
目錄
- 前言
- 1 不使用開發工具
- 2 阻塞event loop
- 3 頻繁呼叫回撥函式
- 4 聖誕樹結構的回撥(回撥的地獄)
- 5 建立一個大而完整的應用程式
- 6 缺少日誌
- 7 沒有測試
- 8 不使用靜態分析工具
- 9 沒有監視與效能分析
- 10 使用console.log來debug
前言
隨著一些大公司如Walmart,PayPal等開始採用Node.js,在過去的幾年裡,Node.js有了快速的增長。越來越多的人開始選擇Node併發布modules到NPM,其發展的速度遠超其它開發語言。不過對於Node的理念你可能需要一些時間去適應,尤其是那些剛從其它程式語言轉型過來的開發人員。
在本文中我將談一談Node開發者們最常範的一些錯誤以及如何來避免這些錯誤。有關示例的原始碼,你可以從github上獲取到。
1 不使用開發工具
- 自動重啟工具nodemon或supervisor
- 瀏覽器內的live reload工具(當靜態資源或views檢視發生改變時自動reload頁面)
與其它程式語言如PHP或Ruby不同,當你修改了原始碼後,Node需要重新啟動才能使修改生效。在建立Web應用程式時還有一件事會使你放慢腳步,那就是當修改靜態資源時重新整理瀏覽器頁面。當然你可以不厭其煩地手動來做這些事情,不過這裡會有一些更好的解決辦法。
1.1 自動重啟工具
我們中的大部分人可能都是這樣編寫和除錯程式碼的,在編輯器中儲存程式碼,然後在控制檯按CTRL+C鍵停止應用,隨後通過向上鍵找到之前執行過的啟動命令,按回車來重新啟動應用。不過,通過使用下面這些工具可以自動完成應用的重啟並簡化開發流程:
這些工具可以監視程式碼檔案的修改並自動重啟服務。下面以nodemon為例來說說如何使用這些工具。首先通過npm進行全域性安裝:
npm i nodemon -g
然後,在終端通過nodemon代替node命令來啟動應用:
# node server.js $ nodemon server.js 14 Nov 21:23:23 - [nodemon] v1.2.1 14 Nov 21:23:23 - [nodemon] to restart at any time, enter `rs` 14 Nov 21:23:23 - [nodemon] watching: *.* 14 Nov 21:23:23 - [nodemon] starting `node server.js` 14 Nov 21:24:14 - [nodemon] restarting due to changes... 14 Nov 21:24:14 - [nodemon] starting `node server.js`
對nodemon或node-supervisor來說,在所有已有的選項中,最牛逼的莫過於可以指定忽略的檔案或資料夾。
1.2 瀏覽器自動重新整理工具
除了上面介紹的自動重啟工具外,還有其它的工具可以幫助你加快web應用程式的開發。livereload工具允許瀏覽器在監測到程式變動後自動重新整理頁面,而不用手動進行重新整理。
其工作的基本原理和上面介紹的相似,只是它監測特定資料夾內的修改然後自動重新整理瀏覽器,而不是重啟整個服務。自動重新整理需要依賴於在頁面中注入指令碼或者通過瀏覽器外掛來實現。
這裡我不去介紹如何使用livereload,相反,我將介紹如何通過Node來建立一個相似的工具,它將具有下面這些功能:
- 監視資料夾中的檔案修改
- 通過server-sent events向所有已連線的客戶端傳送訊息,並且
- 觸發一個page reload
首先我們需要通過NPM來安裝專案需要的所有依賴項:
- express - 建立一個示例web應用程式
- watch - 監視檔案修改
- sendevent - sever-sent events (SSE),或者也可以使用websockets來實現
- uglify-js - 用於壓縮客戶端JavaScript檔案
- ejs - 檢視模板
接下來我將建立一個簡單的Express server在前端頁面中渲染home檢視:
var express = require('express'); var app = express(); var ejs = require('ejs'); var path = require('path'); var PORT = process.env.PORT || 1337; // view engine setup app.engine('html', ejs.renderFile); app.set('views', path.join(__dirname, 'views')); app.set('view engine', 'html'); // serve an empty page that just loads the browserify bundle app.get('/', function(req, res) { res.render('home'); }); app.listen(PORT); console.log('server started on port %s', PORT);
因為使用的是Express,所以我們可以將瀏覽器自動重新整理工具做成一個Express的中介軟體。這個中介軟體會attach到SSE endpoint,並會在客戶端指令碼中建立一個view helper。中介軟體function的引數是Express的app,以及需要被監視的資料夾。於是,我們將下面的程式碼加到server.js中,放到view setup之前:
var reloadify = require('./lib/reloadify'); reloadify(app, __dirname + '/views');
現在/views資料夾中的檔案被監視。整個中介軟體看起來像下面這樣:
var sendevent = require('sendevent'); var watch = require('watch'); var uglify = require('uglify-js'); var fs = require('fs'); var ENV = process.env.NODE_ENV || 'development'; // create && minify static JS code to be included in the page var polyfill = fs.readFileSync(__dirname + '/assets/eventsource-polyfill.js', 'utf8'); var clientScript = fs.readFileSync(__dirname + '/assets/client-script.js', 'utf8'); var script = uglify.minify(polyfill + clientScript, { fromString: true }).code; function reloadify(app, dir) { if (ENV !== 'development') { app.locals.watchScript = ''; return; } // create a middlware that handles requests to `/eventstream` var events = sendevent('/eventstream'); app.use(events); watch.watchTree(dir, function (f, curr, prev) { events.broadcast({ msg: 'reload' }); }); // assign the script to a local var so it's accessible in the view app.locals.watchScript = '<script>' + script + '</script>'; } module.exports = reloadify;
你也許已經注意到了,如果執行環境沒有被設定成'development',那麼這個中介軟體什麼也不會做。這意味著我們不得不在產品環境中將該程式碼刪掉。
前端JS指令碼檔案非常簡單,它只負責監聽SSE的訊息並在需要的時候重新載入頁面:
(function() { function subscribe(url, callback) { var source = new window.EventSource(url); source.onmessage = function(e) { callback(e.data); }; source.onerror = function(e) { if (source.readyState == window.EventSource.CLOSED) return; console.log('sse error', e); }; return source.close.bind(source); }; subscribe('/eventstream', function(data) { if (data && /reload/.test(data)) { window.location.reload(); } }); }());
檔案eventsourfe-polyfill.js可以從Remy Sharp's polyfill for SSE找到。最後非常重要的一點是將生成的指令碼通過下面的方式新增到前端頁面/views/homt.html中:
... <%- watchScript %> ...
現在,當你每次對home.html頁面做修改時,瀏覽器都將從伺服器重新載入該頁面(http://localhost:1337/)。
2 阻塞event loop
由於Node.js是單執行緒執行的,所有對event loop的阻塞都將使整個程式被阻塞。這意味著如果你有一個上千個客戶端訪問的web server,並且程式發生了event loop阻塞,那麼所有的客戶端都將處於等待狀態而無法獲得伺服器應答。
這裡有一些例子,你可能會在不經意中使用它們而產生event loop阻塞:
- 使用JSON.parse()函式解析一個非常大的json
- 嘗試在後臺對一個非常大的檔案進行語法高亮顯示(如使用Ace或者highlight.js)
- 一次性輸出一個大的內容(例如從child process輸出git log命令的結果)
問題是你會不經意中做了上述的事情,畢竟將一個擁有15Mb左右大小的內容輸出並不會經常發生,對嗎?這足以讓攻擊者發現並最終使你的整個伺服器受到DDOS攻擊而崩潰掉。
幸運的是你可以通過監視event loop的延遲來檢測異常。我們可以通過一些特定的解決方案例如StrongOps來實現,或者也可以通過一些開源的modules來實現,如blocked。
這些工具的工作原理是精確地跟蹤每次interval之間所花費的時間然後報告。時間差是通過這樣的方式來計算的:先記錄下interval過程中A點和B點的準確時間,然後用B點的時間減去A點的時間,再減去interval執行間隔的時間。
下面的例子充分說明了如何來實現這一點,它是這麼做的:
- 獲取當前時間和以引數傳入的時間變數之間的高精度時間值(high-resolution)
- 確定在正常情況下interval的event loop的延遲時間
- 將延遲時間顯示成綠色,如果超過閥值則顯示為紅色
- 然後看實際執行的情況,每300毫秒執行一次大的運算
下面是上述示例的原始碼:
var getHrDiffTime = function(time) { // ts = [seconds, nanoseconds] var ts = process.hrtime(time); // convert seconds to miliseconds and nanoseconds to miliseconds as well return (ts[0] * 1000) + (ts[1] / 1000000); }; var outputDelay = function(interval, maxDelay) { maxDelay = maxDelay || 100; var before = process.hrtime(); setTimeout(function() { var delay = getHrDiffTime(before) - interval; if (delay < maxDelay) { console.log('delay is %s', chalk.green(delay)); } else { console.log('delay is %s', chalk.red(delay)); } outputDelay(interval, maxDelay); }, interval); }; outputDelay(300); // heavy stuff happening every 2 seconds here setInterval(function compute() { var sum = 0; for (var i = 0; i <= 999999999; i++) { sum += i * 2 - (i + 1); } }, 2000);
執行上面的程式碼需要安裝chalk。執行之後你應該會在終端看到如下圖所示的結果:
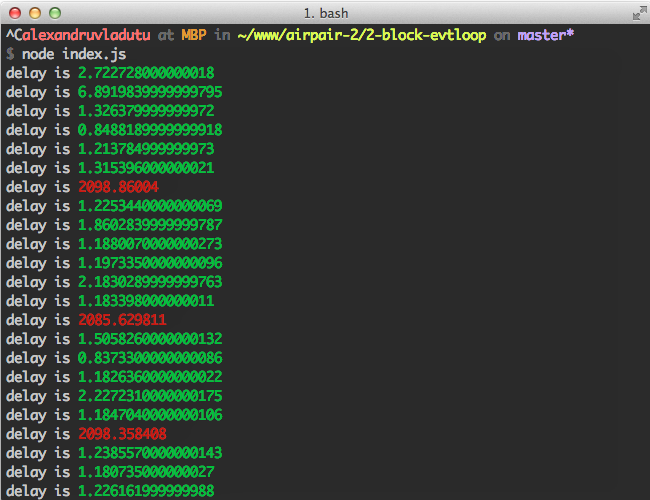
前面已經說過,開源modules也使用了相似的方式來實現對應的功能,因此可以放心使用它們:
- https://github.com/hapijs/heavy/blob/bbc98a5d7c4bddaab94d442210ca694c7cd75bde/lib/index.js#L70
- https://github.com/tj/node-blocked/blob/master/index.js#L2-L14
通過使用這種技術進行效能分析,你可以精確地找出程式碼中的哪部分會導致延遲。
3 頻繁呼叫回撥函式
很多時候當你儲存檔案然後重新啟動Node web app時它就很快地崩掉了。最有可能出現的原因就是呼叫了兩次回撥函式,這意味著你很可能在第一次呼叫之後忘記return了。
我們建立一個例子來重現一下這種情況。我將建立一個簡單的包含基本驗證功能的代理server。要使用它你需要安裝request這個依賴包,執行程式然後訪問(如http://localhost:1337/?url=http://www.google.com/)。下面是這個例子的原始碼:
var request = require('request'); var http = require('http'); var url = require('url'); var PORT = process.env.PORT || 1337; var expression = /[-a-zA-Z0-9@:%_\+.~#?&//=]{2,256}\.[a-z]{2,4}\b(\/[-a-zA-Z0-9@:%_\+.~#?&//=]*)?/gi; var isUrl = new RegExp(expression); var respond = function(err, params) { var res = params.res; var body = params.body; var proxyUrl = params.proxyUrl; res.setHeader('Content-type', 'text/html; charset=utf-8'); if (err) { console.error(err); res.end('An error occured. Please make sure the domain exists.'); } else { res.end(body); } }; http.createServer(function(req, res) { var queryParams = url.parse(req.url, true).query; var proxyUrl = queryParams.url; if (!proxyUrl || (!isUrl.test(proxyUrl))) { res.writeHead(200, { 'Content-Type': 'text/html' }); res.write("Please provide a correct URL param. For ex: "); res.end("<a href='http://localhost:1337/?url=http://www.google.com/'>http://localhost:1337/?url=http://www.google.com/</a>"); } else { // ------------------------ // Proxying happens here // TO BE CONTINUED // ------------------------ } }).listen(PORT);
除代理本身外,上面的程式碼幾乎包含了所有需要的部分。再仔細看看下面的內容:
request(proxyUrl, function(err, r, body) { if (err) { respond(err, { res: res, proxyUrl: proxyUrl }); } respond(null, { res: res, body: body, proxyUrl: proxyUrl }); });
在回撥函式中,我們有錯誤處理的邏輯,但是在呼叫respond函式後忘記停止整個執行流程了。這意味著如果我們訪問一個無法host的站點,respond函式將會被呼叫兩次,我們會在終端收到下面的錯誤資訊:
Error: Can't set headers after they are sent. at ServerResponse.OutgoingMessage.setHeader (http.js:691:11) at respond (/Users/alexandruvladutu/www/airpair-2/3-multi-callback/proxy-server.js:18:7) This can be avoided either by using the `return` statement or by wrapping the 'success' callback in the `else` statement:
request(.., function(..params) { if (err) { return respond(err, ..); } respond(..); }); // OR: request(.., function(..params) { if (err) { respond(err, ..); } else { respond(..); } });
4 聖誕樹結構的回撥(回撥的地獄)
有些人總是拿地獄般的回撥引數來抨擊Node,認為在Node中回撥巢狀是無法避免的。但其實並非如此。這裡有許多解決方法,可以使你的程式碼看起來非常規整:
- 使用流程控制模組如async
- 使用Promises
- 使用Generators
我們來建立一個例子,然後重構它以使用async模組。這個app是一個簡單的前端資源分析工具,它完成下面這些工作:
- 檢查HTML程式碼中有多少scripts,stylesheets,images的引用
- 將檢查的結果輸出到終端
- 檢查每一個資源的content-length並將結果輸出到終端
除async模組外,你需要安裝下面這些npm包:
var URL = process.env.URL; var assert = require('assert'); var url = require('url'); var request = require('request'); var cheerio = require('cheerio'); var once = require('once'); var isUrl = new RegExp(/[-a-zA-Z0-9@:%_\+.~#?&//=]{2,256}\.[a-z]{2,4}\b(\/[-a-zA-Z0-9@:%_\+.~#?&//=]*)?/gi); assert(isUrl.test(URL), 'must provide a correct URL env variable'); request({ url: URL, gzip: true }, function(err, res, body) { if (err) { throw err; } if (res.statusCode !== 200) { return console.error('Bad server response', res.statusCode); } var $ = cheerio.load(body); var resources = []; $('script').each(function(index, el) { var src = $(this).attr('src'); if (src) { resources.push(src); } }); // ..... // similar code for stylesheets and images // checkout the github repo for the full version var counter = resources.length; var next = once(function(err, result) { if (err) { throw err; } var size = (result.size / 1024 / 1024).toFixed(2); console.log('There are ~ %s resources with a size of %s Mb.', result.length, size); }); var totalSize = 0; resources.forEach(function(relative) { var resourceUrl = url.resolve(URL, relative); request({ url: resourceUrl, gzip: true }, function(err, res, body) { if (err) { return next(err); } if (res.statusCode !== 200) { return next(new Error(resourceUrl + ' responded with a bad code ' + res.statusCode)); } if (res.headers['content-length']) { totalSize += parseInt(res.headers['content-length'], 10); } else { totalSize += Buffer.byteLength(body, 'utf8'); } if (!--counter) { next(null, { length: resources.length, size: totalSize }); } }); }); });
上面的程式碼看起來還不是特別糟糕,不過你還可以巢狀更深的回撥函式。從底部的程式碼中你應該能識別出什麼是聖誕樹結構了,其程式碼的縮排看起來像這個樣子:
if (!--counter) { next(null, { length: resources.length, size: totalSize }); } }); }); });
要執行上面的程式碼,在終端輸入下面的命令:
$ URL=https://bbc.co.uk/ node before.js # Sample output: # There are ~ 24 resources with a size of 0.09 Mb.
使用async進行部分重構之後,我們的程式碼看起來像下面這樣:
var async = require('async'); var rootHtml = ''; var resources = []; var totalSize = 0; var handleBadResponse = function(err, url, statusCode, cb) { if (!err && (statusCode !== 200)) { err = new Error(URL + ' responded with a bad code ' + res.statusCode); } if (err) { cb(err); return true; } return false; }; async.series([ function getRootHtml(cb) { request({ url: URL, gzip: true }, function(err, res, body) { if (handleBadResponse(err, URL, res.statusCode, cb)) { return; } rootHtml = body; cb(); }); }, function aggregateResources(cb) { var $ = cheerio.load(rootHtml); $('script').each(function(index, el) { var src = $(this).attr('src'); if (src) { resources.push(src); } }); // similar code for stylesheets && images; check the full source for more setImmediate(cb); }, function calculateSize(cb) { async.each(resources, function(relativeUrl, next) { var resourceUrl = url.resolve(URL, relativeUrl); request({ url: resourceUrl, gzip: true }, function(err, res, body) { if (handleBadResponse(err, resourceUrl, res.statusCode, cb)) { return; } if (res.headers['content-length']) { totalSize += parseInt(res.headers['content-length'], 10); } else { totalSize += Buffer.byteLength(body, 'utf8'); } next(); }); }, cb); } ], function(err) { if (err) { throw err; } var size = (totalSize / 1024 / 1024).toFixed(2); console.log('There are ~ %s resources with a size of %s Mb.', resources.length, size); });
5 建立一個大而完整的應用程式
一些初入Node的開發人員往往會將其它語言的一些思維模式融入進來,從而寫出不同風格的程式碼。例如將所有的程式碼寫到一個檔案裡,而不是將它們分散到自己的模組中再發布到NPM等。
就拿我們之前的例子來說,我們將所有的內容都放在一個檔案裡,這使得程式碼很難被測試和讀懂。不過別擔心,我們會重構程式碼使其看起來漂亮並且更加模組化。當然,這也將有效地避免回撥地獄。
如果我們將URL validator,response handler,request功能塊以及resource處理程式抽出來放到它們自己的模組中,我們的主程式看起來會像下面這樣:
// ... var handleBadResponse = require('./lib/bad-response-handler'); var isValidUrl = require('./lib/url-validator'); var extractResources = require('./lib/resource-extractor'); var request = require('./lib/requester'); // ... async.series([ function getRootHtml(cb) { request(URL, function(err, data) { if (err) { return cb(err); } rootHtml = data.body; cb(null, 123); }); }, function aggregateResources(cb) { resources = extractResources(rootHtml); setImmediate(cb); }, function calculateSize(cb) { async.each(resources, function(relativeUrl, next) { var resourceUrl = url.resolve(URL, relativeUrl); request(resourceUrl, function(err, data) { if (err) { return next(err); } if (data.res.headers['content-length']) { totalSize += parseInt(data.res.headers['content-length'], 10); } else { totalSize += Buffer.byteLength(data.body, 'utf8'); } next(); }); }, cb); } ], function(err) { if (err) { throw err; } var size = (totalSize / 1024 / 1024).toFixed(2); console.log('\nThere are ~ %s resources with a size of %s Mb.', resources.length, size); });
而request功能塊則看起來像這樣:
var handleBadResponse = require('./bad-response-handler'); var request = require('request'); module.exports = function getSiteData(url, callback) { request({ url: url, gzip: true, // lying a bit headers: { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36' } }, function(err, res, body) { if (handleBadResponse(err, url, res && res.statusCode, callback)) { return; } callback(null, { body: body, res: res }); }); };
完整的例子可以從github repo中找到。
現在就簡單了,程式碼更加易讀,我們也可以開始為我們的app新增測試用例了。當然,我們還可以繼續重構程式碼將獲取response長度的功能單獨分離出來放到自己的模組中。
好的一點是Node鼓勵大家編寫小的模組併發布到NPM。在NPM中你可以找到各種各樣的模組小到如在interval間生成隨機數的模組。你應當努力使你的Node應用程式模組化,功能越簡單越好。
6 缺少日誌
很多Node教程都會展示示例程式碼,並在其中不同的地方包含console.log,這給許多Node開發人員留下了一個印象,即console.log就是在Node程式碼中實現日誌功能。
在編寫Node apps程式碼時你應當使用一些比console.log更好的工具來實現日誌功能,因為這些工具:
- 對一些大而複雜的物件不需要使用util.inspect
- 內建序列化器,如對errors,request和response物件等進行序列化
- 支援多種不同的日誌源
- 可自動包含hostname,process id,application name等
- 支援不同級別的日誌(如debug,info,error,fatal等)
- 一些高階功能如日誌檔案自動滾動等
這些功能都可以免費使用,你可以在生產環境中使用日誌模組如bunyan。如果將模組安裝到全域性,你還可以得到一個便利的CLI開發工具。
讓我們來看看它的示例程式以瞭解如何使用它:
var http = require('http'); var bunyan = require('bunyan'); var log = bunyan.createLogger({ name: 'myserver', serializers: { req: bunyan.stdSerializers.req, res: bunyan.stdSerializers.res } }); var server = http.createServer(function (req, res) { log.info({ req: req }, 'start request'); // <-- this is the guy we're testing res.writeHead(200, { 'Content-Type': 'text/plain' }); res.end('Hello World\n'); log.info({ res: res }, 'done response'); // <-- this is the guy we're testing }); server.listen(1337, '127.0.0.1', function() { log.info('server listening'); var options = { port: 1337, hostname: '127.0.0.1', path: '/path?q=1#anchor', headers: { 'X-Hi': 'Mom' } }; var req = http.request(options, function(res) { res.resume(); res.on('end', function() { process.exit(); }) }); req.write('hi from the client'); req.end(); });
在終端執行,你會看到下面的輸出內容:
$ node server.js {"name":"myserver","hostname":"MBP.local","pid":14304,"level":30,"msg":"server listening","time":"2014-11-16T11:30:13.263Z","v":0} {"name":"myserver","hostname":"MBP.local","pid":14304,"level":30,"req":{"method":"GET","url":"/path?q=1#anchor","headers":{"x-hi":"Mom","host":"127.0.0.1:1337","connection":"keep-alive"},"remoteAddress":"127.0.0.1","remotePort":61580},"msg":"start request","time":"2014-11-16T11:30:13.271Z","v":0} {"name":"myserver","hostname":"MBP.local","pid":14304,"level":30,"res":{"statusCode":200,"header":"HTTP/1.1 200 OK\r\nContent-Type: text/plain\r\nDate: Sun, 16 Nov 2014 11:30:13 GMT\r\nConnection: keep-alive\r\nTransfer-Encoding: chunked\r\n\r\n"},"msg":"done response","time":"2014-11-16T11:30:13.273Z","v":0}
開發過程中可將它作為一個CLI工具來使用:
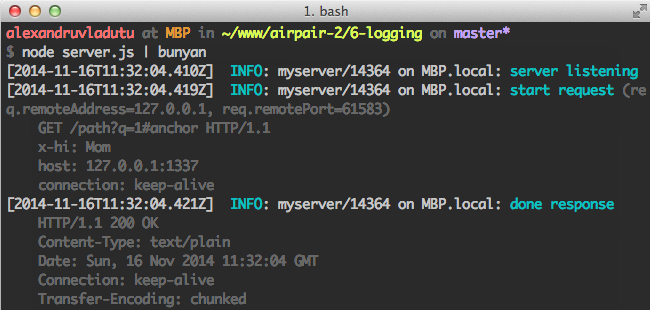
正如你所看到的,bunyan給你提供了有關當前程式的許多有用的資訊,這些資訊在產品環境中都十分重要。另外一個便利的功能是你可以將日誌輸出到一個或多個流中。
7 沒有測試
沒有提供測試的程式不是一個完整的程式。已經有這麼多的工具可以幫助我們來進行測試,實在沒有任何理由不編寫測試用例了:
- 測試框架:mocha, jasmine, tape,還有許多其它框架
- Asertion(斷言)模組:chai, should.js
- 模組mocks, spies, stubs或fake timers如sinon
- 程式碼覆蓋工具:istanbul, blanket
作為NPM模組的約定,你需要在package.json中指定測試命令,如:
{ "name": "express", ... "scripts": { "test": "mocha --require test/support/env --reporter spec --bail --check-leaks test/ test/acceptance/", ... }
然後通過npm test來啟動測試,你根本不用去管如何來呼叫測試框架。
另外一個你需要考慮的是在提交程式碼之前務必使所有的測試用例都通過,這隻需要通過一行簡單的命令就可以做到:
npm i pre-commit --save-dev
當然你也可以強制執行某個特定的code coverage級別的測試而拒絕提交那些不遵守該級別的程式碼。pre-commit模組作為一個pre-commit的hook程式可以自動地執行npm test。
如果你不確定如何來編寫測試,可以通過一些線上教程或者在Github中看看那些流行的Node專案它們是如何做的:
8 不使用靜態分析工具
為了不在生產環境中才發現問題,最好的辦法是在開發過程中使用靜態分析工具立即就發現這些問題。
例如,ESLint工具可以幫助我們解決許多問題:
- 可能的錯誤。如:禁止在條件表示式中使用賦值語句,禁止使用debugger
- 強制最佳體驗。如:禁止宣告多個相同名稱的變數,禁止使用arguments.calle
- 找出潛在的安全問題,如使用eval()或不安全的正規表示式
- 偵測出可能存在的效能問題
- 執行一致的風格
有關ESLint更多的完整規則可以檢視官方文件。如果想在實際專案中使用ESLint,你還應該看看它的配置文件。
有關如何配置ESLint,這裡可以找到一些例子。
如果你想解析AST(抽象源樹或抽象語法樹)並自己建立靜態分析工具,可以參考Esprima或Acorn。
9 沒有監視與效能分析
如果Node應用程式沒有監視與效能分析,你將對其執行情況一無所知。一些很重要的東西如event loop延遲,CPU負載,系統負載或記憶體使用量等你將無法得知。
這裡有一些特定的服務可以幫助到你,可以從New Relic, StrongLoop以及Concurix, AppDynamics等了解到。
你也可以通過開源模組如look或結合不同的NPM包自己來實現。不管選擇哪種方式,你都要確保始終都能監測到你的程式的執行狀態,否則你可能會在半夜收到各種詭異的電話告訴你程式又出現這樣或那樣的問題。
10 使用console.log來debug
一旦程式出現錯誤,你可以簡單地在程式碼中插入console.log來進行debug。問題解決之後刪除console.log除錯語句再繼續。
問題是其他的開發人員(甚至是你自己)可能還會遇到一樣的問題而再重複上面的操作。這就是為什麼除錯模組如debug存在的原因。你可以在程式碼中使用debug function來代替console.log語句,而且在除錯完之後不用刪除它們。
其他開發人員如果遇到問題需要除錯程式碼,只需要通過DEBUG環境變數來啟動程式即可。
這個小的module具有以下優點:
- 除非你通過DEBUG環境變數啟動程式,否則它不會在控制檯輸出任何內容。
- 你可以有選擇地對程式碼中的一部分進行除錯(甚至可以通過萬用字元來指定內容)。
- 終端的輸出內容有各種不同的顏色,看起來很舒服。
來看看官方給出的示例:
// app.js var debug = require('debug')('http') , http = require('http') , name = 'My App'; // fake app debug('booting %s', name); http.createServer(function(req, res){ debug(req.method + ' ' + req.url); res.end('hello\n'); }).listen(3000, function(){ debug('listening'); }); // fake worker of some kind require('./worker'); <!--code lang=javascript linenums=true--> // worker.js var debug = require('debug')('worker'); setInterval(function(){ debug('doing some work'); }, 1000);
如果以node app.js來啟動程式,不會輸出任何內容。但是如果啟動的時候帶著DEBUG標記,那麼:
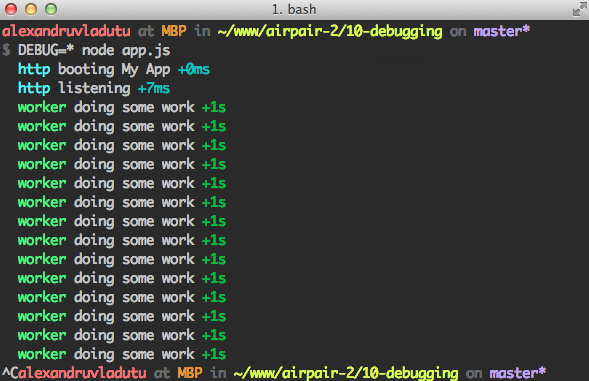
除了在應用程式中使用它們,你還可以在一些小的modules中使用它併發布到NPM。與其它一些複雜的logger不同,它只負責debugging而且還很好使。
原文地址:https://www.airpair.com/node.js/posts/top-10-mistakes-node-developers-make