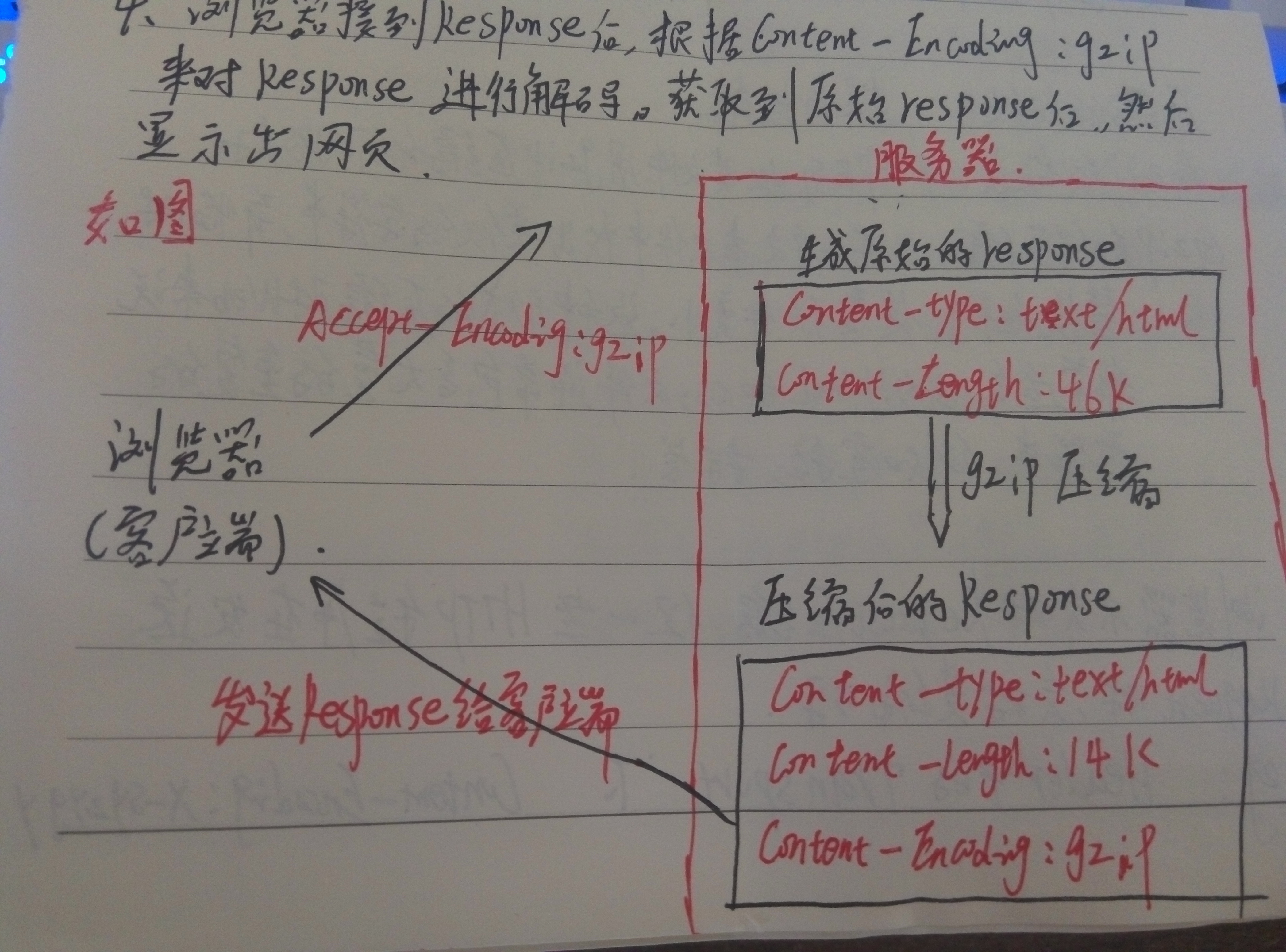
HTTP的壓縮過程如下:
1、瀏覽器傳送HTTP Request給Web伺服器,Request中含有Accept—Encoding:gzip,deflate(告訴伺服器支援的壓縮格式);
2、Web伺服器接到Request後,生成原始的Response,其中有原始的Content—Type和Content—Length;
3、伺服器通過Gzip對Response進行編碼,編碼後header中含有Content—Type和Content—Length(壓縮後的大小),並且增加了Content—Encoding:gzip,然後把Response傳送給瀏覽器;
4、瀏覽器接到Response後,根據Content—Encoding:gzip來對Response進行解碼,獲取到原始的Response後顯示在網頁上。
如圖:(唉,鼠繪的技能沒點,電腦也沒裝畫圖軟體,將就點看這個圖吧):
補充一點關於壓縮的東西:
1、Content—Encoding值:
a)、gzip 表明實體採用GNU Zip編碼
b)、compress 表明實體採用Unix的檔案壓縮程式
c)、deflate 表明實體是用zlib的格式壓縮的
d)、identity 表明沒有對實體進行編碼,當沒有Content—Encoding Header時,預設為這種情況
2、gzip,compress以及deflate編碼均為無失真壓縮演算法,其中gzip通常效率最高,使用最為廣泛
3、壓縮的好處:提高效能
Gzip的缺點:JPEG此類檔案用gzip壓縮的不夠好
Gzip如何壓縮:在一個文字檔案中找出類似的字串,並臨時替換它們,使整個檔案變小,這種形式的壓縮對Web來說非常適合。因為HTML和CSS檔案通常包含大量的重複的字串,例如空格、標籤等。
4、瀏覽器不會自動對Request進行壓縮,但一些HTTP程式在傳送Request時間,會對其編碼。
eg:Header中的Transport下Content—Encoding:X—Syzygy