感謝網友full_of_bull投遞此文(注:此文最初發表在這個這裡,我對原文後半段修改了許多,並加入了插圖)
Linus大嬸在slashdot上回答一些程式設計愛好者的提問,其中一個人問他什麼樣的程式碼是他所喜好的,大嬸表述了自己一些觀點之後,舉了一個指標的例子,解釋了什麼才是core low-level coding。
下面是Linus的教學原文及翻譯——
“At the opposite end of the spectrum, I actually wish more people understood the really core low-level kind of coding. Not big, complex stuff like the lockless name lookup, but simply good use of pointers-to-pointers etc. For example, I’ve seen too many people who delete a singly-linked list entry by keeping track of the “prev” entry, and then to delete the entry, doing something like。(在這段話的最後,我實際上希望更多的人瞭解什麼是真正的核心底層程式碼。這並不像無鎖檔名查詢(注:可能是git原始碼裡的設計)那樣龐大、複雜,只是僅僅像諸如使用二級指標那樣簡單的技術。例如,我見過很多人在刪除一個單項鍊表的時候,維護了一個”prev”表項指標,然後刪除當前表項,就像這樣)”
if(prev)
prev->next = entry->next;
else
list_head = entry->next;
and whenever I see code like that, I just go “This person doesn’t understand pointers”. And it’s sadly quite common.(當我看到這樣的程式碼時,我就會想“這個人不瞭解指標”。令人難過的是這太常見了。)
People who understand pointers just use a “pointer to the entry pointer”, and initialize that with the address of the list_head. And then as they traverse the list, they can remove the entry without using any conditionals, by just doing a “*pp = entry->next”. (瞭解指標的人會使用連結串列頭的地址來初始化一個“指向節點指標的指標”。當遍歷連結串列的時候,可以不用任何條件判斷(注:指prev是否為連結串列頭)就能移除某個節點,只要寫)
*pp = entry->next
So there’s lots of pride in doing the small details right. It may not be big and important code, but I do like seeing code where people really thought about the details, and clearly also were thinking about the compiler being able to generate efficient code (rather than hoping that the compiler is so smart that it can make efficient code *despite* the state of the original source code). (糾正細節是令人自豪的事。也許這段程式碼並非龐大和重要,但我喜歡看那些注重程式碼細節的人寫的程式碼,也就是清楚地瞭解如何才能編譯出有效程式碼(而不是寄望於聰明的編譯器來產生有效程式碼,即使是那些原始的彙編程式碼))。
Linus舉了一個單向連結串列的例子,但給出的程式碼太短了,一般的人很難搞明白這兩個程式碼後面的含義。正好,有個程式設計愛好者閱讀了這段話,並給出了一個比較完整的程式碼。他的話我就不翻譯了,下面給出程式碼說明。
如果我們需要寫一個remove_if(link*, rm_cond_func*)的函式,也就是傳入一個單向連結串列,和一個自定義的是否刪除的函式,然後返回處理後的連結。
這個程式碼不難,基本上所有的教科書都會提供下面的程式碼示例,而這種寫法也是大公司的面試題標準模板:
typedefstructnode
{
structnode * next;
....
} node;
typedefbool(* remove_fn)(node const* v);
// Remove all nodes from the supplied list for which the
// supplied remove function returns true.
// Returns the new head of the list.
node * remove_if(node * head, remove_fn rm)
{
for(node * prev = NULL, * curr = head; curr != NULL; )
{
node * constnext = curr->next;
if(rm(curr))
{
if(prev)
prev->next = next;
else
head = next;
free(curr);
}
else
prev = curr;
curr = next;
}
returnhead;
}
這裡remove_fn由呼叫查提供的一個是否刪除當前實體結點的函式指標,其會判斷刪除條件是否成立。這段程式碼維護了兩個節點指標prev和curr,標準的教科書寫法——刪除當前結點時,需要一個previous的指標,並且還要這裡還需要做一個邊界條件的判斷——curr是否為連結串列頭。於是,要刪除一個節點(不是表頭),只要將前一個節點的next指向當前節點的next指向的物件,即下一個節點(即:prev->next = curr->next),然後釋放當前節點。
但在Linus看來,這是不懂指標的人的做法。那麼,什麼是core low-level coding呢?那就是有效地利用二級指標,將其作為管理和操作連結串列的首要選項。程式碼如下:
voidremove_if(node ** head, remove_fn rm)
{
for(node** curr = head; *curr; )
{
node * entry = *curr;
if(rm(entry))
{
*curr = entry->next;
free(entry);
}
else
curr = &entry->next;
}
}
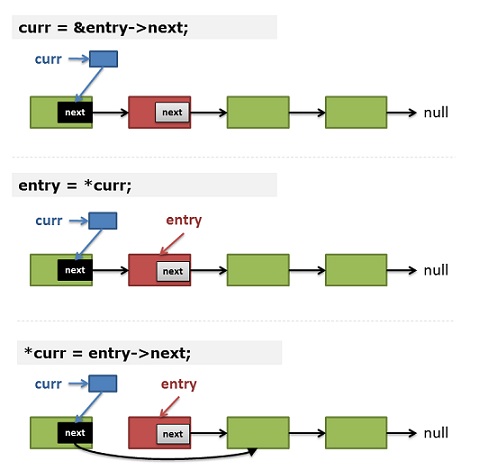
同上一段程式碼有何改進呢?我們看到:不需要prev指標了,也不需要再去判斷是否為連結串列頭了,但是,curr變成了一個指向指標的指標。這正是這段程式的精妙之處。(注意,我所highlight的那三行程式碼)
讓我們來人肉跑一下這個程式碼,對於——
-
刪除節點是表頭的情況,輸入引數中傳入head的二級指標,在for迴圈裡將其初始化curr,然後entry就是*head(*curr),我們馬上刪除它,那麼第8行就等效於*head = (*head)->next,就是刪除表頭的實現。
-
刪除節點不是表頭的情況,對於上面的程式碼,我們可以看到——
1)(第12行)如果不刪除當前結點 —— curr儲存的是當前結點next指標的地址。
2)(第5行) entry 儲存了 *curr —— 這意味著在下一次迴圈:entry就是prev->next指標所指向的記憶體。
3)(第8行)刪除結點:*curr = entry->next; —— 於是:prev->next 指向了 entry -> next;
是不是很巧妙?我們可以只用一個二級指標來操作連結串列,對所有節點都一樣。
如果你對上面的程式碼和描述理解上有困難的話,你可以看看下圖的示意:
(全文完)