[.net 物件導向程式設計進階] (2) 正規表示式 (一) 快速入門
1. 什麼是正規表示式?
1.1 正規表示式概念
正規表示式,又稱正則表示法,英文名:Regular Expression(簡寫為regex、regexp或RE),是電腦科學的一個重要概念。他是用一種數學演算法來解決計算機程式中的文字檢索、區配等問題。
1.2 正規表示式語言支援
正規表示式其實與語言無關,在很多語言中都提供了支援 ,包括最常用的指令碼語言Javascript。當然C#語言也毫不例外的提供了很好的支援。
正規表示式語法支援情況如下表:
|
命令或環境 |
. |
[ ] |
^ |
$ |
\( \) |
\{ \} |
? |
+ |
| |
( ) |
|
vi |
√ |
√ |
√ |
√ |
√ |
|
|
|
|
|
|
Visual C++ |
√ |
√ |
√ |
√ |
√ |
|
|
|
|
|
|
awk |
√ |
√ |
√ |
√ |
|
|
√ |
√ |
√ |
√ |
|
sed |
√ |
√ |
√ |
√ |
√ |
√ |
|
|
|
|
|
delphi |
√ |
√ |
√ |
√ |
√ |
|
√ |
√ |
√ |
√ |
|
python |
√ |
√ |
√ |
√ |
√ |
√ |
|
|
|
|
|
java |
√ |
√ |
√ |
√ |
√ |
√ |
|
|
|
|
|
javascript |
√ |
√ |
√ |
√ |
√ |
|
√ |
√ |
√ |
√ |
|
php |
√ |
√ |
√ |
√ |
√ |
|
|
|
|
|
|
perl |
√ |
√ |
√ |
√ |
√ |
|
√ |
√ |
√ |
√ |
|
C# |
√ |
√ |
√ |
√ |
|
|
√ |
√ |
√ |
√ |
1.3 正式表示式的應用
在進階系列文章的開始就介紹正規表示式,是因為他非常常用,在我們開發應用程式的時候,需要對輸入內容進行格式校驗,需要對複雜的字元中找出規律檢索出我們想要的部分。對於剛接觸的人來說,比較晦澀難懂,當你讀完本篇以後,就會感覺正規表示式並不是什麼複雜的東西。
因此使用正規表示式,可以幫助我們解決以下問題:
A.檢索: 可以通過正規表示式,從字串中獲取我們想要的特定部分。
B.匹配:給定的字串是否符合正規表示式的過濾邏輯
下面幾種應用場景,都特別適合正規表示式來解決
A.在論壇或部落格中發貼時過濾敏感的字詞
B.在應用軟體中進行輸入格式校驗時
C.對一段複雜文字中進行有規則的替換時
D.將一段複雜文字按一定的規則變為另一種形式時
下面我們會介紹正規表示式的基礎知識。
2. 正規表示式的組成
一個正規表示式就是由普通字元以及特殊字元(稱為元字元)組成的文字模式。該模式描述在查詢文字主體時待匹配的一個或多個字串。正規表示式作為一個模板,將某個字元模式與所搜尋的字串進行匹配。
下面,我把特殊字元,也就是元字元列舉一下
|
元字元 |
描述 |
|
\ |
將下一個字元標記為一個特殊字元、或一個原義字元、或一個向後引用、或一個八進位制轉義符。例如,“\\n”匹配\n。“\n”匹配換行符。序列“\\”匹配“\”而“\(”則匹配“(”。即相當於多種程式語言中都有的“轉義字元”的概念。 |
|
^ |
匹配輸入字串的開始位置。如果設定了RegExp物件的Multiline屬性,^也匹配“\n”或“\r”之後的位置。 |
|
$ |
匹配輸入字串的結束位置。如果設定了RegExp物件的Multiline屬性,$也匹配“\n”或“\r”之前的位置。 |
|
* |
匹配前面的子表示式任意次。例如,zo*能匹配“z”,“zo”以及“zoo”。*等價於{0,}。 |
|
+ |
匹配前面的子表示式一次或多次(大於等於1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等價於{1,}。 |
|
? |
匹配前面的子表示式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等價於{0,1}。 |
|
{n} |
n是一個非負整數。匹配確定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的兩個o。 |
|
{n,} |
n是一個非負整數。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等價於“o+”。“o{0,}”則等價於“o*”。 |
|
{n,m} |
m和n均為非負整數,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”將匹配“fooooood”中的前三個o。“o{0,1}”等價於“o?”。請注意在逗號和兩個數之間不能有空格。 |
|
? |
當該字元緊跟在任何一個其他限制符(*,+,?,{n},{n,},{n,m})後面時,匹配模式是非貪婪的。非貪婪模式儘可能少的匹配所搜尋的字串,而預設的貪婪模式則儘可能多的匹配所搜尋的字串。例如,對於字串“oooo”,“o+?”將匹配單個“o”,而“o+”將匹配所有“o”。 |
|
.點 |
匹配除“\r\n”之外的任何單個字元。要匹配包括“\r\n”在內的任何字元,請使用像“[\s\S]”的模式。 |
|
(pattern) |
匹配pattern並獲取這一匹配。所獲取的匹配可以從產生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中則使用$0…$9屬性。要匹配圓括號字元,請使用“\(”或“\)”。 |
|
(?:pattern) |
匹配pattern但不獲取匹配結果,也就是說這是一個非獲取匹配,不進行儲存供以後使用。這在使用或字元“(|)”來組合一個模式的各個部分是很有用。例如“industr(?:y|ies)”就是一個比“industry|industries”更簡略的表示式。 |
|
(?=pattern) |
正向肯定預查,在任何匹配pattern的字串開始處匹配查詢字串。這是一個非獲取匹配,也就是說,該匹配不需要獲取供以後使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。預查不消耗字元,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜尋,而不是從包含預查的字元之後開始。 |
|
(?!pattern) |
正向否定預查,在任何不匹配pattern的字串開始處匹配查詢字串。這是一個非獲取匹配,也就是說,該匹配不需要獲取供以後使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。 |
|
(?<=pattern) |
反向肯定預查,與正向肯定預查類似,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。 |
|
(?<!pattern) |
反向否定預查,與正向否定預查類似,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。 |
|
x|y |
匹配x或y。例如,“z|food”能匹配“z”或“food”或"zood"(此處請謹慎)。“(z|f)ood”則匹配“zood”或“food”。 |
|
[xyz] |
字符集合。匹配所包含的任意一個字元。例如,“[abc]”可以匹配“plain”中的“a”。 |
|
[^xyz] |
負值字符集合。匹配未包含的任意字元。例如,“[^abc]”可以匹配“plain”中的“plin”。 |
|
[a-z] |
字元範圍。匹配指定範圍內的任意字元。例如,“[a-z]”可以匹配“a”到“z”範圍內的任意小寫字母字元。 注意:只有連字元在字元組內部時,並且出現在兩個字元之間時,才能表示字元的範圍; 如果出字元組的開頭,則只能表示連字元本身. |
|
[^a-z] |
負值字元範圍。匹配任何不在指定範圍內的任意字元。例如,“[^a-z]”可以匹配任何不在“a”到“z”範圍內的任意字元。 |
|
\b |
匹配一個單詞邊界,也就是指單詞和空格間的位置(即正規表示式的“匹配”有兩種概念,一種是匹配字元,一種是匹配位置,這裡的\b就是匹配位置的)。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
|
\B |
匹配非單詞邊界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
|
\cx |
匹配由x指明的控制字元。例如,\cM匹配一個Control-M或回車符。x的值必須為A-Z或a-z之一。否則,將c視為一個原義的“c”字元。 |
|
\d |
匹配一個數字字元。等價於[0-9]。 |
|
\D |
匹配一個非數字字元。等價於[^0-9]。 |
|
\f |
匹配一個換頁符。等價於\x0c和\cL。 |
|
\n |
匹配一個換行符。等價於\x0a和\cJ。 |
|
\r |
匹配一個回車符。等價於\x0d和\cM。 |
|
\s |
匹配任何不可見字元,包括空格、製表符、換頁符等等。等價於[ \f\n\r\t\v]。 |
|
\S |
匹配任何可見字元。等價於[^ \f\n\r\t\v]。 |
|
\t |
匹配一個製表符。等價於\x09和\cI。 |
|
\v |
匹配一個垂直製表符。等價於\x0b和\cK。 |
|
\w |
匹配包括下劃線的任何單詞字元。類似但不等價於“[A-Za-z0-9_]”,這裡的"單詞"字元使用Unicode字符集。 |
|
\W |
匹配任何非單詞字元。等價於“[^A-Za-z0-9_]”。 |
|
\xn |
匹配n,其中n為十六進位制轉義值。十六進位制轉義值必須為確定的兩個數字長。例如,“\x41”匹配“A”。“\x041”則等價於“\x04&1”。正規表示式中可以使用ASCII編碼。 |
|
\num |
匹配num,其中num是一個正整數。對所獲取的匹配的引用。例如,“(.)\1”匹配兩個連續的相同字元。 |
|
\n |
標識一個八進位制轉義值或一個向後引用。如果\n之前至少n個獲取的子表示式,則n為向後引用。否則,如果n為八進位制數字(0-7),則n為一個八進位制轉義值。 |
|
\nm |
標識一個八進位制轉義值或一個向後引用。如果\nm之前至少有nm個獲得子表示式,則nm為向後引用。如果\nm之前至少有n個獲取,則n為一個後跟文字m的向後引用。如果前面的條件都不滿足,若n和m均為八進位制數字(0-7),則\nm將匹配八進位制轉義值nm。 |
|
\nml |
如果n為八進位制數字(0-7),且m和l均為八進位制數字(0-7),則匹配八進位制轉義值nml。 |
|
\un |
匹配n,其中n是一個用四個十六進位制數字表示的Unicode字元。例如,\u00A9匹配版權符號(©)。 |
|
\< \> |
匹配詞(word)的開始(\<)和結束(\>)。例如正規表示式\<the\>能夠匹配字串"for the wise"中的"the",但是不能匹配字串"otherwise"中的"the"。注意:這個元字元不是所有的軟體都支援的。 |
|
\( \) |
將 \( 和 \) 之間的表示式定義為“組”(group),並且將匹配這個表示式的字元儲存到一個臨時區域(一個正規表示式中最多可以儲存9個),它們可以用 \1 到\9 的符號來引用。 |
|
| |
將兩個匹配條件進行邏輯“或”(Or)運算。例如正規表示式(him|her) 匹配"it belongs to him"和"it belongs to her",但是不能匹配"it belongs to them."。注意:這個元字元不是所有的軟體都支援的。 |
|
+ |
匹配1或多個正好在它之前的那個字元。例如正規表示式9+匹配9、99、999等。注意:這個元字元不是所有的軟體都支援的。 |
|
? |
匹配0或1個正好在它之前的那個字元。注意:這個元字元不是所有的軟體都支援的。 |
|
{i} {i,j} |
匹配指定數目的字元,這些字元是在它之前的表示式定義的。例如正規表示式A[0-9]{3} 能夠匹配字元"A"後面跟著正好3個數字字元的串,例如A123、A348等,但是不匹配A1234。而正規表示式[0-9]{4,6} 匹配連續的任意4個、5個或者6個數字 |
小夥伴們不要被上面的表格嚇壞了,下面我會以C#中應用正規表示式為例一一說明的,上面的表格中的元字元在今後的應用中,可以作為查閱和參考。
3. C#中使用正規表示式
3.1 C#中正規表示式的名稱空間
System.Text.RegularExpressions 名稱空間包含一些類,這些類提供對 .NET Framework 正規表示式引擎的訪問。 該名稱空間提供正規表示式功能,可以從執行在 Microsoft .NET Framework 內的任何平臺或語言中使用該功能。 除了此名稱空間中包含的型別外,System.Configuration.RegexStringValidator 類還允許您確定特定字串是否與某個正規表示式模式相符。
總結一下,在.net中有兩個名稱空間用於操作正規表示式
A.System.Text.RegularExpressions 名稱空間下在的類、委託、列舉https://msdn.microsoft.com/zh-cn/library/system.text.regularexpressions.aspx
B.System.Configuration.RegexStringValidator 類
3.2 常用的操作正規表示式的方法和委託
其中System.Text.RegularExpressions 下的Regex類中提供了很多靜態方法(比較常用的有IsMatch、Match、Matches、Replace、Split等)和委託MatchEvaluator .
3.2.1 靜態方法IsMatch
IsMatch 方法返回值為一個布林型,主要用於判斷指定的字串是否與正規表示式字串匹配,它有三個過載方法
bool IsMatch(string input, string pattern);
引數: input: 要搜尋匹配項的字串。
pattern: 要匹配的正規表示式模式。
返回結果: 如果正規表示式找到匹配項,則為 true;否則,為 false。
bool IsMatch(string input, string pattern, RegexOptions options);
引數: input: 要搜尋匹配項的字串。
pattern: 要匹配的正規表示式模式。
options: 列舉值的一個按位組合,這些列舉值提供匹配選項。
返回結果: 如果正規表示式找到匹配項,則為 true;否則,為 false。
options下面有詳細說明
bool IsMatch(string input, string pattern, RegexOptions options, TimeSpan matchTimeout);
引數: input: 要搜尋匹配項的字串。
pattern: 要匹配的正規表示式模式。
options: 列舉值的一個按位組合,這些列舉值提供匹配選項。
matchTimeout: 超時間隔,或 System.Text.RegularExpressions.Regex.InfiniteMatchTimeout 指示該方法不應超時。
返回結果: 如果正規表示式找到匹配項,則為 true;否則,為 false。
3.2.2 關於引數RegexOptions options
正規表示式選項RegexOptions有如下一下選項,詳細說明請參考聯機幫助
|
RegexOptions列舉值 |
內聯標誌 |
簡單說明 |
|
ExplicitCapture |
n |
只有定義了命名或編號的組才捕獲 |
|
IgnoreCase |
i |
不區分大小寫 |
|
IgnorePatternWhitespace |
x |
消除模式中的非轉義空白並啟用由 # 標記的註釋。 |
|
MultiLine |
m |
多行模式,其原理是修改了^和$的含義 |
|
SingleLine |
s |
單行模式,和MultiLine相對應 |
這裡我提到內聯標誌,是因為相對於用RegexOptions在new Regex時定義Regex表示式的全域性選項來說,內聯標誌可以更小粒度(以組為單位)的定義匹配選項,從而更方便表達我們的思想
語法是這樣的:(?i:expression)為定義一個選項,(?-i:expression)為刪除一個選項,(?i-s:expression)則定義i,刪除s,是的,我們可以一次定義很多個選項。這樣,通過內聯選項,你就可以在一個Regex中定義一個組為匹分大小寫的,一個組不匹分大小寫的
3.2.3 靜態方法Match
靜態方法Match,使用指定的匹配選項在輸入字串中搜尋指定的正規表示式的第一個匹配項。 返回一個包含有關匹配的資訊的物件。同樣有三個過載方法,引數和IsMatch方法相同。此外,在Regex類中,還有一個同名的非靜態方法,適用於多個例項的情況下,效率更高一些。
Match Match(string input, string pattern); Match Match(string input, string pattern, RegexOptions options); Match Match(string input, string pattern, RegexOptions options, TimeSpan matchTimeout);
3.2.4 靜態方法Matches
靜態方法Matches,在指定的輸入字串中搜尋指定的正規表示式的所有匹配項。跟上面方法不同之處,就是這個方法返回的是所有匹配項,他同樣有三個過載方法,並且引數和Match方法完全相同
Match Matches(string input, string pattern); Match Matches(string input, string pattern, RegexOptions options); Match Matches(string input, string pattern, RegexOptions options, TimeSpan matchTimeout);
3.2.5 Replace函式有四個過載函式
我們知道正規表示式主要是實現驗證,提取,分割,替換字元的功能.Replace函式是實現替換功能的.
1 )Replace(string input,string pattern,string replacement)
//input是源字串,pattern是匹配的條件,replacement是替換的內容,就是把符合匹配條件pattern的內容轉換成它
比如string result = Regex.Replace("abc", "ab", "##");
//結果是##c,就是把字串abc中的ab替換成##
2 )Replace(string input,string pattern,string replacement,RegexOptions options)
//RegexOptions是一個列舉型別,用來做一些設定.
//前面用註釋時就用到了RegexOptions.IgnorePatternWhitespace.如果在匹配時忽略大小寫就可以用RegexOptions.IgnoreCase
比如string result = Regex.Replace("ABc", "ab", "##",RegexOptions.IgnoreCase);
如果是簡單的替換用上面兩個函式就可以實現了.但如果有些複雜的替換,比如匹配到很多內容,不同的內容要替換成不同的字元.就需要用到下面兩個函式
3 )Replace(string input,string pattern,MatchEvaluator evaluator);
//evaluator是一個代理,其實簡單的說是一個函式指標,把一個函式做為引數參進來
//由於C#裡沒有指標就用代理來實現類似的功能.你可以用代理繫結的函式來指定你要實現的複雜替換.
4 )Replace(string input,string pattern,MatchEvaluator evaluator,RegexOptions options);
//這個函式上上面的功能一樣,只不過多了一點列舉型別來指定是否忽略大小寫等設定
3.2.6 靜態方法Split拆分文字
使用正規表示式匹配的位置,將文字拆分為一個字串陣列,同樣有三個過載方法,返回值為字串陣列
string[] Split(string input, string pattern); string[] Match(string input, string pattern, RegexOptions options); string[] Match(string input, string pattern, RegexOptions options, TimeSpan matchTimeout);
下面我們會分別介紹最常用的正規表示式的使用
4. @符號
在“@”雖然並非C#正規表示式的“成員”,但是它經常與C#正規表示式出雙入對。“@”表示,跟在它後面的字串是個“逐字字串”,
示例:
string strFirst="C:\\Program Files\\IIS"; string strSecond=@"C:\Program Files\IIS"; Console.WriteLine(strFirst); Console.WriteLine(strSecond);
以上定義字串是等價的。
5. 定位字元
|
字元 |
說明 |
|
\b |
匹配單詞的開始或結束 |
|
\B |
匹配非單詞的開始或結束 |
|
^ |
匹配必須出現在字串的開頭或行的開頭 |
|
$ |
匹配必須出現在以下位置:字串結尾、字串結尾處的 \n 之前或行的結尾。 |
|
\A |
指定匹配必須出現在字串的開頭(忽略 Multiline 選項)。 |
|
\z |
指定匹配必須出現在字串的結尾(忽略 Multiline 選項)。 |
|
\z |
指定匹配必須出現在字串的結尾或字串結尾處的 \n 之前(忽略 Multiline 選項)。 |
|
\G |
指定匹配必須出現在上一個匹配結束的地方。與 Match.NextMatch() 一起使用時,此斷言確保所有匹配都是連續的。 |
表 5 定位元字元
示例一:區配開始 ^
string str = "I am Blue cat"; Console.WriteLine(Regex.Replace(str, "^","準備開始:"));
輸出結果為:

示例二: 區始結束 $
string str = "I am Blue cat"; Console.WriteLine(Regex.Replace(str, "$", " 結束了!"));
輸出結果為:

6. 字元轉義 \
當我們要查詢元字元時,比如查詢 * 或 . 必須使用轉義符 \,當然查詢/必須使用\\
7. 基本語法元字元
|
字元 |
說明 |
|
. |
匹配除換行符以外的任意字元 |
|
\w |
匹配字母、數字、下線下、漢字 (指大小寫字母、0-9的數字、下劃線_) |
|
\W |
\w的補集 ( 除“大小寫字母、0-9的數字、下劃線_”之外) |
|
\s |
匹配任意空白符 (包括換行符/n、回車符/r、製表符/t、垂直製表符/v、換頁符/f) |
|
\S |
\s的補集 (除\s定義的字元之外) |
|
\d |
匹配數字 (0-9數字) |
|
\D |
表示\d的補集 (除0-9數字之外) |
表7基本語法元字元
示例一:校驗只允許輸入數字
string strCheckNum1 = "23423423a3", strCheckNum2 = "324234"; Console.WriteLine("匹配字串"+strCheckNum1+"是否為數字:"+Regex.IsMatch(strCheckNum1, @"^\d*$")); Console.WriteLine("匹配字串" + strCheckNum2 + "是否為數字:" + Regex.IsMatch(strCheckNum2, @"^\d*$"));
輸出結果為:

其中*表示重複多次檢查字元,後面重複字元中會具體說明
示例二:校驗只允許輸入除大小寫字母、0-9的數字、下劃線_以外的任何字
//示例二:校驗只允許輸入除大小寫字母、0-9的數字、下劃線_以外的任何字元 string strCheckStr1 = "abcds_a", strCheckStr2 = "**&&((((2", strCheckStr3 = "**&&(((("; string regexStr = @"^\W*$"; Console.WriteLine("匹配字串" + strCheckStr1 + "是否為除大小寫字母、0-9的數字、下劃線_以外的任何字元:" + Regex.IsMatch(strCheckStr1, regexStr)); Console.WriteLine("匹配字串" + strCheckStr2 + "是否為除大小寫字母、0-9的數字、下劃線_以外的任何字元:" + Regex.IsMatch(strCheckStr2, regexStr)); Console.WriteLine("匹配字串" + strCheckStr3 + "是否為除大小寫字母、0-9的數字、下劃線_以外的任何字元:" + Regex.IsMatch(strCheckStr3, regexStr));
輸出結果為:

8. 反義
|
字元 |
說明 |
|
\W |
\w的補集 ( 除“大小寫字母、0-9的數字、下劃線_”之外) |
|
\S |
\s的補集 (除\s定義的字元之外) |
|
\D |
表示\d的補集 (除0-9數字之外) |
|
\B |
匹配不是單詞開頭或結束的位置 |
|
[^x] |
匹配除了x以外的任意字元 |
|
[^adwz] |
匹配除了adwz這幾個字元以外的任意字元 |
表8 反義字元
上面的示例中已經使用到到反義了,我們舉一個匹配除某些字母外的任意字元
示例:查詢除ahou這之外的所有字元
//示例:查詢除ahou這之外的所有字元 string strFind1 = "I am a Cat!", strFind2 = "My Name's Blue cat!";
Console.WriteLine("除ahou這之外的所有字元,原字元為:" + strFind1 + "替換後:" + Regex.Replace(strFind1, @"[^ahou]","*")); Console.WriteLine("除ahou這之外的所有字元,原字元為:" + strFind2 + "替換後:" + Regex.Replace(strFind2, @"[^ahou]", "*"));
執行結果為:

9. 重複描述字元
|
字元 |
說明 |
|
{n} |
匹配前面的字元n次 |
|
{n,} |
匹配前面的字元n次或多於n次 |
|
{n,m} |
匹配前面的字元n到m次 |
|
? |
重複零次或一次 |
|
+ |
重複一次或更多次 |
|
* |
重複零次或更多次 |
表9 重複描述字元
前面已經學習了 * 表示重複檢索多個字元,下面我們具體應用一個例項
示例:校驗輸入內容是否為合法QQ號(備註:QQ號為5-12位數字)
//示例:校驗輸入內容是否為合法QQ號(備註:QQ號為5 - 12位數字) string isQq1 = "1233", isQq2 = "a1233", isQq3 = "0123456789123", isQq4 = "556878544"; string regexQq = @"^\d{5,12}$"; Console.WriteLine(isQq1+"是否為合法QQ號(5-12位數字):" + Regex.IsMatch(isQq1, regexQq)); Console.WriteLine(isQq2 + "是否為合法QQ號(5-12位數字):" + Regex.IsMatch(isQq2, regexQq)); Console.WriteLine(isQq3 + "是否為合法QQ號(5-12位數字):" + Regex.IsMatch(isQq3, regexQq)); Console.WriteLine(isQq4 + "是否為合法QQ號(5-12位數字):" + Regex.IsMatch(isQq4, regexQq));
執行結果為:

10. 擇一匹配
|
字元 |
說明 |
|
| |
將兩個匹配條件進行邏輯“或”(Or)運算。 |
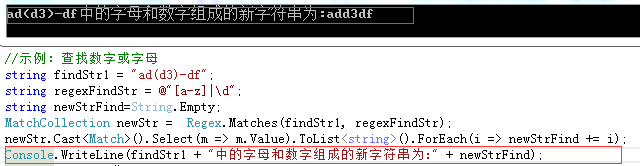
示例一:查詢數字或字母
//示例:查詢數字或字母 string findStr1 = "ad(d3)-df"; string regexFindStr = @"[a-z]|\d"; string newStrFind=String.Empty; MatchCollection newStr = Regex.Matches(findStr1, regexFindStr); newStr.Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(i => newStrFind += i); Console.WriteLine(findStr1 + "中的字母和數字組成的新字串為:" + newStrFind);
輸出結果為:
示例二:將人名輸出("zhangsan;lisi,wangwu.zhaoliu")
//示例:使用Split方法拆分 string strSplit = "zhangsan;lisi,wangwu.zhaoliu"; string regexSplitstr = @"[;]|[,]|[.]"; Regex.Split(strSplit, regexSplitstr).ToList().ForEach(i => Console.WriteLine(i));
輸出結果如下:

示例三:校驗國內電話號碼(支援三種寫法校驗 A. 010-87654321 B. (010)87654321 C.01087654321 D.010 87654321)
//示例:校驗國內電話號碼(支援三種寫法校驗 A. 010-87654321 B. (010)87654321 C.01087654321 D.010 87654321) string TelNumber1 = "(010)87654321", TelNumber2 = "010-87654321", TelNumber3 = "01087654321", TelNumber4 = "09127654321", TelNumber5 = "010)87654321",TelNumber6="(010-87654321", TelNumber7="91287654321"; Regex RegexTelNumber1 =new Regex(@"\(?0\d{2,3}[-)]?\d{7,8}"); Console.WriteLine( "電話號碼 "+TelNumber1+" 是否合法:" + RegexTelNumber1.IsMatch(TelNumber1)); Console.WriteLine("電話號碼 " + TelNumber2 + " 是否合法:" + RegexTelNumber1.IsMatch(TelNumber2)); Console.WriteLine("電話號碼 " + TelNumber3 + " 是否合法:" + RegexTelNumber1.IsMatch(TelNumber3)); Console.WriteLine("電話號碼 " + TelNumber4 + " 是否合法:" + RegexTelNumber1.IsMatch(TelNumber4)); Console.WriteLine("電話號碼 " + TelNumber5 + " 是否合法:" + RegexTelNumber1.IsMatch(TelNumber5)); Console.WriteLine("電話號碼 " + TelNumber6 + " 是否合法:" + RegexTelNumber1.IsMatch(TelNumber6)); Console.WriteLine("電話號碼 " + TelNumber7 + " 是否合法:" + RegexTelNumber1.IsMatch(TelNumber7)); Console.WriteLine("\n"); //上面未使用擇一寫法,導致TelNumber4和TelNumber5被合法化 //注意第二個分枝加了^ $符,表示從頭到尾檢索,不加的開始符,容易產生(010-87654321合法化(網上30分鐘正則教程中,就存在此錯誤) //改進使用擇一寫法後如下: Console.WriteLine("\n"); Regex RegexTelNumber3 = new Regex(@"\(0\d{2,3}\)[- ]?\d{7,8}|^0\d{2,3}[- ]?\d{7,8}$"); Console.WriteLine("電話號碼 " + TelNumber1 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber1)); Console.WriteLine("電話號碼 " + TelNumber2 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber2)); Console.WriteLine("電話號碼 " + TelNumber3 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber3)); Console.WriteLine("電話號碼 " + TelNumber4 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber4)); Console.WriteLine("電話號碼 " + TelNumber5 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber5)); Console.WriteLine("電話號碼 " + TelNumber6 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber6)); Console.WriteLine("電話號碼 " + TelNumber7 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber7));
執行結果如下:

11. 要點:
A.本篇主要說明了正規表示式的基本元字元及使用方法舉例
B.說明了C#中使用正規表示式的幾種方法
這些只是最基礎的正規表示式的內容,學習本節內容,我們還不能完成複雜的正規表示式,
在下一節中,我們會繼續說明正規表示式更深層次的使用。
下面附本節所有示例程式碼:
1 //開始和結束符 ^ $ 2 string str = "I am Blue cat"; 3 Console.WriteLine(Regex.Replace(str, "^","準備開始:")); 4 string str2 = "I am Blue cat"; 5 Console.WriteLine(Regex.Replace(str2, "$", " 結束了!")); 6 7 string str3 = "myWord.*"; 8 Console.WriteLine(Regex.Replace(str3, ".*", ".doc")); 9 10 //示例:校驗只允許輸入數字 11 12 string strCheckNum1 = "23423423a3", strCheckNum2 = "324234"; 13 Console.WriteLine("匹配字串"+strCheckNum1+"是否為數字:"+Regex.IsMatch(strCheckNum1, @"^\d*$")); 14 Console.WriteLine("匹配字串" + strCheckNum2 + "是否為數字:" + Regex.IsMatch(strCheckNum2, @"^\d*$")); 15 16 //示例二:校驗只允許輸入除大小寫字母、0-9的數字、下劃線_以外的任何字元 17 string strCheckStr1 = "abcds_a", strCheckStr2 = "**&&((((2", strCheckStr3 = "**&&(((("; 18 string regexStr = @"^\W*$"; 19 Console.WriteLine("匹配字串" + strCheckStr1 + "是否為除大小寫字母、0-9的數字、下劃線_以外的任何字元:" + Regex.IsMatch(strCheckStr1, regexStr)); 20 Console.WriteLine("匹配字串" + strCheckStr2 + "是否為除大小寫字母、0-9的數字、下劃線_以外的任何字元:" + Regex.IsMatch(strCheckStr2, regexStr)); 21 Console.WriteLine("匹配字串" + strCheckStr3 + "是否為除大小寫字母、0-9的數字、下劃線_以外的任何字元:" + Regex.IsMatch(strCheckStr3, regexStr)); 23 24 //示例:查詢除ahou這之外的所有字元 25 string strFind1 = "I am a Cat!", strFind2 = "My Name's Blue cat!"; 26 Console.WriteLine("除ahou這之外的所有字元,原字元為:" + strFind1 + "替換後:" + Regex.Replace(strFind1, @"[^ahou]","*")); 27 Console.WriteLine("除ahou這之外的所有字元,原字元為:" + strFind2 + "替換後:" + Regex.Replace(strFind2, @"[^ahou]", "*")); 28 29 //示例:校驗輸入內容是否為合法QQ號(備註:QQ號為5 - 12位數字) 30 string isQq1 = "1233", isQq2 = "a1233", isQq3 = "0123456789123", isQq4 = "556878544"; 31 string regexQq = @"^\d{5,12}$"; 32 Console.WriteLine(isQq1+"是否為合法QQ號(5-12位數字):" + Regex.IsMatch(isQq1, regexQq)); 33 Console.WriteLine(isQq2 + "是否為合法QQ號(5-12位數字):" + Regex.IsMatch(isQq2, regexQq)); 34 Console.WriteLine(isQq3 + "是否為合法QQ號(5-12位數字):" + Regex.IsMatch(isQq3, regexQq)); 35 Console.WriteLine(isQq4 + "是否為合法QQ號(5-12位數字):" + Regex.IsMatch(isQq4, regexQq)); 37 38 //示例:查詢數字或字母 39 string findStr1 = "ad(d3)-df"; 40 string regexFindStr = @"[a-z]|\d"; 41 string newStrFind=String.Empty; 42 MatchCollection newStr = Regex.Matches(findStr1, regexFindStr); 43 newStr.Cast<Match>().Select(m => m.Value).ToList<string>().ForEach(i => newStrFind += i); 44 Console.WriteLine(findStr1 + "中的字母和數字組成的新字串為:" + newStrFind); 45 46 //示例:使用Split方法拆分 47 string strSplit = "zhangsan;lisi,wangwu.zhaoliu"; 48 string regexSplitstr = @"[;]|[,]|[.]"; 49 Regex.Split(strSplit, regexSplitstr).ToList().ForEach(i => Console.WriteLine(i)); 52 53 //示例:校驗國內電話號碼(支援三種寫法校驗 A. 010-87654321 B. (010)87654321 C.01087654321 D.010 87654321) 54 string TelNumber1 = "(010)87654321", TelNumber2 = "010-87654321", TelNumber3 = "01087654321", 55 TelNumber4 = "09127654321", TelNumber5 = "010)87654321",TelNumber6="(010-87654321", 56 TelNumber7="91287654321"; 57 Regex RegexTelNumber1 =new Regex(@"\(?0\d{2,3}[-)]?\d{7,8}"); 58 Console.WriteLine( "電話號碼 "+TelNumber1+" 是否合法:" + RegexTelNumber1.IsMatch(TelNumber1)); 59 Console.WriteLine("電話號碼 " + TelNumber2 + " 是否合法:" + RegexTelNumber1.IsMatch(TelNumber2)); 60 Console.WriteLine("電話號碼 " + TelNumber3 + " 是否合法:" + RegexTelNumber1.IsMatch(TelNumber3)); 61 Console.WriteLine("電話號碼 " + TelNumber4 + " 是否合法:" + RegexTelNumber1.IsMatch(TelNumber4)); 62 Console.WriteLine("電話號碼 " + TelNumber5 + " 是否合法:" + RegexTelNumber1.IsMatch(TelNumber5)); 63 Console.WriteLine("電話號碼 " + TelNumber6 + " 是否合法:" + RegexTelNumber1.IsMatch(TelNumber6)); 64 Console.WriteLine("電話號碼 " + TelNumber7 + " 是否合法:" + RegexTelNumber1.IsMatch(TelNumber7)); 65 66 Console.WriteLine("\n"); 67 68 //上面未使用擇一寫法,導致TelNumber4和TelNumber5被合法化 69 //注意第二個分枝加了^ $符,表示從頭到尾檢索,不加的開始符,容易產生(010-87654321合法化(網上30分鐘正則教程中,就存在此錯誤) 70 //改進使用擇一寫法後如下: 71 72 Console.WriteLine("\n"); 73 74 Regex RegexTelNumber3 = new Regex(@"\(0\d{2,3}\)[- ]?\d{7,8}|^0\d{2,3}[- ]?\d{7,8}$"); 75 76 Console.WriteLine("電話號碼 " + TelNumber1 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber1)); 77 Console.WriteLine("電話號碼 " + TelNumber2 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber2)); 78 Console.WriteLine("電話號碼 " + TelNumber3 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber3)); 79 Console.WriteLine("電話號碼 " + TelNumber4 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber4)); 80 Console.WriteLine("電話號碼 " + TelNumber5 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber5)); 81 Console.WriteLine("電話號碼 " + TelNumber6 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber6)); 82 Console.WriteLine("電話號碼 " + TelNumber7 + " 是否合法:" + RegexTelNumber3.IsMatch(TelNumber7));
==============================================================================================
<如果對你有幫助,記得點一下推薦哦,如有
有不明白或錯誤之處,請多交流>
<對本系列文章閱讀有困難的朋友,請先看《.net 物件導向程式設計基礎》>
<轉載宣告:技術需要共享精神,歡迎轉載本部落格中的文章,但請註明版權及URL>
.NET 技術交流群:467189533 
==============================================================================================