3.1、Notify
Notify是淘寶自主研發的一套訊息服務引擎,是支撐雙11最為核心的系統之一,在淘寶和支付寶的核心交易場景中都有大量使用。訊息系統的核心作用就是三點:解耦,非同步和並行。下面讓我以一個實際的例子來說明一下解耦非同步和並行分別所代表的具體意義吧:
假設我們有這麼一個應用場景,為了完成一個使用者註冊淘寶的操作,可能需要將使用者資訊寫入到使用者庫中,然後通知給紅包中心給使用者發新手紅包,然後還需要通知支付寶給使用者準備對應的支付寶賬號,進行合法性驗證,告知sns系統給使用者匯入新的使用者等10步操作。
那麼針對這個場景,一個最簡單的設計方法就是序列的執行整個流程,如圖3-1所示:

圖3-1-使用者註冊流程
這種方式的最大問題是,隨著後端流程越來越多,每步流程都需要額外的耗費很多時間,從而會導致使用者更長的等待延遲。自然的,我們可以採用並行的方式來完成業務,能夠極大的減少延遲,如圖3-2所示。

圖3-2-使用者註冊流程-並行方式
但並行以後又會有一個新的問題出現了,在使用者註冊這一步,系統並行的發起了4個請求,那麼這四個請求中,如果通知SNS這一步需要的時間很長,比如需要10秒鐘的話,那麼就算是發新手包,準備支付寶賬號,進行合法性驗證這幾個步驟的速度再快,使用者也仍然需要等待10秒以後才能完成使用者註冊過程。因為只有當所有的後續操作全部完成的時候,使用者的註冊過程才算真正的“完成”了。使用者的資訊狀態才是完整的。而如果這時候發生了更嚴重的事故,比如發新手紅包的所有伺服器因為業務邏輯bug導致down機,那麼因為使用者的註冊過程還沒有完全完成,業務流程也就是失敗的了。這樣明顯是不符合實際的需要的,隨著下游步驟的逐漸增多,那麼使用者等待的時間就會越來越長,並且更加嚴重的是,隨著下游系統越來越多,整個系統出錯的概率也就越來越大。
通過業務分析我們能夠得知,使用者的實際的核心流程其實只有一個,就是使用者註冊。而後續的準備支付寶,通知sns等操作雖然必須要完成,但卻是不需要讓使用者等待的。 這種模式有個專業的名詞,就叫最終一致。為了達到最終一致,我們引入了MQ系統。業務流程如下:
主流程如圖3-3所示:

圖3-3-使用者註冊流程-引入MQ系統-主流程
非同步流程如圖3-4所示:
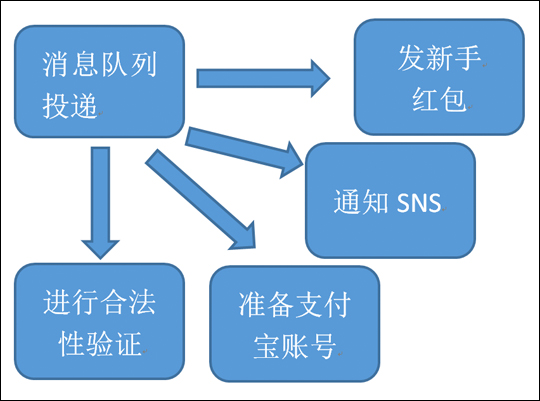
圖3-4-使用者註冊流程-引入MQ系統-非同步流程
核心原理
Notify在設計思路上與傳統的MQ有一定的不同,他的核心設計理念是
1. 為了訊息堆積而設計系統
2. 無單點,可自由擴充套件的設計
下面就請隨我一起,進入到我們的訊息系統內部來看看他設計的核心原理
- 為了訊息堆積而設計系統在市面上的大部分MQ產品,大部分的核心場景就是點對點的訊息傳輸通道,然後非常激進的使用記憶體來提升整體的系統效能,這樣做雖然標稱的tps都能達到很高,但這種設計的思路是很難符合大規模分散式場景的實際需要的。
在實際的分散式場景中,這樣的系統會存在著較大的應用場景瓶頸,在後端有大量消費者的前提下,消費者出現問題是個非常常見的情況,而訊息系統則必須能夠在後端消費不穩定的情況下,仍然能夠保證使用者寫入的正常並且TPS不降,是個非常考驗訊息系統能力的實際場景。
也因為如此,在Notify的整體設計中,我們最優先考慮的就是訊息堆積問題,在目前的設計中我們使用了持久化磁碟的方式,在每次使用者發訊息到Notify的時候都將訊息先落盤,然後再非同步的進行訊息投遞,而沒有采用激進的使用記憶體的方案來加快投遞速度。
這種方式,雖然系統效能在峰值時比目前市面的MQ效率要差一些,但是作為整個業務邏輯的核心單元,穩定,安全可靠是系統的核心訴求。 - 無單點,可自由擴充套件的設計

圖3-5-Notify系統組成結構
圖3-5展示了組成Notify整個生態體系的有五個核心的部分。
- 傳送訊息的叢集這主要是業務方的機器,這些APP的機器上是沒有任何狀態資訊的,可以隨著使用者請求量的增加而隨時增加或減少業務傳送方的機器數量,從而擴大或縮小叢集能力。
- 配置伺服器叢集(Config server)這個叢集的主要目的是動態的感知應用叢集,訊息叢集機器上線與下線的過程,並及時廣播給其他叢集。如當業務接受訊息的機器下線時,config server會感知到機器下線,從而將該機器從目標使用者組內踢出,並通知給notify server,notify server 在獲取通知後,就可以將已經下線的機器從自己的投遞目標列表中刪除,這樣就可以實現機器的自動上下線擴容了。
- 訊息伺服器(Notify Server)訊息伺服器,也就是真正承載訊息傳送與訊息接收的伺服器,也是一個叢集,應用傳送訊息時可以隨機選擇一臺機器進行訊息傳送,任意一臺server 掛掉,系統都可以正常執行。當需要增加處理能力時,只需要簡單地增加notify Server就可以了
- 儲存(Storage)Notify的儲存叢集有多種不同的實現方式,以滿足不同應用的實際儲存需求。針對訊息安全性要求高的應用,我們會選擇使用多份落盤的方式儲存訊息資料,而對於要求吞吐量而不要求訊息安全的場景,我們則可以使用記憶體儲存模型的儲存。自然的,所有儲存也被設計成了隨機無狀態寫入儲存模型以保障可以自由擴充套件。
- 訊息接收叢集業務方用於處理訊息的伺服器組,上下線機器時候也能夠動態的由config server 感知機器上下線的時機,從而可以實現機器自動擴充套件。
3.3、MetaQ
METAQ是一款完全的佇列模型訊息中介軟體,伺服器使用Java語言編寫,可在多種軟硬體平臺上部署。客戶端支援Java、C++程式語言,已於2012年3月對外開源,開源地址是: http://metaq.taobao.org/ 。MetaQ大約經歷了下面3個階段
- 在2011年1月份釋出了MetaQ 1.0版本,從Apache Kafka衍生而來,在內部主要用於日誌傳輸。
- 在2012年9月份釋出了MetaQ 2.0版本,解決了分割槽數受限問題,在資料庫binlog同步方面得到了廣泛的應用。
- 在2013年7月份釋出了MetaQ 3.0版本,MetaQ開始廣泛應用於訂單處理,cache同步、流計算、IM實時訊息、binlog同步等領域。MetaQ3.0版本已經開源, 參見這裡
綜上,MetaQ借鑑了Kafka的思想,並結合網際網路應用場景對效能的要求,對資料的儲存結構進行了全新設計。在功能層面,增加了更適合大型網際網路特色的功能點。

圖3-6-MetaQ整體結構
如圖3-6所示,MetaQ對外提供的是一個佇列服務,內部實現也是完全的佇列模型,這裡的佇列是持久化的磁碟佇列,具有非常高的可靠性,並且充分利用了作業系統cache來提高效能。
- 是一個佇列模型的訊息中介軟體,具有高效能、高可靠、高實時、分散式特點。
- Producer、Consumer、佇列都可以分散式。
- Producer向一些佇列輪流傳送訊息,佇列集合稱為Topic,Consumer如果做廣播消費,則一個consumer例項消費這個Topic對應的所有佇列,如果做叢集消費,則多個Consumer例項平均消費這個topic對應的佇列集合。
- 能夠保證嚴格的訊息順序
- 提供豐富的訊息拉取模式
- 高效的訂閱者水平擴充套件能力
- 實時的訊息訂閱機制
- 億級訊息堆積能力
MetaQ儲存結構
MetaQ的儲存結構是根據阿里大規模網際網路應用需求,完全重新設計的一套儲存結構,使用這套儲存結構可以支援上萬的佇列模型,並且可以支援訊息查詢、分散式事務、定時佇列等功能,如圖3-7所示。

圖3-7-MetaQ儲存體系
MetaQ單機上萬佇列
MetaQ內部大部分功能都靠佇列來驅動,那麼必須支援足夠多的佇列,才能更好的滿足業務需求,如圖所示,MetaQ可以在單機支援上萬佇列,這裡的佇列全部為持久化磁碟方式,從而對IO效能提出了挑戰。MetaQ是這樣解決的
- Message全部寫入到一個獨立的佇列,完全的順序寫
- Message在檔案的位置資訊寫入到另外的檔案,序列方式寫。
通過以上方式,既做到資料可靠,又可以支援更多的佇列,如圖3-8所示。

圖3-8-MetaQ單機上萬佇列
MetaQ與Notify區別
- Notify側重於交易訊息,分散式事務訊息方面。
- MetaQ側重於順序訊息場景,例如binlog同步。以及主動拉訊息場景,例如流計算等。