.c
- 程式碼分析:
(1)這個程式碼演示的是生產者生產和消費者消費交替進行的過程。是執行緒間同步的一種情況。
(2)主函式中用srand(time(NULL))設定當前的時間值為種子,在後面的producer和consumer函式中呼叫rand()函式產生隨機數。 - 執行結果:
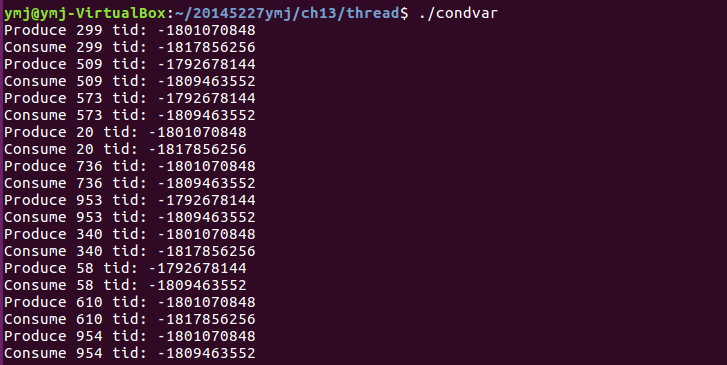
- 將主函式做如下修改後,發現生產和消費的速率比原來慢了一倍左右,因此也可以知道,通過增加或減少建立的執行緒數量能夠影響程式輸出的速率。這也側面反應出了互斥鎖在程式中所起的作用。
cp_t.c
- 程式碼分析:
(1)mmap函式
void* mmap(void* start,size_t length,int prot,int flags,int fd,off_t offset);
將一個檔案或者其他物件對映進記憶體。檔案被對映到多個頁上,如果檔案的大小不是所有頁的大小之和,最後一個頁不被使用的空間將會清零。mmap在使用者空間對映呼叫系統中作用很大。
成功執行時,mmap()返回被對映區的指標,munmap()返回0.失敗時,mmap()返回MAP_FAILED,munmap返回-1.
(2)lseek函式
off_t lseek(int fd,off_t offset,int whence);
fd表示要操作的檔案描述符,offset是相對於whence(基準)的偏移量,whence可以是SEEK_SET(檔案指標開始),SEEK_CUR(檔案指標當前位置),SEEK_END(檔案指標尾)
lseek主要作用是移動檔案讀寫指標,返回檔案讀寫指標距檔案開頭的位元組大小,若出錯則返回-1. - 執行結果:

createthread.c
- 程式碼分析:
(1)程式主要演示了建立執行緒函式pthread_create()函式的使用,用來列印程式和執行緒的ID。
(2)主函式中先利用pthread_create()函式建立一個執行緒,接著呼叫printids函式(列印識別符號的函式)列印主執行緒號,最後執行緒函式thr_fn中列印出新建的執行緒號。 - 執行結果:

semphore.c
- 程式碼分析:
(1)sem_init函式
sem_init(sem_t *sem, int pshared, umsigned int value);
函式初始化一個定位在sem的匿名訊號量;pshared引數為0指明訊號量是由程式內執行緒共享,若為非0值則訊號量在程式之間共享;value引數指定訊號量的初始值。
(2)sem_init()成功時返回0;錯誤時返回-1,並把errno設定為合適的值。
(3)sem_destroy()函式用於銷燬由sem指向的匿名訊號量。只有通過sem_init()初始化的訊號量才應該使用該函式銷燬。函式成功時返回0,錯誤時返回-1,並把errno設定為合適的值。
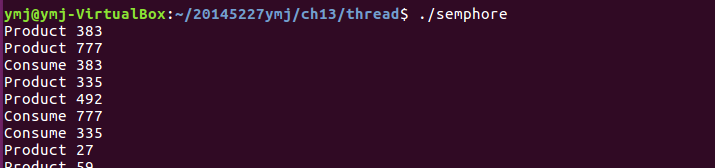
(4)這個函式和之前的condvar.c一樣都是展示生產者和消費者交替工作的過程。區別是本程式實現生產或消費的過程是利用sem_wait()和sem_post(),它們的作用分別是從訊號量的值減去一個“1”和從訊號量的值加上一個“1” - 執行結果:
hello_multi.c
- 程式碼分析:程式中的print_msg()函式中:在printf後的fflush(stdout);說明要立刻將要輸出的內容輸出,每輸出一次停1秒,並迴圈5次。
- 執行結果:

- 若想要使程式輸出像預期的列印出5個完整的helloworld,只需要將執行緒t1和t2的位置互換,修改程式碼如下:
- 修改後程式碼執行如下:

hello_multi1.c
- 程式碼分析:執行結果只輸出hello99
- 執行結果:
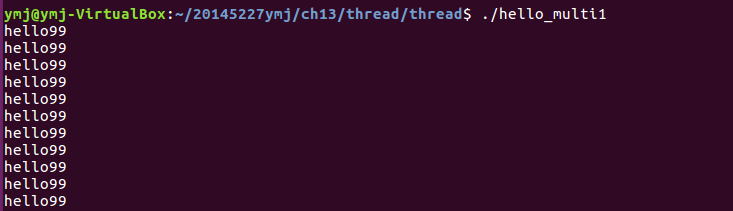
hello_single.c
- 程式碼分析:根據程式碼,先單獨執行print_msg("hello");——輸出5個hello,後輸出5個帶換行的world
- 執行結果:

incprint.c
程式碼分析:由於定義中NUM=5,所以輸出的count為1——5
執行結果:

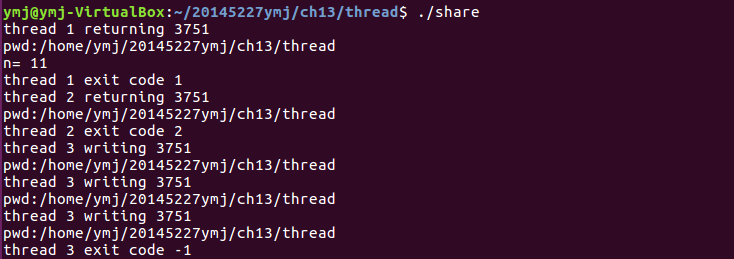
share.c
- 執行結果:
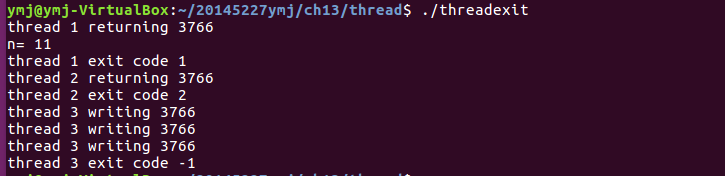
threadexit.c
- 執行結果:
countwithmutex.c
- 程式碼分析:
(1)程式碼中涉及到的函式:
- pthread_creat:建立執行緒,若成功則返回0,若失敗則返回出錯編號。第一個引數為指向執行緒識別符號的指標,建立成功時指向的記憶體單元被設定為新建立執行緒的執行緒ID;第二個引數設定執行緒屬性;第三個引數是執行緒執行函式的起始地址;最後一個引數是執行函式的引數
- pthread_join:用來等待一個執行緒的結束。當函式返回時,被等待執行緒的資源被收回。
- pthread_mutex_lock:執行緒呼叫該函式讓互斥鎖上鎖。成功鎖定時返回0,其他任何返回值都表示出現了錯誤。
- pthread_mutex_unlock:與pthread_mutex_lock成對存在。釋放互斥鎖。
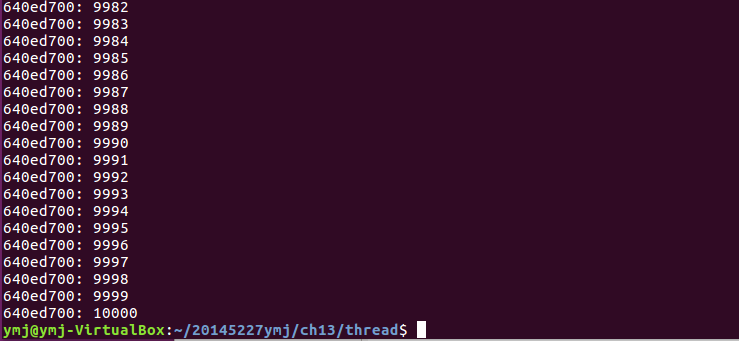
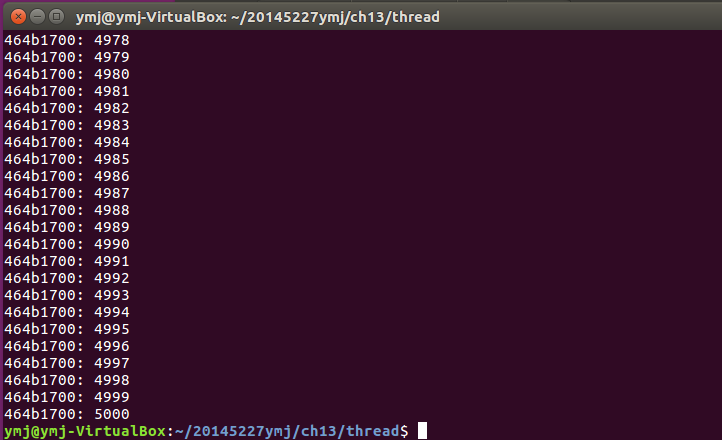
(2)程式首先定義了一個巨集PTHREAD_MUTEX_INITIALIZER來靜態初始化互斥鎖。先建立tidA執行緒後執行doit函式,利用互斥鎖鎖定資源,進行計數,執行完畢後解鎖。後建立tidB,與tidA交替執行。由於定義的NLOOP值為5000,所以程式最後的輸出值為10000.程式的最後還需要分別回收tidA和tidB的資源。
- 執行結果:
count.c
- 程式碼分析:這個程式碼用於與countwithmutex.c進行對比,差別在於本程式碼doit函式的for迴圈中沒有引入互斥鎖,只進行了單純的計數,建立兩個執行緒共享同一變數都實現加一操作。
- 執行結果
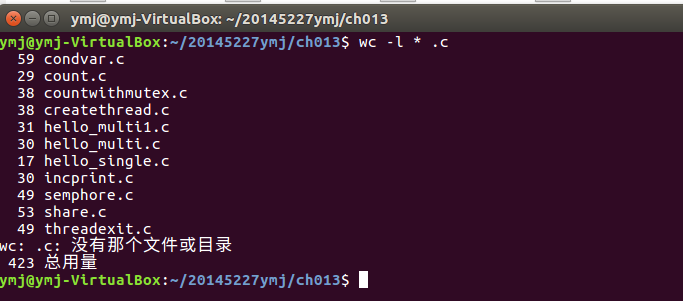
本週程式碼託管連結
https://git.oschina.net/20145227/IS-Design-20145227/tree/master/ch13
本週程式碼總數
學習進度條
| 程式碼行數(新增/累積) | 部落格量(新增/累積) | 學習時間(新增/累積) | 重要成長 | |
|---|---|---|---|---|
| 目標 | 5000行 | 30篇 | 400小時 | |
| 第一週 | 0 | 2/2 | 20/20 | |
| 第二週 | 100/100 | 1/3 | 20/40 | |
| 第三週 | 200/300 | 1/4 | 22/62 | |
| 第五週 | 200/500 | 1/5 | 22/84 | |
| 第六週 | 274/774 | 1/6 | 22/106 | |
| 第七週 | 127/901 | 2/8 | 22/128 | |
| 第八週 | 50/951 | 2/10 | 22/150 | |
| 第九周 | 418/1369 | 2/12 | 22/172 | |
| 第十週 | 485/1854 | 2/14 | 22/194 | |
| 第十一週 | 628/2482 | 3/17 | 32/226 | |
| 第十二週 | 68/2550 | 2/19 | 32/258 | |
| 第十三週 | 423/2973 | 2/21 | 32/290 |